
 Technologie-Peripheriegeräte
KI
Mithilfe einer Codezeile, um die Wirkung von Zero-Shot-Lernmethoden erheblich zu verbessern, schlagen die Nanjing University of Technology und Oxford ein Plug-and-Play-Klassifizierungsmodul vor
Technologie-Peripheriegeräte
KI
Mithilfe einer Codezeile, um die Wirkung von Zero-Shot-Lernmethoden erheblich zu verbessern, schlagen die Nanjing University of Technology und Oxford ein Plug-and-Play-Klassifizierungsmodul vor
Mithilfe einer Codezeile, um die Wirkung von Zero-Shot-Lernmethoden erheblich zu verbessern, schlagen die Nanjing University of Technology und Oxford ein Plug-and-Play-Klassifizierungsmodul vor

Zero-Shot Learning konzentriert sich auf die Klassifizierung von Kategorien, die während des Trainingsprozesses nicht aufgetreten sind. Zero-Shot-Learning basierend auf semantischer Beschreibung realisiert die Klassifizierung von sichtbaren Klassen (Wissenstransfer von gesehenen Klassen zu unsichtbaren Klassen). Beim herkömmlichen Zero-Shot-Lernen müssen in der Testphase nur unsichtbare Klassen identifiziert werden, während beim verallgemeinerten Zero-Shot-Lernen (GZSL) sowohl sichtbare als auch unsichtbare Klassen identifiziert werden müssen. Seine Bewertungsindikatoren sind die durchschnittliche Genauigkeit sichtbarer Klassen und die durchschnittliche Genauigkeit unsichtbarer Klassen Klassen. Harmonischer Durchschnitt der Genauigkeit.
Eine allgemeine Zero-Shot-Lernstrategie besteht darin, sichtbare Klassenproben und Semantik zu verwenden, um ein bedingtes Generierungsmodell vom semantischen Raum zum visuellen Probenraum zu trainieren, dann unsichtbare Klassensemantik zu verwenden, um Pseudoproben unsichtbarer Klassen zu generieren, und schließlich sichtbare Klassen zu verwenden Klassen Stichproben und Pseudostichproben unsichtbarer Klassen werden zum Trainieren des Klassifizierungsnetzwerks verwendet. Das Erlernen einer guten Zuordnungsbeziehung zwischen zwei Modalitäten (semantische Modalität und visuelle Modalität) erfordert jedoch normalerweise eine große Anzahl von Beispielen (siehe CLIP), was in einer herkömmlichen Zero-Shot-Lernumgebung nicht erreicht werden kann. Daher weicht die visuelle Stichprobenverteilung, die mithilfe der Semantik unsichtbarer Klassen generiert wird, normalerweise von der tatsächlichen Stichprobenverteilung ab, was die folgenden zwei Punkte bedeutet: 1. Die mit dieser Methode erzielte Genauigkeit unsichtbarer Klassen ist begrenzt. 2. Wenn die durchschnittliche Anzahl der pro Klasse generierten Pseudoproben für unsichtbare Klassen der durchschnittlichen Anzahl der Proben für jede Klasse für sichtbare Klassen entspricht, besteht ein großer Unterschied zwischen der Genauigkeit unsichtbarer Klassen und der Genauigkeit sichtbarer Klassen siehe Tabelle 1 unten.

Wir haben festgestellt, dass selbst wenn wir nur die Zuordnung der Semantik zu Kategoriemittelpunkten lernen und den einzelnen Beispielpunkt, dem die unsichtbare Klassensemantik zugeordnet wird, mehrmals kopieren und dann am Klassifikatortraining teilnehmen, Wir können dem generativen Modelleffekt nahe kommen. Dies bedeutet, dass die vom generativen Modell generierten unsichtbaren Pseudo-Stichprobenmerkmale für den Klassifikator relativ homogen sind.
Frühere Methoden berücksichtigen normalerweise die GZSL-Bewertungsmetrik, indem sie eine große Anzahl unsichtbarer Klassen-Pseudostichproben generieren (obwohl eine große Anzahl von Stichproben für die Unterscheidung unsichtbarer Klassen zwischen Klassen nicht hilfreich ist). Es hat sich jedoch gezeigt, dass diese Resampling-Strategie im Bereich des Long-Tail-Lernens dazu führt, dass der Klassifikator bei einigen Merkmalen überpasst, was pseudo-unsichtbar ist und von den tatsächlichen Klassenmerkmalen abweicht. Diese Situation ist der Identifizierung realer Stichproben sichtbarer und unsichtbarer Klassen nicht förderlich. Können wir diese Resampling-Strategie aufgeben und stattdessen den Versatz und die Homogenität der Generierung von Pseudo-Stichproben unsichtbarer Klassen (oder das Klassenungleichgewicht zwischen gesehenen Klassen und unsichtbaren Klassen) als induktive Verzerrung nutzen? Was ist mit dem Klassifikatorlernen?
Auf dieser Grundlage haben wir ein Plug-and-Play-Klassifikatormodul vorgeschlagen, das die Wirkung der generativen Zero-Shot-Lernmethode verbessern kann, indem nur eine Codezeile geändert wird. Für jede unsichtbare Klasse werden nur 10 Pseudo-Samples generiert, um das SOTA-Level zu erreichen. Im Vergleich zu anderen generativen Zero-Sample-Methoden weist die neue Methode einen enormen Vorteil hinsichtlich der Rechenkomplexität auf. Forschungsmitglieder kommen von der Nanjing University of Science and Technology und der Oxford University.

- Papier: https://arxiv.org/abs/2204.11822
- Code: https://github.com/cdb342/IJCAI-2022-Z LA
Dieser Artikel verwendet die konsistenten Trainings- und Testziele als Leitfaden zur Ableitung der Variationsuntergrenze des verallgemeinerten Zero-Shot-Lernbewertungsindex. Der auf diese Weise modellierte Klassifikator kann die Verwendung der Wiederannahmestrategie vermeiden und verhindern, dass der Klassifikator eine Überanpassung an die generierten Pseudoproben durchführt und die Erkennung realer Proben beeinträchtigt. Die vorgeschlagene Methode kann den einbettungsbasierten Klassifikator im Rahmen der generativen Methode wirksam machen und die Abhängigkeit des Klassifikators von der Qualität der generierten Pseudoproben verringern.
Methode
1. Einführung des parametrisierten Priors
Wir haben beschlossen, mit der Verlustfunktion des Klassifikators zu beginnen. Unter der Annahme, dass der Klassenraum durch generierte Pseudostichproben unsichtbarer Klassen vervollständigt wurde, wird der vorherige Klassifikator mit dem Ziel optimiert, die globale Genauigkeit zu maximieren:
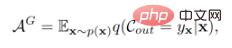

wobei  die globale Genauigkeit ist,
die globale Genauigkeit ist,  die Klassifikatorausgabe darstellt,
die Klassifikatorausgabe darstellt,  die Probenverteilung darstellt,
die Probenverteilung darstellt,  die entsprechende Bezeichnung von Probe X ist. Die Bewertungsindikatoren von GZSL sind:
die entsprechende Bezeichnung von Probe X ist. Die Bewertungsindikatoren von GZSL sind:
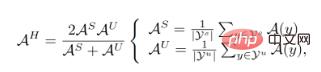

, wobei  und
und  die sichtbaren bzw. unsichtbaren Klassensätze darstellen. Die Inkonsistenz zwischen Trainingszielen und Testzielen bedeutet, dass frühere Klassifikator-Trainingsstrategien die Unterschiede zwischen sichtbaren und unsichtbaren Klassen nicht berücksichtigten. Selbstverständlich versuchen wir durch die Ableitung von
die sichtbaren bzw. unsichtbaren Klassensätze darstellen. Die Inkonsistenz zwischen Trainingszielen und Testzielen bedeutet, dass frühere Klassifikator-Trainingsstrategien die Unterschiede zwischen sichtbaren und unsichtbaren Klassen nicht berücksichtigten. Selbstverständlich versuchen wir durch die Ableitung von  Ergebnisse zu erzielen, die den Trainings- und Testzielen entsprechen. Nach der Ableitung erhielten wir seine Untergrenze:
Ergebnisse zu erzielen, die den Trainings- und Testzielen entsprechen. Nach der Ableitung erhielten wir seine Untergrenze:

wobei  die sichtbare Klasse darstellt – die unsichtbare vorherige Klasse, die unabhängig von den Daten ist und im Experiment als Hyperparameter angepasst wird,
die sichtbare Klasse darstellt – die unsichtbare vorherige Klasse, die unabhängig von den Daten ist und im Experiment als Hyperparameter angepasst wird,  Die sichtbare Klasse oder der interne Prior der unsichtbaren Klasse wird während des Implementierungsprozesses durch die Stichprobenhäufigkeit oder gleichmäßige Verteilung der gesehenen Klasse ersetzt. Durch Maximieren der Untergrenze von
Die sichtbare Klasse oder der interne Prior der unsichtbaren Klasse wird während des Implementierungsprozesses durch die Stichprobenhäufigkeit oder gleichmäßige Verteilung der gesehenen Klasse ersetzt. Durch Maximieren der Untergrenze von  erhalten wir das endgültige Optimierungsziel:
erhalten wir das endgültige Optimierungsziel:

Daraus ergibt sich für unser Klassifizierungsmodellierungsziel die folgenden Änderungen gegenüber dem vorherigen:

Durch die Verwendung Die Kreuzentropie passt zur A-posteriori-Wahrscheinlichkeit  , und wir erhalten den Klassifikatorverlust als:
, und wir erhalten den Klassifikatorverlust als:

Dies ähnelt der Logit-Anpassung beim Long-Tail-Lernen, daher nennen wir es Zero-Sample Logit Adjustment (ZLA). Bisher haben wir die Einführung parametrisierter Priors implementiert, um das Kategorieungleichgewicht zwischen sichtbaren und unsichtbaren Klassen als induktive Verzerrung in das Klassifikatortraining einzubetten, und müssen lediglich zusätzliche Bias-Terme zu den ursprünglichen Logits in der Code-Implementierung hinzufügen Effekte.

2. Einführung des semantischen Priors
Bisher spielt der Kern des Zero-Shot-Transfers, also der semantische Prior, nur eine Rolle beim Training des Generators und bei der Generierung von Pseudoproben hängt ausschließlich von der Qualität der generierten Pseudo-Samples unsichtbarer Klassen ab. Wenn in der Trainingsphase des Klassifikators semantische Prioritäten eingeführt werden können, hilft dies natürlich dabei, unsichtbare Klassen zu identifizieren. Im Bereich des Zero-Shot-Lernens gibt es eine Klasse einbettungsbasierter Methoden, die diese Funktion erreichen können. Diese Art von Methode ähnelt jedoch dem durch das generative Modell erlernten Wissen, also der Verbindung zwischen Semantik und Vision (semantisch-visuelle Verknüpfung), die zur direkten Einführung des vorherigen generativen Rahmens führte (siehe Artikel f -CLSWGAN) basierend auf Der eingebettete Klassifikator kann keine besseren Ergebnisse als das Original erzielen (es sei denn, der Klassifikator selbst weist eine bessere Nullschussleistung auf). Durch die in diesem Artikel vorgeschlagene ZLA-Strategie können wir die Rolle ändern, die die generierten Pseudoproben unsichtbarer Klassen beim Klassifikatortraining spielen. Von der ursprünglichen Bereitstellung unsichtbarer Klasseninformationen bis hin zur aktuellen Anpassung der Entscheidungsgrenze zwischen unsichtbaren und sichtbaren Klassen können wir in der Trainingsphase des Klassifikators semantische Prioritäten einführen. Insbesondere verwenden wir eine Prototyp-Lernmethode, um die Semantik jeder Kategorie in einen visuellen Prototyp (d. h. Klassifikatorgewicht) abzubilden und modellieren dann die angepasste A-Posteriori-Wahrscheinlichkeit als Kosinusähnlichkeit zwischen der Stichprobe und dem visuellen Prototyp (Grad der Kosinusähnlichkeit). , das heißt

wobei  der Temperaturkoeffizient ist. In der Testphase wird vorhergesagt, dass die Proben der Kategorie des visuellen Prototyps mit der größten Kosinusähnlichkeit entsprechen.
der Temperaturkoeffizient ist. In der Testphase wird vorhergesagt, dass die Proben der Kategorie des visuellen Prototyps mit der größten Kosinusähnlichkeit entsprechen.

Experimente
Wir haben den vorgeschlagenen Klassifikator mit dem Basis-WGAN kombiniert und bei der Generierung von 10 Proben pro unsichtbarer Klasse mit SoTAs vergleichbare Ergebnisse erzielt. Darüber hinaus haben wir es in die fortschrittlichere CE-GZSL-Methode eingefügt und so den anfänglichen Effekt verbessert, ohne andere Parameter (einschließlich der Anzahl der generierten Proben) zu ändern.

In Ablationsexperimenten haben wir einen generationsbasierten Prototyp-Lernenden mit einem reinen Prototyp-Lernenden verglichen. Wir haben herausgefunden, dass die letzte ReLU-Schicht für den Erfolg eines reinen Prototyp-Lerners von entscheidender Bedeutung ist, da das Nullen negativer Zahlen die Ähnlichkeit des Kategorieprototyps mit unsichtbaren Klassenmerkmalen erhöht (unsichtbare Klassenmerkmale werden ebenfalls durch ReLU aktiviert). Das Setzen einiger Werte auf Null schränkt jedoch auch den Ausdruck des Prototyps ein, was der weiteren Erkennungsleistung nicht förderlich ist. Durch die Verwendung pseudounsichtbarer Klassenbeispiele zum Ausgleich unsichtbarer Klasseninformationen kann bei Verwendung von RuLU nicht nur eine höhere Leistung erzielt werden, sondern auch ohne eine ReLU-Schicht eine weitere Leistungssteigerung erreicht werden.

In einer anderen Ablationsstudie haben wir einen Prototyp-Lerner mit einem anfänglichen Klassifikator verglichen. Die Ergebnisse zeigen, dass der Prototyp-Lerner beim Generieren einer großen Anzahl unsichtbarer Klassenstichproben keinen Vorteil gegenüber dem ursprünglichen Klassifikator hat. Bei Verwendung der in diesem Artikel vorgeschlagenen ZLA-Technologie zeigt der Prototyp-Lerner seine Überlegenheit. Wie bereits erwähnt, liegt dies daran, dass sowohl der prototypische Lernende als auch das generative Modell semantisch-visuelle Zusammenhänge lernen, sodass es schwierig ist, die semantischen Informationen vollständig zu nutzen. ZLA ermöglicht es den generierten unsichtbaren Klassenbeispielen, die Entscheidungsgrenze anzupassen, anstatt nur unsichtbare Klasseninformationen bereitzustellen, wodurch der prototypische Lernende aktiviert wird.

Das obige ist der detaillierte Inhalt vonMithilfe einer Codezeile, um die Wirkung von Zero-Shot-Lernmethoden erheblich zu verbessern, schlagen die Nanjing University of Technology und Oxford ein Plug-and-Play-Klassifizierungsmodul vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1660
1660
 14
1416
52
1311
25
1261
29
1234
24
14
1416
52
1311
25
1261
29
1234
24

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
