

Erstellen von Textgeneratoren mithilfe von Markov-Ketten

In diesem Artikel stellen wir ein beliebtes Projekt für maschinelles Lernen vor – den Textgenerator. Sie erfahren, wie Sie einen Textgenerator erstellen und wie Sie eine Markov-Kette implementieren, um ein schnelleres Vorhersagemodell zu erhalten.

Einführung in Textgeneratoren
Die Textgenerierung ist in verschiedenen Branchen beliebt, insbesondere in den Bereichen Mobilgeräte, Apps und Datenwissenschaft. Sogar die Presse nutzt die Textgenerierung, um den Schreibprozess zu unterstützen.
Im täglichen Leben sind wir mit einigen Textgenerierungstechnologien konfrontiert. Textvervollständigung, Suchvorschläge, Smart Compose und Chatbots sind alles Beispiele für Anwendungen.
In diesem Artikel wird die Markov-Kette zum Erstellen eines Textgenerators verwendet. Dies wäre ein zeichenbasiertes Modell, das das vorherige Zeichen der Kette übernimmt und den nächsten Buchstaben in der Sequenz generiert.
Durch das Trainieren unseres Programms anhand von Beispielwörtern lernt der Textgenerator gängige Zeichenreihenfolgemuster. Der Textgenerator wendet diese Muster dann auf die Eingabe an, bei der es sich um ein unvollständiges Wort handelt, und gibt das Zeichen aus, das mit der höchsten Wahrscheinlichkeit das Wort vervollständigt.
Die Textgenerierung ist ein Zweig der Verarbeitung natürlicher Sprache, der das nächste Zeichen basierend auf zuvor beobachteten Sprachmustern vorhersagt und generiert.
Vor dem maschinellen Lernen führte NLP die Textgenerierung durch, indem es eine Tabelle mit allen Wörtern in der englischen Sprache erstellte und die übergebene Zeichenfolge mit vorhandenen Wörtern abgleichte. Bei diesem Ansatz gibt es zwei Probleme.
- Das Durchsuchen Tausender Wörter wird sehr langsam sein.
- Der Generator kann nur Wörter vervollständigen, die er zuvor gesehen hat.
Das Aufkommen von maschinellem Lernen und tiefem Lernen (NLP) ermöglicht es uns, die Laufzeit drastisch zu verkürzen und die Allgemeingültigkeit zu erhöhen, da der Generator Wörter vervollständigen kann, auf die er noch nie zuvor gestoßen ist. NLP kann auf Wunsch erweitert werden, um Wörter, Phrasen oder Sätze vorherzusagen.
Für dieses Projekt verwenden wir ausschließlich Markov-Ketten. Markov-Prozesse sind die Grundlage vieler Projekte zur Verarbeitung natürlicher Sprache, bei denen es um geschriebene Sprache und die Simulation von Beispielen aus komplexen Verteilungen geht.
Markov-Prozesse sind so leistungsstark, dass sie dazu verwendet werden können, mit nur einem Beispieldokument scheinbar real aussehenden Text zu generieren.
Was ist eine Markov-Kette?
Eine Markov-Kette ist ein stochastischer Prozess, der eine Abfolge von Ereignissen modelliert, bei der die Wahrscheinlichkeit jedes Ereignisses vom Zustand des vorherigen Ereignisses abhängt. Das Modell verfügt über eine endliche Menge von Zuständen und die bedingte Wahrscheinlichkeit, von einem Zustand in einen anderen zu wechseln, ist fest.
Die Wahrscheinlichkeit jedes Übergangs hängt nur vom vorherigen Zustand des Modells ab, nicht vom gesamten Ereignisverlauf.
Angenommen, Sie möchten ein Markov-Kettenmodell erstellen, um das Wetter vorherzusagen.
In diesem Modell haben wir zwei Zustände, sonnig oder regnerisch. Wenn wir heute einen sonnigen Tag haben, ist die Wahrscheinlichkeit (70 %) höher, dass es morgen sonnig sein wird. Das Gleiche gilt für Regen; wenn es bereits geregnet hat, wird es wahrscheinlich weiter regnen.
Aber es ist möglich (30 %), dass sich das Wetter ändert, deshalb beziehen wir dies auch in unser Markov-Kettenmodell ein.
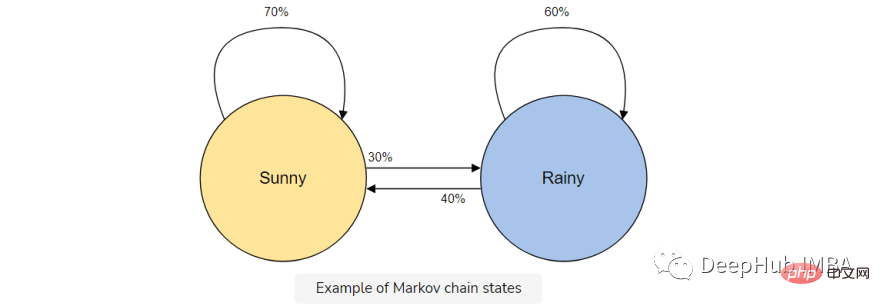
Die Markov-Kette ist das perfekte Modell für unseren Textgenerator, da unser Modell das nächste Zeichen nur anhand des vorherigen Zeichens vorhersagt. Die Vorteile der Verwendung einer Markov-Kette bestehen darin, dass sie genau ist, weniger Speicher benötigt (es wird nur ein vorheriger Zustand gespeichert) und schnell ausgeführt werden kann.
Implementierung der Textgenerierung
Hier vervollständigen wir den Textgenerator in 6 Schritten:
- Nachschlagetabelle erstellen: Erstellen Sie eine Tabelle zur Aufzeichnung der Worthäufigkeit
- Häufigkeiten in Wahrscheinlichkeiten umwandeln: Wandeln Sie unsere Erkenntnisse in eine verwendbare Form um
- Laden den Datensatz: Laden und nutzen Sie einen Trainingssatz.
- Erstellen Sie eine Markov-Kette: Verwenden Sie Wahrscheinlichkeiten, um Ketten für jedes Wort und Zeichen zu erstellen.
- Abtasten Sie die Daten: Erstellen Sie eine Funktion, um verschiedene Teile des Korpus abzutasten.
- Text generieren: Testen Sie unser Modell

1. Nachschlagetabelle erstellen
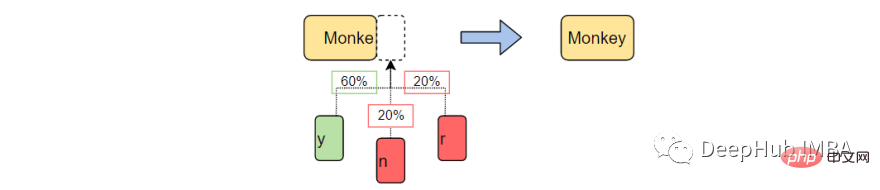
Zunächst erstellen wir eine Tabelle, um das Auftreten jedes Zeichenzustands im Trainingskorpus aufzuzeichnen. Speichern Sie die letzten „K“-Zeichen und „K+1“-Zeichen aus dem Trainingskorpus und speichern Sie sie in einer Nachschlagetabelle.
Stellen Sie sich zum Beispiel vor, dass unser Schulungskorpus Folgendes enthält: „Der Mann war, sie, dann, der, der“. Dann beträgt die Häufigkeit des Vorkommens des Wortes:
- "the" — 3
- "then" — 1
- "they" — 1
- "man" — 1
Das Folgende sind die Ergebnisse der Suche Tisch:

Im obigen Beispiel nehmen wir K = 3, was bedeutet, dass 3 Zeichen gleichzeitig berücksichtigt werden und das nächste Zeichen (K+1) als Ausgabezeichen verwendet wird. Behandeln Sie das Wort (X) als Zeichen in der obigen Nachschlagetabelle und das Ausgabezeichen (Y) als einzelnes Leerzeichen („“), da nach dem ersten kein Wort steht. Außerdem wird berechnet, wie oft diese Sequenz im Datensatz vorkommt, in diesem Fall dreimal.
Auf diese Weise werden Daten für jedes Wort im Korpus generiert, d. h. alle möglichen X- und Y-Paare werden generiert.
So generieren wir die Nachschlagetabelle im Code:
def generateTable(data,k=4):
T = {}
for i in range(len(data)-k):
X = data[i:i+k]
Y = data[i+k]
#print("X %s and Y %s "%(X,Y))
if T.get(X) is None:
T[X] = {}
T[X][Y] = 1
else:
if T[X].get(Y) is None:
T[X][Y] = 1
else:
T[X][Y] += 1
return T
T = generateTable("hello hello helli")
print(T)
#{'llo ': {'h': 2}, 'ello': {' ': 2}, 'o he': {'l': 2}, 'lo h': {'e': 2}, 'hell': {'i': 1, 'o': 2}, ' hel': {'l': 2}}Einfache Erklärung des Codes:
In Zeile 3 wird ein Wörterbuch erstellt, das X und die entsprechenden Y- und Häufigkeitswerte speichert. Die Zeilen 9 bis 17 prüfen, ob X und Y vorkommen. Wenn im Nachschlagewörterbuch bereits ein X- und Y-Paar vorhanden ist, erhöhen Sie es einfach um 1.
2. Häufigkeit in Wahrscheinlichkeit umrechnen
Sobald wir diese Tabelle und die Anzahl der Vorkommen haben, können wir die Wahrscheinlichkeit für das Auftreten von Y nach einem bestimmten Vorkommen von x ermitteln. Die Formel lautet:
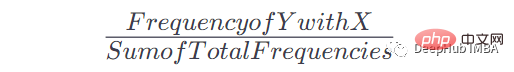
Wenn beispielsweise Wenden Sie diese Formel an, um die Nachschlagetabelle in eine nutzbare Wahrscheinlichkeit der Markov-Kette umzuwandeln:
def convertFreqIntoProb(T):
for kx in T.keys():
s = float(sum(T[kx].values()))
for k in T[kx].keys():
T[kx][k] = T[kx][k]/s
return T
T = convertFreqIntoProb(T)
print(T)
#{'llo ': {'h': 1.0}, 'ello': {' ': 1.0}, 'o he': {'l': 1.0}, 'lo h': {'e': 1.0}, 'hell': {'i': 0.3333333333333333, 'o': 0.6666666666666666}, ' hel': {'l': 1.0}}Einfache Erklärung:
Summieren Sie die Häufigkeitswerte eines bestimmten Schlüssels und dividieren Sie dann jeden Häufigkeitswert für diesen Schlüssel durch diesen Mehrwert, um die zu erhalten Wahrscheinlichkeit.
3. Laden Sie den Datensatz
Als nächstes wird der eigentliche Trainingskorpus geladen. Sie können jedes gewünschte Langtextdokument (.txt) verwenden.
Der Einfachheit halber wird eine politische Rede verwendet, um genügend Vokabular für die Vermittlung unseres Modells bereitzustellen.
text_path = "train_corpus.txt"
def load_text(filename):
with open(filename,encoding='utf8') as f:
return f.read().lower()
text = load_text(text_path)
print('Loaded the dataset.')Dieser Datensatz kann für unser Beispielprojekt genügend Ereignisse bereitstellen, um einigermaßen genaue Vorhersagen zu treffen. Wie bei jedem maschinellen Lernen führt ein größerer Trainingskorpus zu genaueren Vorhersagen.
4. Erstellen Sie eine Markov-Kette
Lassen Sie uns eine Markov-Kette erstellen und jedem Zeichen die Wahrscheinlichkeit zuordnen. Die in den Schritten 1 und 2 erstellten Funktionen „generateTable()“ und „convertFreqIntoProb()“ werden hier zum Erstellen des Markov-Modells verwendet.
def MarkovChain(text,k=4): T = generateTable(text,k) T = convertFreqIntoProb(T) return T model = MarkovChain(text)
Zeile 1 erstellt eine Methode zum Generieren eines Markov-Modells. Die Methode akzeptiert einen Textkorpus und einen K-Wert. Dies ist der Wert, der das Markov-Modell anweist, K Zeichen zu berücksichtigen und das nächste Zeichen vorherzusagen. In Zeile 2 wird die Nachschlagetabelle generiert, indem der Methode genericTable(), die wir im vorherigen Abschnitt erstellt haben, der Textkorpus und K zur Verfügung gestellt werden. Zeile 3 wandelt die Häufigkeit mithilfe der Methode „convertFreqIntoProb()“, die wir ebenfalls in der vorherigen Lektion erstellt haben, in einen Wahrscheinlichkeitswert um.
5. Text-Sampling
Erstellen Sie eine Sampling-Funktion, die das unvollendete Wort (ctx), das Markov-Kettenmodell (Modell) aus Schritt 4 und die Anzahl der Zeichen verwendet, die zur Bildung der Wortbasis (k) verwendet werden.
Wir werden diese Funktion verwenden, um den übergebenen Kontext abzutasten, das nächstmögliche Zeichen zurückzugeben und die Wahrscheinlichkeit zu bestimmen, dass es das richtige Zeichen ist.
import numpy as np
def sample_next(ctx,model,k):
ctx = ctx[-k:]
if model.get(ctx) is None:
return " "
possible_Chars = list(model[ctx].keys())
possible_values = list(model[ctx].values())
print(possible_Chars)
print(possible_values)
return np.random.choice(possible_Chars,p=possible_values)
sample_next("commo",model,4)
#['n']
#[1.0]Code-Erklärung:
Die Funktion sample_next akzeptiert drei Parameter: ctx, model und k-Wert.
ctx ist Text, der zum Generieren eines neuen Textes verwendet wird. Aber hier werden nur die letzten K Zeichen in ctx vom Modell verwendet, um das nächste Zeichen in der Sequenz vorherzusagen. Beispielsweise übergeben wir common, K = 4, und der Text, den das Modell zum Generieren des nächsten Zeichens verwendet, ist ommo, da das Markov-Modell nur den vorherigen Verlauf verwendet.
In den Zeilen 9 und 10 werden die möglichen Zeichen und ihre Wahrscheinlichkeitswerte abgedruckt, da diese Zeichen auch in unserem Modell vorhanden sind. Wir erhalten, dass das nächste vorhergesagte Zeichen n ist, mit einer Wahrscheinlichkeit von 1,0. Da es wahrscheinlicher ist, dass das Wort „commo“ häufiger vorkommt, nachdem das nächste Zeichen generiert wurde.
In Zeile 12 geben wir ein Zeichen zurück, das auf dem oben diskutierten Wahrscheinlichkeitswert basiert.
6. Text generieren
Kombinieren Sie abschließend alle oben genannten Funktionen, um Text zu generieren.
def generateText(starting_sent,k=4,maxLen=1000):
sentence = starting_sent
ctx = starting_sent[-k:]
for ix in range(maxLen):
next_prediction = sample_next(ctx,model,k)
sentence += next_prediction
ctx = sentence[-k:]
return sentence
print("Function Created Successfully!")
text = generateText("dear",k=4,maxLen=2000)
print(text)Die Ergebnisse sind wie folgt:
dear country brought new consciousness. i heartily great service of their lives, our country, many of tricoloring a color flag on their lives independence today.my devoted to be oppression of independence.these day the obc common many country, millions of oppression of massacrifice of indian whom everest. my dear country is not in the sevents went was demanding and nights by plowing in the message of the country is crossed, oppressed, women, to overcrowding for years of the south, it is like the ashok chakra of constitutional states crossed, deprived, oppressions of freedom, i bow my heart to proud of our country.my dear country, millions under to be a hundred years of the south, it is going their heroes.
Die obige Funktion akzeptiert drei Parameter: das Startwort des generierten Textes, den Wert von K und die maximale Zeichenlänge des erforderlichen Textes. Das Ausführen des Codes führt zu einem Text mit 2000 Zeichen, der mit „dear“ beginnt.
Obwohl diese Rede vielleicht nicht viel Sinn ergibt, sind die Wörter vollständig und ahmen oft bekannte Muster in Wörtern nach.
Was Sie als Nächstes lernen sollten
Dies ist ein einfaches Textgenerierungsprojekt. Nutzen Sie dieses Projekt, um zu erfahren, wie die Verarbeitung natürlicher Sprache und Markov-Ketten in Aktion funktionieren, was Sie auf Ihrer Deep-Learning-Reise nutzen können.
Dieser Artikel dient nur dazu, das experimentelle Projekt der Markov-Kette vorzustellen, da es in der tatsächlichen Anwendung keine Rolle spielt. Wenn Sie einen besseren Textgenerierungseffekt erzielen möchten, lernen Sie bitte Tools wie GPT-3 kennen.
Das obige ist der detaillierte Inhalt vonErstellen von Textgeneratoren mithilfe von Markov-Ketten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
