
 Technologie-Peripheriegeräte
KI
Web Speech API-Entwicklerhandbuch: Was es ist und wie es funktioniert
Technologie-Peripheriegeräte
KI
Web Speech API-Entwicklerhandbuch: Was es ist und wie es funktioniert
Web Speech API-Entwicklerhandbuch: Was es ist und wie es funktioniert

Übersetzer |. Li Rui Integrieren Sie Sprachdaten in Anwendungen. Es kann Sprache über den Browser in Text umwandeln und umgekehrt.
Web Speech API wurde 2012 von der W3C-Community eingeführt. Zehn Jahre später befindet sich diese API aufgrund eingeschränkter Browserkompatibilität immer noch in der Entwicklung. Die API unterstützt sowohl kurzfristige Eingabefragmente, wie z. B. einen verbalen Befehl, als auch langfristige kontinuierliche Eingaben. Umfangreiche Diktierfunktionen machen es ideal für die Integration mit Applause-Apps, während kurzes Tippen hervorragend für Sprachübersetzungen geeignet ist. Die Spracherkennung hat einen großen Einfluss auf die Barrierefreiheit gehabt. Benutzer mit Behinderungen können per Spracheingabe einfacher im Internet surfen. Daher könnte diese API der Schlüssel dazu sein, das Web benutzerfreundlicher und effizienter zu machen. Die Text-to-Speech- und Speech-to-Text-Funktionalität wird über zwei Schnittstellen verwaltet: Sprachsynthese und Spracherkennung. 1. Spracherkennung In der Spracherkennungsoberfläche spricht der Benutzer in das Mikrofon, und dann führt der Spracherkennungsdienst eine Grammatik durch Überprüfen Sie, was er gesagt hat. Die API schützt die Privatsphäre des Benutzers, indem sie zunächst die Erlaubnis anfordert, über das Mikrofon auf die Stimme des Benutzers zuzugreifen. Wenn die Seite, die die API nutzt, das HTTPS-Protokoll verwendet, wird die Erlaubnis nur einmal angefordert. Andernfalls fragt die API jeweils nach. Das Gerät des Benutzers verfügt möglicherweise bereits über ein Spracherkennungssystem, z. B. Siri für iOS oder Android-Stimmen. Bei Verwendung der Spracherkennungsschnittstelle wird das Standardsystem verwendet. Nachdem die Sprache erkannt wurde, wird sie konvertiert und als Textzeichenfolge zurückgegeben. Bei der „One-Shot“-Spracherkennung endet die Erkennung, sobald der Benutzer aufhört zu sprechen. Dies ist nützlich für kurze Befehle, z. B. das Durchsuchen des Internets nach einer Website zum Testen von Anwendungen oder das Tätigen eines Telefonanrufs. Bei der „kontinuierlichen“ Erkennung muss der Benutzer die Erkennung manuell über die Schaltfläche „Stopp“ beenden. Derzeit wird die Spracherkennung der Web Speech API offiziell nur von zwei Browsern unterstützt: Chrome für Desktop und Android. Chrome muss die Präfixschnittstelle verwenden. Allerdings befindet sich die Web Speech API noch im experimentellen Stadium und die Spezifikation kann sich ändern. Sie können überprüfen, ob der aktuelle Browser diese API unterstützt, indem Sie nach dem webkitSpeechRecognition-Objekt suchen. 2. Spracherkennungsattribute Lernen wir eine neue Funktion: Spracherkennung().var recognizer = new speechRecognition();
speechRecognition.continuous = true;
 Zusätzlich kann dem Benutzer erlaubt werden, die Sprache aus einem Menü auszuwählen:
Zusätzlich kann dem Benutzer erlaubt werden, die Sprache aus einem Menü auszuwählen:
speechRecognition.lang = document.querySelector("#select_dialect").value;(3 ) Zwischenergebnisse# 🎜🎜#
Zwischenergebnisse beziehen sich auf Ergebnisse, die noch nicht vollständig oder endgültig sind. Indem Sie diese Eigenschaft auf „true“ setzen, können Sie veranlassen, dass das Objekt temporäre Ergebnisse als Feedback für den Benutzer anzeigt: 🎜#Wenn das Spracherkennungsobjekt als „kontinuierlich“ konfiguriert wurde, müssen Sie die onClick-Attribute der Start- und Stoppschaltflächen festlegen wie folgt: JavaScript
speechRecognition.interimResults = true;
这将允许用户控制使用的浏览器何时开始“监听”,何时停止。
因此,在深入了解了语音识别界面、方法和属性之后。现在探索Web Speech API的另一面。
三、语音合成
语音合成也被称为文本到语音(TTS)。语音合成是指从应用程序中获取文本,将其转换成语音,然后从设备的扬声器中播放。
可以使用语音合成做任何事情,从驾驶指南到为在线课程朗读课堂笔记,再到视觉障碍用户的屏幕阅读。
在浏览器支持方面,从Gecko42+版本开始,Web Speech API的语音合成可以在Firefox桌面和移动端使用。但是,必须首先启用权限。Firefox OS2.5+默认支持语音合成;不需要权限。Chrome和Android 33+也支持语音合成。
那么,如何让浏览器说话呢?语音合成的主要控制器界面是SpeechSynthesis,但需要一些相关的界面,例如用于输出的声音。大多数操作系统都有默认的语音合成系统。
简单地说,用户需要首先创建一个SpeechSynthesisUtterance界面的实例。其界面包含服务将读取的文本,以及语言、音量、音高和速率等信息。指定这些之后,将实例放入一个队列中,该队列告诉浏览器应该说什么以及什么时候说。
将需要说话的文本指定给其“文本”属性,如下所示:
newUtterance.text =
除非使用.lang属性另有指定,否则语言将默认为应用程序或浏览器的语言。
在网站加载后,语音更改事件可以被触发。要改变浏览器的默认语音,可以使用语音合成中的getvoices()方法。这将显示所有可用的语音。
声音的种类取决于操作系统。谷歌和MacOSx一样有自己的默认声音集。最后,用户使用Array.find()方法选择喜欢的声音。
根据需要定制SpeechSynthesisUtterance。可以启动、停止和暂停队列,或更改通话速度(“速率”)。
四、Web Speech API的优点和缺点
什么时候应该使用Web Speech API?这种技术使用起来很有趣,但仍在发展中。尽管如此,还是有很多潜在的用例。集成API可以帮助实现IT基础设施的现代化,而用户可以了解Web Speech API哪些方面已经成熟可以改进。
1.提高生产力
对着麦克风说话比打字更快捷、更有效。在当今快节奏的工作生活中,人们可能需要能够在旅途中访问网页。
它还可以很好地减少管理工作量。语音到文本技术的改进有可能显著减少数据输入任务的时间。语音到文本技术可以集成到音频视频会议中,以加快会议的记录速度。
2.可访问性
如上所述,语音到文本(STT)和文本语音(TTS)对于有残疾或支持需求的用户来说都是很好的工具。此外,由于任何原因而在写作或拼写方面有困难的用户可以通过语音识别更好地表达自己。
这样,语音识别技术就可以成为互联网上一个很好的均衡器。鼓励在办公室使用这些工具也能促进工作场所的可访问性。
3.翻译
Web Speech API可以成为一种强大的语言翻译工具,因为它同时支持语音到文本(STT)和文本语音(TTS)。目前,并不是每一种语言都可用。这是Web Speech API尚未充分发挥其潜力的一个领域。
4.离线功能
一个缺点是API必须要有互联网连接才能正常工作。此时,浏览器将输入发送到它的服务器,然后服务器返回结果。这限制了Web Speech API可以使用的环境。
5.精确度
在提高语音识别器的准确性方面已经取得了令人难以置信的进展。用户可能偶尔还会遇到一些困难,例如技术术语和其他专业词汇或者方言。然而,到2022年,语音识别软件的精确度已经达到了人类的水平。
五、结语
虽然Web Speech API还处于实验阶段,但它可以成为网站或应用程序的一个惊人的补充。从科技公司到市场营销商,所有的工作场所都可以使用这个API来提高效率。只需几行简单的JavaScript代码,就可以打开一个全新的可访问性世界。
语音识别可以使用户更容易更有效地浏览网页,人们期待看到这项技术快速成长和发展!
原文链接:https://dzone.com/articles/the-developers-guide-to-web-speech-api-what-is-it
Das obige ist der detaillierte Inhalt vonWeb Speech API-Entwicklerhandbuch: Was es ist und wie es funktioniert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So erkennen Sie automatisch Sprache und generieren Untertitel in Filmausschnitten. Einführung in die Methode zur automatischen Generierung von Untertiteln
Mar 14, 2024 pm 08:10 PM
So erkennen Sie automatisch Sprache und generieren Untertitel in Filmausschnitten. Einführung in die Methode zur automatischen Generierung von Untertiteln
Mar 14, 2024 pm 08:10 PM
Wie implementieren wir die Funktion zur Generierung von Sprachuntertiteln auf dieser Plattform? Wenn wir einige Videos erstellen, müssen wir unsere Untertitel hinzufügen, um mehr Textur zu erhalten, oder wenn wir einige Geschichten erzählen, damit jeder die Informationen besser verstehen kann einige der Videos oben. Es spielt auch eine Rolle beim Ausdruck, aber viele Benutzer sind mit der automatischen Spracherkennung und der Untertitelgenerierung nicht sehr vertraut, wir können Sie in verschiedenen Aspekten problemlos dazu bringen, bessere Entscheidungen zu treffen Wir müssen einige funktionale Fähigkeiten langsam verstehen, also beeilen Sie sich und schauen Sie sich den Editor an, verpassen Sie es nicht.
 So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem. Einführung: Mit der kontinuierlichen Weiterentwicklung der Technologie ist die Spracherkennungstechnologie zu einem wichtigen Bestandteil des Bereichs der künstlichen Intelligenz geworden. Das auf WebSocket und JavaScript basierende Online-Spracherkennungssystem zeichnet sich durch geringe Latenz, Echtzeit und plattformübergreifende Eigenschaften aus und hat sich zu einer weit verbreiteten Lösung entwickelt. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem implementieren.
 Detaillierte Methode zum Deaktivieren der Spracherkennung im WIN10-System
Mar 27, 2024 pm 02:36 PM
Detaillierte Methode zum Deaktivieren der Spracherkennung im WIN10-System
Mar 27, 2024 pm 02:36 PM
1. Rufen Sie die Systemsteuerung auf, suchen Sie die Option [Spracherkennung] und schalten Sie sie ein. 2. Wenn die Spracherkennungsseite angezeigt wird, wählen Sie [Erweiterte Sprachoptionen]. 3. Deaktivieren Sie abschließend das Kontrollkästchen [Spracherkennung beim Start ausführen] in der Spalte „Benutzereinstellungen“ im Fenster „Spracheigenschaften“.
 Probleme mit der Audioqualität bei der Spracherkennung
Oct 08, 2023 am 08:28 AM
Probleme mit der Audioqualität bei der Spracherkennung
Oct 08, 2023 am 08:28 AM
Probleme mit der Audioqualität bei der Spracherkennung erfordern spezifische Codebeispiele. Mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz wurde die Spracherkennung (Automatic Speech Recognition, kurz ASR) in großem Umfang eingesetzt und erforscht. In praktischen Anwendungen treten jedoch häufig Probleme mit der Audioqualität auf, die sich direkt auf die Genauigkeit und Leistung des ASR-Algorithmus auswirken. Dieser Artikel konzentriert sich auf Audioqualitätsprobleme bei der Spracherkennung und gibt spezifische Codebeispiele. Audioqualität für Sprachausgabe
 Problem der Sprechervariation bei der Sprachgeschlechtserkennung
Oct 08, 2023 pm 02:22 PM
Problem der Sprechervariation bei der Sprachgeschlechtserkennung
Oct 08, 2023 pm 02:22 PM
Das Problem der Sprechervariation bei der Stimmgeschlechtserkennung erfordert spezifische Codebeispiele. Mit der rasanten Entwicklung der Sprachtechnologie ist die Stimmgeschlechtserkennung zu einem immer wichtigeren Bereich geworden. Es wird häufig in vielen Anwendungsszenarien eingesetzt, z. B. im telefonischen Kundenservice, bei Sprachassistenten usw. Bei der Sprachgeschlechtserkennung stoßen wir jedoch häufig auf eine Herausforderung, nämlich die Sprechervariabilität. Unter Sprechervariation versteht man Unterschiede in den phonetischen Eigenschaften der Stimmen verschiedener Personen. Denn individuelle Stimmeigenschaften werden von vielen Faktoren beeinflusst, wie zum Beispiel Geschlecht, Alter, Stimme usw.
 so schnell! Erkennen Sie Videosprache in nur wenigen Minuten mit weniger als 10 Codezeilen in Text
Feb 27, 2024 pm 01:55 PM
so schnell! Erkennen Sie Videosprache in nur wenigen Minuten mit weniger als 10 Codezeilen in Text
Feb 27, 2024 pm 01:55 PM
Hallo zusammen, ich bin Kite. Die Notwendigkeit, Audio- und Videodateien in Textinhalte umzuwandeln, war vor zwei Jahren schwierig, aber jetzt kann dies problemlos in nur wenigen Minuten gelöst werden. Es heißt, dass einige Unternehmen, um Trainingsdaten zu erhalten, Videos auf Kurzvideoplattformen wie Douyin und Kuaishou vollständig gecrawlt haben, dann den Ton aus den Videos extrahiert und sie in Textform umgewandelt haben, um sie als Trainingskorpus für Big-Data-Modelle zu verwenden . Wenn Sie eine Video- oder Audiodatei in Text konvertieren müssen, können Sie diese heute verfügbare Open-Source-Lösung ausprobieren. Sie können beispielsweise nach bestimmten Zeitpunkten suchen, zu denen Dialoge in Film- und Fernsehsendungen erscheinen. Kommen wir ohne weitere Umschweife zum Punkt. Whisper ist OpenAIs Open-Source-Whisper. Es ist natürlich in Python geschrieben und erfordert nur ein paar einfache Installationspakete.
 Verwenden Sie die Go-Sprache, um leistungsstarke Spracherkennungsanwendungen zu entwickeln und zu implementieren
Nov 20, 2023 am 08:11 AM
Verwenden Sie die Go-Sprache, um leistungsstarke Spracherkennungsanwendungen zu entwickeln und zu implementieren
Nov 20, 2023 am 08:11 AM
Mit der kontinuierlichen Weiterentwicklung von Wissenschaft und Technologie hat auch die Spracherkennungstechnologie große Fortschritte und Anwendungen gemacht. Spracherkennungsanwendungen werden häufig in Sprachassistenten, intelligenten Lautsprechern, virtueller Realität und anderen Bereichen eingesetzt und bieten Menschen eine bequemere und intelligentere Art der Interaktion. Wie leistungsstarke Spracherkennungsanwendungen implementiert werden können, ist zu einer Frage geworden, die es wert ist, untersucht zu werden. In den letzten Jahren hat die Go-Sprache als leistungsstarke Programmiersprache große Aufmerksamkeit bei der Entwicklung von Spracherkennungsanwendungen auf sich gezogen. Die Go-Sprache zeichnet sich durch hohe Parallelität, präzises Schreiben und schnelle Ausführungsgeschwindigkeit aus. Sie eignet sich sehr gut für den Aufbau hoher Leistung
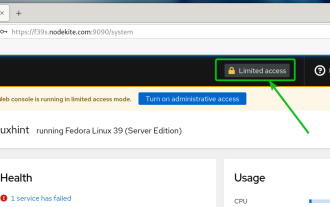 So aktivieren Sie den administrativen Zugriff über die Cockpit-Web-Benutzeroberfläche
Mar 20, 2024 pm 06:56 PM
So aktivieren Sie den administrativen Zugriff über die Cockpit-Web-Benutzeroberfläche
Mar 20, 2024 pm 06:56 PM
Cockpit ist eine webbasierte grafische Oberfläche für Linux-Server. Es soll vor allem neuen/erfahrenen Benutzern die Verwaltung von Linux-Servern erleichtern. In diesem Artikel besprechen wir die Cockpit-Zugriffsmodi und wie Sie den Administratorzugriff von CockpitWebUI auf das Cockpit umstellen. Inhaltsthemen: Cockpit-Eingabemodi Ermitteln des aktuellen Cockpit-Zugriffsmodus Aktivieren des Verwaltungszugriffs für das Cockpit über CockpitWebUI Deaktivieren des Verwaltungszugriffs für das Cockpit über CockpitWebUI Fazit Cockpit-Eingabemodi Das Cockpit verfügt über zwei Zugriffsmodi: Eingeschränkter Zugriff: Dies ist die Standardeinstellung für den Cockpit-Zugriffsmodus. In diesem Zugriffsmodus können Sie vom Cockpit aus nicht auf den Webbenutzer zugreifen
