

GPT-3: Künstliche Intelligenz, die schreiben kann

Übersetzer |. Sun Shujuan# 🎜 🎜#
EröffnungskapitelKünstliche Intelligenz (KI) befindet sich zwar noch in einem frühen Entwicklungsstadium, hat aber das Potenzial, den Menschen zu revolutionieren Interaktion mit der Technologie.
Einführung in die Künstliche IntelligenzWenn es um künstliche Intelligenz geht, gibt es derzeit hauptsächlich zwei Ansichten. Einige glauben, dass KI irgendwann die menschliche Intelligenz übertreffen wird, während andere glauben, dass KI immer der Menschheit dienen wird. In einem sind sich beide Seiten einig: Künstliche Intelligenz entwickelt sich immer schneller. Künstliche Intelligenz (KI) befindet sich noch in einem frühen Entwicklungsstadium, hat aber das Potenzial, die Art und Weise, wie Menschen mit Technologie interagieren, zu revolutionieren.
Eine einfache, allgemeine Beschreibung ist, dass künstliche Intelligenz der Prozess ist, bei dem Computer so programmiert werden, dass sie selbstständig Entscheidungen treffen. Dies kann auf verschiedene Weise erreicht werden, am häufigsten jedoch durch den Einsatz von Algorithmen. Ein Algorithmus ist eine Reihe von Regeln oder Anweisungen, die zur Lösung eines Problems befolgt werden können. Bei der künstlichen Intelligenz werden Algorithmen eingesetzt, um Computern das Treffen von Entscheidungen beizubringen.
In der Vergangenheit wurde künstliche Intelligenz hauptsächlich für einfache Aufgaben wie Schachspielen oder das Lösen mathematischer Probleme eingesetzt. Mittlerweile wird künstliche Intelligenz für komplexere Aufgaben wie Gesichtserkennung, Verarbeitung natürlicher Sprache und sogar autonomes Fahren eingesetzt. Da sich künstliche Intelligenz weiterentwickelt, wissen wir nicht, welche Fähigkeiten sie in Zukunft haben wird. Da die KI-Fähigkeiten schnell wachsen, ist es wichtig zu verstehen, was sie ist, wie sie funktioniert und welche potenziellen Auswirkungen sie hat.
Die Vorteile, die künstliche Intelligenz mit sich bringt, sind enorm. Mit der Fähigkeit, selbstständig Entscheidungen zu treffen, hat KI das Potenzial, unzählige Branchen effizienter zu machen und Chancen für alle Arten von Menschen zu bieten. In diesem Artikel werden wir über GPT-3 sprechen.
Was ist GPT-3 und wo kommt es her?GPT-3 wurde von OpenAI entwickelt, einem bahnbrechenden KI-Forschungsunternehmen mit Sitz in San Francisco. Sie definieren ihr Ziel als „sicherzustellen, dass künstliche Intelligenz der gesamten Menschheit zugute kommt“. Ihre Vision für die Schaffung künstlicher Intelligenz ist klar: eine künstliche Intelligenz, die nicht auf spezielle Aufgaben beschränkt ist, sondern wie Menschen vielfältige Aufgaben übernehmen kann.
Vor einigen Monaten hat das Unternehmen OpenAI sein neues Sprachmodell namens GPT-3 für alle Benutzer freigegeben. GPT-3 ist die Abkürzung für Generative Pretrained Transformer 3, die die Möglichkeit beinhaltet, Text über eine Prämisse namens Prompt zu generieren. Einfach ausgedrückt verfügt es über umfassende Funktionen zur automatischen Vervollständigung. Sie müssen beispielsweise nur zwei oder drei Sätze zu einem bestimmten Thema bereitstellen, den Rest erledigt GPT-3. Sie können auch Konversationen generieren und die von GPT-3 gegebenen Antworten basieren auf dem Kontext früherer Fragen und Antworten.
Es sollte betont werden, dass jede von GPT-3 bereitgestellte Antwort nur eine Möglichkeit ist und daher nicht die einzige mögliche Antwort sein wird . Wenn Sie dieselbe Prämisse außerdem mehrmals testen, kann dies zu einer anderen oder sogar widersprüchlichen Antwort führen. Es handelt sich also um ein Modell, das eine Antwort basierend auf dem zuvor Gesagten zurückgibt und diese mit allem, was Sie wissen, verknüpft, um die vernünftigste Antwort zu erhalten. Dies bedeutet, dass es nicht verpflichtet ist, eine Antwort mit realen Daten zu geben, was wir berücksichtigen müssen. Dies bedeutet nicht, dass Benutzer keine relevanten Arbeitsdaten offenlegen können, aber GPT-3 muss diese Daten mit Kontextinformationen vergleichen. Je umfassender der Kontext, desto vernünftiger ist die Antwort, die Sie erhalten, und umgekehrt.
Das GPT-3-Sprachmodell von OpenAI ist vorab trainiert und das Training umfasst das Studium großer Informationsmengen im Internet. GPT-3 wird in alle öffentlich zugänglichen Bücher, den gesamten Inhalt von Wikipedia sowie Millionen von Webseiten und wissenschaftlichen Arbeiten im Internet eingespeist. Kurz gesagt, es beinhaltet das wichtigste menschliche Wissen, das wir im Laufe der Geschichte im Internet veröffentlicht haben. Nach dem Lesen und Analysieren dieser Informationen erstellte das Sprachmodell Verbindungen in einem 700-GB-Modell, das sich auf 48 16-GB-GPUs befand. Um diese Dimension zu verstehen, war das vorherige OpenAI-Modell, das GPT-2-Modell, 40 GB groß und analysierte 45 Millionen Webseiten. Der Unterschied ist enorm, denn GPT-2 hat 1,5 Milliarden Parameter, während GPT-3 175 Milliarden Parameter hat.
Sollen wir einen Test machen? Ich habe GPT-3 gefragt, wie es sich selbst definieren soll, und das Ergebnis ist wie folgt:

So verwenden Sie GPT-3
Das Einzige, was wir tun müssen, ist zu gehen Besuchen Sie die Website, registrieren Sie sich und geben Sie Ihre persönlichen Daten ein. Während des Prozesses werden Sie gefragt: Wofür werden Sie künstliche Intelligenz einsetzen? Für diese Beispiele habe ich die Option „Persönlicher Gebrauch“ gewählt.
Ich möchte darauf hinweisen, dass es meiner Erfahrung nach im englischen Kontext besser funktioniert. Das bedeutet nicht, dass es in anderen Sprachen nicht gut funktioniert; auf Spanisch funktioniert es sogar sehr gut, aber ich bevorzuge die Ergebnisse, die es auf Englisch liefert, weshalb ich von nun an Tests und Ergebnisse zeige auf Englisch. GPT-3 schenkte uns beim Eintritt ein Gratisgeschenk. Sobald Sie sich mit Ihrer E-Mail-Adresse und Telefonnummer angemeldet haben, stehen Ihnen 18 $ zur völlig kostenlosen Nutzung zur Verfügung, ohne dass Sie eine Zahlungsmethode eingeben müssen. Auch wenn es vielleicht nicht nach viel aussieht, sind 18 US-Dollar in Wirklichkeit ziemlich viel. Um Ihnen eine Vorstellung zu geben: Ich habe die KI fünf Stunden lang getestet und es hat mich nur 1 Dollar gekostet. Später werde ich die Preise erklären, damit wir das besser verstehen können. Sobald wir die Website betreten, müssen wir zum Abschnitt „Spielplatz“ gehen. Hier geschieht die ganze Magie. #? , das Auffälligste im Internet ist das große Textfeld. Hier können wir mit der Eingabe von Eingabeaufforderungen in die KI beginnen (denken Sie daran, dies sind unsere Anfragen und/oder Anweisungen). Es ist so einfach, etwas einzugeben, in diesem Fall eine Frage, und auf die Schaltfläche „Senden“ unten zu klicken, damit GPT-3 uns antworten und schreiben kann, wonach wir gefragt haben.
Default
Die Standardeinstellung ist für Funktionen jederzeit verschiedene Aufgaben erledigen zu können. Sie finden sie in der oberen rechten Ecke des Textfelds. Wenn wir auf mehrere davon klicken, öffnet sich mit „Weitere Beispiele“ ein neuer Bildschirm, in dem wir die gesamte Liste zur Verfügung haben. Wenn eine Voreinstellung ausgewählt wird, wird der Inhalt des Textbereichs mit dem Standardtext aktualisiert. Die Einstellungen in der rechten Seitenleiste werden ebenfalls aktualisiert. Wenn wir beispielsweise die Voreinstellung „Grammatikkorrektur“ verwenden möchten, sollten wir für optimale Ergebnisse der folgenden Struktur folgen. Es wird zum Trainieren von GPT-3 verwendet und ist der Hauptgrund, warum GPT-3 so leistungsstark ist. Größer bedeutet jedoch nicht immer besser. Aus diesen Gründen bietet OpenAI vier Hauptmodelle. Es gibt natürlich auch andere Modelle, wir würden jedoch empfehlen, die neueste Version zu verwenden, die wir derzeit verwenden.
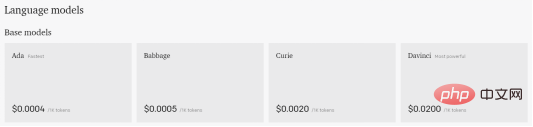
 Die verfügbaren Modelle heißen Davinci, Babbage, Curie und Ada. Von den vier Modellen ist Davinci das größte und leistungsfähigste, da es alle Aufgaben der anderen Motoren abdecken kann.
Die verfügbaren Modelle heißen Davinci, Babbage, Curie und Ada. Von den vier Modellen ist Davinci das größte und leistungsfähigste, da es alle Aufgaben der anderen Motoren abdecken kann.
Wir geben einen Überblick über das Modell und die Aufgabentypen, zu denen das Modell passt. Bedenken Sie, dass kleinere Engines zwar möglicherweise nicht mit so vielen Daten trainiert wurden, es sich aber immer noch um Allzweckmodelle handelt, die für bestimmte Aufgaben sehr praktisch und praktisch sind.
Davinci
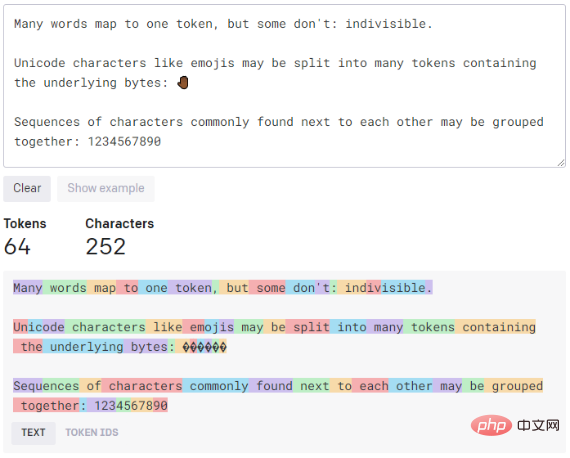
Es ist etwas stärker als Ada, aber nicht so effizient. Es kann dieselben Aufgaben wie Ada ausführen, kann aber auch etwas komplexere Klassifizierungsaufgaben bewältigen, was es ideal für semantische Suchaufgaben macht, die klassifizieren, wie gut ein Dokument mit einer Suchabfrage übereinstimmt. Schließlich ist dies normalerweise das schnellste und günstigste Modell. Es eignet sich am besten für weniger differenzierte Aufgaben wie das Parsen von Text, das Neuformatieren von Text und einfachere Klassifizierungsaufgaben. Je mehr Kontext Sie Ada bereitstellen, desto besser ist die Leistung. Weitere Parameter, die wir anpassen können, um die beste Reaktion auf unsere Hinweise zu erhalten, sind die Modelle. Eine der wichtigsten Einstellungen, die die Leistung der GPT-3-Engine steuert, ist die Temperatur. Diese Einstellung steuert die Zufälligkeit des generierten Textes. Bei einem Wert von 0 ist die Engine deterministisch, was bedeutet, dass sie für eine bestimmte Texteingabe immer die gleiche Ausgabe erzeugt. Bei einem Wert von 1 geht die Engine die größten Risiken ein und erfordert viel Kreativität. Möglicherweise ist Ihnen aufgefallen, dass GPT-3 bei einigen Tests, die Sie selbst durchführen konnten, mitten im Satz anhielt. Um die maximale Textmenge zu steuern, die generiert werden darf, können Sie die in einem Token angegebene Einstellung „max-length“ verwenden. Wir werden später erklären, was dieser Token ist. Der Parameter „Top P“ kann die Zufälligkeit und Kreativität von GPT-3-Text steuern, aber in diesem Fall hängt er mit dem Token (Wort) innerhalb des Wahrscheinlichkeitsbereichs zusammen, je nachdem, wo wir ihn platzieren ( 0,1 entspricht 10 %). In der OpenAI-Dokumentation wird empfohlen, nur eine Funktion zwischen Temperatur und Top P zu verwenden. Wenn Sie also eine Funktion verwenden, stellen Sie sicher, dass die andere auf 1 eingestellt ist. Andererseits haben wir zwei Parameter, um die von GPT-3 gegebene Antwort zu bestrafen. Eine davon ist die „Frequenzstrafe“, die die Tendenz des Modells steuert, wiederholte Vorhersagen zu treffen. Es verringert auch die Wahrscheinlichkeit, dass ein Wort generiert wurde, und hängt davon ab, wie oft ein Wort in der Vorhersage vorkommt. Die zweite Strafe ist die Existenzstrafe. Das Vorhandensein eines Strafparameters ermutigt das Modell, neue Vorhersagen zu treffen. Wenn ein Wort bereits im vorhergesagten Text vorkommt, gibt es eine Strafe, die die Wahrscheinlichkeit dieses Worts verringert. Im Gegensatz zur Häufigkeitsstrafe hängt die Anwesenheitsstrafe nicht davon ab, wie oft das Wort in früheren Vorhersagen vorkam. Schließlich haben wir einen „besten“ Parameter, der mehrere Antworten auf eine Abfrage liefert. Playground wählt den besten Anbieter aus, um uns zu antworten. GPT-3 warnt Sie, dass mehrere vollständige Antworten auf die Eingabeaufforderung dazu führen, dass mehr Token ausgegeben werden. Um diesen Abschnitt abzuschließen, zeigt das dritte Symbol neben der Schaltfläche „Senden“ alle unsere historischen Anfragen für GPT-3 an. Hier finden Sie die Eingabeaufforderungen für die Antworten mit der besten Leistung. Sobald das kostenlose Guthaben von 18 $ aufgebraucht ist, bietet GPT-3 auch eine Möglichkeit, seine Plattform weiter zu nutzen, die kein monatliches Abonnement oder ähnliches ist. Der Preis hängt direkt von der Nutzung ab. Mit anderen Worten: Die Gebühr richtet sich nach dem Token. Dies ist ein Begriff für künstliche Intelligenz, bei dem Token mit den Produktionskosten in Zusammenhang stehen. Ein Token kann alles sein, von einem Buchstaben bis zu einem Satz. Daher ist es schwierig, genau zu wissen, wie hoch der Preis für jeden Einsatz von KI sein sollte. Aber wenn man bedenkt, dass es sich in der Regel um ein paar Cent pro Dollar handelt, lässt sich mit ein wenig Experimentieren schnell erkennen, wie viel alles kostet. Während OpenAI uns nur ein Dutzend Beispiele für die GPT-3-Nutzung zeigt, können wir die ausgegebenen Token für jedes Beispiel sehen, um besser zu verstehen, wie es funktioniert. Das sind die Versionen und ihre jeweiligen Preise. Um uns eine Vorstellung davon zu geben, wie viel eine bestimmte Anzahl von Wörtern kosten könnte, oder um uns ein Beispiel dafür zu geben, wie die Tokenisierung funktioniert, haben wir das folgende Tool namens Tokenizer. Es sagt uns, dass die GPT-Modellserie Text mithilfe von Token verarbeitet, bei denen es sich um häufig in Texten vorkommende Zeichenfolgen handelt. Das Modell versteht die statistische Beziehung zwischen Token und wird ausgewählt, wenn der nächste Token in der Produktionssequenz verwendet wird. Zum Schluss noch ein kleines Beispiel dafür, wie viel uns das gleiche Beispiel kosten würde. Aus meiner Sicht ist GPT-3 ein Tool, das Benutzer richtig verwenden müssen, GPT-3 liefert nicht unbedingt korrekte Daten. Das heißt, wenn Sie damit arbeiten, Fragen beantworten oder Hausaufgaben machen möchten, müssen Sie einen guten Kontext für die Antworten bereitstellen, die Sie erhalten, um den gewünschten Ergebnissen nahe zu kommen. Manche Menschen machen sich Sorgen, ob GPT-3 das Bildungswesen verändern wird oder ob einige heute bestehende Schreibberufe dadurch verschwinden werden. Meiner bescheidenen Meinung nach wird dies passieren. Früher oder später werden wir alle durch künstliche Intelligenz ersetzt. In diesem Beispiel geht es um künstliche Intelligenz im Zusammenhang mit dem Schreiben, aber es gibt sie auch in den Bereichen Programmierung, Malerei, Audio usw. Andererseits eröffnet es mehr Möglichkeiten für viele, viele Jobs und Projekte, sowohl privat als auch beruflich. Wollten Sie zum Beispiel schon immer eine Horrorgeschichte schreiben? Diese Funktion kann gezielt in der Beispielliste des Grammatikprüfers implementiert werden. Nachdem ich das alles gesagt habe, möchte ich sagen, dass wir uns in der frühen Version der künstlichen Intelligenz befinden. Es gibt noch viele Produkte auf dieser Welt, die wachsen und verbessert werden müssen, aber das bedeutet nicht sie wurden nicht umgesetzt. Solange wir künstliche Intelligenz erlernen und nutzen, müssen wir sie weiter trainieren, um die beste Reaktion zu geben. Cui Hao, 51CTO-Community-Redakteur, leitender Architekt, verfügt über 18 Jahre Erfahrung in der Softwareentwicklung und Architektur sowie 10 Jahre Erfahrung in verteilter Architektur. Originaltitel: GPT-3 Playground: The AI That Can Write for You, Autor: Isaac Alvarez. Babbage
Ada
Engine
Verlauf
Gebühren und Tokens
Fazit
Einführung des Übersetzers
Das obige ist der detaillierte Inhalt vonGPT-3: Künstliche Intelligenz, die schreiben kann. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
