
 Backend-Entwicklung
Python-Tutorial
Eine vollständige Anleitung zur Datenbereinigung mit Python
Backend-Entwicklung
Python-Tutorial
Eine vollständige Anleitung zur Datenbereinigung mit Python
Eine vollständige Anleitung zur Datenbereinigung mit Python

Sie müssen dieses berühmte Data-Science-Zitat gehört haben:
In einem Data-Science-Projekt sind 80 % der Zeit Datenverarbeitung.
Wenn Sie noch nie davon gehört haben, denken Sie daran: Die Datenbereinigung ist die Grundlage des Data-Science-Workflows. Die Leistung von Modellen für maschinelles Lernen basiert auf den von Ihnen bereitgestellten Daten. Unordentliche Daten können zu schlechter Leistung oder sogar falschen Ergebnissen führen, während saubere Daten eine Voraussetzung für eine gute Modellleistung sind. Natürlich bedeuten saubere Daten nicht immer eine gute Leistung. Auch die richtige Auswahl des Modells (die restlichen 20 %) ist wichtig, aber ohne saubere Daten kann selbst das leistungsstärkste Modell nicht das erwartete Niveau erreichen.
In diesem Artikel listen wir die Probleme auf, die bei der Datenbereinigung gelöst werden müssen, und zeigen mögliche Lösungen auf. In diesem Artikel erfahren Sie, wie Sie die Datenbereinigung Schritt für Schritt durchführen.
Fehlende Werte
Wenn der Datensatz fehlende Daten enthält, kann vor dem Füllen eine Datenanalyse durchgeführt werden. Denn die Position der leeren Zelle selbst kann uns einige nützliche Informationen liefern. Beispiel:
- NA-Werte erscheinen nur am Ende oder in der Mitte des Datensatzes. Dies bedeutet, dass es während des Datenerfassungsprozesses zu technischen Problemen kommen kann. Es kann erforderlich sein, den Datenerfassungsprozess für diese bestimmte Probensequenz zu analysieren und zu versuchen, die Ursache des Problems zu ermitteln.
- Wenn die Anzahl der NAs in einer Spalte 70–80 % überschreitet, können Sie die Spalte löschen.
- Wenn sich NA-Werte in einer Spalte als optionale Frage im Formular befinden, kann diese Spalte zusätzlich als vom Benutzer beantwortet (1) oder nicht beantwortet (0) codiert werden.
missingno Diese Python-Bibliothek kann verwendet werden, um die obige Situation zu überprüfen, und sie ist sehr einfach zu verwenden. Die weiße Linie im Bild unten ist beispielsweise NA:
import missingno as msno msno.matrix(df)

Es gibt viele Methoden zum Ausfüllen fehlende Werte, wie zum Beispiel:
- Mittelwert, Median, Modus
- kNN
- Null oder konstant usw.
Verschiedene Methoden haben Stärken und Schwächen gegenüber einander, und es gibt keine „beste“ Technik, die insgesamt funktioniert Situationen. Einzelheiten finden Sie in unseren vorherigen Artikeln
Ausreißer
Ausreißer sind sehr große oder sehr kleine Werte im Verhältnis zu anderen Punkten im Datensatz. Ihre Anwesenheit hat großen Einfluss auf die Leistung mathematischer Modelle. Schauen wir uns dieses einfache Beispiel an:
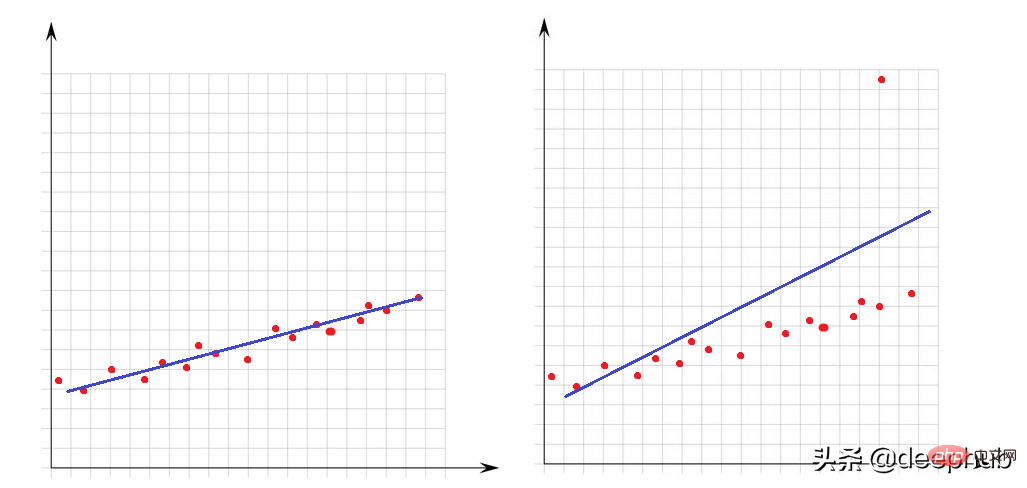
Im linken Bild gibt es keine Ausreißer und unser lineares Modell passt sehr gut zu den Datenpunkten. Im Bild rechts gibt es einen Ausreißer. Wenn das Modell versucht, alle Punkte des Datensatzes abzudecken, ändert das Vorhandensein dieses Ausreißers die Art und Weise, wie das Modell passt, und führt dazu, dass unser Modell für mindestens die Hälfte der Punkte nicht geeignet ist.
Für Ausreißer müssen wir einführen, wie man Anomalien bestimmt. Dazu muss geklärt werden, was aus mathematischer Sicht maximal oder minimal ist.
Jeder Wert größer als Q3+1,5 x IQR oder kleiner als Q1-1,5 x IQR kann als Ausreißer angesehen werden. IQR (Interquartilbereich) ist die Differenz zwischen Q3 und Q1 (IQR = Q3-Q1).
Mit der folgenden Funktion kann die Anzahl der Ausreißer im Datensatz überprüft werden:
def number_of_outliers(df): df = df.select_dtypes(exclude = 'object') Q1 = df.quantile(0.25) Q3 = df.quantile(0.75) IQR = Q3 - Q1 return ((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).sum()
Eine Möglichkeit, mit Ausreißern umzugehen, besteht darin, sie gleich Q3 oder Q1 zu machen. Die folgende Funktion „lower_upper_range“ verwendet die Pandas- und Numpy-Bibliotheken, um Bereiche mit Ausreißern außerhalb dieser Bereiche zu finden, und verwendet dann die Clip-Funktion, um die Werte auf den angegebenen Bereich zu begrenzen.
def lower_upper_range(datacolumn): sorted(datacolumn) Q1,Q3 = np.percentile(datacolumn , [25,75]) IQR = Q3 - Q1 lower_range = Q1 - (1.5 * IQR) upper_range = Q3 + (1.5 * IQR) return lower_range,upper_range for col in columns: lowerbound,upperbound = lower_upper_range(df[col]) df[col]=np.clip(df[col],a_min=lowerbound,a_max=upperbound)
Inkonsistente Daten
Das Ausreißerproblem betraf numerische Merkmale. Schauen wir uns nun die Merkmale des Zeichentyps (kategorial) an. Inkonsistente Daten bedeuten, dass eindeutige Spaltenklassen unterschiedliche Darstellungen haben. Beispielsweise gibt es in der Spalte „Geschlecht“ sowohl m/f als auch männlich/weiblich. In diesem Fall gäbe es 4 Klassen, tatsächlich sind es aber zwei Klassen.
Für dieses Problem gibt es derzeit keine automatische Lösung, daher ist eine manuelle Analyse erforderlich. Die einzigartige Funktion von Pandas ist für diese Analyse vorbereitet. Schauen wir uns ein Beispiel einer Automarke an:
df['CarName'] = df['CarName'].str.split().str[0] print(df['CarName'].unique())
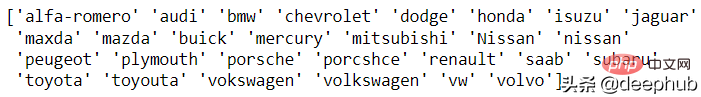
Maxda-Mazda, Nissan-Nissan, Porcshce-Porsche, Toyouta-Toyota usw. können alle zusammengeführt werden.
df.loc[df['CarName'] == 'maxda', 'CarName'] = 'mazda' df.loc[df['CarName'] == 'Nissan', 'CarName'] = 'nissan' df.loc[df['CarName'] == 'porcshce', 'CarName'] = 'porsche' df.loc[df['CarName'] == 'toyouta', 'CarName'] = 'toyota' df.loc[df['CarName'] == 'vokswagen', 'CarName'] = 'volkswagen' df.loc[df['CarName'] == 'vw', 'CarName'] = 'volkswagen'
Ungültige Daten
Ungültige Daten stellen einen Wert dar, der logisch überhaupt nicht korrekt ist. Zum Beispiel:
- Jemand ist 560 Jahre alt;
- Eine bestimmte Operation ist 1200 cm groß usw.; Für numerische Spalten kann die Beschreibungsfunktion von Pandas verwendet werden Fehler:
df.describe()
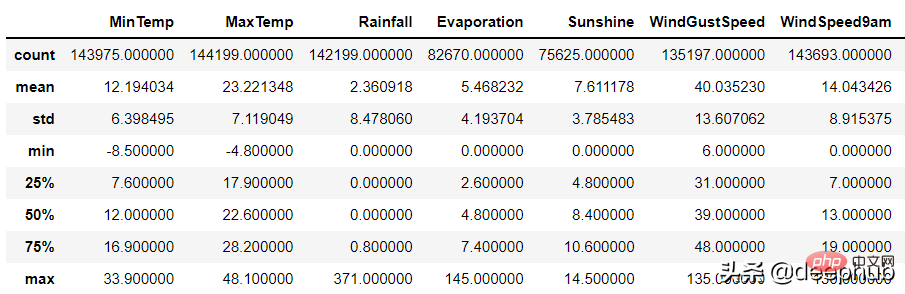 Es kann zwei Gründe für ungültige Daten geben:
Es kann zwei Gründe für ungültige Daten geben:
1 Datenerfassungsfehler: Beispielsweise wird der Bereich bei der Eingabe nicht beurteilt und bei der Eingabe der Höhe werden 1799 cm anstelle von 179 cm eingegeben, aber das Programm beurteilt nicht den Umfang der Daten.
2. Datenoperationsfehler
数据集的某些列可能通过了一些函数的处理。 例如,一个函数根据生日计算年龄,但是这个函数出现了BUG导致输出不正确。
以上两种随机错误都可以被视为空值并与其他 NA 一起估算。
重复数据
当数据集中有相同的行时就会产生重复数据问题。 这可能是由于数据组合错误(来自多个来源的同一行),或者重复的操作(用户可能会提交他或她的答案两次)等引起的。 处理该问题的理想方法是删除复制行。
可以使用 pandas duplicated 函数查看重复的数据:
df.loc[df.duplicated()]
在识别出重复的数据后可以使用pandas 的 drop_duplicate 函数将其删除:
df.drop_duplicates()
数据泄漏问题
在构建模型之前,数据集被分成训练集和测试集。 测试集是看不见的数据用于评估模型性能。 如果在数据清洗或数据预处理步骤中模型以某种方式“看到”了测试集,这个就被称做数据泄漏(data leakage)。 所以应该在清洗和预处理步骤之前拆分数据:
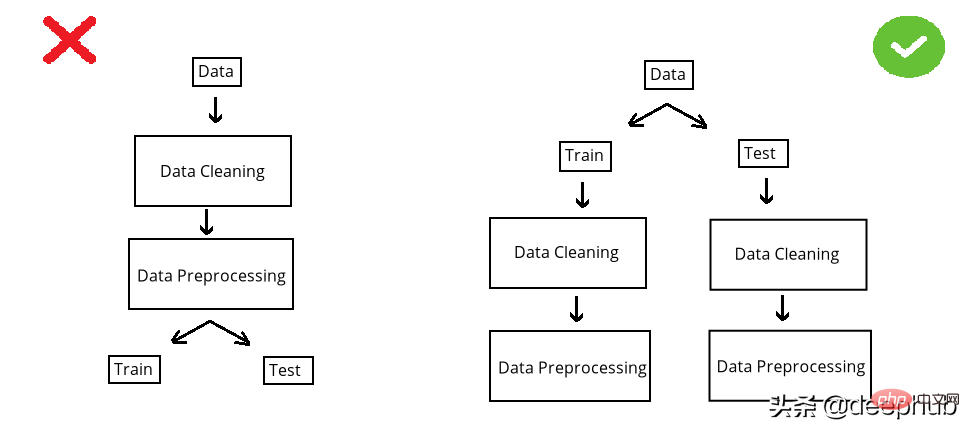
以选择缺失值插补为例。数值列中有 NA,采用均值法估算。在 split 前完成时,使用整个数据集的均值,但如果在 split 后完成,则使用分别训练和测试的均值。
第一种情况的问题是,测试集中的推算值将与训练集相关,因为平均值是整个数据集的。所以当模型用训练集构建时,它也会“看到”测试集。但是我们拆分的目标是保持测试集完全独立,并像使用新数据一样使用它来进行性能评估。所以在操作之前必须拆分数据集。
虽然训练集和测试集分别处理效率不高(因为相同的操作需要进行2次),但它可能是正确的。因为数据泄露问题非常重要,为了解决代码重复编写的问题,可以使用sklearn 库的pipeline。简单地说,pipeline就是将数据作为输入发送到的所有操作步骤的组合,这样我们只要设定好操作,无论是训练集还是测试集,都可以使用相同的步骤进行处理,减少的代码开发的同时还可以减少出错的概率。
Das obige ist der detaillierte Inhalt vonEine vollständige Anleitung zur Datenbereinigung mit Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Es gibt kein absolutes Gehalt für Python- und JavaScript -Entwickler, je nach Fähigkeiten und Branchenbedürfnissen. 1. Python kann mehr in Datenwissenschaft und maschinellem Lernen bezahlt werden. 2. JavaScript hat eine große Nachfrage in der Entwicklung von Front-End- und Full-Stack-Entwicklung, und sein Gehalt ist auch beträchtlich. 3. Einflussfaktoren umfassen Erfahrung, geografische Standort, Unternehmensgröße und spezifische Fähigkeiten.
 Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Obwohl eindeutig und unterschiedlich mit der Unterscheidung zusammenhängen, werden sie unterschiedlich verwendet: Unterschieds (Adjektiv) beschreibt die Einzigartigkeit der Dinge selbst und wird verwendet, um Unterschiede zwischen den Dingen zu betonen; Das Unterscheidungsverhalten oder die Fähigkeit des Unterschieds ist eindeutig (Verb) und wird verwendet, um den Diskriminierungsprozess zu beschreiben. In der Programmierung wird häufig unterschiedlich, um die Einzigartigkeit von Elementen in einer Sammlung darzustellen, wie z. B. Deduplizierungsoperationen; Unterscheidet spiegelt sich in der Gestaltung von Algorithmen oder Funktionen wider, wie z. B. die Unterscheidung von ungeraden und sogar Zahlen. Bei der Optimierung sollte der eindeutige Betrieb den entsprechenden Algorithmus und die Datenstruktur auswählen, während der unterschiedliche Betrieb die Unterscheidung zwischen logischer Effizienz optimieren und auf das Schreiben klarer und lesbarer Code achten sollte.
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
 Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
! X Understanding! X ist ein logischer Nicht-Operator in der C-Sprache. Es booleschen den Wert von x, dh wahre Änderungen zu falschen, falschen Änderungen an True. Aber seien Sie sich bewusst, dass Wahrheit und Falschheit in C eher durch numerische Werte als durch Boolesche Typen dargestellt werden, ungleich Null wird als wahr angesehen und nur 0 wird als falsch angesehen. Daher handelt es sich um negative Zahlen wie positive Zahlen und gilt als wahr.
 Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Es gibt keine integrierte Summenfunktion in C für die Summe, kann jedoch implementiert werden durch: Verwenden einer Schleife, um Elemente nacheinander zu akkumulieren; Verwenden eines Zeigers, um auf die Elemente nacheinander zuzugreifen und zu akkumulieren; Betrachten Sie für große Datenvolumina parallele Berechnungen.
 Wie erhalten Sie Echtzeit-Anwendungs- und Zuschauerdaten auf der Arbeit von 58.com?
Apr 05, 2025 am 08:06 AM
Wie erhalten Sie Echtzeit-Anwendungs- und Zuschauerdaten auf der Arbeit von 58.com?
Apr 05, 2025 am 08:06 AM
Wie erhalte ich dynamische Daten von 58.com Arbeitsseite beim Kriechen? Wenn Sie eine Arbeitsseite von 58.com mit Crawler -Tools kriechen, können Sie auf diese begegnen ...
 Kopieren Sie den Liebescode und fügen Sie den Liebescode kostenlos kopieren und einfügen
Apr 04, 2025 am 06:48 AM
Kopieren Sie den Liebescode und fügen Sie den Liebescode kostenlos kopieren und einfügen
Apr 04, 2025 am 06:48 AM
Das Kopieren und Einfügen des Codes ist nicht unmöglich, sollte aber mit Vorsicht behandelt werden. Abhängigkeiten wie Umgebung, Bibliotheken, Versionen usw. im Code stimmen möglicherweise nicht mit dem aktuellen Projekt überein, was zu Fehlern oder unvorhersehbaren Ergebnissen führt. Stellen Sie sicher, dass der Kontext konsistent ist, einschließlich Dateipfade, abhängiger Bibliotheken und Python -Versionen. Wenn Sie den Code für eine bestimmte Bibliothek kopieren und einfügen, müssen Sie möglicherweise die Bibliothek und ihre Abhängigkeiten installieren. Zu den häufigen Fehlern gehören Pfadfehler, Versionskonflikte und inkonsistente Codestile. Die Leistungsoptimierung muss gemäß dem ursprünglichen Zweck und den Einschränkungen des Codes neu gestaltet oder neu gestaltet werden. Es ist entscheidend, den Code zu verstehen und den kopierten kopierten Code zu debuggen und nicht blind zu kopieren und einzufügen.
