

Muss künstliche Intelligenz wie Menschen sein?

Können Maschinen denken? Kann künstliche Intelligenz so intelligent sein wie der Mensch?
Eine aktuelle Studie zeigt, dass künstliche Intelligenz dazu in der Lage sein könnte.
In einem nicht-linguistischen Turing-Test hat ein Forschungsteam unter der Leitung von Professorin Agnieszka Wykowska vom Italienischen Technologieinstitut herausgefunden, dass menschenähnliche Verhaltensvariabilität (Verhaltensvariabilität) den Unterschied zwischen Menschen und Maschinen verwischen, also helfen kann Roboter sehen eher wie Menschen aus.
Konkret bestand ihr KI-Programm den nonverbalen Turing-Test, indem es Verhaltensvariabilität in menschlichen Reaktionszeiten simulierte, während es ein Spiel spielte, bei dem es darum ging, Formen und Farben mit menschlichen Teamkollegen abzugleichen.
Die entsprechende Forschungsarbeit trägt den Titel „Menschenähnliche Verhaltensvariabilität verwischt die Unterscheidung zwischen einem Menschen und einer Maschine in einem nonverbalen Turing-Test“ und wurde in der Fachzeitschrift Science Robotics veröffentlicht.
Das Forschungsteam gab an, dass diese Arbeit Leitlinien für das zukünftige Roboterdesign liefern und Robotern menschenähnliche Verhaltensweisen verleihen kann, die von Menschen wahrgenommen werden können.
In Bezug auf diese Forschung glauben Tom Ziemke, Professor für kognitive Systeme an der Universität Linköping, und der Postdoktorand Sam Thellman, dass die Forschungsergebnisse „die Unterscheidung zwischen Menschen und Maschinen verwischen“ und zum wissenschaftlichen Verständnis der menschlichen sozialen Kognition beitragen Beitrag.
Allerdings ist „Menschenähnlichkeit nicht unbedingt ein wünschenswertes Ziel für die Entwicklung von künstlicher Intelligenz und Robotik, und es könnte ein klügerer Ansatz sein, die KI weniger menschenähnlich zu machen
Hat den Turing-Test bestanden
1950“, Alan Turing, Der Vater der Informatik und der künstlichen Intelligenz schlug eine Testmethode vor, um festzustellen, ob eine Maschine intelligent ist: den Turing-Test.
Die Kernidee des Turing-Tests besteht darin, dass komplexe Fragen zur Möglichkeit von maschinellem Denken und Intelligenz überprüft werden können, indem getestet wird, ob Menschen erkennen können, ob sie mit einem anderen Menschen oder einer Maschine interagieren.
Heute wird der Turing-Test von Wissenschaftlern verwendet, um zu bewerten, welche Verhaltensmerkmale auf künstlichen Agenten implementiert werden sollten, um es für Menschen unmöglich zu machen, Computerprogramme von menschlichem Verhalten zu unterscheiden.
Herbert Simon, der Pionier der künstlichen Intelligenz, sagte einmal: „Wenn das Verhalten des Programms dem des Menschen ähnelt, dann nennen wir sie intelligent.“ In ähnlicher Weise definierte Elaine Rich künstliche Intelligenz als „Forschung, wie man etwas macht.“ Computer können Dinge, die Menschen derzeit besser können.
Der nichtlinguistische Turing-Test ist eine Form des Turing-Tests. Den nonverbalen Turing-Test zu bestehen, ist für künstliche Intelligenzen nicht einfach, da sie nicht so gut darin sind wie Menschen, subtile Verhaltensmerkmale anderer Menschen (Objekte) zu erkennen und zu unterscheiden.
Kann also ein humanoider Roboter den nonverbalen Turing-Test bestehen und menschliche Eigenschaften in seinem physischen Verhalten verkörpern? Mit dem nonverbalen Turing-Test wollte das Forschungsteam herausfinden, ob eine KI so programmiert werden kann, dass sie ihre Reaktionszeiten innerhalb eines Bereichs variiert, der den menschlichen Verhaltensvariationen ähnelt, und somit als menschlich betrachtet werden kann.
Dazu arrangierten sie Menschen und Roboter in einem Raum mit unterschiedlichen Farben und Formen auf dem Bildschirm.

 Bild|Roboter und Menschen erledigen gemeinsam Aufgaben. (Quelle: The Paper)
Bild|Roboter und Menschen erledigen gemeinsam Aufgaben. (Quelle: The Paper)
Wenn sich die Form oder Farbe ändert, drückt der Teilnehmer einen Knopf und der Roboter reagiert auf dieses Signal, indem er auf die entgegengesetzte Farbe oder Form klickt, die auf dem Bildschirm angezeigt wird.

 Abbildung |. Reagieren per Knopfdruck (Quelle: das Papier)
Abbildung |. Reagieren per Knopfdruck (Quelle: das Papier)
Während der Tests wurde der Roboter manchmal von einem Menschen ferngesteuert und manchmal von einer künstlichen Intelligenz, die darauf trainiert war, Verhaltensvariabilität nachzuahmen.

Bild|Die Teilnehmer wurden gebeten zu beurteilen, ob das Verhalten des Roboters vorprogrammiert oder von einem Menschen gesteuert wurde. (Quelle: Das Papier)
Die Ergebnisse zeigten, dass die Teilnehmer leicht erkennen konnten, wann der Roboter von einer anderen Person bedient wurde.
Wenn der Roboter jedoch mit künstlicher Intelligenz betrieben wurde, lag die Wahrscheinlichkeit, dass die Teilnehmer falsch rieten, bei mehr als 50 %.
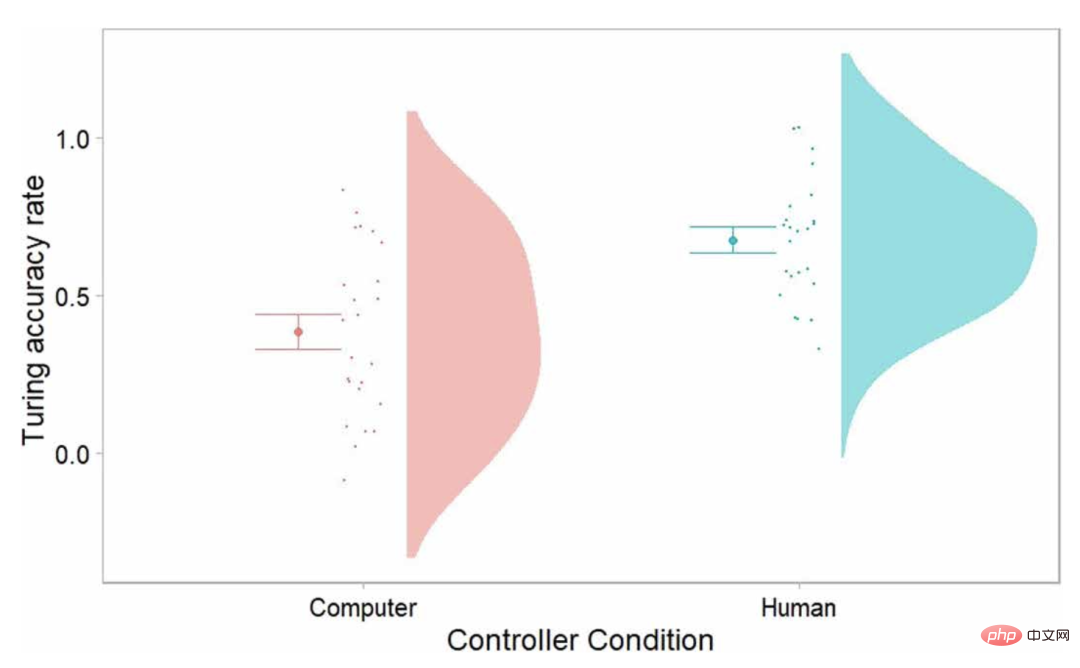
Abbildung|Durchschnittliche Genauigkeit des Turing-Tests. (Quelle: The Paper)
Das bedeutet, dass ihre künstliche Intelligenz den nonverbalen Turing-Test bestanden hat.
Allerdings schlagen die Forscher auch vor, dass Variabilität im menschenähnlichen Verhalten möglicherweise nur eine notwendige und unzureichende Bedingung für das Bestehen des nonverbalen Turing-Tests für künstliche Intelligenz von Entitäten ist, da sie sich auch in menschlichen Umgebungen manifestieren kann.
Muss künstliche Intelligenz wie Menschen sein?
In der Forschung zur künstlichen Intelligenz wird die menschliche Ähnlichkeit seit langem als Ziel und Maßstab verwendet, und die Forschung von Wykowskas Team zeigt, dass Verhaltensvariabilität genutzt werden kann, um Roboter Menschen ähnlicher zu machen.
Ziemke und andere glauben, dass es klüger sein könnte, künstliche Intelligenz weniger menschenähnlich zu machen, und gingen auf die beiden Fälle selbstfahrender Autos und Chat-Roboter ein.
Wenn Sie beispielsweise gerade dabei sind, den Zebrastreifen auf der Straße zu überqueren, und aus der Ferne ein Auto auf sich zukommen sehen, können Sie möglicherweise nicht erkennen, ob es sich um ein selbstfahrendes Auto handelt, sodass Sie nur anhand dessen urteilen können das Verhalten des Autos zu beurteilen.

(Quelle: Pixabay)
Doch selbst wenn Sie jemanden vor dem Lenkrad sitzen sehen, können Sie nicht sicher sein, ob diese Person das Fahrzeug aktiv steuert oder nur den Fahrbetrieb des Fahrzeugs überwacht.
„Dies hat einen sehr wichtigen Einfluss auf die Verkehrssicherheit. Wenn ein selbstfahrendes Auto anderen nicht anzeigen kann, ob es sich im Selbstfahrmodus befindet, kann dies zu unsicheren Mensch-Maschine-Interaktionen führen.“
Vielleicht würden einige Leute sagen , Ideal In diesem Fall müssen Sie nicht wissen, ob ein Auto selbstfahrend ist, da selbstfahrende Autos auf lange Sicht möglicherweise besser fahren können als Menschen. Allerdings reicht das Vertrauen der Menschen in selbstfahrende Autos derzeit bei weitem nicht aus.
Der Chatbot kommt dem realen Szenario von Turings ursprünglichem Test näher. Viele Unternehmen nutzen Chatbots in ihrem Online-Kundenservice, wo Gesprächsthemen und Interaktionsmöglichkeiten relativ begrenzt sind. In diesem Zusammenhang sind Chatbots oft kaum von Menschen zu unterscheiden.
(Quelle: Pixabay)
Die Frage ist also: Sollten Unternehmen ihre Kunden über den nichtmenschlichen Status von Chatbots informieren? Wenn es einmal erzählt wird, führt es oft zu negativen Reaktionen der Verbraucher, wie zum Beispiel zu einem Vertrauensverlust.
Wie die oben genannten Fälle zeigen, mag menschenähnliches Verhalten aus technischer Sicht zwar eine beeindruckende Leistung sein, die Ununterscheidbarkeit von Mensch und Maschine bringt jedoch offensichtliche psychologische, ethische und rechtliche Probleme mit sich.
Einerseits müssen Menschen, die mit diesen Systemen interagieren, die Art dessen kennen, mit dem sie interagieren, um Spoofing zu vermeiden. Am Beispiel von Chatbots: Kalifornien in den Vereinigten Staaten hat seit 2018 ein Gesetz zur Offenlegung von Chatbot-Informationen erlassen, das klarstellt, dass die Offenlegung eine strenge Anforderung ist.
Andererseits gibt es noch mehr ununterscheidbare Beispiele als Chatbots und menschlichen Kundenservice. Wenn es beispielsweise um das autonome Fahren geht, haben die Interaktionen zwischen selbstfahrenden Autos und anderen Verkehrsteilnehmern nicht die gleichen klaren Start- und Endpunkte, sie sind oft nicht eins zu eins und sie haben bestimmte reale- Zeitbeschränkungen.
Die Frage ist also, wann und wie die Identität und Fähigkeiten selbstfahrender Autos kommuniziert werden sollen.
Außerdem kann es noch Jahrzehnte dauern, bis vollautomatisierte Autos kommen. Mischverkehr und unterschiedliche Grade der Teilautomatisierung dürften daher auf absehbare Zeit Realität sein.
Es wurde viel darüber geforscht, welche externen Schnittstellen selbstfahrende Autos möglicherweise benötigen, um mit Menschen zu kommunizieren. Es ist jedoch wenig darüber bekannt, mit welchen Komplexitäten schwächere Verkehrsteilnehmer wie Kinder und Menschen mit Behinderungen tatsächlich zurechtkommen und bereit sind, damit umzugehen.
Daher kann die obige allgemeine Regel, dass „Personen, die mit einem solchen System interagieren, über die Art der Objekte, mit denen interagiert wird, informiert werden müssen“, möglicherweise nur unter expliziteren Umständen befolgt werden.
In ähnlicher Weise spiegelt sich diese Ambivalenz in Diskussionen über die Forschung im Bereich Sozialrobotik wider: Angesichts der Tendenz des Menschen, mentale Zustände zu anthropomorphisieren und ihnen menschenähnliche Eigenschaften zuzuweisen, zielen viele Forscher darauf ab, Roboter mehr wie Menschen aussehen und sich verhalten zu lassen, damit sie interagieren können eine mehr oder weniger menschenähnliche Art und Weise.
Es gibt jedoch auch diejenigen, die glauben, dass Roboter leicht als Maschinen identifizierbar sein sollten, um übermäßig anthropomorphe Eigenschaften und unrealistische Erwartungen zu vermeiden.
„Vielleicht wäre es klüger, diese Erkenntnisse zu nutzen, um Roboter weniger menschenähnlich zu machen.“ Teil des täglichen Lebens der Menschen „Heute müssen wir zumindest darüber nachdenken, in welche Richtung es wirklich Sinn macht, eine menschenähnliche künstliche Intelligenz anzustreben.“
Das obige ist der detaillierte Inhalt vonMuss künstliche Intelligenz wie Menschen sein?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
