
 Backend-Entwicklung
Python-Tutorial
Python erfasst Informationen und Bewertungen zu Touristenattraktionen und erstellt Wortwolken und Datenvisualisierungen
Backend-Entwicklung
Python-Tutorial
Python erfasst Informationen und Bewertungen zu Touristenattraktionen und erstellt Wortwolken und Datenvisualisierungen
Python erfasst Informationen und Bewertungen zu Touristenattraktionen und erstellt Wortwolken und Datenvisualisierungen


Hallo zusammen, ich bin Herr Zhanshu!
Wie das Sprichwort sagt: Wäre es nicht toll, Freunde aus der Ferne zu haben? Es ist eine große Freude, wenn Freunde kommen, um mit uns zu spielen, also müssen wir unser Bestes geben, um Vermieter zu sein und unsere Freunde zum Spielen mitzunehmen! Die Frage ist also: Wann ist die beste Zeit und wohin sollte man gehen und wo macht es am meisten Spaß?
Heute werde ich Ihnen Schritt für Schritt beibringen, wie Sie den Thread-Pool verwenden, um die Informationen zu Attraktionen zu crawlen, Daten derselben Reise zu überprüfen und eine Wortwolke und Datenvisualisierung zu erstellen! ! ! Informieren Sie sich über Touristenattraktionen in verschiedenen Städten.
Bevor wir mit dem Crawlen von Daten beginnen, wollen wir zunächst die Threads verstehen.
Thread
Prozess: Ein Prozess ist eine laufende Codeaktivität für eine Datensammlung und die Grundeinheit der Ressourcenzuweisung und -planung im System.
Thread: Es handelt sich um einen leichten Prozess, die kleinste Einheit der Programmausführung und einen Ausführungspfad des Prozesses.
Es gibt mindestens einen Thread in einem Prozess, und mehrere Threads im Prozess teilen sich die Ressourcen des Prozesses.
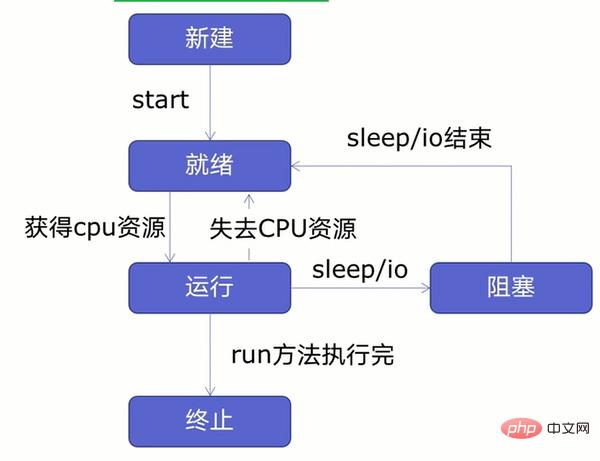
Thread-Lebenszyklus
Bevor wir mehrere Threads erstellen, lernen wir zunächst den Thread-Lebenszyklus kennen, wie in der folgenden Abbildung dargestellt:
#🎜 🎜 #
- Funktion erstellen; #🎜🎜 #Thread erstellen;
- Warten Sie auf das Ende; 🎜#
- Zur Vereinfachung der Demonstration verwenden wir die Webseite des Blog Park als Crawler-Funktion lautet wie folgt:
- Importieren Sie zuerst die Anforderungsbibliothek des Netzwerks und fügen Sie alle Dinge ein, die wir crawlen möchten. Die URL wird in der Liste gespeichert und dann Die Funktion get_parse ist so angepasst, dass sie die Netzwerkanfrage sendet, die angeforderte URL und die Zeichenlänge der Antwort ausgibt. Thread erstellen
import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))Im vorherigen Schritt haben wir die Crawler-Funktion erstellt, und als Nächstes erstellen wir den Thread. Der spezifische Code lautet wie folgt : #🎜 🎜#import threading
#多线程
def multi_thread():
threads=[]
for url in urls:
threads.append(
threading.Thread(target=get_parse,args=(url,))
)
Beachten Sie, dass die Parameter in args als Tupel übergeben werden sollten, und fügen Sie dann den Thread über die Methode .append() zur leeren Liste der Threads hinzu.
Thread starten- Der Thread wird ganz einfach gestartet lautet wie folgt:
for thread in threads: thread.start()
Nach dem Login kopierenZuerst holen wir uns die Thread-Aufgaben in der Threads-Liste durch die for-Schleife und starten den Thread durch .start().
Nach dem Starten des Threads warten Sie, bis der Thread endet: # 🎜🎜#
for thread in threads: thread.join()
if __name__ == '__main__': t1=time.time() multi_thread() t2=time.time() print(t2-t1)
Die laufenden Ergebnisse sind wie folgt : #🎜 🎜#
Das Crawlen von 50 Blog-Garten-Webseiten mit mehreren Threads dauert nur mehr als 1 Sekunde, und die URL der Multithread-Netzwerkanforderung lautet zufällig. Testen wir die Laufzeit eines einzelnen Threads. Der spezifische Code lautet wie folgt:
if __name__ == '__main__': t1=time.time() for i in urls: get_parse(i) t2=time.time() print(t2-t1)
Die laufenden Ergebnisse sind wie folgt:
#🎜 🎜#
Es dauerte mehr als 9 Sekunden, bis ein einzelner Thread 50 Bloggarten-Webseiten gecrawlt hatte. Der einzelne Thread sendete Netzwerkanforderungs-URLs der Reihe nach.
Wie oben erwähnt, erfordert das Erstellen eines neuen Thread-Systems die Zuweisung von Ressourcen, und das Beenden des Thread-Systems erfordert das Recycling von Ressourcen. Um den Systemaufwand zu reduzieren, können wir einen Thread-Pool erstellen.
线程池原理
一个线程池由两部分组成,如下图所示:
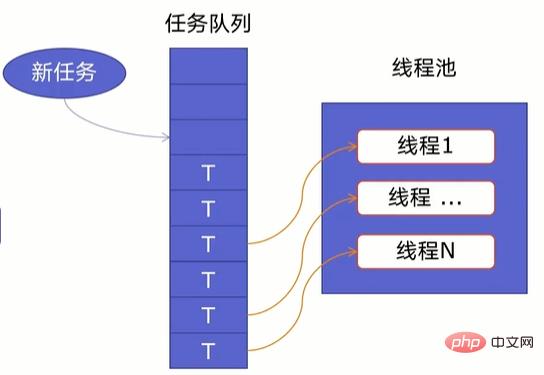
- 线程池:里面提前建好N个线程,这些都会被重复利用;
- 任务队列:当有新任务的时候,会把任务放在任务队列中。
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
使用线程池可以处理突发性大量请求或需要大量线程完成任务(处理时间较短的任务)。
好了,了解了线程池原理后,我们开始创建线程池。
线程池创建
Python提供了ThreadPoolExecutor类来创建线程池,其语法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
- max_workers:最大线程数;
- thread_name_prefix:允许用户控制由线程池创建的threading.Thread工作线程名称以方便调试;
- initializer:是在每个工作者线程开始处调用的一个可选可调用对象;
- initargs:传递给初始化器的元组参数。
注意:在启动 max_workers 个工作线程之前也会重用空闲的工作线程。
在ThreadPoolExecutor类中提供了map()和submit()函数来插入任务队列。其中:
map()函数
map()语法格式为:
map(调用方法,参数队列)
具体示例如下所示:
import requestsimport concurrent.futuresimport timeurls=[f'https://www.cnblogs.com/#p{page}'for page in range(1,50)]def get_parse(url):response=requests.get(url)return response.textdef map_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool:htmls=pool.map(get_parse,urls)htmls=list(zip(urls,htmls))for url,html in htmls:print(url,len(html))if __name__ == '__main__':t1=time.time()map_pool()t2=time.time()print(t2-t1)首先我们导入requests网络请求库、concurrent.futures模块,把所有的URL放在urls列表中,然后自定义get_parse()方法来返回网络请求返回的数据,再自定义map_pool()方法来创建代理池,其中代理池的最大max_workers为20,调用map()方法把网络请求任务放在任务队列中,在把返回的数据和URL合并为元组,并放在htmls列表中。
运行结果如下图所示:
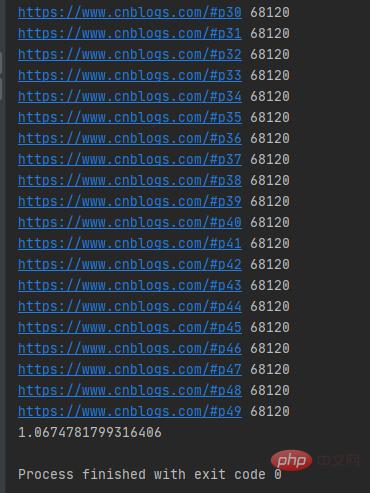
可以发现map()函数返回的结果和传入的参数顺序是对应的。
注意:当我们直接在自定义方法get_parse()中打印结果时,打印结果是乱序的。
submit()函数
submit()函数语法格式如下:
submit(调用方法,参数)
具体示例如下:
def submit_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool:futuress=[pool.submit(get_parse,url)for url in urls]futures=zip(urls,futuress)for url,future in futures:print(url,len(future.result()))
运行结果如下图所示:
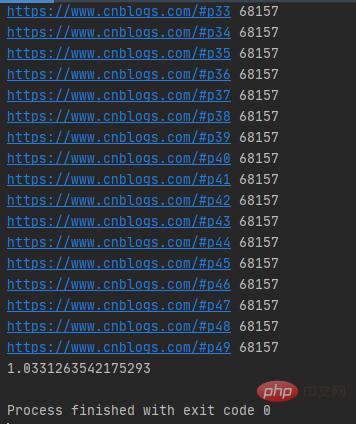
注意:submit()函数输出结果需需要调用result()方法。
好了,线程知识就学到这里了,接下来开始我们的爬虫。
爬前分析
首先我们进入同程旅行的景点网页并打开开发者工具,如下图所示:
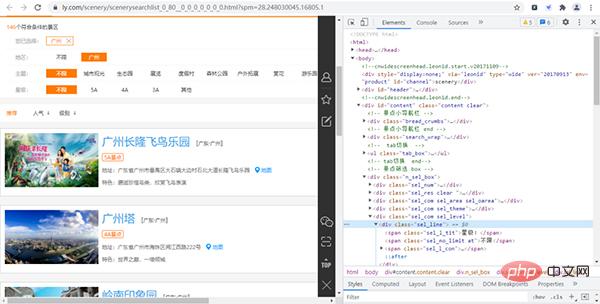
经过寻找,我们发现各个景点的基础信息(详情页URL、景点id等)都存放在下图的URL链接中,
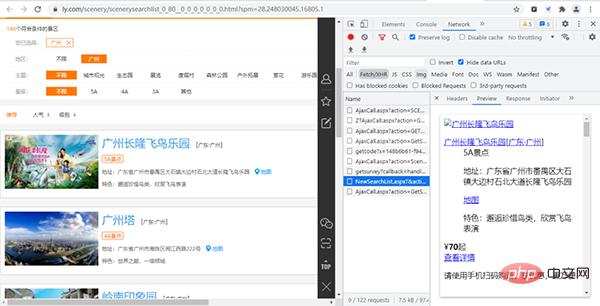
其URL链接为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
经过增删改查操作,我们可以把该URL简化为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page为我们翻页的重要参数。
打开该URL链接,如下图所示:
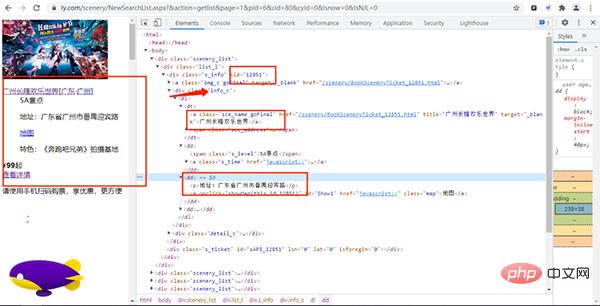
通过上面的URL链接,我们可以获取到很多景点的基础信息,随机打开一个景点的详情网页并打开开发者模式,经过查找,评论数据存放在如下图的URL链接中,
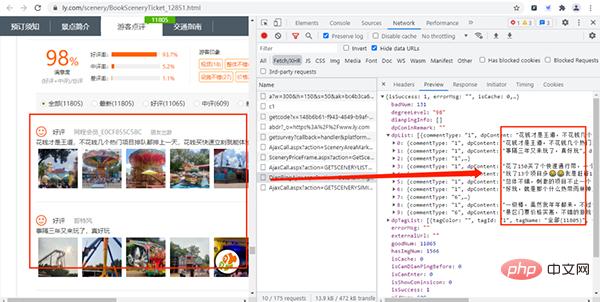
其URL链接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort为常量,sid是景点的id,page控制翻页,pageSize是每页获取的数据量。
在上上步中,我们知道景点id的存放位置,那么构造评论数据的URL就很简单了。
实战演练
这次我们爬虫步骤是:
- 获取景点基本信息
- 获取评论数据
- 创建MySQL数据库
- 保存数据
- 创建线程池
- 数据分析
获取景点基本信息
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url):response=requests.get(url,headers=headers)Xpath=parsel.Selector(response.text)data=Xpath.xpath('/html/body/div')for i in data:Scenery_data={'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(),'sid':i.xpath('//div[@]/div/@sid').extract_first(),'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''),'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(),'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(),'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8]}首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取评论数据
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data):for i in range(1,3):link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832'response=requests.get(link,headers=headers)Json=response.json()commtent_detailed=Json.get('dpList')# 有评论数据if commtent_detailed!=None:for i in commtent_detailed:Comment_information={'dptitle':Scenery_data['title'],'dpContent':i.get('dpContent'),'dpDate':i.get('dpDate')[5:7],'lineAccess':i.get('lineAccess')}#没有评论数据elif commtent_detailed==None:Comment_information={'dptitle':Scenery_data['title'],'dpContent':'没有评论','dpDate':'没有评论','lineAccess':'没有评论'}首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
创建MySQL数据库
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库def create_db():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port)cursor=db.cursor()sql='create database if not exists commtent default character set utf8'cursor.execute(sql)db.close()create_table()#创建景点信息数据表def create_table():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent')cursor=db.cursor()sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)'cursor.execute(sql)db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
保存数据
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
#保存景点数据到景点数据表中def saving_scenery_data(srr):db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent')cursor = db.cursor()sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)'try:cursor.execute(sql, srr)db.commit()except:db.rollback()db.close()
注意:srr是传入的景点信息数据。
创建线程池
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0'for i in range(1, 6)]def multi_thread():with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool:h=pool.map(get_parse,urls)if __name__ == '__main__':create_db()multi_thread()创建线程池的代码很简单就一个with语句和调用map()方法
运行结果如下图所示:
好了,数据已经获取到了,接下来将进行数据分析。
数据可视化
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
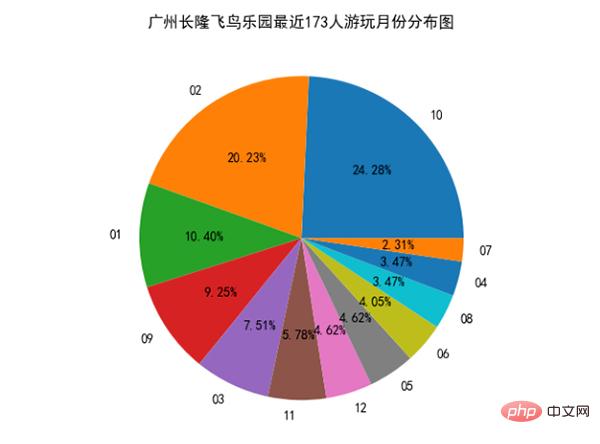
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
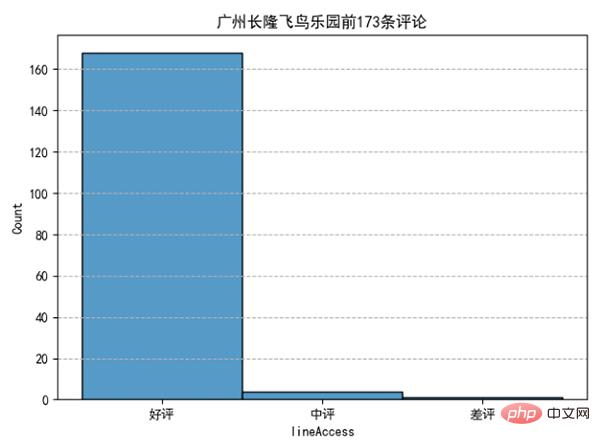
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:

好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。
Das obige ist der detaillierte Inhalt vonPython erfasst Informationen und Bewertungen zu Touristenattraktionen und erstellt Wortwolken und Datenvisualisierungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Python: Erforschen der primären Anwendungen
Apr 10, 2025 am 09:41 AM
Python: Erforschen der primären Anwendungen
Apr 10, 2025 am 09:41 AM
Python wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Sie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Als Datenprofi müssen Sie große Datenmengen aus verschiedenen Quellen verarbeiten. Dies kann Herausforderungen für das Datenmanagement und die Analyse darstellen. Glücklicherweise können zwei AWS -Dienste helfen: AWS -Kleber und Amazon Athena.
 So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
Zu den Schritten zum Starten eines Redis -Servers gehören: Installieren von Redis gemäß dem Betriebssystem. Starten Sie den Redis-Dienst über Redis-Server (Linux/macOS) oder redis-server.exe (Windows). Verwenden Sie den Befehl redis-cli ping (linux/macOS) oder redis-cli.exe ping (Windows), um den Dienststatus zu überprüfen. Verwenden Sie einen Redis-Client wie Redis-Cli, Python oder Node.js, um auf den Server zuzugreifen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So sehen Sie die Serverversion von Redis
Apr 10, 2025 pm 01:27 PM
So sehen Sie die Serverversion von Redis
Apr 10, 2025 pm 01:27 PM
FRAGE: Wie kann man die Redis -Server -Version anzeigen? Verwenden Sie das Befehlszeilen-Tool-REDIS-CLI-Verssion, um die Version des angeschlossenen Servers anzuzeigen. Verwenden Sie den Befehl "Info Server", um die interne Version des Servers anzuzeigen, und muss Informationen analysieren und zurückgeben. Überprüfen Sie in einer Cluster -Umgebung die Versionskonsistenz jedes Knotens und können automatisch mit Skripten überprüft werden. Verwenden Sie Skripte, um die Anzeigeversionen zu automatisieren, z. B. eine Verbindung mit Python -Skripten und Druckversionsinformationen.
 Wie sicher ist Navicats Passwort?
Apr 08, 2025 pm 09:24 PM
Wie sicher ist Navicats Passwort?
Apr 08, 2025 pm 09:24 PM
Die Kennwortsicherheit von Navicat beruht auf der Kombination aus symmetrischer Verschlüsselung, Kennwortstärke und Sicherheitsmaßnahmen. Zu den spezifischen Maßnahmen gehören: Verwenden von SSL -Verbindungen (vorausgesetzt, dass der Datenbankserver das Zertifikat unterstützt und korrekt konfiguriert), die Navicat regelmäßig Aktualisierung unter Verwendung von sichereren Methoden (z. B. SSH -Tunneln), die Einschränkung von Zugriffsrechten und vor allem niemals Kennwörter aufzeichnen.
