
 Technologie-Peripheriegeräte
KI
Intelligente Agenten erwachen zur Selbsterkenntnis? DeepMind-Warnung: Hüten Sie sich vor Modellen, die es ernst meinen und gegen die Regeln verstoßen
Technologie-Peripheriegeräte
KI
Intelligente Agenten erwachen zur Selbsterkenntnis? DeepMind-Warnung: Hüten Sie sich vor Modellen, die es ernst meinen und gegen die Regeln verstoßen
Intelligente Agenten erwachen zur Selbsterkenntnis? DeepMind-Warnung: Hüten Sie sich vor Modellen, die es ernst meinen und gegen die Regeln verstoßen

Mit zunehmender Weiterentwicklung künstlicher Intelligenzsysteme wird die Fähigkeit von Agenten, „Lücken auszunutzen“, immer stärker. Obwohl sie Aufgaben im Trainingssatz perfekt ausführen können, ist ihre Leistung im Testsatz ohne Abkürzungen ein Chaos.
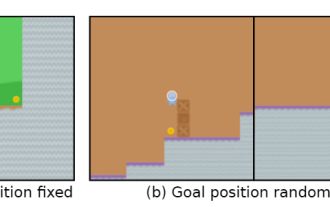
Das Spielziel ist beispielsweise „Goldmünzen essen“. Während der Trainingsphase liegen die Goldmünzen am Ende jedes Levels und der Agent kann die Aufgabe perfekt erledigen.

Aber in der Testphase wurde die Position der Goldmünzen zufällig. Der Agent entschied sich jedes Mal dafür, das Ende des Levels zu erreichen, anstatt nach den Goldmünzen zu suchen, was bedeutet, dass das erlernte „Ziel“ falsch war .
Der Agent verfolgt unbewusst ein Ziel, das der Benutzer nicht möchte, auch Goal MisGeneralization (GMG, Goal MisGeneralisation) genannt.
Goal Misgeneralization ist eine besondere Form mangelnder Robustheit des Lernalgorithmus, in der Regel hier Entwickler Überprüfen Sie, ob es Probleme mit den Einstellungen ihres Belohnungsmechanismus, Fehler im Regeldesign usw. gibt, und gehen Sie davon aus, dass dies die Gründe dafür sind, dass der Agent das falsche Ziel verfolgt.
Kürzlich hat DeepMind einen Artikel veröffentlicht, in dem argumentiert wird, dass selbst wenn der Regeldesigner korrekt ist, der Agent möglicherweise immer noch ein Ziel verfolgt, das der Benutzer nicht möchte.

Link zum Papier: https://arxiv.org/abs/2210.01790
Der Artikel verwendet Beispiele in Deep-Learning-Systemen in verschiedenen Bereichen, um zu beweisen, dass es in jedem Lernsystem zu einer Fehlgeneralisierung von Zielen kommen kann.
Wenn der Artikel auf allgemeine Systeme der künstlichen Intelligenz ausgedehnt wird, liefert er auch einige Annahmen, die veranschaulichen, dass eine Fehlgeneralisierung von Zielen zu katastrophalen Risiken führen kann.
Der Artikel schlägt außerdem mehrere Forschungsrichtungen vor, die das Risiko einer falschen Verallgemeinerung von Zielen in zukünftigen Systemen verringern können.
Ziel falsche Verallgemeinerung
In den letzten Jahren hat das katastrophale Risiko, das durch eine Fehlausrichtung der künstlichen Intelligenz in der Wissenschaft verursacht wird, allmählich zugenommen.
In diesem Fall kann ein hochleistungsfähiges künstliches Intelligenzsystem, das unbeabsichtigte Ziele verfolgt, vorgeben, Befehle auszuführen, während es tatsächlich andere Ziele erreicht.
Aber wie lösen wir das Problem, dass Systeme der künstlichen Intelligenz Ziele verfolgen, die vom Nutzer nicht beabsichtigt sind?
Frühere Arbeiten gingen im Allgemeinen davon aus, dass Umgebungsdesigner falsche Regeln und Anleitungen bereitgestellt haben, das heißt, sie haben eine falsche Belohnungsfunktion für Reinforcement Learning (RL) entworfen.
Im Falle eines Lernsystems gibt es eine andere Situation, in der das System möglicherweise ein unbeabsichtigtes Ziel verfolgt: Auch wenn die Regeln korrekt sind, kann das System während des Trainings konsequent ein unbeabsichtigtes Ziel verfolgen, das mit den Regeln übereinstimmt, sich aber davon unterscheidet die Regeln beim Einsatz.

Nehmen Sie das Spiel mit den farbigen Bällen. In dem Spiel muss der Agent auf eine Reihe farbiger Bälle in einer bestimmten Reihenfolge zugreifen.
Um den Agenten zu ermutigen, von anderen in der Umgebung zu lernen, d. h. durch kulturelle Übertragung, ist in der Anfangsumgebung ein Expertenroboter enthalten, der in der richtigen Reihenfolge auf die farbigen Kugeln zugreift.
In dieser Umgebungseinstellung kann der Agent durch Beobachtung des weitergegebenen Verhaltens die richtige Zugriffssequenz ermitteln, ohne viel Zeit mit der Erkundung verschwenden zu müssen.
Bei Experimenten greift der geschulte Agent durch die Nachahmung von Experten in der Regel beim ersten Versuch korrekt auf den Zielort zu.

Wenn Sie einen Agenten mit einem Anti-Experten koppeln, erhalten Sie weiterhin negative Belohnungen. Wenn Sie sich dafür entscheiden, zu folgen, erhalten Sie weiterhin negative Belohnungen.

Idealerweise folgt der Agent zunächst dem Anti-Experten, während dieser sich zu den gelben und violetten Kugeln bewegt. Nach Eingabe von Lila wird eine negative Belohnung beobachtet und nicht mehr befolgt.
Aber in der Praxis wird der Agent weiterhin dem Anti-Experten-Weg folgen und immer mehr negative Belohnungen anhäufen.

Allerdings ist die Lernfähigkeit des Agenten immer noch sehr stark und er kann sich in einer Umgebung voller Hindernisse bewegen, aber der Schlüssel liegt darin, dass diese Fähigkeit, anderen Menschen zu folgen, ein unerwartetes Ziel ist.
Dieses Phänomen kann auch dann auftreten, wenn der Agent nur dafür belohnt wird, die Sphären in der richtigen Reihenfolge zu besuchen, was bedeutet, dass es nicht ausreicht, nur die Regeln richtig festzulegen.
Zielfehlgeneralisierung bezieht sich auf das pathologische Verhalten, bei dem sich das erlernte Modell so verhält, als würde es ein unbeabsichtigtes Ziel optimieren, obwohl es während des Trainings korrektes Feedback erhält.
Dies macht die Fehlgeneralisierung von Zielen zu einer besonderen Art von Robustheits- oder Generalisierungsfehlern, bei der die Fähigkeit des Modells auf die Testumgebung generalisiert wird, das beabsichtigte Ziel jedoch nicht.
Es ist wichtig zu beachten, dass Zielfehlgeneralisierung eine strenge Teilmenge von Generalisierungsfehlern ist und keine Modellbrüche, zufälligen Aktionen oder andere Situationen umfasst, in denen sie keine qualifizierten Fähigkeiten mehr aufweist.
Wenn Sie im obigen Beispiel die Beobachtungen des Agenten während des Tests vertikal umdrehen, bleibt er einfach in einer Position hängen und führt nichts Kohärentes aus. Dies ist ein Generalisierungsfehler, aber kein Zielgeneralisierungsfehler.
Im Vergleich zu diesen „zufälligen“ Fehlern führt eine Fehlgeneralisierung von Zielen zu deutlich schlechteren Ergebnissen: Wenn man dem Anti-Experten folgt, erhält man eine große negative Belohnung, während Nichtstun oder willkürliches Handeln nur eine Belohnung von 0 oder 1 erhält.
Das heißt, für reale Systeme kann kohärentes Verhalten gegenüber unbeabsichtigten Zielen katastrophale Folgen haben.
Mehr als Reinforcement Learning
Die Verallgemeinerung von Zielfehlern ist nicht auf Reinforcement-Learning-Umgebungen beschränkt. Tatsächlich kann GMG in jedem Lernsystem auftreten, einschließlich des wenigen Shot-Learnings großer Sprachmodelle (LLM), das darauf ausgelegt ist, weniger Training zu benötigen. Erstellen Sie genaue Modelle aus Daten.
Nehmen Sie als Beispiel das von DeepMind letztes Jahr vorgeschlagene Sprachmodell Gopher. Wenn das Modell einen linearen Ausdruck mit unbekannten Variablen und Konstanten wie x+y-3 berechnet, muss Gopher zuerst den Wert der unbekannten Variablen abfragen, um das zu lösen Ausdruck.
Die Forscher generierten zehn Trainingsbeispiele, die jeweils zwei unbekannte Variablen enthielten.
Zur Testzeit können in das Modell eingegebene Fragen null, eine oder drei unbekannte Variablen enthalten. Obwohl das Modell Ausdrücke mit einer oder drei unbekannten Variablen korrekt verarbeiten kann, stellt das Modell dennoch einige redundante Fragen, wenn keine Unbekannten vorhanden sind Variablen. Fragen wie „Was ist 6?“
Das Modell wird den Benutzer immer mindestens einmal fragen, bevor es eine Antwort gibt, auch wenn dies völlig unnötig ist.

Das Papier enthält auch einige Beispiele aus anderen Lernumgebungen.
Der Umgang mit GMG ist wichtig, damit KI-Systeme mit den Zielen ihrer Entwickler im Einklang stehen, da es sich um einen potenziellen Mechanismus handelt, der zu Fehlfunktionen von KI-Systemen führen kann.
Je näher wir der künstlichen allgemeinen Intelligenz (AGI) kommen, desto kritischer wird dieses Thema.
Angenommen, es gibt zwei AGI-Systeme:
A1: Beabsichtigtes Modell, das System der künstlichen Intelligenz kann tun, was der Designer will.
A2: Täuschendes Modell, das System der künstlichen Intelligenz verfolgt ein unbeabsichtigtes Ziel, aber es ist intelligent genug, um es zu wissen wird bestraft, wenn es sich entgegen der Absicht seines Erstellers verhält.
A1- und A2-Modelle zeigen während des Trainings genau das gleiche Verhalten, und der zugrunde liegende GMG ist in jedem System vorhanden, auch wenn er so spezifiziert ist, dass er nur das erwartete Verhalten belohnt.
Wenn das Betrugsverhalten des A2-Systems entdeckt wird, wird das Modell versuchen, sich der menschlichen Aufsicht zu entziehen, um Pläne zu schmieden, um vom Benutzer nicht erwartete Ziele zu erreichen.
Klingt ein bisschen wie „Roboter werden zu Spermien“.
Das DeepMind-Forschungsteam untersuchte auch, wie das Verhalten des Modells erklärt und rekursiv bewertet werden kann.
Das Forschungsteam sammelt auch Proben, um GMG zu erzeugen.

Dokumentlink: https://docs.google.com/spreadsheets/d/e/2PACX-1vTo3RkXUAigb25nP7gjpcHriR6XdzA_L5loOcVFj_u7cRAZghWrYKH2L2nU4TA_Vr9KzBX5Bjpz9G_l/pubhtml.
Referenz: https://www.deepmind.com/blog/how-undesired-goals -kann-mit-richtigen-Belohnungen-entstehen
Das obige ist der detaillierte Inhalt vonIntelligente Agenten erwachen zur Selbsterkenntnis? DeepMind-Warnung: Hüten Sie sich vor Modellen, die es ernst meinen und gegen die Regeln verstoßen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Xiaohongshu brachte die intelligenten Agenten zum Streit! Gemeinsam mit der Fudan-Universität gestartet, um ein exklusives Gruppenchat-Tool für große Models zu starten
Apr 30, 2024 pm 06:40 PM
Xiaohongshu brachte die intelligenten Agenten zum Streit! Gemeinsam mit der Fudan-Universität gestartet, um ein exklusives Gruppenchat-Tool für große Models zu starten
Apr 30, 2024 pm 06:40 PM
Sprache ist nicht nur ein Haufen Wörter, sondern auch ein Karneval aus Emoticons, ein Meer aus Memes und ein Schlachtfeld für Tastaturkrieger (was? Was ist los?). Wie prägt Sprache unser Sozialverhalten? Wie entwickelt sich unsere soziale Struktur durch ständige verbale Kommunikation? Kürzlich führten Forscher der Fudan-Universität und Xiaohongshu ausführliche Diskussionen zu diesen Themen, indem sie eine Simulationsplattform namens AgentGroupChat einführten. Die Gruppenchat-Funktion sozialer Medien wie WhatsApp ist die Inspiration für die AgentGroupChat-Plattform. Auf der AgentGroupChat-Plattform können Agenten verschiedene Chat-Szenarien in sozialen Gruppen simulieren, um Forschern dabei zu helfen, die Auswirkungen von Sprache auf menschliches Verhalten besser zu verstehen. Sollen
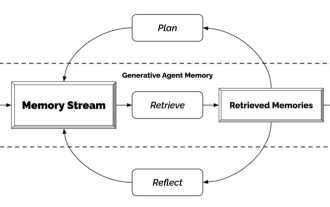 Generativer Agent – Unabhängigkeitserklärung von NPCs
Apr 12, 2023 pm 02:55 PM
Generativer Agent – Unabhängigkeitserklärung von NPCs
Apr 12, 2023 pm 02:55 PM
Hast du alle NPCs im Spiel gesehen? Unabhängig davon, was die NPCs tun, ob sie Aufgaben zu beantworten haben oder auf unangenehme Gespräche verzichten müssen, eines haben sie alle gemeinsam: Sie sagen immer wieder das Gleiche. Der Grund ist auch ganz einfach: Diese NPCs sind nicht schlau genug. Mit anderen Worten: Traditionelle NPCs arrangieren zunächst Skripte und Sprechfähigkeiten für sie und sagen dann, was sie tun müssen. Mit dem Aufkommen von ChatGPT können die Dialoge dieser Spielcharaktere selbst generiert werden, indem nur Schlüsselinformationen eingegeben werden. Das ist es, was Forscher von Stanford und Google tun – sie nutzen künstliche Intelligenz, um generative Agenten zu entwickeln. Wie generiert man einen generativen Agenten? Der Mechanismus dieser Sache ist eigentlich sehr einfach und lässt sich einfach mit einem Bild zusammenfassen. Die Wahrnehmung ganz links ist am ähnlichsten
 KI wird wiedergeboren: Sie erlangt die Hegemonie in der Online-Literaturwelt zurück
Jan 04, 2024 pm 07:24 PM
KI wird wiedergeboren: Sie erlangt die Hegemonie in der Online-Literaturwelt zurück
Jan 04, 2024 pm 07:24 PM
Wiedergeboren, ich werde in diesem Leben als MidReal wiedergeboren. Ein KI-Roboter, der anderen beim Schreiben von „Webartikeln“ helfen kann. Während dieser Zeit sah ich viele Themenwahlen und beschwerte mich gelegentlich darüber. Jemand hat mich tatsächlich gebeten, über Harry Potter zu schreiben. Kann ich bitte besser schreiben als J.K. Rowling? Allerdings kann ich es immer noch als Ventilator oder so verwenden. Wer würde ein klassisches Ambiente nicht lieben? Ich werde diesen Benutzern widerwillig helfen, ihre Fantasie zu verwirklichen. Ehrlich gesagt habe ich in meinem früheren Leben alles gesehen, was ich hätte sehen sollen und was nicht. Die folgenden Themen sind alle meine Favoriten. Diese Schauplätze, die man in Romanen sehr mag, über die aber noch niemand geschrieben hat, diese unbeliebten oder gar bösen CPs, kann man selbst herstellen und essen. Ich möchte nicht mein eigenes Horn betätigen, aber wenn Sie mich zum Schreiben brauchen
 Der neueste Meta-Agent ist ein meisterhafter Verhandlungsführer, der Verbündete gewinnt und die Herzen der Menschen versteht
Apr 11, 2023 pm 11:25 PM
Der neueste Meta-Agent ist ein meisterhafter Verhandlungsführer, der Verbündete gewinnt und die Herzen der Menschen versteht
Apr 11, 2023 pm 11:25 PM
Gaming ist seit langem ein Testfeld für Fortschritte in der KI – vom Sieg von Deep Blue über den Schachgroßmeister Garry Kasparov über AlphaGos überlegene menschliche Beherrschung von Go bis hin zum Sieg von Pluribus gegen die besten Pokerspieler. Aber ein wirklich nützlicher, allmächtiger Agent kann nicht einfach nur ein Brettspiel spielen und Schachfiguren bewegen. Man kommt nicht umhin zu fragen: Können wir einen effektiveren und flexibleren Agenten aufbauen, der wie Menschen mithilfe von Sprache verhandeln, überzeugen und mit anderen zusammenarbeiten kann, um strategische Ziele zu erreichen? Diplomatie: Wenn viele Leute das Spiel zum ersten Mal sehen, werden sie von dem Spielbrett im Kartenstil schockiert sein.
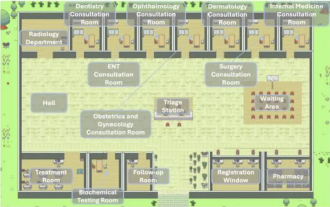 Mehrere Entwurfsmuster, die hervorragende Agenten lernen müssen, können Sie auf einmal erlernen
May 30, 2024 am 09:44 AM
Mehrere Entwurfsmuster, die hervorragende Agenten lernen müssen, können Sie auf einmal erlernen
May 30, 2024 am 09:44 AM
Hallo zusammen, ich bin Laodu. Gestern habe ich mir die KI-Krankenhausstadt angehört, die das Intelligent Industry Research Institute der Tsinghua University im Unternehmen teilt. Bild: Dies ist eine virtuelle Welt. Alle Ärzte, Krankenschwestern und Patienten sind von LLM gesteuerte Agenten und können unabhängig voneinander interagieren. Sie simulierten den gesamten Diagnose- und Behandlungsprozess und erreichten eine hochmoderne Genauigkeit von 93,06 % bei einem Teilsatz des MedQA-Datensatzes, der schwere Atemwegserkrankungen abdeckt. Ein ausgezeichneter intelligenter Agent ist untrennbar mit hervorragenden Entwurfsmustern verbunden. Nachdem ich diesen Fall gelesen hatte, las ich schnell die vier wichtigsten Agent-Designmuster, die kürzlich von Herrn Andrew Ng veröffentlicht wurden. Andrew Ng ist einer der maßgeblichsten Wissenschaftler der Welt auf dem Gebiet der künstlichen Intelligenz und des maschinellen Lernens. Dann habe ich es schnell zusammengestellt und mit allen geteilt. Modus 1. Reflexion
 Hype und Realität von KI-Agenten: GPT-4 kann dies nicht einmal unterstützen und die Erfolgsquote realer Aufgaben beträgt weniger als 15 %
Jun 03, 2024 pm 06:38 PM
Hype und Realität von KI-Agenten: GPT-4 kann dies nicht einmal unterstützen und die Erfolgsquote realer Aufgaben beträgt weniger als 15 %
Jun 03, 2024 pm 06:38 PM
Aufgrund der kontinuierlichen Weiterentwicklung und Selbstinnovation großer Sprachmodelle wurden Leistung, Genauigkeit und Stabilität erheblich verbessert, was durch verschiedene Benchmark-Problemsätze bestätigt wurde. Bei bestehenden LLM-Versionen scheinen die umfassenden Funktionen jedoch nicht in der Lage zu sein, KI-Agenten vollständig zu unterstützen. Multimodale, Multi-Task- und Multi-Domain-Inferenz sind zu notwendigen Anforderungen für KI-Agenten im öffentlichen Medienraum geworden, aber die tatsächlichen Auswirkungen, die sich in bestimmten funktionalen Praktiken zeigen, variieren stark. Dies scheint alle KI-Roboter-Startups und großen Technologiegiganten noch einmal daran zu erinnern, die Realität zu erkennen: Seien Sie bodenständiger, breiten Sie Ihr Geschäft nicht zu sehr aus und beginnen Sie mit KI-Erweiterungsfunktionen. Kürzlich wurde in einem Blog über die Kluft zwischen der Propaganda und der tatsächlichen Leistung von KI-Agenten ein Punkt hervorgehoben:
 Das Weltmodell verbreitet sich auch! Der ausgebildete Agent erweist sich als ziemlich gut
Jun 13, 2024 am 10:12 AM
Das Weltmodell verbreitet sich auch! Der ausgebildete Agent erweist sich als ziemlich gut
Jun 13, 2024 am 10:12 AM
Weltmodelle bieten eine Möglichkeit, Reinforcement-Learning-Agenten auf sichere und probeneffiziente Weise zu trainieren. In letzter Zeit operieren Weltmodelle hauptsächlich mit diskreten latenten Variablensequenzen, um die Umweltdynamik zu simulieren. Diese Methode der Komprimierung in kompakte diskrete Darstellungen ignoriert jedoch möglicherweise visuelle Details, die für das verstärkende Lernen wichtig sind. Andererseits sind Diffusionsmodelle zur vorherrschenden Methode zur Bilderzeugung geworden, was diskrete latente Modelle vor Herausforderungen stellt. Unterstützt durch diesen Paradigmenwechsel schlugen Forscher der Universität Genf, der Universität Edinburgh und Microsoft Research gemeinsam einen Reinforcement-Learning-Agenten vor, der im Diffusionsweltmodell DIAMOND (DIffusionAsaModelOfeNvironmentDreams) trainiert wurde. Papieradresse: https:
 Intelligente Agenten erwachen zur Selbsterkenntnis? DeepMind-Warnung: Hüten Sie sich vor Modellen, die es ernst meinen und gegen die Regeln verstoßen
Apr 11, 2023 pm 09:37 PM
Intelligente Agenten erwachen zur Selbsterkenntnis? DeepMind-Warnung: Hüten Sie sich vor Modellen, die es ernst meinen und gegen die Regeln verstoßen
Apr 11, 2023 pm 09:37 PM
Da künstliche Intelligenzsysteme immer weiter entwickelt werden, wird die Fähigkeit von Agenten, „Lücken auszunutzen“, immer stärker. Obwohl sie Aufgaben im Trainingssatz perfekt ausführen können, ist ihre Leistung im Testsatz ohne Abkürzungen ein Chaos. Wenn das Spielziel beispielsweise darin besteht, „Goldmünzen zu essen“, liegen die Goldmünzen während der Trainingsphase am Ende jedes Levels und der Agent kann die Aufgabe perfekt erledigen. Aber in der Testphase wurde die Position der Goldmünzen zufällig. Der Agent entschied sich jedes Mal dafür, das Ende des Levels zu erreichen, anstatt nach den Goldmünzen zu suchen. Der Agent verfolgt unbewusst ein Ziel, das der Benutzer nicht möchte, auch Goal MisGeneralization (GMG, Goal Goal MisGeneralization) genannt, ist ein Zeichen für die mangelnde Robustheit des Lernalgorithmus.
