

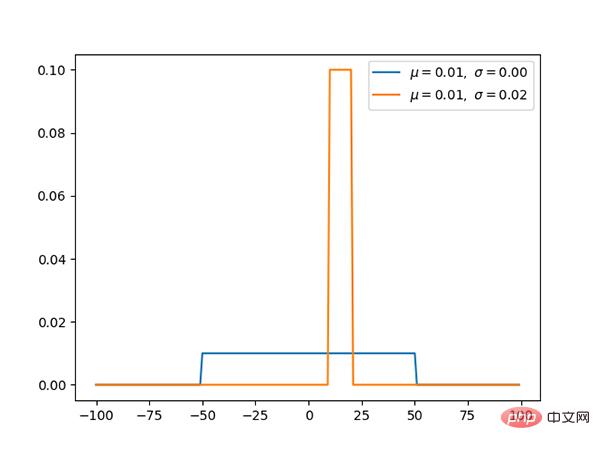
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/uniform.py
Die Gleichverteilung hat den gleichen Wahrscheinlichkeitswert für [a, b] und ist eine einfache Wahrscheinlichkeitsverteilung.
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/bernoulli.py
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/binomial.py
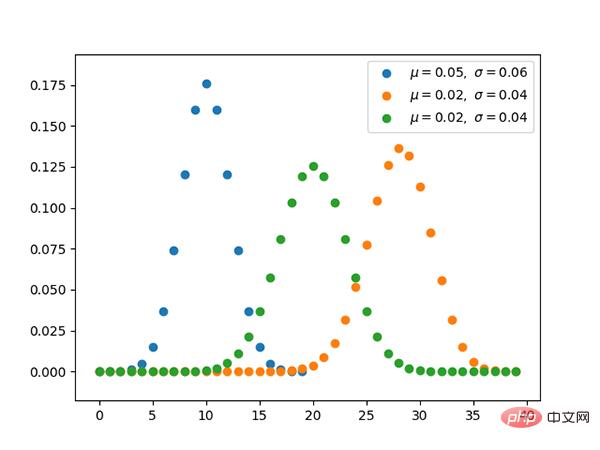
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/categorical.py
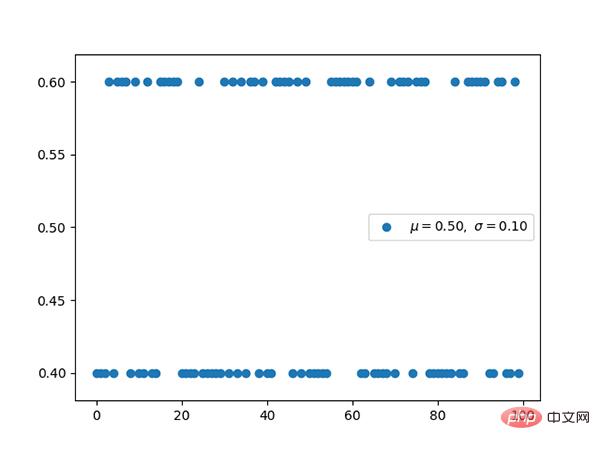
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/multinomial.py
Polynomverteilung und Klassifizierung Die Beziehung zwischen den Verteilungen ist dieselbe wie die Beziehung zwischen der Bernoul-Verteilung und der Binomialverteilung.
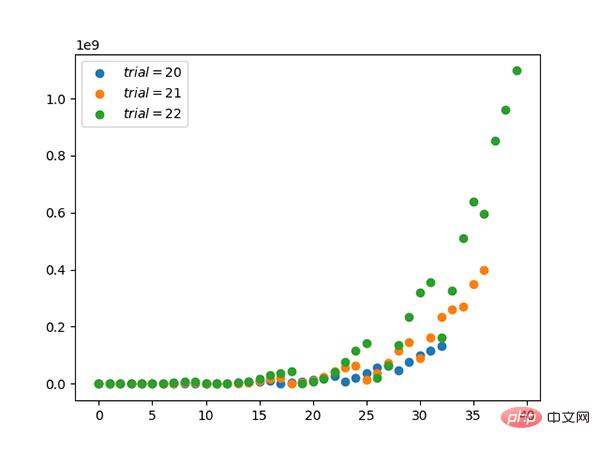
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/beta.py
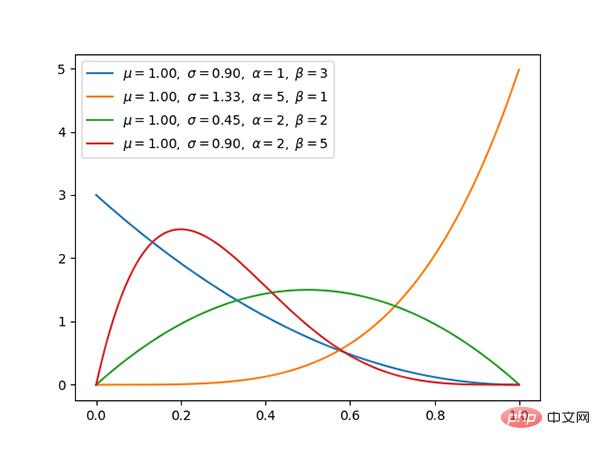
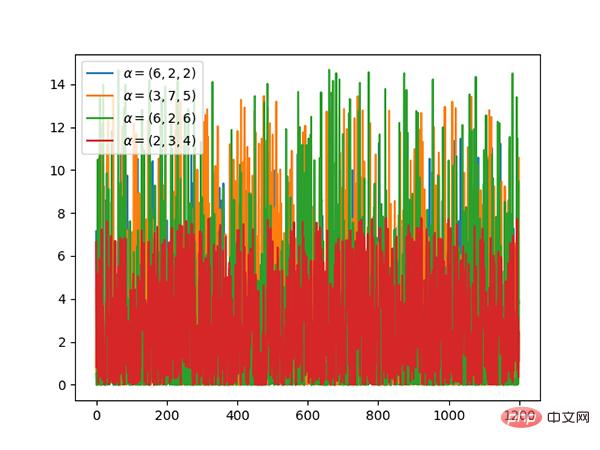
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/dirichlet.py
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/gamma.py
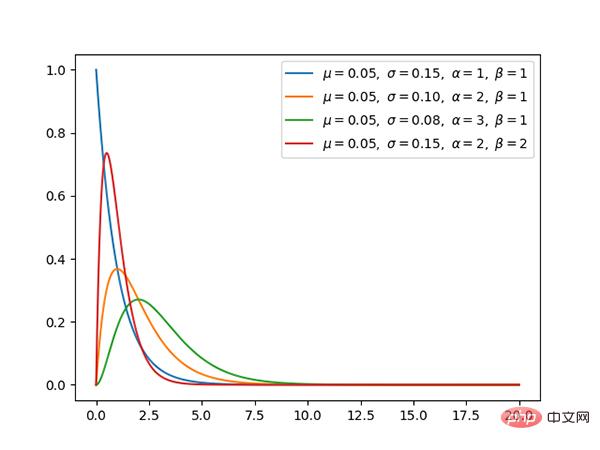
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/exponential.py
Die Exponentialverteilung ist ein Sonderfall der γ-Verteilung, wenn α 1 ist.
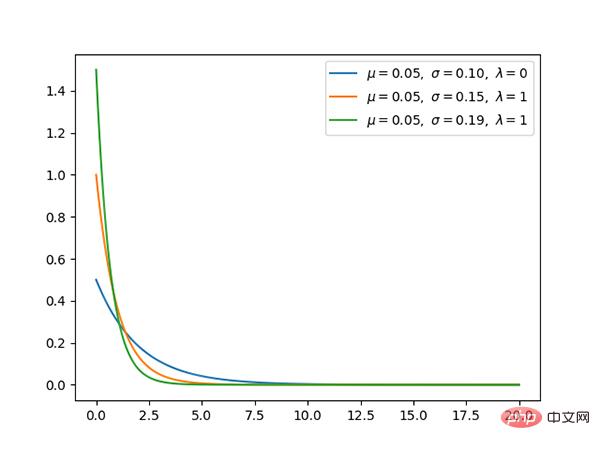
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/gaussian.py
Die Gaußsche Verteilung ist eine Sehr häufige kontinuierliche Wahrscheinlichkeitsverteilung.
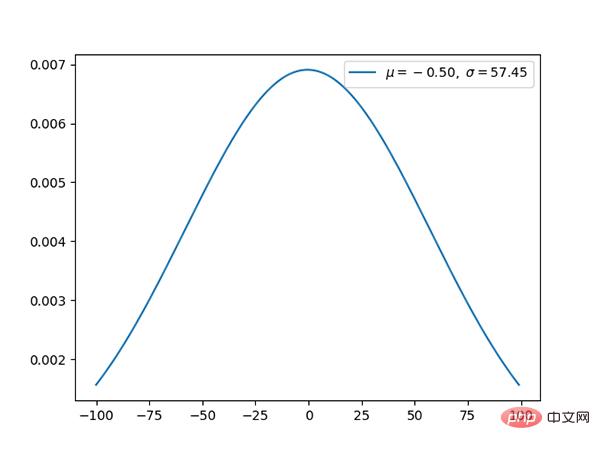
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/normal.py
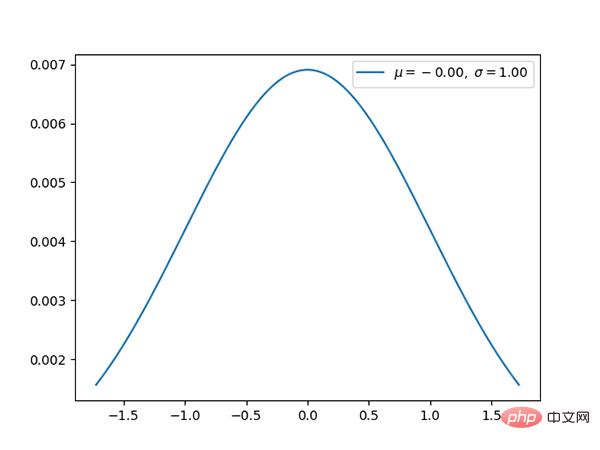
Die Normalverteilung ist The Die Standard-Gauß-Verteilung hat einen Mittelwert von 0 und eine Standardabweichung von 1.
Code: https://github.com/graykode/distribution-is-all-you-need/blob/master/chi-squared.py
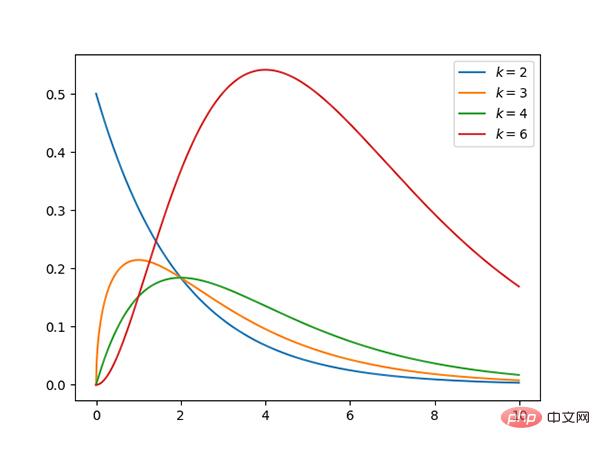
Code: https://github.com/graykode/distribution-is-all-you-need/ blob/master /student-t.py
t Die Verteilung ist symmetrisch, glockenförmig, ähnlich der Normalverteilung, hat aber schwerere Enden, was bedeutet, dass sie mit größerer Wahrscheinlichkeit Werte erzeugt, die deutlich unter dem Mittelwert liegen.
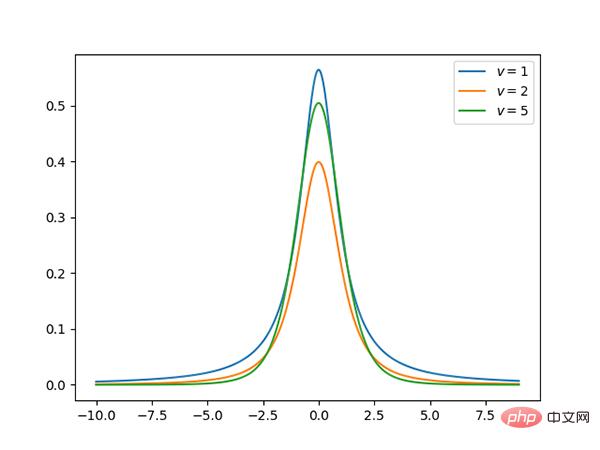
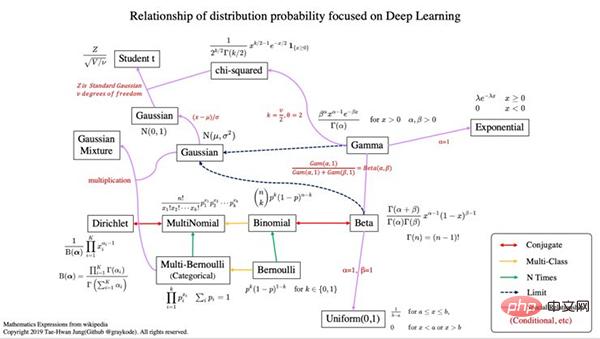
über: https://github.com/graykode/distribution-is-all-you-needa
Das obige ist der detaillierte Inhalt von13 Wahrscheinlichkeitsverteilungen, die beim Deep Learning beherrscht werden müssen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So importieren Sie MDF-Dateien in die Datenbank
So importieren Sie MDF-Dateien in die Datenbank
 Überprüfen Sie den Status der belegten Ports in Windows
Überprüfen Sie den Status der belegten Ports in Windows
 Die Rolle des „Bitte nicht stören'-Modus von Apple
Die Rolle des „Bitte nicht stören'-Modus von Apple
 So kehren Sie in HTML zur Startseite zurück
So kehren Sie in HTML zur Startseite zurück
 Was ist ein kollaboratives Büro?
Was ist ein kollaboratives Büro?
 So verhindern Sie, dass der Computer automatisch Software installiert
So verhindern Sie, dass der Computer automatisch Software installiert
 location.hash
location.hash
 So überprüfen Sie die Mac-Adresse
So überprüfen Sie die Mac-Adresse








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



