
 Technologie-Peripheriegeräte
KI
Kann BERT auch auf CNN verwendet werden? Die Forschungsergebnisse von ByteDance wurden für das ICLR 2023 Spotlight ausgewählt
Technologie-Peripheriegeräte
KI
Kann BERT auch auf CNN verwendet werden? Die Forschungsergebnisse von ByteDance wurden für das ICLR 2023 Spotlight ausgewählt
Kann BERT auch auf CNN verwendet werden? Die Forschungsergebnisse von ByteDance wurden für das ICLR 2023 Spotlight ausgewählt

Wie führt man BERT in einem Faltungs-Neuronalen Netzwerk aus?
Sie können SparK direkt verwenden – Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling, vorgeschlagen vom technischen Team von ByteDance, das kürzlich von der künstlichen Intelligenz anerkannt wurde Als Spotlight-Fokuspapier enthalten:

Papierlink:
https://www.php.c efcdb288dd1
Offener Quellcode:
https://www.php.cn/link/9dfcf16f0adbc5e2a55ef02db36bac7f
Dies ist auch der erste Erfolg von BERT auf Convolutional Neural Network (CNN). Lassen Sie uns zunächst die Leistung von SparK im Vortraining erleben.
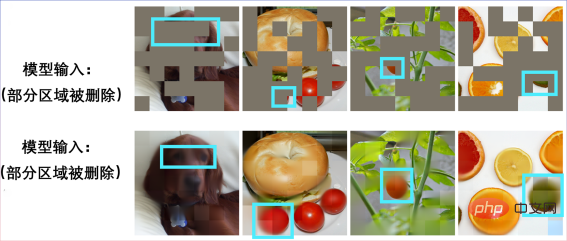
Geben Sie ein unvollständiges Bild ein:

Einen Welpen wiederherstellen:

Noch ein unvollständiges Bild:

Es stellte sich heraus, dass es sich um ein Bagel-Sandwich handelte:

Andere Szenen können auch eine Bildwiederherstellung erreichen:

BERT und Transformer Ein himmlisches Spiel
"Jede großartige Handlung und jeder großartige Gedanke hat einen bescheidenen Anfang."
Hinter dem BERT-Vortrainingsalgorithmus steckt ein einfaches und tiefgreifendes Design. BERT verwendet „Lückentext“: Löschen Sie nach dem Zufallsprinzip mehrere Wörter in einem Satz und lassen Sie das Modell lernen, sich wiederherzustellen.
BERT verlässt sich stark auf das Kernmodell im NLP-Bereich – Transformer.
Transformer eignet sich natürlich für die Verarbeitung von Sequenzdaten variabler Länge (z. B. einen englischen Satz) und kommt daher problemlos mit dem „zufälligen Löschen“ von BERT-Lückentexten zurecht.
CNN im visuellen Bereich möchte auch BERT genießen: Was sind die beiden Herausforderungen?
Rückblickend auf die Geschichte der Computer-Vision-Entwicklung: Das Faltungsmodell für neuronale Netze verdichtet die Essenz vieler klassischer Modelle wie translatorische Äquivarianz, Mehrskalenstruktur usw. und kann als Hauptstütze bezeichnet werden der CV-Welt. Der große Unterschied zu Transformer besteht jedoch darin, dass CNN von Natur aus nicht in der Lage ist, sich an Daten anzupassen, die durch Lückentexte „ausgehöhlt“ und voller „zufälliger Lücken“ sind, sodass es auf den ersten Blick nicht in den Genuss der Vorteile des BERT-Vortrainings kommen kann.
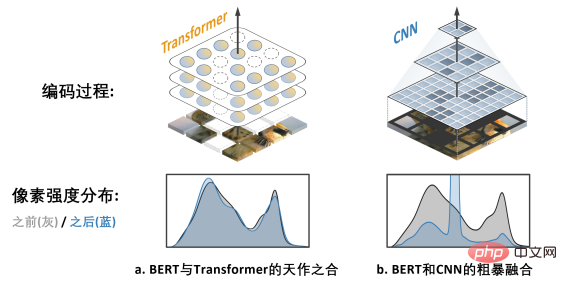
Das obige Bild zeigt die Arbeit von MAE (Masked Autoencoders are Scalable Visual Learners). Da es das Transformer-Modell anstelle des CNN-Modells verwendet, kann es sein flexibel Der Umgang mit Eingaben mit Löchern ist eine „natürliche Ergänzung“ zu BERT.
Das rechte Bild b zeigt eine grobe Möglichkeit, die BERT- und CNN-Modelle zu verschmelzen – das heißt, alle leeren Bereiche zu „schwärzen“ und dieses „schwarze Mosaik“-Bild in CNN einzugeben, das Ergebnis kann man sich vorstellen Dies führt zu einem schwerwiegenden Problem der Verschiebung der Pixelintensitätsverteilung und zu einer sehr schlechten Leistung (später überprüft). Dies ist die
Herausforderung 1, die die erfolgreiche Anwendung von BERT auf CNN behindert. Darüber hinaus wies das Autorenteam auch darauf hin, dass der aus dem NLP-Bereich stammende BERT-Algorithmus natürlich nicht die Eigenschaften von „Multi-Scale“ aufweist und die Multi-Scale-Pyramidenstruktur als beschrieben werden kann der „Goldstandard“ in der langen Geschichte der Computer Vision. Der Konflikt zwischen Single-Scale-BERT und natürlichem Multi-Scale-CNN ist
Herausforderung 2. Lösung SparK: Sparse and Hierarchical Mask Modeling
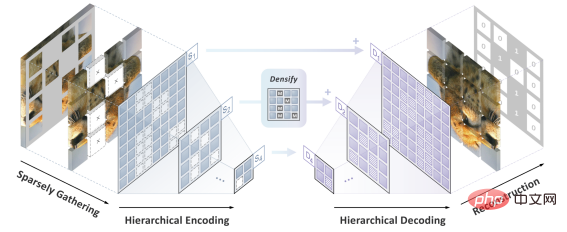
Das Autorenteam schlug SparK (Sparse. and Hierarchische maskierte Modellierung), um die beiden zu lösen bisherige Herausforderungen.
Inspiriert durch die Verarbeitung dreidimensionaler Punktwolkendaten schlug das Autorenteam zunächst vor, die fragmentierten Bilder nach der Maskierungsoperation (Aushöhlungsoperation) als spärliche Punktwolken zu behandeln und eine submanifold spärliche Faltung (Submanifold Sparse) zu verwenden Faltung) zu kodieren. Dadurch kann das Faltungsnetzwerk zufällig gelöschte Bilder problemlos verarbeiten.
Zweitens hat das Autorenteam, inspiriert vom eleganten Design von UNet, natürlich ein Encoder-Decoder-Modell mit seitlichen Verbindungen entworfen, um den Fluss von Multiskalenfunktionen zwischen mehreren Ebenen des Modells zu ermöglichen Multiskalen-Goldstandard für Computer Vision.
Zu diesem Zeitpunkt wurde SparK geboren, ein spärlicher, mehrskaliger Maskenmodellierungsalgorithmus, der auf Faltungsnetzwerke (CNN) zugeschnitten ist.
SparK ist
generisch: Es kann direkt auf jedes Faltungsnetzwerk angewendet werden, ohne dass dessen Struktur geändert oder zusätzliche Komponenten eingeführt werden müssen – sei es das bekannte klassische ResNet oder Mit dem aktuellen Weiterentwicklungsmodell ConvNeXt können Sie direkt von SparK profitieren. Von ResNet zu ConvNeXt: Leistungsverbesserung von drei großen visuellen Aufgaben
Das Autorenteam wählte zwei repräsentative Faltungsmodellfamilien, ResNet und ConvNeXt, aus und verwendete sie in der Bildklassifizierung, Leistung Es wurden Tests zu Zielerkennungs- und Instanzsegmentierungsaufgaben durchgeführt.
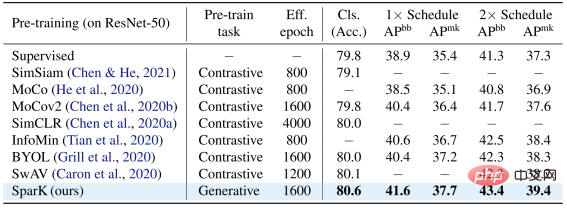
Auf dem klassischen ResNet-50-Modell dient SparK als einziges generatives Vortraining,
erreicht das State-of-the-Art-Niveau:
Auf dem ConvNeXt-Modell ist SparK immer noch führend . Vor dem Vortraining war ConvNeXt gleichauf mit Swin-Transformer; nach dem Vortraining übertraf ConvNeXt Swin-Transformer in drei Aufgaben bei weitem: In der Modellfamilie können Sie Folgendes beobachten:
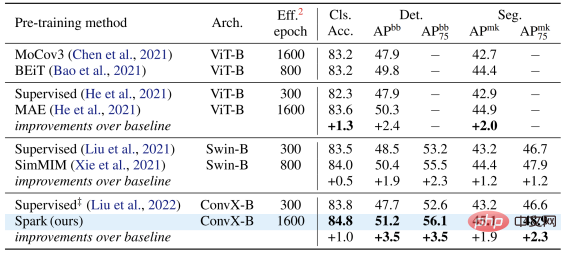 Egal, ob das Modell groß oder klein, neu oder alt ist, Sie können von SparK profitieren, und wenn die Modellgröße/der Schulungsaufwand zunimmt, ist der Anstieg sogar noch höher. was die Skalierungsfähigkeit des SparK-Algorithmus widerspiegelt:
Egal, ob das Modell groß oder klein, neu oder alt ist, Sie können von SparK profitieren, und wenn die Modellgröße/der Schulungsaufwand zunimmt, ist der Anstieg sogar noch höher. was die Skalierungsfähigkeit des SparK-Algorithmus widerspiegelt:
Schließlich entwarf das Autorenteam auch ein bestätigendes Ablationsexperiment, aus dem wir
sparse mask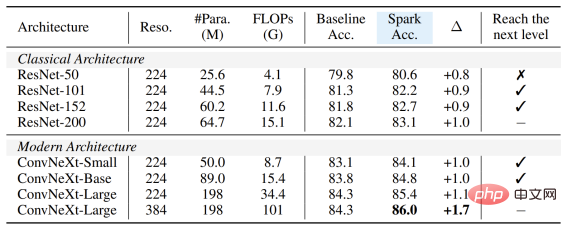
und sehen können Hierarchische Struktur Zeilen 3 und 4) sind beide sehr kritische Designs. Sobald sie fehlen, führt dies zu ernsthaften Leistungseinbußen:
Das obige ist der detaillierte Inhalt vonKann BERT auch auf CNN verwendet werden? Die Forschungsergebnisse von ByteDance wurden für das ICLR 2023 Spotlight ausgewählt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Die weltweiten Benutzerausgaben der Videobearbeitungs-App CapCut von ByteDance übersteigen 100 Millionen US-Dollar
Sep 14, 2023 pm 09:41 PM
Die weltweiten Benutzerausgaben der Videobearbeitungs-App CapCut von ByteDance übersteigen 100 Millionen US-Dollar
Sep 14, 2023 pm 09:41 PM
CapCut, ein kreatives Videobearbeitungstool von ByteDance, hat eine große Anzahl von Benutzern in China, den Vereinigten Staaten und Südostasien. Das Tool unterstützt Android-, iOS- und PC-Plattformen. Der neueste Bericht der Marktforschungsagentur data.ai wies darauf hin, dass die Gesamtausgaben der Nutzer von CapCut für iOS und Google Play am 11. September 2023 100 Millionen US-Dollar überschritten haben (Anmerkungen auf dieser Website: derzeit rund 7,28 Milliarden), überholte erfolgreich Splice (Platz 1 im zweiten Halbjahr 2022) und entwickelte sich im ersten Halbjahr 2023 zur weltweit profitabelsten Videobearbeitungsanwendung, was einer Steigerung von 180 % im Vergleich zum zweiten Halbjahr 2022 entspricht. Im August 2023 nutzen 490 Millionen Menschen auf der ganzen Welt CapCut über iPhone und Android-Telefone. da
 Bytedance-Modell groß angelegter Einsatz im tatsächlichen Kampf
Apr 12, 2023 pm 08:31 PM
Bytedance-Modell groß angelegter Einsatz im tatsächlichen Kampf
Apr 12, 2023 pm 08:31 PM
1. Einführung in den Hintergrund In ByteDance florieren überall Anwendungen, die auf Deep Learning basieren. Ingenieure achten auf den Modelleffekt, müssen aber auch auf die Konsistenz und Leistung von Online-Diensten achten und eine enge Zusammenarbeit zwischen Algorithmenexperten und Ingenieurexperten. Dieser Modus ist mit relativ hohen Kosten verbunden, z. B. für die Fehlerbehebung und Überprüfung von Diffs. Mit der Popularität des PyTorch/TensorFlow-Frameworks wurden Deep-Learning-Modelltraining und Online-Argumentation vereinheitlicht. Entwickler müssen nur noch auf die spezifische Algorithmuslogik achten und die Python-API des Frameworks aufrufen, um den Trainingsüberprüfungsprozess abzuschließen. Das Modell kann problemlos serialisiert und exportiert werden, und die Argumentationsarbeit wird durch eine einheitliche leistungsstarke C++-Engine vervollständigt. Verbesserte Entwicklererfahrung von der Schulung bis zur Bereitstellung
 Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Laut Nachrichten vom 13. Juni hat Xiaomis Assistent für künstliche Intelligenz „Xiao Ai“ laut Bytes öffentlichem Bericht „Volcano Engine“ eine Zusammenarbeit mit Volcano Engine erzielt. Die beiden Parteien werden ein intelligenteres interaktives KI-Erlebnis auf der Grundlage des großen Beanbao-Modells erzielen . Berichten zufolge kann das von ByteDance erstellte groß angelegte Beanbao-Modell bis zu 120 Milliarden Text-Tokens effizient verarbeiten und täglich 30 Millionen Inhalte generieren. Xiaomi nutzte das große Doubao-Modell, um die Lern- und Denkfähigkeiten seines eigenen Modells zu verbessern und einen neuen „Xiao Ai Classmate“ zu schaffen, der nicht nur die Benutzerbedürfnisse genauer erfasst, sondern auch eine schnellere Reaktionsgeschwindigkeit und umfassendere Inhaltsdienste bietet. Wenn ein Benutzer beispielsweise nach einem komplexen wissenschaftlichen Konzept fragt, &ldq
 Beschleunigen Sie das Diffusionsmodell und generieren Sie Bilder auf SOTA-Ebene im schnellsten Schritt. Byte Hyper-SD ist Open Source
Apr 25, 2024 pm 05:25 PM
Beschleunigen Sie das Diffusionsmodell und generieren Sie Bilder auf SOTA-Ebene im schnellsten Schritt. Byte Hyper-SD ist Open Source
Apr 25, 2024 pm 05:25 PM
In letzter Zeit hat DiffusionModel erhebliche Fortschritte im Bereich der Bildgenerierung gemacht und beispiellose Entwicklungsmöglichkeiten für Bild- und Videogenerierungsaufgaben eröffnet. Trotz der beeindruckenden Ergebnisse führen die mehrstufigen iterativen Entrauschungseigenschaften, die dem Inferenzprozess von Diffusionsmodellen innewohnen, zu hohen Rechenkosten. Kürzlich wurde eine Reihe von Diffusionsmodell-Destillationsalgorithmen entwickelt, um den Inferenzprozess von Diffusionsmodellen zu beschleunigen. Diese Methoden lassen sich grob in zwei Kategorien einteilen: i) bahnerhaltende Destillation; ii) bahnenerhaltende Destillation. Diese beiden Arten von Methoden werden jedoch durch die begrenzte Effektobergrenze oder Änderungen im Ausgabebereich eingeschränkt. Um diese Probleme zu lösen, schlug das technische Team von ByteDance einen Konsens zur Trajektoriensegmentierung namens Hyper-SD vor.
 Das Shenzhen Bytedance Houhai Center verfügt über eine Gesamtbaufläche von 77.400 Quadratmetern und die Hauptstruktur wurde fertiggestellt
Jan 24, 2024 pm 05:27 PM
Das Shenzhen Bytedance Houhai Center verfügt über eine Gesamtbaufläche von 77.400 Quadratmetern und die Hauptstruktur wurde fertiggestellt
Jan 24, 2024 pm 05:27 PM
Laut dem offiziellen öffentlichen WeChat-Account „Innovation Nanshan“ der Bezirksregierung von Nanshan hat das Shenzhen ByteDance Houhai Center-Projekt in letzter Zeit wichtige Fortschritte gemacht. Nach Angaben der China Construction First Engineering Bureau Construction and Development Company wurde die Hauptstruktur des Projekts drei Tage früher als geplant fertiggestellt. Diese Nachricht bedeutet, dass im Kerngebiet von Nanshan Houhai ein neues Wahrzeichengebäude entstehen wird. Das Shenzhen ByteDance Houhai Center-Projekt befindet sich im Kerngebiet von Houhai, Bezirk Nanshan. Es ist das Hauptbürogebäude von Toutiao Technology Co., Ltd. in Shenzhen. Die gesamte Baufläche beträgt 77.400 Quadratmeter, bei einer Höhe von etwa 150 Metern und insgesamt 4 Untergeschossen und 32 Obergeschossen. Es wird berichtet, dass das Shenzhen ByteDance Houhai Center-Projekt ein innovatives Superhochhaus werden wird, das Büro-, Unterhaltungs-, Catering- und andere Funktionen integriert. Dieses Projekt wird Shenzhen dabei helfen, die Integration der Internetbranche voranzutreiben
 NUS und Byte arbeiteten branchenübergreifend zusammen, um durch Modelloptimierung ein 72-mal schnelleres Training zu erreichen, und gewannen den AAAI2023 Outstanding Paper.
May 06, 2023 pm 10:46 PM
NUS und Byte arbeiteten branchenübergreifend zusammen, um durch Modelloptimierung ein 72-mal schnelleres Training zu erreichen, und gewannen den AAAI2023 Outstanding Paper.
May 06, 2023 pm 10:46 PM
Kürzlich gab die führende internationale Konferenz für künstliche Intelligenz AAAI2023 die Auswahlergebnisse bekannt. Der von der National University of Singapore (NUS) und dem ByteDance Machine Learning Team (AML) gemeinsam erstellte Fachartikel CowClip kam in die engere Wahl für „Distinguished Papers“ (Distinguished Papers). CowClip ist eine Strategie zur Modelltrainingsoptimierung, die die Modelltrainingsgeschwindigkeit auf einer einzelnen GPU um das 72-fache erhöhen und gleichzeitig die Modellgenauigkeit gewährleisten kann. Der entsprechende Code ist jetzt Open Source. Papieradresse: https://arxiv.org/abs/2204.06240Open-Source-Adresse: https://github.com/bytedance/LargeBatchCTRAAA
 Die Verkäufe von PICO 4 liegen weit unter den Erwartungen und Nachrichten berichten, dass ByteDance das VR-Headset PICO 5 der nächsten Generation einstellen wird
Dec 15, 2023 am 09:34 AM
Die Verkäufe von PICO 4 liegen weit unter den Erwartungen und Nachrichten berichten, dass ByteDance das VR-Headset PICO 5 der nächsten Generation einstellen wird
Dec 15, 2023 am 09:34 AM
Laut Nachrichten dieser Website vom 13. Dezember bereitet sich ByteDance laut The Information darauf vor, sein PICO-VR-Headset der neuen Generation PICO5 einzustellen, da die Verkaufszahlen des aktuellen PICO4 weitaus geringer ausfallen als erwartet. Einem Artikel von EqualOcean vom Oktober dieses Jahres zufolge soll ByteDance PICO schrittweise schließen und das Metaverse-Feld aufgeben. In dem Artikel wurde darauf hingewiesen, dass ByteDance der Ansicht ist, dass der Hardwarebereich, in dem PICO angesiedelt ist, nicht seine Expertise ist, dass seine Leistung in den letzten Jahren nicht den Erwartungen entsprochen hat und dass es ihm an Hoffnung für die Zukunft mangelt, so die zuständige Person von ByteDance antwortete auf die Gerüchte über eine „schrittweise Aufgabe des PICO-Geschäfts“ und sagte, die Nachricht sei unwahr. Sie sagten, dass das Geschäft von PICO weiterhin normal laufe und dass das Unternehmen langfristig in die erweiterte Realität investieren werde.
 ByteDance erweitert globale Forschungs- und Entwicklungszentren und entsendet Ingenieure nach Kanada, Australien und an andere Orte
Jan 18, 2024 pm 04:00 PM
ByteDance erweitert globale Forschungs- und Entwicklungszentren und entsendet Ingenieure nach Kanada, Australien und an andere Orte
Jan 18, 2024 pm 04:00 PM
Laut Nachrichten des IT House vom 18. Januar gaben Personen aus dem Umfeld von ByteDance als Reaktion auf die jüngsten Gerüchte, dass inländische Mitarbeiter von TikTok ins Ausland versetzt wurden, bekannt, dass das Unternehmen den Bau von Forschungs- und Entwicklungszentren in Kanada, Australien und anderen Orten vorbereitet. Derzeit sind einige Forschungs- und Entwicklungszentren seit etwa einem halben Jahr im Probebetrieb und werden in Zukunft die Forschung und Entwicklung mehrerer ausländischer Unternehmen wie TikTok, CapCut und Lemon8 unterstützen. ByteDance plant, sich auf die Rekrutierung vor Ort zu konzentrieren und durch eine kleine Anzahl von Expatriates beim Aufbau relevanter Forschungs- und Entwicklungszentren zu helfen. Es wird davon ausgegangen, dass das Unternehmen in den letzten sechs Monaten eine kleine Anzahl von Ingenieuren aus den USA, China, Singapur und anderen Ländern ausgewählt hat, um an den Vorbereitungen teilzunehmen. Darunter wurden insgesamt 120 Personen aus China in die Forschungs- und Entwicklungszentren an den beiden Orten entsandt, darunter Produkt-, Forschungs- und Entwicklungs- sowie Betriebspositionen. Relevante Personen sagten, dass dieser Schritt dazu dient, die Entwicklung des Auslandsgeschäfts besser zu bewältigen
