

Zehn Python-Tipps decken 90 % des Datenanalysebedarfs ab!

Die tägliche Arbeit von Datenanalysten umfasst verschiedene Aufgaben, wie z. B. Datenvorverarbeitung, Datenanalyse, Modellerstellung für maschinelles Lernen und Modellbereitstellung.
In diesem Artikel werde ich 10 Python-Operationen vorstellen, die 90 % der Datenanalyseprobleme abdecken können. Gewinnen Sie Likes, Favoriten und Aufmerksamkeit.
1. Das Lesen von Datensätzen
Das Lesen von Daten ist ein wesentlicher Bestandteil der Datenanalyse. Der erste Schritt für einen Datenanalysten ist. Hier ist ein Beispiel dafür, wie man mit Pandas eine CSV-Datei mit Covid-19-Daten liest.
import pandas as pd
# reading the countries_data file along with the location within read_csv function.
countries_df = pd.read_csv('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_data.csv')
# showing the first 5 rows of the dataframe
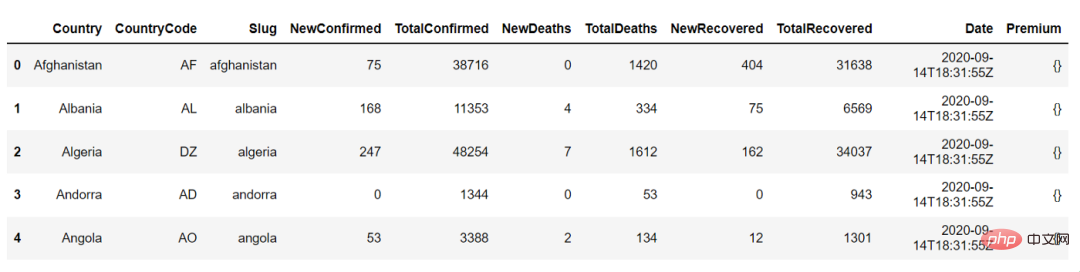
countries_df.head()
Das Folgende ist die Ausgabe von states_df.head(), wir können damit die ersten 5 Zeilen des Datenrahmens anzeigen:
2. Zusammenfassende Statistik
Der nächste Schritt besteht darin, die Daten zu verstehen Anzeigen der Datenzusammenfassung, z. B. NewConfirmed, der Anzahl, des Mittelwerts, der Standardabweichung, des Quantils numerischer Spalten wie TotalConfirmed sowie der Häufigkeit und des höchsten Vorkommenswerts kategorialer Spalten wie Ländercode
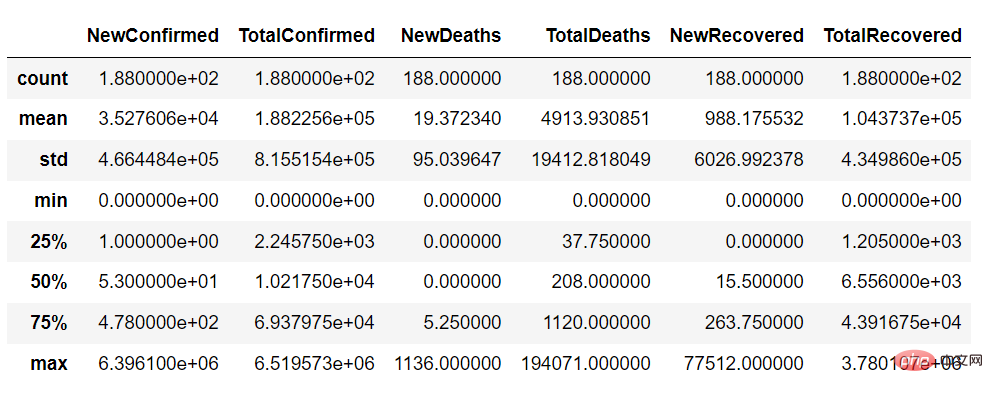
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">countries_df</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">describe</span>()
Mit der Beschreibungsfunktion können wir Folgendes erhalten eine Zusammenfassung der kontinuierlichen Variablen des Datensatzes wie folgt:
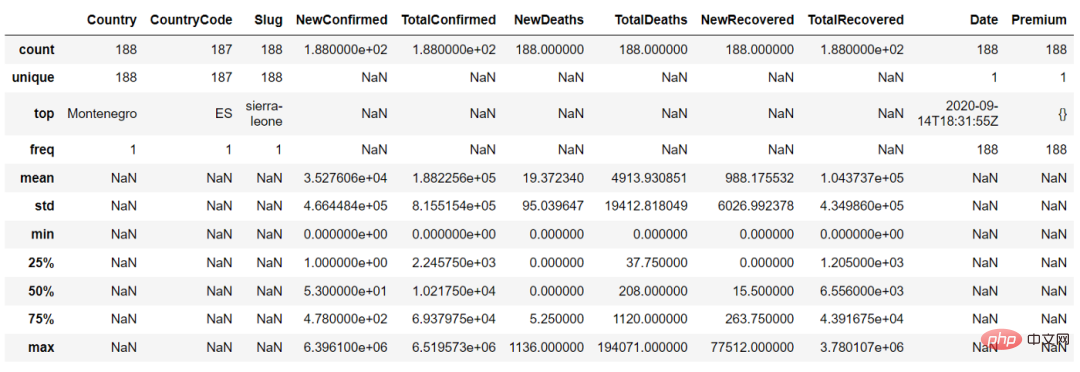
In der Funktion discover() können wir den Parameter „include = 'all'“ setzen, um die Zusammenfassung der kontinuierlichen Variablen und kategorialen Variablen zu erhalten
countries_df.describe(include = 'all')
3. Datenauswahl und -filterung
Für die Analyse ist eigentlich kein Datensatz aller Zeilen und Spalten erforderlich. Wählen Sie einfach die gewünschten Spalten aus und filtern Sie einige Zeilen basierend auf der Frage.
Zum Beispiel können wir den folgenden Code verwenden, um die Spalten „Land“ und „Neu bestätigt“ auszuwählen:
countries_df[['Country','NewConfirmed']]
Mit loc können wir die Spalten auch anhand einiger Werte wie folgt filtern:
countries_df.loc[countries_df['Country'] == 'United States of America']

4. Aggregation
Datenaggregation wie Zählungen, Summen und Durchschnittswerte sind eine der am häufigsten durchgeführten Aufgaben in der Datenanalyse.
Mit Hilfe der Aggregation können wir die Gesamtzahl der NewConfimed-Fälle nach Ländern ermitteln. Verwenden Sie die Funktionen „groupby“ und „agg“, um eine Aggregation durchzuführen.
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})5. Join
Verwenden Sie die Join-Operation, um zwei Datensätze zu einem Datensatz zu kombinieren.
Zum Beispiel: Ein Datensatz kann die Anzahl der Covid-19-Fälle in verschiedenen Ländern enthalten, ein anderer Datensatz kann Informationen zu Breiten- und Längengraden für verschiedene Länder enthalten.
Jetzt müssen wir diese beiden Informationen kombinieren, dann können wir den Verbindungsvorgang wie unten gezeigt ausführen
countries_lat_lon = pd.read_excel('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_lat_lon.xlsx')
# joining the 2 dataframe : countries_df and countries_lat_lon
# syntax : pd.merge(left_df, right_df, on = 'on_column', how = 'type_of_join')
joined_df = pd.merge(countries_df, countries_lat_lon, on = 'CountryCode', how = 'inner')
joined_df6 Eingebaute Funktionen
Verstehen Sie die mathematischen integrierten Funktionen wie min(), max(), mean(), sum() usw. sind sehr hilfreich für die Durchführung verschiedener Analysen.
Wir können diese Funktionen direkt auf den Datenrahmen anwenden, indem wir sie aufrufen. Diese Funktionen können unabhängig auf Spalten oder in Aggregatfunktionen verwendet werden, wie unten gezeigt:
# finding sum of NewConfirmed cases of all the countries
countries_df['NewConfirmed'].sum()
# Output : 6,631,899
# finding the sum of NewConfirmed cases across different countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})
# Output
#NewConfirmed
#Country
#Afghanistan75
#Albania 168
#Algeria 247
#Andorra0
#Angola537 Benutzerdefinierte Funktionen
Funktion, die wir selbst geschrieben haben. Es ist eine Benutzerdefinierte Funktion. Wir können den Code in diesen Funktionen bei Bedarf ausführen, indem wir die Funktion aufrufen. Wir können zum Beispiel eine Funktion erstellen, die zwei Zahlen wie folgt addiert:
# User defined function is created using 'def' keyword, followed by function definition - 'addition()' # and 2 arguments num1 and num2 def addition(num1, num2): return num1+num2 # calling the function using function name and providing the arguments print(addition(1,2)) #output : 3
8, Pivot
Pivot ist eine großartige Datenverarbeitungstechnik, die eindeutige Werte innerhalb einer Spaltenzeile in mehrere neue Spalten umwandelt.
Mit der Funktion „pivot_table()“ für den Covid-19-Datensatz können wir die Ländernamen in separate neue Spalten umwandeln:
# using pivot_table to convert values within the Country column into individual columns and # filling the values corresponding to these columns with numeric variable - NewConfimed pivot_df = pd.pivot_table(countries_df,columns = 'Country', values = 'NewConfirmed') pivot_df
9. Durchlaufen des Datenrahmens
Oft müssen wir die Indizes und Zeilen der Daten durchqueren Rahmen können wir die Funktion iterrows verwenden, um den Datenrahmen zu durchlaufen:
# iterating over the index and row of a dataframe using iterrows() function
for index, row in countries_df.iterrows():
print('Index is ' + str(index))
print('Country is '+ str(row['Country']))
# Output :
# Index is 0
# Country is Afghanistan
# Index is 1
# Country is Albania
# .......10. String-Operationen
Oft beschäftigen wir uns mit String-Spalten im Datensatz. In diesem Fall ist es wichtig, einige grundlegende String-Operationen zu verstehen.
Zum Beispiel, wie man eine Zeichenfolge in Groß- und Kleinbuchstaben umwandelt und wie man die Länge einer Zeichenfolge ermittelt.
# country column to upper case countries_df['Country_upper'] = countries_df['Country'].str.upper() # country column to lower case countries_df['CountryCode_lower']=countries_df['CountryCode'].str.lower() # finding length of characters in the country column countries_df['len'] = countries_df['Country'].str.len() countries_df.head()
Das obige ist der detaillierte Inhalt vonZehn Python-Tipps decken 90 % des Datenanalysebedarfs ab!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
Bei der Installation von PyTorch am CentOS -System müssen Sie die entsprechende Version sorgfältig auswählen und die folgenden Schlüsselfaktoren berücksichtigen: 1. Kompatibilität der Systemumgebung: Betriebssystem: Es wird empfohlen, CentOS7 oder höher zu verwenden. CUDA und CUDNN: Pytorch -Version und CUDA -Version sind eng miteinander verbunden. Beispielsweise erfordert Pytorch1.9.0 CUDA11.1, während Pytorch2.0.1 CUDA11.3 erfordert. Die Cudnn -Version muss auch mit der CUDA -Version übereinstimmen. Bestimmen Sie vor der Auswahl der Pytorch -Version unbedingt, dass kompatible CUDA- und CUDNN -Versionen installiert wurden. Python -Version: Pytorch Official Branch
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
