

Praxis für Sprachtechnologie in Zuoyebang

Gast | Wang Qiangqiang Zusammenstellung | In der Grundsatzrede wurde Zuoyebangs Sprachtechnologiepraxis unter drei Gesichtspunkten erläutert: Sprachsynthese, Sprachbewertung und Spracherkennung. Der Inhalt umfasste die End-to-End-Implementierung und effiziente Datennutzung bei der Spracherkennung sowie die Korrektur von Sprachaussprachefehlern in Szenarien mit hoher Parallelität , und Die Faktordifferenzierung und die Anti-Interferenz-Fähigkeit des Modells werden verbessert.
Damit mehr Schüler, die sich für Sprachtechnologie interessieren, den aktuellen Entwicklungstrend und die neuesten Technologiepraktiken der Sprachtechnologie verstehen, wird der Inhalt der Rede von Lehrer Wang Qiangqiang nun wie folgt zusammengestellt, in der Hoffnung, Ihnen etwas Inspiration zu bringen.
1. Sprachsynthese
Sprachsynthese mit geringem Datenvolumen
Wenn Sie bei der herkömmlichen Sprachsynthesetechnologie die Stimme einer Person vollständig synthetisieren möchten, dauert die Aufnahme mindestens zehn Stunden. Für Blockflöten stellt dies eine große Herausforderung dar, und nur wenige Menschen schaffen es, über einen so langen Zeitraum eine gute Aussprache beizubehalten. Durch die Sprachsynthesetechnologie mit geringem Datenvolumen müssen wir nur Dutzende Sätze und ein paar Minuten der vom Rekorder gesprochenen Sprache verwenden, um einen vollständigen Sprachsyntheseeffekt zu erzielen.
Die Sprachsynthesetechnologie mit kleinem Datenvolumen wird grob in zwei Kategorien unterteilt. Eine davon ist für Situationen gedacht, in denen Annotation und Sprache nicht übereinstimmen. Es gibt zwei Hauptverarbeitungsmethoden: Die eine ist selbstüberwachtes Lernen, bei dem selbstüberwachtes Algorithmuslernen verwendet wird, um die Entsprechung zwischen der Modellierungseinheit und dem Audio zu ermitteln, und dann die Annotation verwendet wird Die zweite Möglichkeit besteht darin, unbeschriftete Korpusse mithilfe von ASR zu identifizieren und TTS zur Synthese von Doppelfunktionen und dualen Lernmethoden zu verwenden, um den Syntheseeffekt von TTS schrittweise zu verbessern.
Für den Text- und Audioabgleich werden die Hauptverarbeitungsmethoden ebenfalls in zwei Typen unterteilt: Die eine besteht darin, ein mehrsprachiges Vortrainingsmodell mit annotiertem Korpus zu erstellen. Die andere basiert auf dieser Lösung. Mehrere Sprecher derselben Sprache werden mit annotierten Daten vorab trainiert, und die Feinabstimmung wird anhand der Daten des Zielsprechers durchgeführt, um den gewünschten Effekt zu erzielen.
Sprachsynthese-Technologie-Framework
Das Sprachsynthese-Technologie-Framework von Zuoyebang verwendet FastSpeech2 im Phonemteil. FastSpeech2 hat den Hauptvorteil einer schnellen Synthesegeschwindigkeit. Gleichzeitig integriert FastSpeech2 auch Duration, Pitch und Energy Predictor, was uns bei der Wahl des Vocoders mehr Spielraum bieten kann, was dem Sprachteam bei der Wahl von Multi hilft -Band MelGAN wird verwendet, weil Multi-Band MelGAN gute Syntheseeffekte hat und sehr schnell ist.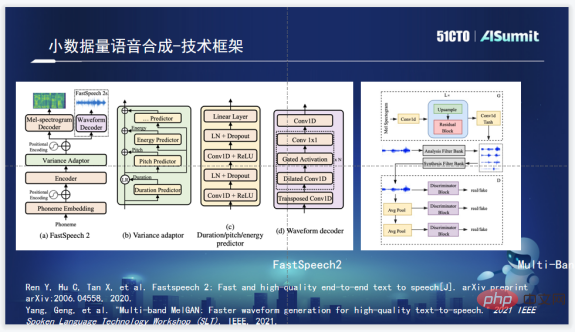 Sprachsynthese für mehrere Sprecher
Sprachsynthese für mehrere Sprecher
Nachdem das Grundgerüst festgelegt wurde, ist als nächstes die Sprachsynthese für mehrere Sprecher zu erledigen. Eine gängige Idee für die Sprachsynthese mit mehreren Sprechern besteht darin, dem Encoder Informationen zur Sprechereinbettung hinzuzufügen, die Informationen eines bestimmten Sprechers zu lernen und dann das Modell zum Trainieren eines Sprachsynthesemodells mit mehreren Sprechern zu verwenden. Verwenden Sie abschließend bestimmte Lautsprecher, um eine einfache Feinabstimmung durchzuführen. Diese Lösung kann den Aufzeichnungsbedarf von zehn Stunden auf etwa eine Stunde komprimieren. In der Praxis ist es jedoch immer noch schwierig, einstündige Aufzeichnungen zu sammeln, die den Modelltrainingsstandards entsprechen. Das Ziel der Sprachsynthese mit kleinen Datenmengen besteht im Wesentlichen darin, weniger Töne zu verwenden, um einen relativ guten Klang zu synthetisieren.
Daher hat das Sprachteam von Zuoyebang aus der Siegerlösung des M2VOC-Wettbewerbs gelernt und sich schließlich für die Kombination aus D-Vector und ECAPA-basiertem Speaker Embedding entschieden und drei Upgrades durchgeführt, darunter das Upgrade des Speaker Embedding; Wird von FastSpeech2 zu Conformer verwendet und fügt Sprecherinformationen zu LayerNorm hinzu.
2. Sprachbewertung
Sprachbewertungstechnologie-Framework
Das grundlegende technische Rahmenwerk der Sprachbewertung von Zuoyebang verwendet im Wesentlichen die GOP-Bewertung, um die Aussprache von Wörtern oder Sätzen durch den Benutzer zu beurteilen. In Bezug auf die Modelle wurde es jedoch auf Conformer und CGC+ aufmerksamkeitsbasiert aktualisiert, ein vollständiger End-to-End-Modelltrainingsprozess. GOP hängt stark von Lauten und Phonemen ab, also vom Ausrichtungsgrad der Modellierungseinheiten. Daher haben wir beim Training des Modells die durch das GMM-Modell erhaltenen Ausrichtungsinformationen des Korpus hinzugefügt. Durch ein vollständig zertifiziertes Modell und abgestimmte entsprechende Informationen kann ein sehr effektives Modell trainiert werden. Durch die Kombination der Stärken beider wird sichergestellt, dass der GOP-Score relativ genau ist. Probleme und Schwachstellen des Bewertungssystems
Probleme und Schwachstellen des Bewertungssystems
Bewertungsszenarien reagieren von Natur aus empfindlich auf Latenz, daher sind Latenz und Netzwerk die beiden Hauptprobleme bei der Implementierung des GOP-Bewertungssystems. Wenn die Latenz hoch und die Echtzeitleistung schlecht ist, wird das gesamte Benutzererlebnis stark beeinträchtigt. Wenn außerdem ein Problem mit dem Netzwerk vorliegt und die Netzwerkumgebung des Benutzers schwankt, kann es in Verbindung mit der Netzwerkverzögerung leicht dazu kommen, dass die vom Benutzer wahrgenommene Färbungszeit eine Sekunde überschreitet, was zu einem sehr offensichtlichen Gefühl der Stagnation führt und ernsthafte Auswirkungen hat der gesamte Kurseinfluss.
Lösungsrichtung – Algorithmus
Für die oben genannten Probleme kann das Problem der Verzögerung und des übermäßigen Speichers algorithmisch durch Chunk Mask gelöst werden. Chunk schaut bis zu zwei Frames vorwärts und bis zu fünf Frames rückwärts, und das Verzögerungsproblem ist gelöst.
Als der echte Algorithmus in der Praxis getestet wurde, betrug seine harte Verzögerung nur etwa 50 Millisekunden, was bedeutet, dass das Wort im Grunde in 50 Millisekunden aktiviert wird. 50 Millisekunden sind in der menschlichen Wahrnehmung sehr schnell. Zumindest auf Algorithmusebene ist das Problem der harten Verzögerung also gelöst. Dies ist die erste Ebene unserer Arbeit.
Lösungsrichtung – Integrierte Terminal- und Cloud-Plattform
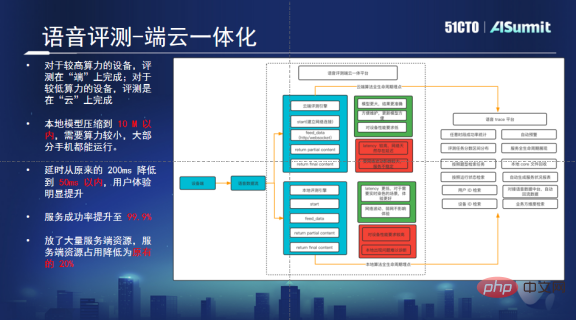
Eine integrierte Terminal- und Cloud-Plattform kann Probleme lösen, die durch hohe Parallelität und Netzwerkübertragung verursacht werden. Diese Plattform kann automatisch feststellen, ob das Mobiltelefon des Nutzers über ausreichend Rechenleistung verfügt. Bei ausreichender Anzahl werden lokale Bewertungen priorisiert. Reicht die Rechenleistung nicht aus, wird die Anfrage an die Cloud gesendet und die Cloud führt die Auswertung durch. Wenn vor Ort ein Problem auftritt, wird auch dessen Lebenszyklus kontrolliert.
Durch diese Lösung haben wir die durch die sofortige hohe Parallelität verursachten Probleme gelöst. Da ein Teil der Rechenleistung an das Ende übertragen wird, muss die Cloud nur 20 % der ursprünglichen Maschinen beibehalten, um einen normalen Betrieb zu erreichen, was viel spart von Geld. Darüber hinaus wurde nach der Lokalisierung des Algorithmus auch das Problem der Verzögerung gelöst, was umfangreiche Bewertungsaufgaben gut unterstützen und Benutzern ein besseres audiovisuelles Erlebnis bieten kann.
Korrektur von Aussprachefehlern
Der Hintergrund der Nachfrage nach Korrektur von Aussprachefehlern sind kontextbezogene Probleme und der Mangel an Bildungsressourcen. Auch dieser Problempunkt kann mithilfe von Bewertungstechnologie gelöst werden. Durch die Optimierung der Bewertungstechnologie können wir feststellen, ob die Aussprache korrekt ist und wo es Probleme mit der Aussprache gibt.
In Bezug auf die Technologieauswahl ist das Bewertungssystem zwar ein stabiles Bewertungsschema, das auf der GOP basiert, das GOP-Schema hängt jedoch stark von der Ausrichtung der Audio- und Modellierungseinheiten ab. Wenn die Startzeit ungenau ist, ist die Abweichung größer die Differenzierung wird sich verschlechtern. Daher ist der ursprüngliche Plan für diese Art von Schallkorrekturszenario nicht geeignet. Darüber hinaus besteht die Idee von GOP darin, Expertenwissen zur Korrektur und Anleitung der Aussprache zu nutzen. Das Fehlen und Hinzufügen der Aussprache bei der Korrektur der Aussprache ist für GOP sehr schmerzhaft und erfordert zu viel manuelle Unterstützung. Dies erfordert eine flexiblere Lösung, daher haben wir uns schließlich für die ASR-Lösung zur Korrektur von Aussprachefehlern entschieden.
Der große Vorteil der ASR-Lösung besteht darin, dass der Trainingsprozess einfach ist und nicht zu viele Ausrichtungsinformationen erfordert. Selbst wenn die Aussprache falsch ist, hat dies keinen großen Einfluss auf die Unterscheidung kontextueller Phoneme. ASR behandelt zusätzliche Lektüre und versäumte Lektüre und bietet natürliche theoretische und technische Vorteile. Daher haben wir uns schließlich für ein reines End-to-End-ASR-Modell als technische Basis für unsere Korrektur von Aussprachefehlern entschieden.
Gleichzeitig hat Zuoyebang auf dieser Basis auch einige Optimierungs- und Innovationsarbeiten durchgeführt. Erstens werden durch das Attention-Modul a priori Textinformationen zum Modelltraining hinzugefügt. Zweitens werden Fehler durch zufälliges Ersetzen simuliert, um das Modell so zu trainieren, dass es über Fehlerkorrekturfunktionen verfügt. Drittens werden Fehler geschichtet, da das Modell nicht differenziert genug ist , und einige kleinere Fehler werden nicht als falsch beurteilt. Durch die obige Lösung konnte die Fehlalarmrate schließlich deutlich reduziert werden, gleichzeitig wurde sichergestellt, dass der Verlust der Erinnerungsrate nicht besonders groß war, und auch die Diagnosegenauigkeitsrate wurde verbessert.
3. Spracherkennungs-Framework
Zuoyebangs Spracherkennungs-Framework ist ein End-to-End-Spracherkennungs-Framework und bietet ganz offensichtliche Vorteile: Erstens vermeidet viele komplexe Clustering- und Ausrichtungsoperationen; zweitens ist der Trainingsprozess etwas einfacher; drittens erfordert das End-to-End-Framework keine manuelle Generierung von Aussprachewörterbüchern; viertens können Phoneminformationen und Sequenzinformationen erlernt werden Gleichzeitig entspricht dies dem gemeinsamen Erlernen der Akustik. Modell, Sprachmodell.
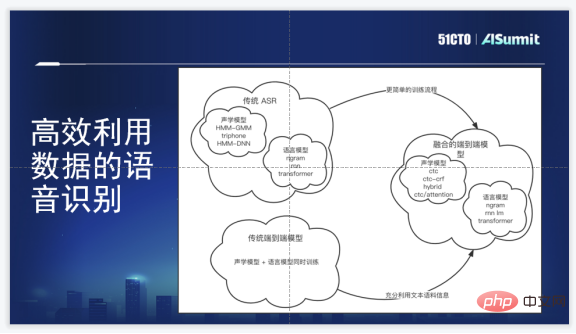 Natürlich liegen auch die Nachteile auf der Hand. Für das End-to-End-Modell ist es zu Beginn schwierig, mehr Sprach- oder Textdaten zu nutzen, und die Kosten für die Kennzeichnung des Korpus sind sehr hoch. Unsere Anforderung ist, dass die interne Auswahl das Ziel erreichen muss, ein End-to-End-Generierungsmodell zu haben, mit den neuesten Algorithmen Schritt zu halten und Korpusmodellinformationen zusammenführen zu können.
Natürlich liegen auch die Nachteile auf der Hand. Für das End-to-End-Modell ist es zu Beginn schwierig, mehr Sprach- oder Textdaten zu nutzen, und die Kosten für die Kennzeichnung des Korpus sind sehr hoch. Unsere Anforderung ist, dass die interne Auswahl das Ziel erreichen muss, ein End-to-End-Generierungsmodell zu haben, mit den neuesten Algorithmen Schritt zu halten und Korpusmodellinformationen zusammenführen zu können.
Algorithmus des Spracherkennungssystems
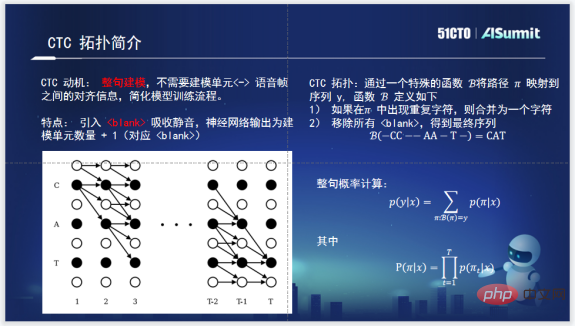 Wenn es um CTC-CRF geht, müssen Sie zuerst CTC kennen. CTC wurde für die Modellierung des gesamten Satzes entwickelt. Nach dem Aufkommen von CTC ist für das Training des akustischen Modells des gesamten Satzes keine Ausrichtung zwischen Phonemen und Audio mehr erforderlich. Die CTC-Topologie führt einerseits einen Leerraum zum Absorbieren von Stille ein, der die Stille außerhalb der wirklich effektiven Modellierungseinheit absorbieren kann. Wenn andererseits die Wahrscheinlichkeit des gesamten Satzes berechnet wird, wird ein dynamischer Programmieralgorithmus basierend auf π verwendet, um den Pfad des gesamten Satzes in einem relativ vernünftigen Maßstab zu halten, was den Berechnungsaufwand erheblich reduzieren kann. Das ist eine sehr bahnbrechende Arbeit von CTC.
Wenn es um CTC-CRF geht, müssen Sie zuerst CTC kennen. CTC wurde für die Modellierung des gesamten Satzes entwickelt. Nach dem Aufkommen von CTC ist für das Training des akustischen Modells des gesamten Satzes keine Ausrichtung zwischen Phonemen und Audio mehr erforderlich. Die CTC-Topologie führt einerseits einen Leerraum zum Absorbieren von Stille ein, der die Stille außerhalb der wirklich effektiven Modellierungseinheit absorbieren kann. Wenn andererseits die Wahrscheinlichkeit des gesamten Satzes berechnet wird, wird ein dynamischer Programmieralgorithmus basierend auf π verwendet, um den Pfad des gesamten Satzes in einem relativ vernünftigen Maßstab zu halten, was den Berechnungsaufwand erheblich reduzieren kann. Das ist eine sehr bahnbrechende Arbeit von CTC.

Das von Zuoyebang intern verwendete Spracherkennungssystem CTC-CRF. Verstehen Sie die Formel und passen Sie die Wahrscheinlichkeit des gesamten Satzes durch CRF an. Die Wahrscheinlichkeit des gesamten Satzes ist eine Sequenz, deren Eingabe X und deren Ausgabe π ist (π wird durch die Topologie von CTC oben dargestellt), daher wird sie als CTC-CRF bezeichnet.
Das Wichtigste an CRF ist die potenzielle Funktion und die gesamte Planung der potenziellen Funktion. Die potentielle Funktion ist die bedingte Wahrscheinlichkeit, dass die Eingabe X und die Ausgabe πt ist, plus der Wahrscheinlichkeit eines ganzen Satzes. Sie entsprechen tatsächlich den Knoten und Kanten in CRF.
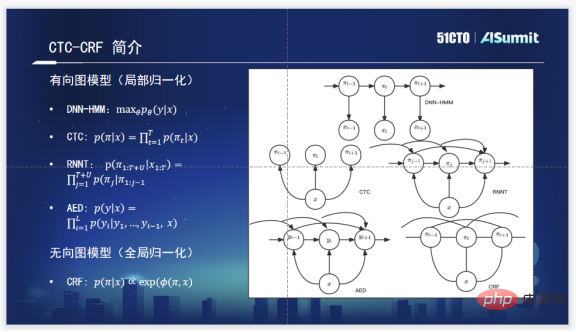
CTC-CRF unterscheidet sich etwas von den häufig verwendeten akustischen Modellideen. Zu den häufig verwendeten Akustikmodellen gehören die folgenden vier DNN-HMM, CTC, RNNT und AED.
Das grundlegende bedingte Wahrscheinlichkeitsmodell von RNNT ist die Wahrscheinlichkeit der Eingabe X und der Ausgabe Y. Das Anpassungsziel ist maxθ und seine Parameter, um diese Wahrscheinlichkeit zu maximieren.
CTC ist in der Abbildung dargestellt, nämlich die Annahme der bedingten Unabhängigkeit. Es besteht kein Zusammenhang zwischen seinen Zuständen und die bedingte Wahrscheinlichkeitsbeziehung zwischen ihnen wird nicht berücksichtigt.
RNNT berücksichtigt die bedingten Wahrscheinlichkeiten des aktuellen Zustands und aller historischen Zustände, wie in der Abbildung deutlich zu sehen ist. Das Gleiche gilt für den AED, der die bedingte Wahrscheinlichkeit des aktuellen Zustands und des historischen Zustands berücksichtigt.
Aber CTC-CRF ist eigentlich kein lokales Normalisierungsmodell, das auf bedingter Wahrscheinlichkeit basiert, sondern ein Modell der Normalisierung ganzer Sätze und ein globales Normalisierungsmodell. Wir sehen also, dass es nicht nur von der Geschichte, sondern auch von der Zukunft abhängt. Es kann tatsächlich die Wahrscheinlichkeitsinformationen des gesamten Satzes berücksichtigen. Dies ist ihr größter theoretischer Unterschied.
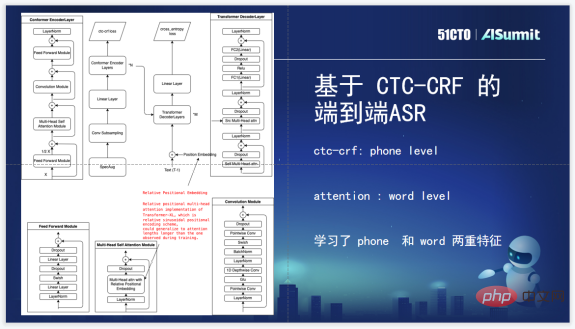
Wir verwenden CTC-CRF zuerst in der Verlustschicht, einem derzeit verwendeten Standard-Encoder und -Decoder, und fügen dann CTC-CRF und Verlust hinzu, um das akustische Modell zu trainieren, einen End-to-End-Akustikmodellprozess. Die Verlustschicht verwendet CTC-CRF-Verlust anstelle des ursprünglichen CTC-Verlusts. CTC-CRF wird auf Telefonebene modelliert, aber hier bei Attention wird unsere Aufmerksamkeit auf die Modellierung auf Wortebene ausgerichtet. Zum Trainieren des Modells werden sowohl Funktionen auf Telefon- als auch auf Word-Ebene verwendet.
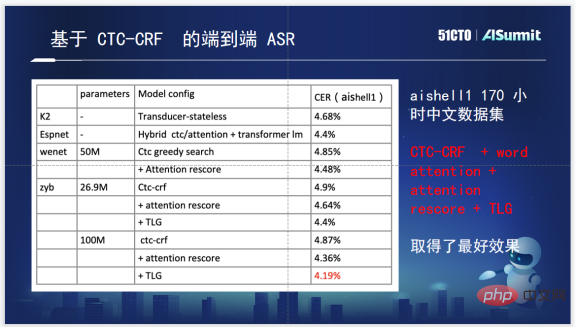
Was schließlich die spezifischen Auswirkungen betrifft, handelt es sich hierbei um die Auswirkungen mehrerer Open-Source-Tools auf den Aishell1-Testsatz, und auch die Anzahl der Parameter ist markiert. Es ist ersichtlich, dass die auf CTC-CRF basierende Methode relativ Vorteile hat.
Mit dem Algorithmus ist der theoretische Effekt auch sehr gut. In Kombination mit der Geschäftsseite ist die Geschäftsseite immer noch unterschiedlich, aber alle Geschäftsseiten haben einen gemeinsamen Wunsch, nämlich eine optimale Effizienz zu erreichen. Um dieses Problem zu lösen, gibt es eine Hot-Word-Lösung. Die Hot-Word-Lösung kann dieses Problem perfekt lösen und schnell die Wörter identifizieren, die die Geschäftsseite identifizieren möchte.
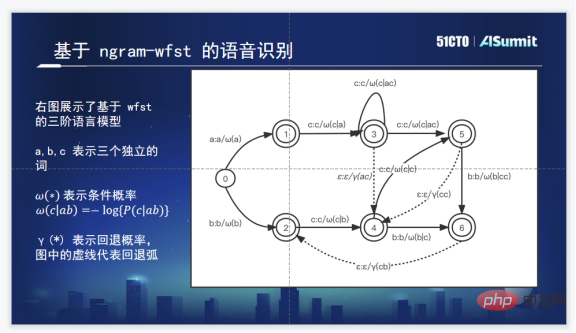
Eine gängige Hot-Word-Lösung besteht darin, den erweiterten gerichteten Graphen von Hot-Words zu TLG hinzuzufügen. Das obige Bild ist das WFST-Dekodierungsdiagramm eines üblichen dreistufigen Ngrams. Die durchgezogene Linie stellt die bedingte Wahrscheinlichkeit dar und die gepunktete Linie ist die Backoff-Wahrscheinlichkeit.
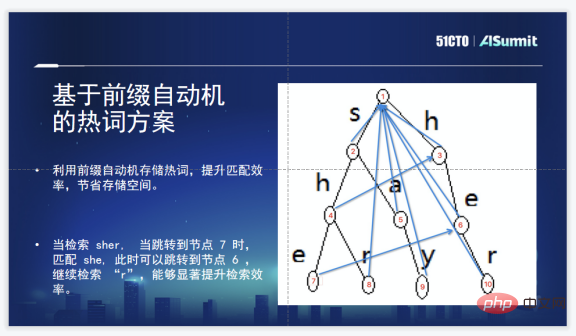
Zhuoyebangs Lösung ist eine Hot-Word-Lösung, die auf Präfixautomaten basiert. Dies liegt daran, dass der Umfang der Hot-Words so groß ist, dass es zu einem Effizienzengpass kommt. Es ist sehr gut geeignet, Präfixautomaten zu verwenden, um das Problem der Übereinstimmung von Zeichenfolgen mit mehreren Mustern zu lösen, insbesondere für Zeichenfolgen, die ein heißes Wort in der Liste heißer Wörter treffen, abdecken oder abdecken. Eine Sequenz wie „sher“ deckt zwei heiße Wörter ab, nämlich „she“ und „her“. Nach dem Abrufen von „she“ können Sie schnell zu „her“ springen und mehrere in der Zeichenfolge enthaltene „heiße“ Wörter finden. Das Fazit ist, dass diese Lösung schnell genug ist und etwas Speicherplatz sparen kann.

Es gibt auch einige Probleme, wenn diese Lösung tatsächlich verwendet wird. Der Aufbau eines Präfixbaums erfordert immer noch das Durchlaufen des gesamten Präfixbaums, was relativ teuer ist. Da Hotwords in Echtzeit hinzugefügt werden müssen, können sie jederzeit hinzugefügt werden und werden jederzeit wirksam. Um dieses Problem zu lösen, haben wir schließlich einen oder zwei Bäume erstellt, einen ist ein gewöhnlicher Präfixbaum und der andere ist ein Präfixautomat. Das heißt, dem gewöhnlichen Präfixbaum werden Benutzer-Hotwords hinzugefügt Sofortige Wirkung, also jederzeit online, Hotwords können aktiviert werden. Nach Überschreiten eines Schwellenwerts wird der Präfixautomat automatisch aufgebaut und entspricht damit im Wesentlichen den Anforderungen einer Benutzergruppe.
4. Zusammenfassung
Das Obige erfolgt hauptsächlich über drei Richtungen, ein bis zwei Punkte in jede Richtung. Diese technische Entschlüsselungsmethode hat die Implementierung der Zuoyebang-Sprachtechnologie und die bei der Implementierung aufgetretenen Probleme geklärt und schließlich einen Satz ausgegeben von Lösungen, die den Anforderungen der Geschäftsseite relativ gerecht werden können.
Aber zusätzlich zu diesen drei Punkten hat die Stimmgruppe auch viele atomare Stimmfähigkeiten angesammelt. Die Bewertungsebene ist sehr detailliert und es werden sogar erhöhtes Lesen, fehlendes Lesen, kontinuierliches Lesen, Stimmhaftigkeit, Akzent, steigende und fallende Intonation durchgeführt. Die Erkennung fügt auch gemischte Erkennung von Chinesisch und Englisch, Stimmabdruck, Geräuschreduzierung und Altersunterscheidung hinzu.
Mit diesen atomaren Fähigkeiten wird es einfacher sein, die Geschäftsseite auf der Algorithmusebene zu unterstützen und zu bedienen.
Gastvorstellung:
Wang Qiangqiang, Leiter des Sprachtechnologieteams von Zuoyebang. Bevor er zu Zuoyebang kam, arbeitete er im Labor für Sprachverarbeitung und maschinelle Intelligenz der Fakultät für Elektrotechnik der Tsinghua-Universität, wo er für die Implementierung von Spracherkennungsalgorithmen und die Entwicklung industrietauglicher Lösungen verantwortlich war. Kam 2018 zu Zuoyebang und ist für die Forschung und Implementierung sprachbezogener Algorithmen verantwortlich. Er leitete die Implementierung von Spracherkennung, -bewertung, -synthese und anderen Algorithmen in Zuoyebang und versorgte das Unternehmen mit einem kompletten Satz an Sprachtechnologielösungen.
Das obige ist der detaillierte Inhalt vonPraxis für Sprachtechnologie in Zuoyebang. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
