
 Technologie-Peripheriegeräte
KI
Deep-Ensemble-Learning-Algorithmus zur Klassifizierung von Netzhautbildern
Technologie-Peripheriegeräte
KI
Deep-Ensemble-Learning-Algorithmus zur Klassifizierung von Netzhautbildern
Deep-Ensemble-Learning-Algorithmus zur Klassifizierung von Netzhautbildern

Übersetzer | Zhu Xianzhong
Rezensent | Weltweit gab es etwa 2,2 Milliarden Menschen mit Sehbehinderungen, von denen mindestens eine Milliarde hätte verhindert werden können oder noch behandelt werden. Wenn es um die Augenpflege geht, steht die Welt vor vielen Herausforderungen, darunter Ungleichheiten in der Abdeckung und Qualität präventiver, therapeutischer und rehabilitativer Dienste. Es mangelt an geschultem Augenpflegepersonal und die Augenpflegedienste sind nur unzureichend in das Hauptgesundheitssystem integriert. Mein Ziel ist es, zum Handeln anzuregen, um diese Herausforderungen gemeinsam anzugehen. Das in diesem Artikel vorgestellte Projekt ist Teil von Iluminado, einem datenwissenschaftlichen Abschlussprojekt, an dem ich derzeit arbeite.
Designziele des Capstone-Projekts
Der Zweck der Erstellung dieses Artikelprojekts besteht darin, ein Deep-Learning-Ensemble-Modell zu trainieren, das letztendlich für Familien mit niedrigem Einkommen sehr zugänglich ist und eine erste Krankheitsrisikodiagnose zu geringen Kosten durchführen kann. Mithilfe meines Modellverfahrens können Augenärzte anhand der Netzhautfundusfotografie feststellen, ob ein sofortiger Eingriff erforderlich ist.
Quelle des ProjektdatensatzesOphthAI stellt einen öffentlich verfügbaren Bilddatensatz namens Retinal Fundus Multi-Disease Image Dataset („RFMiD“) bereit, der 3200 Bilder enthält. Fundusbilder, die von drei verschiedenen Funduskameras aufgenommen wurden, wurden mit Anmerkungen versehen von zwei hochrangigen Netzhautexperten basierend auf einem gerichtlichen Konsens.
Diese Bilder wurden aus Tausenden von Inspektionen extrahiert, die im Zeitraum 2009–2010 durchgeführt wurden. Dabei wurden sowohl einige qualitativ hochwertige Bilder als auch einige Bilder geringer Qualität ausgewählt, was den Datensatz anspruchsvoller macht.
Der Datensatz ist in drei Teile unterteilt: Trainingssatz (60 % oder 1920 Bilder), Bewertungssatz (20 % oder 640 Bilder) und Testsatz (20 % und 640 Bilder). Im Durchschnitt betrug der Anteil der Menschen mit Erkrankungen im Trainingssatz, Bewertungssatz und Testsatz 60 ± 7 %, 20 ± 7 % bzw. 20 ± 5 %. Der Hauptzweck dieses Datensatzes besteht darin, verschiedene Augenkrankheiten zu behandeln, die in der täglichen klinischen Praxis auftreten, wobei insgesamt 45 Kategorien von Krankheiten/Pathologien identifiziert werden. Diese Labels sind in drei CSV-Dateien zu finden, nämlich RFMiD_Training_Labels.CSV, RFMiD_Validation_Labels.SSV und RFMiD_Testing_Labels.CSV.
Bildquelle
Das Bild unten wurde mit einem Werkzeug namens Funduskamera aufgenommen. Eine Funduskamera ist ein spezielles Mikroskop mit geringer Leistung, das an eine Blitzkamera angeschlossen ist und zum Fotografieren des Fundus, der Netzhautschicht im hinteren Teil des Auges, verwendet wird.
Heutzutage sind die meisten Funduskameras Handkameras, sodass der Patient nur direkt in die Linse schauen muss. Darunter zeigt der hell blinkende Teil an, dass das Fundusbild aufgenommen wurde.
Handkameras haben ihre Vorteile, da sie an verschiedene Orte getragen werden können und Patienten mit besonderen Bedürfnissen, wie beispielsweise Rollstuhlfahrern, gerecht werden können. Darüber hinaus kann jeder Mitarbeiter mit der erforderlichen Schulung die Kameras bedienen, sodass unterversorgte Diabetiker ihre jährlichen Kontrolluntersuchungen schnell, sicher und effizient durchführen können.
Fundus-Retina-Bildgebungssystem-Aufnahmesituation:
Abbildung 2: Bilder, die basierend auf ihren jeweiligen visuellen Merkmalen aufgenommen wurden: (a) diabetische Retinopathie (DR), (b) altersbedingte Makuladegeneration (ARMD) und (c) Mäßige Trübung (MH).
Wo wird die endgültige Diagnose gestellt?
Der anfängliche Screening-Prozess kann durch Deep Learning unterstützt werden, die endgültige Diagnose wird jedoch von einem Augenarzt mithilfe einer Spaltlampenuntersuchung gestellt.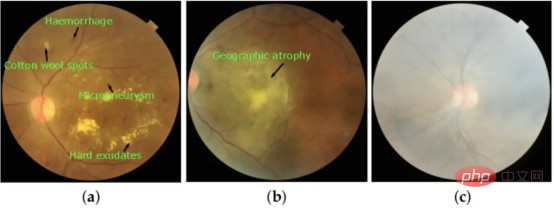
Dieser Vorgang wird auch biomikroskopische Diagnostik genannt und beinhaltet die Untersuchung lebender Zellen. Der Arzt kann eine mikroskopische Untersuchung durchführen, um festzustellen, ob Anomalien in den Augen des Patienten vorliegen.
Abbildung 3: Abbildung einer Spaltlampenuntersuchung
Anwendung von Deep Learning bei der Klassifizierung von Netzhautbildern
Im Gegensatz zu herkömmlichen Algorithmen für maschinelles Lernen können Deep Convolutional Neural Networks (CNN) mehrschichtige Modelle verwenden, um automatisch zu extrahieren und zu klassifizieren Merkmale aus Rohdaten.
Kürzlich hat die akademische Gemeinschaft eine große Anzahl von Artikeln über den Einsatz von Convolutional Neural Networks (CNN) zur Identifizierung verschiedener Augenkrankheiten wie diabetischer Retinopathie und Glaukom mit abnormalen Ergebnissen (AUROC>0,9) veröffentlicht.
Datenmetriken
Der AUROC-Score fasst die ROC-Kurve in einer Zahl zusammen, die die Leistung des Modells bei der gleichzeitigen Verarbeitung mehrerer Schwellenwerte beschreibt. Es ist erwähnenswert, dass ein AUROC-Score von 1 einen perfekten Score darstellt, während ein AUROC-Score von 0,5 einer zufälligen Schätzung entspricht.
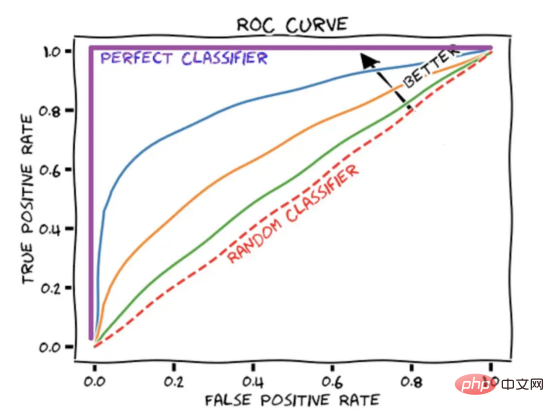
Abbildung 4: Schematische Darstellung der ROC-Kurve mit Darstellung
Verwendete Methode – Kreuzentropie-Verlustfunktion
Kreuzentropie wird normalerweise als Verlustfunktion beim maschinellen Lernen verwendet. Kreuzentropie ist eine Metrik im Bereich der Informationstheorie, die auf der Definition von Entropie aufbaut und typischerweise zur Berechnung der Differenz zwischen zwei Wahrscheinlichkeitsverteilungen verwendet wird, während man sich Kreuzentropie als Berechnung der Gesamtentropie zwischen zwei Verteilungen vorstellen kann.
Kreuzentropie hängt auch mit logistischen Verlusten zusammen, die als logarithmischer Verlust bezeichnet werden. Obwohl diese beiden Maße aus unterschiedlichen Quellen stammen, berechnen beide Methoden bei Verwendung als Verlustfunktion für ein Klassifizierungsmodell dieselbe Menge und können austauschbar verwendet werden.
(Weitere Einzelheiten finden Sie unter: https://machinelearningmastery.com/logistic-regression-with-maximum-likelihood-estimation/)
Was ist Kreuzentropie?
Kreuzentropie ist ein Maß für die Differenz zwischen zwei Wahrscheinlichkeitsverteilungen für eine gegebene Zufallsvariable oder eine Reihe von Ereignissen. Sie erinnern sich vielleicht, dass Informationen die Anzahl der Bits quantifizieren, die zum Kodieren und Übertragen eines Ereignisses erforderlich sind. Ereignisse mit geringer Wahrscheinlichkeit enthalten tendenziell mehr Informationen, während Ereignisse mit hoher Wahrscheinlichkeit weniger Informationen enthalten.
In der Informationstheorie beschreiben wir gerne die „Überraschung“ von Ereignissen. Je unwahrscheinlicher das Eintreten eines Ereignisses ist, desto überraschender ist es und desto mehr Informationen enthält es.
- Ereignis mit geringer Wahrscheinlichkeit (überraschend): Weitere Informationen.
- Ereignis mit hoher Wahrscheinlichkeit (keine Überraschung): weniger Informationen.
Angesichts der Wahrscheinlichkeit des Ereignisses P(x) kann die Information h(x) für Ereignis x wie folgt berechnet werden:
h(x) = -log(P(x))
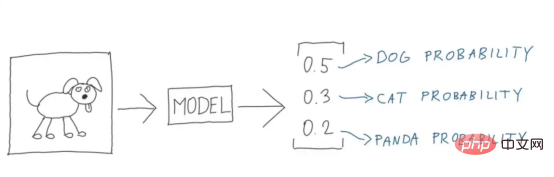
Abbildung 4: Perfekte Illustration ( Bildnachweis: Vlastimil Martinek)
Entropie ist die Anzahl der Bits, die erforderlich sind, um ein zufällig ausgewähltes Ereignis aus einer Wahrscheinlichkeitsverteilung zu übertragen. Schiefe Verteilungen haben eine geringere Entropie, während Verteilungen mit gleichen Ereigniswahrscheinlichkeiten im Allgemeinen eine höhere Entropie aufweisen.
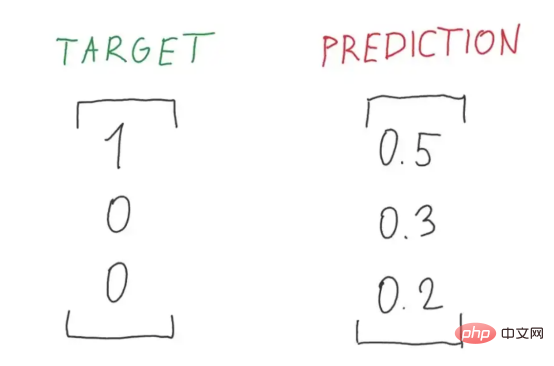
Abbildung 5: Eine perfekte Darstellung des Verhältnisses von Ziel- zu vorhergesagten Wahrscheinlichkeiten (Bildquelle: Vlastimil Martinek)
Eine schiefe Wahrscheinlichkeitsverteilung hat weniger „Überraschungen“ und hat im Gegenzug möglichst eine geringere Entropie Ereignisse dominieren. Relativ gesehen ist die Gleichgewichtsverteilung überraschender und weist eine höhere Entropie auf, da die Ereignisse mit gleicher Wahrscheinlichkeit eintreten.
- Schiefe Wahrscheinlichkeitsverteilung (keine Überraschung): niedrige Entropie.
- Ausgewogene Wahrscheinlichkeitsverteilung (überraschenderweise): hohe Entropie.
Die Entropie H(x) kann für eine Zufallsvariable mit einer Menge von x in x diskreten Zuständen und ihrer Wahrscheinlichkeit P(x) berechnet werden, wie in der folgenden Abbildung dargestellt:
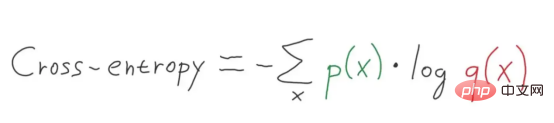
Abbildung 6: Mehrstufige Kreuzentropieformel (Bildquelle: Vlastimil Martinek)
Multi-Kategorie-Klassifizierung – wir verwenden Multi-Kategorie-Kreuzentropie – ein spezifischer Anwendungsfall der Kreuzentropie, bei dem das Ziel Es wird ein One-Hot-Codierungsvektorschema verwendet. (Interessierte Leser können den Artikel von Vlastimil Martinek lesen)

Abbildung 7: Perfektes Zerlegungsdiagramm der Panda- und Katzenverlustberechnung (Bildquelle: Vlastimil Martinek)
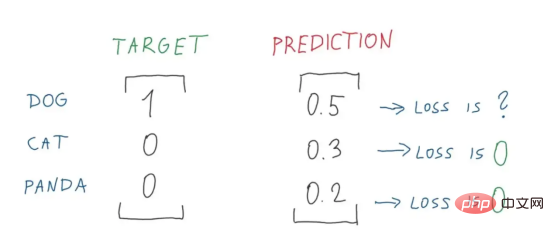
Abbildung 8: Verlustwert Abbildung 9 : Perfekte Zerlegung des Verlustwerts Abbildung 2 (Bildquelle: Vlastimil Martinek) Abbildung 9: Über Wahrscheinlichkeit und Verlust Visuelle Darstellung von (Bildnachweis: Vlastimil Martinek)
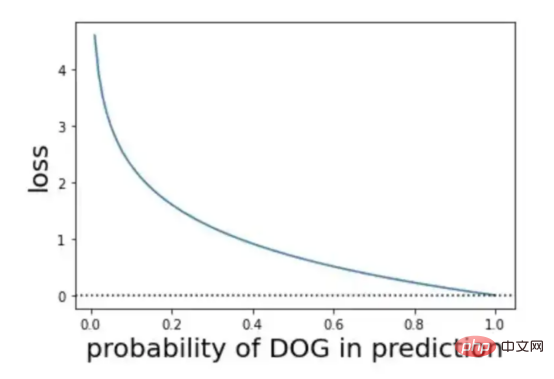
Wie wäre es mit binärer Kreuzentropie? 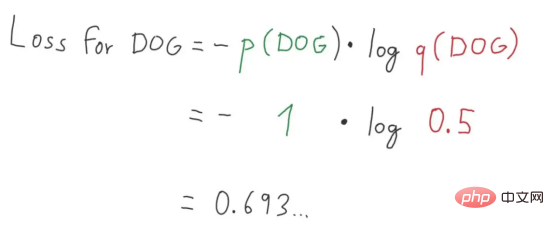
Abbildung 10: Darstellung der Klassifizierungs-Kreuzentropieformel (Bildquelle: Vlastimil Martinek)
In unserem Projekt haben wir uns für die binäre Klassifizierung entschieden – binäres Kreuzentropieschema, das heißt, das Ziel ist 0 oder 1 Kreuzentropieschema. Wenn wir die Ziele in Hot-Codierungsvektoren von [0,1] bzw. [1,0] umwandeln und vorhersagen, können wir zur Berechnung die Kreuzentropieformel verwenden.
 Abbildung 11: Darstellung der Formel zur Berechnung der binären Kreuzentropie (Bildquelle: Vlastimil Martinek)
Abbildung 11: Darstellung der Formel zur Berechnung der binären Kreuzentropie (Bildquelle: Vlastimil Martinek)
Verwendung eines asymmetrischen Verlustalgorithmus zur Verarbeitung unausgeglichener Daten
In einer typischen Multi-Label-Modellumgebung wird die Datenmerkmale einer Menge können eine unverhältnismäßige Anzahl positiver und negativer Bezeichnungen aufweisen. An diesem Punkt hat die Tendenz des Datensatzes, negative Labels zu bevorzugen, einen dominanten Einfluss auf den Optimierungsprozess und führt letztendlich zu einer Unterbetonung des Gradienten positiver Labels, wodurch die Genauigkeit der Vorhersageergebnisse verringert wird.
Das ist genau die Situation, in der sich der Datensatz befindet, den ich derzeit auswähle. 
Der von BenBaruch et al. entwickelte asymmetrische Verlustalgorithmus (siehe Abbildung 12) wird in diesem Projekt verwendet. Dies ist eine Methode zur Lösung der Klassifizierung mit mehreren Etiketten, aber die Kategorien weisen auch schwerwiegende unausgeglichene Verteilungssituationen auf.
Die Methode, die ich mir ausgedacht habe, besteht darin, das Gewicht des negativen Etikettenteils durch asymmetrische Änderung der positiven und negativen Komponenten der Kreuzentropie zu reduzieren und schließlich das Gewicht des positiven Etikettenteils hervorzuheben, das schwieriger zu verarbeiten ist .
Abbildung 12: Asymmetrischer Multi-Label-Klassifizierungsalgorithmus (2020, Autor: Ben-Baruch et al.)
Die zu testende Architektur
Zusammenfassend lässt sich sagen, dass dieses Projekt die im gezeigte verwendet Abbildung Architektur:
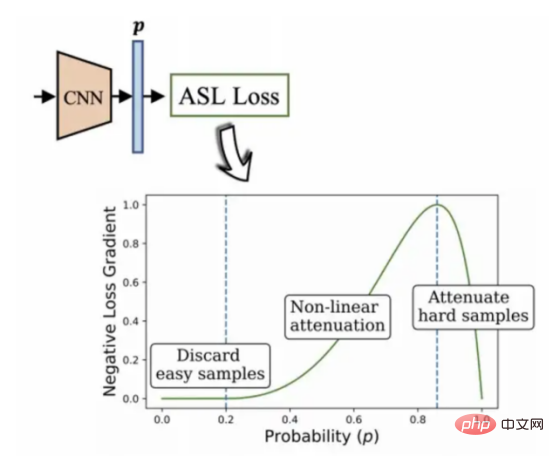
Abbildung 13 (Bildquelle: Sixu)
Die in der obigen Architektur verwendeten Schlüsselalgorithmen umfassen hauptsächlich:
- DenseNet-121 # 🎜🎜#
- InceptionV3
- # VGG16
- # 🎜🎜 # Darüber hinaus werden die oben genannten algorithmischen Inhalte auf jeden Fall aktualisiert, nachdem ich das Capstone-Projekt dieses Artikels abgeschlossen habe! Interessierte Leser bleiben bitte dran!
- Übersetzer-Einführung
Zhu Xianzhong, 51CTO-Community-Redakteur, 51CTO-Expertenblogger, Dozent, Computerlehrer an einer Universität in Weifang, Veteran in der Freiberufliche Programmierbranche Ein Stück.
Originaltitel:
Deep Ensemble Learning für Retinal Bildklassifizierung (CNN), Autor: Cathy Kam
Das obige ist der detaillierte Inhalt vonDeep-Ensemble-Learning-Algorithmus zur Klassifizierung von Netzhautbildern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
BERT ist ein vorab trainiertes Deep-Learning-Sprachmodell, das 2018 von Google vorgeschlagen wurde. Der vollständige Name lautet BidirektionalEncoderRepresentationsfromTransformers, der auf der Transformer-Architektur basiert und die Eigenschaften einer bidirektionalen Codierung aufweist. Im Vergleich zu herkömmlichen Einweg-Codierungsmodellen kann BERT bei der Textverarbeitung gleichzeitig Kontextinformationen berücksichtigen, sodass es bei Verarbeitungsaufgaben in natürlicher Sprache eine gute Leistung erbringt. Seine Bidirektionalität ermöglicht es BERT, die semantischen Beziehungen in Sätzen besser zu verstehen und dadurch die Ausdrucksfähigkeit des Modells zu verbessern. Durch Vorschulungs- und Feinabstimmungsmethoden kann BERT für verschiedene Aufgaben der Verarbeitung natürlicher Sprache verwendet werden, wie z. B. Stimmungsanalyse und Benennung
 Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Dec 28, 2023 pm 11:35 PM
Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Dec 28, 2023 pm 11:35 PM
Aktivierungsfunktionen spielen beim Deep Learning eine entscheidende Rolle. Sie können nichtlineare Eigenschaften in neuronale Netze einführen und es dem Netz ermöglichen, komplexe Eingabe-Ausgabe-Beziehungen besser zu lernen und zu simulieren. Die richtige Auswahl und Verwendung von Aktivierungsfunktionen hat einen wichtigen Einfluss auf die Leistung und Trainingsergebnisse neuronaler Netze. In diesem Artikel werden vier häufig verwendete Aktivierungsfunktionen vorgestellt: Sigmoid, Tanh, ReLU und Softmax. Beginnend mit der Einführung, den Verwendungsszenarien und den Vorteilen. Nachteile und Optimierungslösungen werden besprochen, um Ihnen ein umfassendes Verständnis der Aktivierungsfunktionen zu vermitteln. 1. Sigmoid-Funktion Einführung in die Sigmoid-Funktionsformel: Die Sigmoid-Funktion ist eine häufig verwendete nichtlineare Funktion, die jede reelle Zahl auf Werte zwischen 0 und 1 abbilden kann. Es wird normalerweise verwendet, um das zu vereinheitlichen
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latent Space Embedding (LatentSpaceEmbedding) ist der Prozess der Abbildung hochdimensionaler Daten auf niedrigdimensionalen Raum. Im Bereich des maschinellen Lernens und des tiefen Lernens handelt es sich bei der Einbettung latenter Räume normalerweise um ein neuronales Netzwerkmodell, das hochdimensionale Eingabedaten in einen Satz niedrigdimensionaler Vektordarstellungen abbildet. Dieser Satz von Vektoren wird oft als „latente Vektoren“ oder „latent“ bezeichnet Kodierungen". Der Zweck der Einbettung latenter Räume besteht darin, wichtige Merkmale in den Daten zu erfassen und sie in einer prägnanteren und verständlicheren Form darzustellen. Durch die Einbettung latenter Räume können wir Vorgänge wie das Visualisieren, Klassifizieren und Clustern von Daten im niedrigdimensionalen Raum durchführen, um die Daten besser zu verstehen und zu nutzen. Die Einbettung latenter Räume findet in vielen Bereichen breite Anwendung, z. B. bei der Bilderzeugung, der Merkmalsextraktion, der Dimensionsreduzierung usw. Die Einbettung des latenten Raums ist das Wichtigste
 Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
In der heutigen Welle rasanter technologischer Veränderungen sind künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL) wie helle Sterne und führen die neue Welle der Informationstechnologie an. Diese drei Wörter tauchen häufig in verschiedenen hochaktuellen Diskussionen und praktischen Anwendungen auf, aber für viele Entdecker, die neu auf diesem Gebiet sind, sind ihre spezifische Bedeutung und ihre internen Zusammenhänge möglicherweise noch immer rätselhaft. Schauen wir uns also zunächst dieses Bild an. Es ist ersichtlich, dass zwischen Deep Learning, maschinellem Lernen und künstlicher Intelligenz ein enger Zusammenhang und eine fortschreitende Beziehung besteht. Deep Learning ist ein spezifischer Bereich des maschinellen Lernens und des maschinellen Lernens
 Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Fast 20 Jahre sind vergangen, seit das Konzept des Deep Learning im Jahr 2006 vorgeschlagen wurde. Deep Learning hat als Revolution auf dem Gebiet der künstlichen Intelligenz viele einflussreiche Algorithmen hervorgebracht. Was sind Ihrer Meinung nach die zehn besten Algorithmen für Deep Learning? Im Folgenden sind meiner Meinung nach die besten Algorithmen für Deep Learning aufgeführt. Sie alle nehmen hinsichtlich Innovation, Anwendungswert und Einfluss eine wichtige Position ein. 1. Hintergrund des Deep Neural Network (DNN): Deep Neural Network (DNN), auch Multi-Layer-Perceptron genannt, ist der am weitesten verbreitete Deep-Learning-Algorithmus. Als er erstmals erfunden wurde, wurde er aufgrund des Engpasses bei der Rechenleistung in Frage gestellt Jahre, Rechenleistung, Der Durchbruch kam mit der Datenexplosion. DNN ist ein neuronales Netzwerkmodell, das mehrere verborgene Schichten enthält. In diesem Modell übergibt jede Schicht Eingaben an die nächste Schicht und
 Sehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an
Oct 23, 2023 pm 05:17 PM
Sehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an
Oct 23, 2023 pm 05:17 PM
1. Einleitung Die Vektorabfrage ist zu einem Kernbestandteil moderner Such- und Empfehlungssysteme geworden. Es ermöglicht einen effizienten Abfrageabgleich und Empfehlungen, indem es komplexe Objekte (wie Text, Bilder oder Töne) in numerische Vektoren umwandelt und Ähnlichkeitssuchen in mehrdimensionalen Räumen durchführt. Schauen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte von Elasticsearch Vector Retrieval_elasticsearch an. Als beliebte Open-Source-Suchmaschine hat die Entwicklung von Elasticsearch im Bereich Vektor Retrieval schon immer große Aufmerksamkeit erregt. In diesem Artikel wird die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs untersucht, wobei der Schwerpunkt auf den Merkmalen und dem Fortschritt jeder Phase liegt. Wenn Sie sich an der Geschichte orientieren, ist es für jeden praktisch, eine umfassende Palette zum Abrufen von Elasticsearch-Vektoren einzurichten.
 AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
Herausgeber | Rettichhaut Seit der Veröffentlichung des leistungsstarken AlphaFold2 im Jahr 2021 verwenden Wissenschaftler Modelle zur Proteinstrukturvorhersage, um verschiedene Proteinstrukturen innerhalb von Zellen zu kartieren, Medikamente zu entdecken und eine „kosmische Karte“ jeder bekannten Proteininteraktion zu zeichnen. Gerade hat Google DeepMind das AlphaFold3-Modell veröffentlicht, das gemeinsame Strukturvorhersagen für Komplexe wie Proteine, Nukleinsäuren, kleine Moleküle, Ionen und modifizierte Reste durchführen kann. Die Genauigkeit von AlphaFold3 wurde im Vergleich zu vielen dedizierten Tools in der Vergangenheit (Protein-Ligand-Interaktion, Protein-Nukleinsäure-Interaktion, Antikörper-Antigen-Vorhersage) deutlich verbessert. Dies zeigt, dass dies innerhalb eines einzigen einheitlichen Deep-Learning-Frameworks möglich ist
