
 Technologie-Peripheriegeräte
KI
CRPS: Bewertungsfunktion für Bayesianische Modelle des maschinellen Lernens
Technologie-Peripheriegeräte
KI
CRPS: Bewertungsfunktion für Bayesianische Modelle des maschinellen Lernens
CRPS: Bewertungsfunktion für Bayesianische Modelle des maschinellen Lernens

Continuous Ranked Probability Score (CRPS) oder „Continuous Ranked Probability Score“ ist eine Funktion oder Statistik, die Verteilungsvorhersagen mit wahren Werten vergleicht.

Ein wichtiger Teil des maschinellen Lernworkflows ist die Modellbewertung. Der Prozess selbst kann als gesunder Menschenverstand angesehen werden: Teilen Sie die Daten in Trainings- und Testsätze auf, trainieren Sie das Modell auf dem Trainingssatz und verwenden Sie eine Bewertungsfunktion, um seine Leistung auf dem Testsatz zu bewerten.
Eine Bewertungsfunktion (oder Metrik) ordnet wahre Werte und ihre Vorhersagen einem einzigen und vergleichbaren Wert zu [1]. Für kontinuierliche Prognosen können Sie beispielsweise Scoring-Funktionen wie RMSE, MAE, MAPE oder R-Quadrat verwenden. Was ist, wenn es sich bei der Prognose nicht um eine punktuelle Schätzung, sondern um eine Verteilung handelt?
Beim Bayes'schen maschinellen Lernen sind Vorhersagen normalerweise keine punktuellen Schätzungen, sondern eher Verteilungen von Werten. Die Vorhersagen können beispielsweise geschätzte Parameter einer Verteilung oder im nichtparametrischen Fall eine Reihe von Stichproben aus einer MCMC-Methode sein.
In diesem Fall eignen sich herkömmliche Bewertungsfunktionen nicht für das statistische Design; die Aggregation vorhergesagter Verteilungen in ihren Mittelwert oder Median führt zum Verlust erheblicher Informationen über die Streuung und Form der vorhergesagten Verteilung.
CRPS
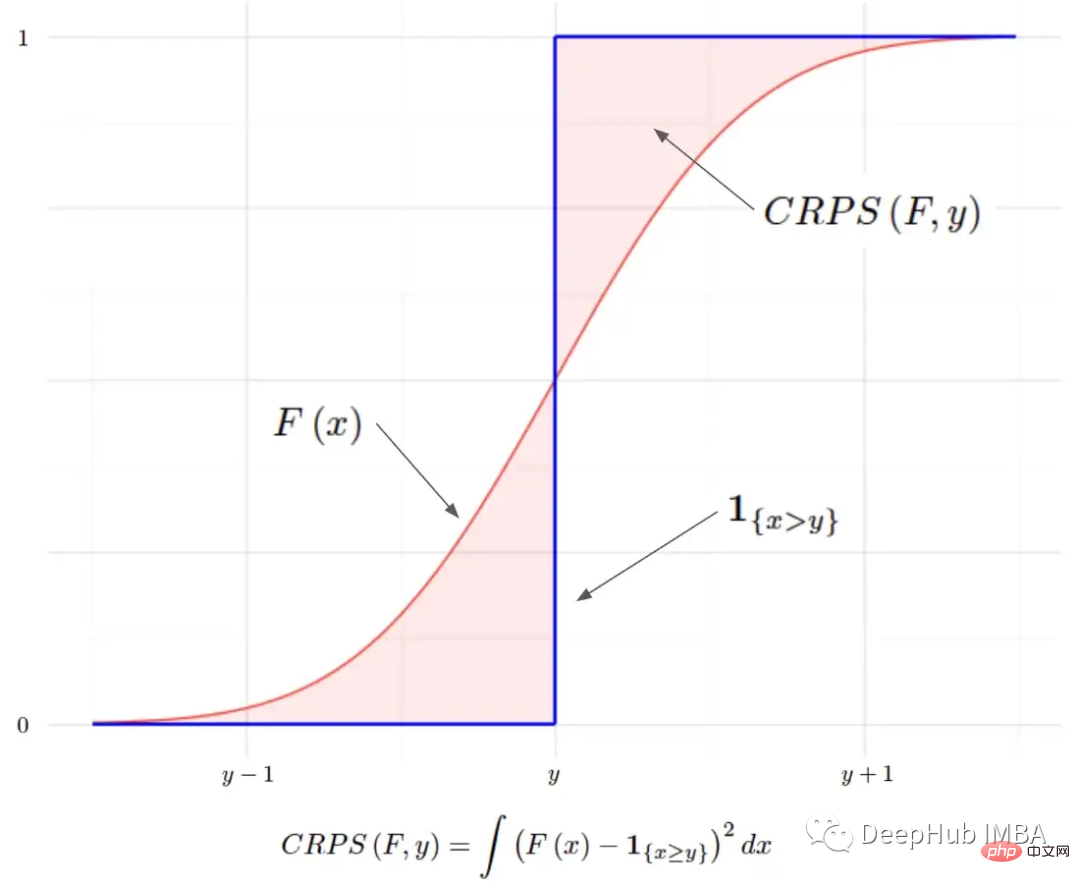
Continuous Graded Probability Score (CRPS) ist eine Bruchfunktion, die einen einzelnen wahren Wert mit einer kumulativen Verteilungsfunktion (CDF) vergleicht:

Sie wurde erstmals in den 1970er Jahren eingeführt [4] und wird hauptsächlich verwendet Die Wettervorhersage erhält nun in der Literatur und in der Industrie erneut Aufmerksamkeit [1][6]. Es kann als Metrik zur Bewertung der Modellleistung verwendet werden, wenn die Zielvariable kontinuierlich ist und das Modell die Verteilung des Ziels vorhersagt. Beispiele hierfür sind Bayes'sche Regression oder Bayes'sche Zeitreihenmodelle [5].
CRPS ist sowohl für parametrische als auch für nichtparametrische Vorhersagen mithilfe von CDF nützlich: Für viele Verteilungen verfügt CRPS [3] über einen analytischen Ausdruck, und für nichtparametrische Vorhersagen verwendet CRPS die empirische kumulative Verteilungsfunktion (eCDF).
Nach der Berechnung des CRPS für jede Beobachtung im Testsatz müssen Sie die Ergebnisse auch zu einem einzigen Wert zusammenfassen. Ähnlich wie bei RMSE und MAE werden sie mithilfe eines (möglicherweise gewichteten) Mittelwerts zusammengefasst:
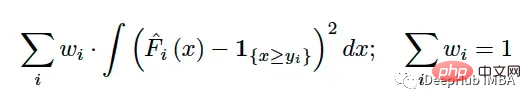
Die größte Herausforderung beim Vergleich eines einzelnen Werts mit einer Verteilung besteht darin, den einzelnen Wert in eine Darstellung der Verteilung umzuwandeln. CRPS löst dieses Problem, indem es die Grundwahrheit in eine entartete Verteilung mit einer Indikatorfunktion umwandelt. Wenn der wahre Wert beispielsweise 7 ist, können wir Folgendes verwenden:
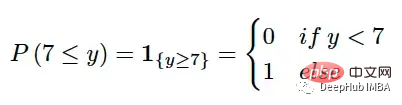
Die Indikatorfunktion ist ein gültiger CDF und kann alle Anforderungen eines CDF erfüllen. Die vorhergesagte Verteilung kann dann mit der degenerierten Verteilung der wahren Werte verglichen werden. Wir möchten auf jeden Fall, dass die vorhergesagte Verteilung der Realität so nahe wie möglich kommt. Daher kann dies mathematisch ausgedrückt werden, indem die (quadratische) Fläche zwischen diesen beiden CDFs gemessen wird:
MAE-zu-MAE-Beziehung
CRPS zum berühmten MAE ( Mittlerer absoluter Fehler) hängen eng zusammen. Wenn wir eine punktweise Vorhersage nehmen, sie als degenerierte CDF behandeln und in die CRPS-Gleichung einfügen, erhalten wir:

Wenn die Vorhersageverteilung also eine degenerierte Verteilung ist (z. B. punktweise Schätzung), wird dies beim CRPS der Fall sein auf MAE reduzieren. Dies hilft uns, CRPS aus einer anderen Perspektive zu verstehen: Es kann als Verallgemeinerung von MAE auf die Vorhersage von Verteilungen angesehen werden oder als MAE als Sonderfall von CRPS, wenn die Vorhersageverteilung degeneriert.
Wenn die Vorhersage des Modells eine parametrische Verteilung ist (z. B. müssen Verteilungsparameter vorhergesagt werden), verfügt CRPS über einen analytischen Ausdruck für einige gängige Verteilungen [3]. Wenn das Modell die Parameter μ und σ der Normalverteilung vorhersagt, kann das CRPS mit der folgenden Formel berechnet werden:

Dieses Schema kann für bekannte Verteilungen wie Beta-, Gamma-, Logistik-, Lognormalverteilung und andere lösen [3 ].
Die Berechnung des eCDF ist eine mühsame Aufgabe, wenn die Vorhersage nichtparametrisch ist, oder genauer gesagt, wenn die Vorhersage eine Reihe von Simulationen ist. Aber CRPS kann auch ausgedrückt werden als:

wobei X, X' F-unabhängig und identisch verteilt sind. Diese Ausdrücke sind einfacher zu berechnen, erfordern jedoch noch einige Berechnungen.
Python-Implementierung
import numpy as np # Adapted to numpy from pyro.ops.stats.crps_empirical # Copyright (c) 2017-2019 Uber Technologies, Inc. # SPDX-License-Identifier: Apache-2.0 def crps(y_true, y_pred, sample_weight=None): num_samples = y_pred.shape[0] absolute_error = np.mean(np.abs(y_pred - y_true), axis=0) if num_samples == 1: return np.average(absolute_error, weights=sample_weight) y_pred = np.sort(y_pred, axis=0) diff = y_pred[1:] - y_pred[:-1] weight = np.arange(1, num_samples) * np.arange(num_samples - 1, 0, -1) weight = np.expand_dims(weight, -1) per_obs_crps = absolute_error - np.sum(diff * weight, axis=0) / num_samples**2 return np.average(per_obs_crps, weights=sample_weight)
CRPS-Funktion gemäß NRG-Formular [2] implementiert. Angepasst von pyroppl[6]
import numpy as np def crps(y_true, y_pred, sample_weight=None): num_samples = y_pred.shape[0] absolute_error = np.mean(np.abs(y_pred - y_true), axis=0) if num_samples == 1: return np.average(absolute_error, weights=sample_weight) y_pred = np.sort(y_pred, axis=0) b0 = y_pred.mean(axis=0) b1_values = y_pred * np.arange(num_samples).reshape((num_samples, 1)) b1 = b1_values.mean(axis=0) / num_samples per_obs_crps = absolute_error + b0 - 2 * b1 return np.average(per_obs_crps, weights=sample_weight)
Der obige Code implementiert CRPS basierend auf der PWM-Form[2].
Zusammenfassung
Der Continuous Ranked Probability Score (CRPS) ist eine Bewertungsfunktion, die einen einzelnen wahren Wert mit seiner vorhergesagten Verteilung vergleicht. Diese Eigenschaft macht es für das Bayes'sche maschinelle Lernen relevant, wo Modelle typischerweise Verteilungsvorhersagen statt punktueller Schätzungen ausgeben. Es kann als eine Verallgemeinerung des bekannten MAE zur Verteilungsvorhersage angesehen werden.
Es verfügt über analytische Ausdrücke für parametrische Vorhersagen und kann einfache Berechnungen für nichtparametrische Vorhersagen durchführen. CRPS könnte zur neuen Standardmethode zur Bewertung der Leistung von Bayes'schen Modellen für maschinelles Lernen mit kontinuierlichen Zielen werden.
Das obige ist der detaillierte Inhalt vonCRPS: Bewertungsfunktion für Bayesianische Modelle des maschinellen Lernens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
 Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
In C++ umfasst die Implementierung von Algorithmen für maschinelles Lernen: Lineare Regression: Wird zur Vorhersage kontinuierlicher Variablen verwendet. Zu den Schritten gehören das Laden von Daten, das Berechnen von Gewichtungen und Verzerrungen, das Aktualisieren von Parametern und die Vorhersage. Logistische Regression: Wird zur Vorhersage diskreter Variablen verwendet. Der Prozess ähnelt der linearen Regression, verwendet jedoch die Sigmoidfunktion zur Vorhersage. Support Vector Machine: Ein leistungsstarker Klassifizierungs- und Regressionsalgorithmus, der die Berechnung von Support-Vektoren und die Vorhersage von Beschriftungen umfasst.
 Vollständige Sammlung von Excel-Funktionsformeln
May 07, 2024 pm 12:04 PM
Vollständige Sammlung von Excel-Funktionsformeln
May 07, 2024 pm 12:04 PM
1. Die SUMME-Funktion wird verwendet, um die Zahlen in einer Spalte oder einer Gruppe von Zellen zu summieren, zum Beispiel: =SUMME(A1:J10). 2. Die Funktion AVERAGE wird verwendet, um den Durchschnitt der Zahlen in einer Spalte oder einer Gruppe von Zellen zu berechnen, zum Beispiel: =AVERAGE(A1:A10). 3. COUNT-Funktion, die verwendet wird, um die Anzahl der Zahlen oder Texte in einer Spalte oder einer Gruppe von Zellen zu zählen, zum Beispiel: =COUNT(A1:A10) 4. IF-Funktion, die verwendet wird, um logische Urteile auf der Grundlage spezifizierter Bedingungen zu treffen und die zurückzugeben entsprechendes Ergebnis.
 Ausblick auf zukünftige Trends der Golang-Technologie im maschinellen Lernen
May 08, 2024 am 10:15 AM
Ausblick auf zukünftige Trends der Golang-Technologie im maschinellen Lernen
May 08, 2024 am 10:15 AM
Das Anwendungspotenzial der Go-Sprache im Bereich des maschinellen Lernens ist enorm. Ihre Vorteile sind: Parallelität: Sie unterstützt die parallele Programmierung und eignet sich für rechenintensive Operationen bei maschinellen Lernaufgaben. Effizienz: Der Garbage Collector und die Sprachfunktionen sorgen dafür, dass der Code auch bei der Verarbeitung großer Datenmengen effizient ist. Benutzerfreundlichkeit: Die Syntax ist prägnant und erleichtert das Erlernen und Schreiben von Anwendungen für maschinelles Lernen.
