
 Backend-Entwicklung
Python-Tutorial
Teilen Sie ein beliebtes Python-Visualisierungsmodul, einfach und schnell loslegen! !
Backend-Entwicklung
Python-Tutorial
Teilen Sie ein beliebtes Python-Visualisierungsmodul, einfach und schnell loslegen! !
Teilen Sie ein beliebtes Python-Visualisierungsmodul, einfach und schnell loslegen! !


Was ist Altair?
Altair wird als statistische Visualisierungsbibliothek bezeichnet, da es Daten durch Klassifizierung und Aggregation, Datentransformation, Dateninteraktion, grafische Zusammensetzung usw. umfassend verstehen, verstehen und analysieren kann und der Installationsprozess ebenfalls ist Ganz einfach. Es kann direkt über den Pip-Befehl wie folgt ausgeführt werden:
pip install altair pip install vega_datasets pip install altair_viewer
Wenn Sie den Conda-Paketmanager verwenden, um das Altair-Modul zu installieren, lautet der Code wie folgt:
conda install -c conda-forge altair vega_datasets
AltairInitial Experience
Versuchen wir einfach, ein Histogramm zu zeichnen. Erstellen Sie zunächst einen DataFrame-Datensatz:
df = pd.DataFrame({"brand":["iPhone","Xiaomi","HuaWei","Vivo"],
"profit(B)":[200,55,88,60]})Der nächste Schritt ist Code zum Zeichnen des Histogramms: # 🎜🎜#
import altair as alt import pandas as pd import altair_viewer chart = alt.Chart(df).mark_bar().encode(x="brand:N",y="profit(B):Q") # 展示数据,调用display()方法 altair_viewer.display(chart,inline=True)
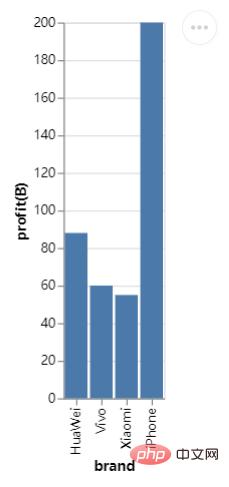
chart.save("chart.html")kann auch als JSON-Datei gespeichert werden, was vom Code her sehr ähnlich ist.
chart.save("chart.json")Natürlich können wir Dateien auch im Bildformat speichern, wie unten gezeigt:
 Erweiterte Funktionen von Altair #🎜 🎜#
Erweiterte Funktionen von Altair #🎜 🎜#
chart = alt.Chart(df).mark_bar().encode(x="profit(B):Q", y="brand:N")
chart.save("chart1.html")output
Gleichzeitig versuchen wir auch, ein Liniendiagramm zu zeichnen wird wie folgt aufgerufen:## 创建一组新的数据,以日期为行索引值
np.random.seed(29)
value = np.random.randn(365)
data = np.cumsum(value)
date = pd.date_range(start="20220101", end="20221231")
df = pd.DataFrame({"num": data}, index=date)
line_chart = alt.Chart(df.reset_index()).mark_line().encode(x="index:T", y="num:Q")
line_chart.save("chart2.html")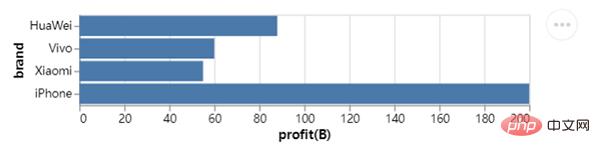 outputWir können auch ein Gantt-Diagramm zeichnen, einen Vergleich, der normalerweise im Projektmanagement verwendet wird. Mehr , die X-Achse fügt Zeit und Datum hinzu, während die Y-Achse den Fortschritt des Projekts darstellt. Der Code lautet wie folgt:
outputWir können auch ein Gantt-Diagramm zeichnen, einen Vergleich, der normalerweise im Projektmanagement verwendet wird. Mehr , die X-Achse fügt Zeit und Datum hinzu, während die Y-Achse den Fortschritt des Projekts darstellt. Der Code lautet wie folgt: project = [{"project": "Proj1", "start_time": "2022-01-16", "end_time": "2022-03-20"},
{"project": "Proj2", "start_time": "2022-04-12", "end_time": "2022-11-20"},
......
]
df = alt.Data(values=project)
chart = alt.Chart(df).mark_bar().encode(
alt.X("start_time:T",
axis=alt.Axis(format="%x",
formatType="time",
tickCount=3),
scale=alt.Scale(domain=[alt.DateTime(year=2022, month=1, date=1),
alt.DateTime(year=2022, month=12, date=1)])),
alt.X2("end_time:T"),
alt.Y("project:N", axis=alt.Axis(labelAlign="left",
labelFontSize=15,
labelOffset=0,
labelPadding=50)),
color=alt.Color("project:N", legend=alt.Legend(labelFontSize=12,
symbolOpacity=0.7,
titleFontSize=15)))
chart.save("chart_gantt.html")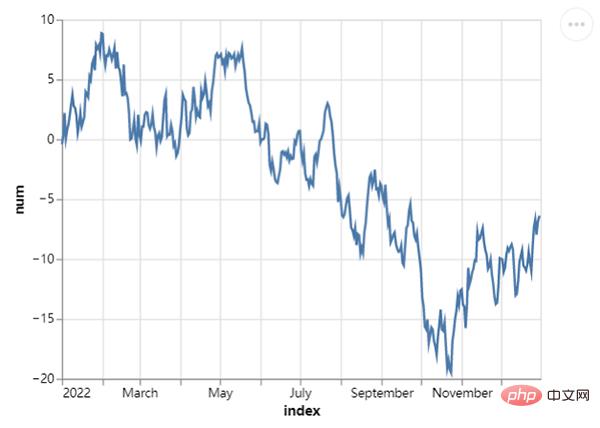 output #🎜🎜 #
output #🎜🎜 #Auf dem Bild oben können wir mehrere Projekte sehen, an denen das Team arbeitet. Natürlich ist auch die Zeitspanne der verschiedenen Projekte unterschiedlich Das Diagramm sieht sehr intuitiv aus.
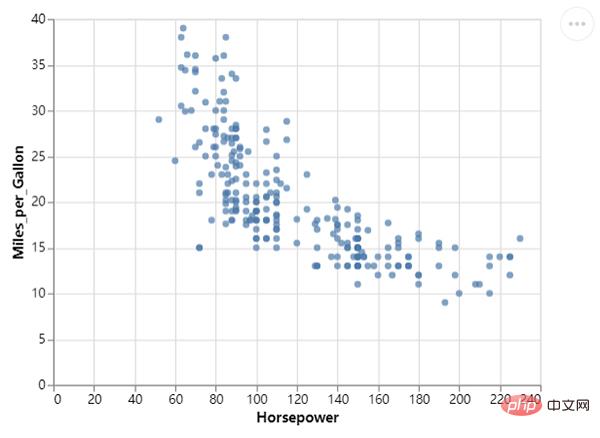
Als nächstes zeichnen wir das Streudiagramm und rufen die Methode mark_circle() auf. Der Code lautet wie folgt: 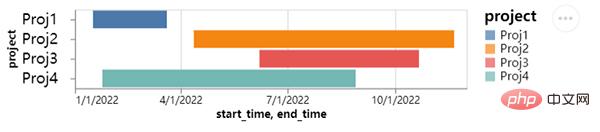
df = data.cars()
## 筛选出地区是“USA”也就是美国的乘用车数据
df_1 = alt.Chart(df).transform_filter(
alt.datum.Origin == "USA"
)
df = data.cars()
df_1 = alt.Chart(df).transform_filter(
alt.datum.Origin == "USA"
)
chart = df_1.mark_circle().encode(
alt.X("Horsepower:Q"),
alt.Y("Miles_per_Gallon:Q")
)
chart.save("chart_dots.html")chart = df_1.mark_circle(color=alt.RadialGradient("radial",[alt.GradientStop("white", 0.0),
alt.GradientStop("red", 1.0)]),
size=160).encode(
alt.X("Horsepower:Q", scale=alt.Scale(zero=False,padding=20)),
alt.Y("Miles_per_Gallon:Q", scale=alt.Scale(zero=False,padding=20))
)#🎜🎜 #
Wir ändern die Größe der Streupunkte. Die Größen der verschiedenen Streupunkte stellen unterschiedliche Werte dar. Der Code lautet wie folgt:
chart = df_1.mark_circle(color=alt.RadialGradient("radial",[alt.GradientStop("white", 0.0),
alt.GradientStop("red", 1.0)]),
size=160).encode(
alt.X("Horsepower:Q", scale=alt.Scale(zero=False, padding=20)),
alt.Y("Miles_per_Gallon:Q", scale=alt.Scale(zero=False, padding=20)),
size="Acceleration:Q"
)output#🎜 🎜##🎜 🎜#
Das obige ist der detaillierte Inhalt vonTeilen Sie ein beliebtes Python-Visualisierungsmodul, einfach und schnell loslegen! !. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
Bei der Installation von PyTorch am CentOS -System müssen Sie die entsprechende Version sorgfältig auswählen und die folgenden Schlüsselfaktoren berücksichtigen: 1. Kompatibilität der Systemumgebung: Betriebssystem: Es wird empfohlen, CentOS7 oder höher zu verwenden. CUDA und CUDNN: Pytorch -Version und CUDA -Version sind eng miteinander verbunden. Beispielsweise erfordert Pytorch1.9.0 CUDA11.1, während Pytorch2.0.1 CUDA11.3 erfordert. Die Cudnn -Version muss auch mit der CUDA -Version übereinstimmen. Bestimmen Sie vor der Auswahl der Pytorch -Version unbedingt, dass kompatible CUDA- und CUDNN -Versionen installiert wurden. Python -Version: Pytorch Official Branch
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
