

Was maschinelles Lernen betrifft, ist Audio selbst ein komplettes Feld mit einem breiten Anwendungsspektrum, einschließlich Spracherkennung, Musikklassifizierung, Erkennung von Schallereignissen usw. Bei der Audioklassifizierung werden traditionell Methoden wie die Spektrogrammanalyse und versteckte Markov-Modelle verwendet, die sich als effektiv erwiesen haben, aber auch ihre Grenzen haben. In letzter Zeit hat sich VIT als vielversprechende Alternative für Audioaufgaben herausgestellt, wobei Whisper von OpenAI ein gutes Beispiel ist.

Der GTZAN-Datensatz ist der am häufigsten verwendete öffentliche Datensatz in der Musikgenreerkennungsforschung (MGR). Die Dateien wurden in den Jahren 2000–2001 aus verschiedenen Quellen gesammelt, darunter persönliche CDs, Radios und Mikrofonaufnahmen, und stellen Geräusche unter verschiedenen Aufnahmebedingungen dar.
Dieser Datensatz besteht aus Unterordnern, jeder Unterordner ist ein Typ.
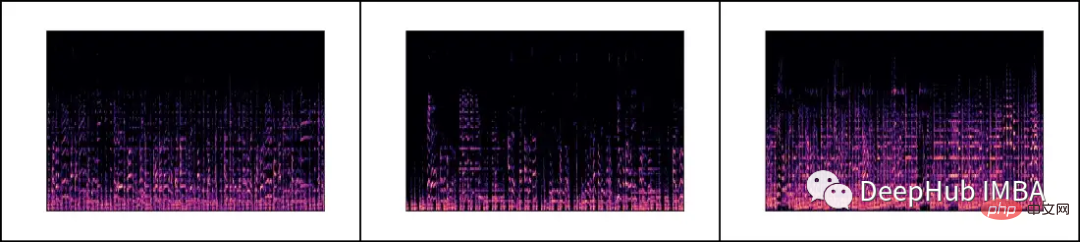
Wir laden jede .wav-Datei und generieren das entsprechende Mel-Spektrum über die librosa-Bibliothek.
Ein Mel-Spektrogramm ist eine visuelle Darstellung des Spektralinhalts eines Tonsignals. Seine vertikale Achse stellt die Frequenz auf der Mel-Skala dar und die horizontale Achse stellt die Zeit dar. Es handelt sich um eine häufig verwendete Darstellung in der Audiosignalverarbeitung, insbesondere im Bereich des Abrufens von Musikinformationen.
Mel-Skala (englisch: Mel-Skala) ist eine Skala, die die menschliche Tonhöhenwahrnehmung berücksichtigt. Da Menschen keine linearen Frequenzbereiche wahrnehmen, bedeutet dies, dass wir Unterschiede bei niedrigen Frequenzen besser erkennen können als bei hohen Frequenzen. Wir können zum Beispiel leicht den Unterschied zwischen 500 Hz und 1000 Hz erkennen, aber es fällt uns schwerer, den Unterschied zwischen 10.000 Hz und 10.500 Hz zu erkennen, selbst wenn der Abstand zwischen ihnen gleich ist. Die Mel-Skala löst also dieses Problem. Wenn die Unterschiede in der Mel-Skala gleich sind, bedeutet das, dass die vom Menschen wahrgenommenen Tonhöhenunterschiede gleich sind.
def wav2melspec(fp):
y, sr = librosa.load(fp)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
log_S = librosa.amplitude_to_db(S, ref=np.max)
img = librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
# get current figure without white border
img = plt.gcf()
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
img.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0,
hspace = 0, wspace = 0)
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
# to pil image
img.canvas.draw()
img = Image.frombytes('RGB', img.canvas.get_width_height(), img.canvas.tostring_rgb())
return imgDie obige Funktion erzeugt ein einfaches Mel-Spektrogramm:

Jetzt laden wir den Datensatz aus dem Ordner und wenden die Transformation auf das Bild an.
class AudioDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self.classes = sorted(os.listdir(root))
self.class_to_idx = {c: i for i, c in enumerate(self.classes)}
self.samples = []
for c in self.classes:
for fp in os.listdir(os.path.join(root, c)):
self.samples.append((os.path.join(root, c, fp), self.class_to_idx[c]))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
fp, target = self.samples[idx]
img = Image.open(fp)
if self.transform:
img = self.transform(img)
return img, target
train_dataset = AudioDataset(root, transform=transforms.Compose([
transforms.Resize((480, 480)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))Wir werden ViT als unser Modell verwenden: Vision Transformer führte in der Arbeit zunächst ein Bild ein, das 16 x 16 Wörtern entspricht, und demonstrierte erfolgreich, dass diese Methode nicht auf CNN angewiesen ist und direkt auf einen reinen Transformer angewendet werden kann einer Folge von Bildfeldern kann Bildklassifizierungsaufgaben gut durchführen.
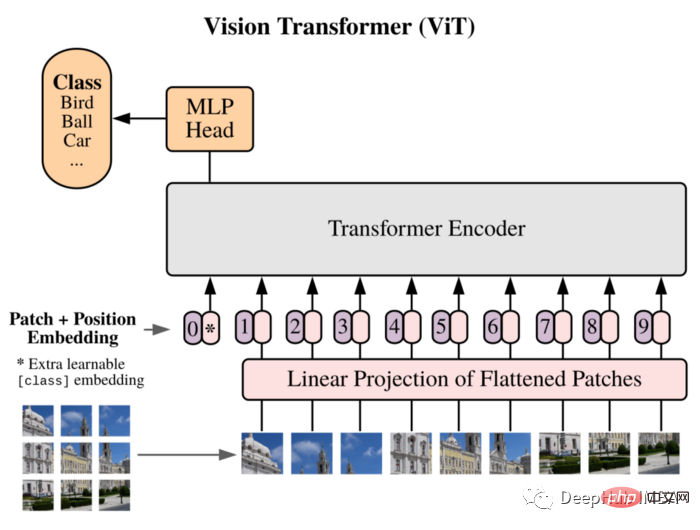
Teilen Sie das Bild in Patches auf und verwenden Sie die lineare Einbettungssequenz dieser Patches als Eingabe des Transformers. Patches werden in NLP-Anwendungen genauso behandelt wie Token (Wörter).
Aufgrund des Fehlens einer induktiven Vorspannung (z. B. Lokalität), die CNN innewohnt, kann Transformer nicht gut verallgemeinern, wenn die Menge an Trainingsdaten nicht ausreicht. Aber wenn es auf große Datensätze trainiert wird, erreicht oder übertrifft es den Stand der Technik bei mehreren Bilderkennungs-Benchmarks.
Die Struktur der Implementierung ist wie folgt:
class ViT(nn.Sequential): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 356, depth: int = 12, n_classes: int = 1000, **kwargs): super().__init__( PatchEmbedding(in_channels, patch_size, emb_size, img_size), TransformerEncoder(depth, emb_size=emb_size, **kwargs), ClassificationHead(emb_size, n_classes)
Die Trainingsschleife ist ebenfalls ein traditioneller Trainingsprozess:
vit = ViT(
n_classes = len(train_dataset.classes)
)
vit.to(device)
# train
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
optimizer = optim.Adam(vit.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(optimizer, 'max', factor=0.3, patience=3, verbose=True)
criterion = nn.CrossEntropyLoss()
num_epochs = 30
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
vit.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm.tqdm(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = vit(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_dataset)
epoch_acc = running_corrects.double() / len(train_dataset)
scheduler.step(epoch_acc)
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))Diese benutzerdefinierte Implementierung der Vision Transformer-Architektur wurde von Grund auf mit PyTorch trainiert. Da der Datensatz sehr klein ist (nur 100 Stichproben pro Klasse), beeinträchtigt dies die Leistung des Modells und es wird nur eine Genauigkeit von 0,71 erreicht.
Dies ist nur eine einfache Demonstration. Wenn Sie die Modellleistung verbessern müssen, können Sie einen größeren Datensatz verwenden oder die verschiedenen Hyperparameter der Architektur leicht anpassen.
Der hier verwendete Vit-Code stammt von:
https: //medium.com/artificialis/vit-visiontransformer-a-pytorch-implementation-8d6a1033bdc5
Das obige ist der detaillierte Inhalt vonVon Video zu Audio: Audioklassifizierung mit VIT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 So kaufen und verkaufen Sie Bitcoin auf Binance
So kaufen und verkaufen Sie Bitcoin auf Binance
 So drücken Sie den Breitenwert in CSS aus
So drücken Sie den Breitenwert in CSS aus
 So öffnen Sie eine DB-Datei
So öffnen Sie eine DB-Datei
 Zusammenfassung der Java-Grundkenntnisse
Zusammenfassung der Java-Grundkenntnisse
 So verwenden Sie die Diktatfunktion in Python
So verwenden Sie die Diktatfunktion in Python
 Welche Software ist Openal?
Welche Software ist Openal?
 Datenstruktur der C-Sprache
Datenstruktur der C-Sprache








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



