
 Technologie-Peripheriegeräte
KI
Ist das KI-Spiel nach dem Aufkommen supergroßer Modelle vorbei? Gary Marcus: Der Weg ist schmal
Technologie-Peripheriegeräte
KI
Ist das KI-Spiel nach dem Aufkommen supergroßer Modelle vorbei? Gary Marcus: Der Weg ist schmal
Ist das KI-Spiel nach dem Aufkommen supergroßer Modelle vorbei? Gary Marcus: Der Weg ist schmal

In jüngster Zeit hat die von Google gestern vorgeschlagene Technologie der künstlichen Intelligenz in großen Modellen Durchbrüche erzielt, die erneut Diskussionen über KI-Funktionen ausgelöst haben. Durch das Lernen vor dem Training aus großen Datenmengen verfügt der Algorithmus über beispiellose Fähigkeiten beim Erstellen realistischer Bilder und beim Verstehen von Sprache.
Viele Menschen sind der Meinung, dass wir der allgemeinen künstlichen Intelligenz nahe stehen, aber Gary Marcus, ein bekannter Wissenschaftler und Professor an der New York University, glaubt nicht daran.
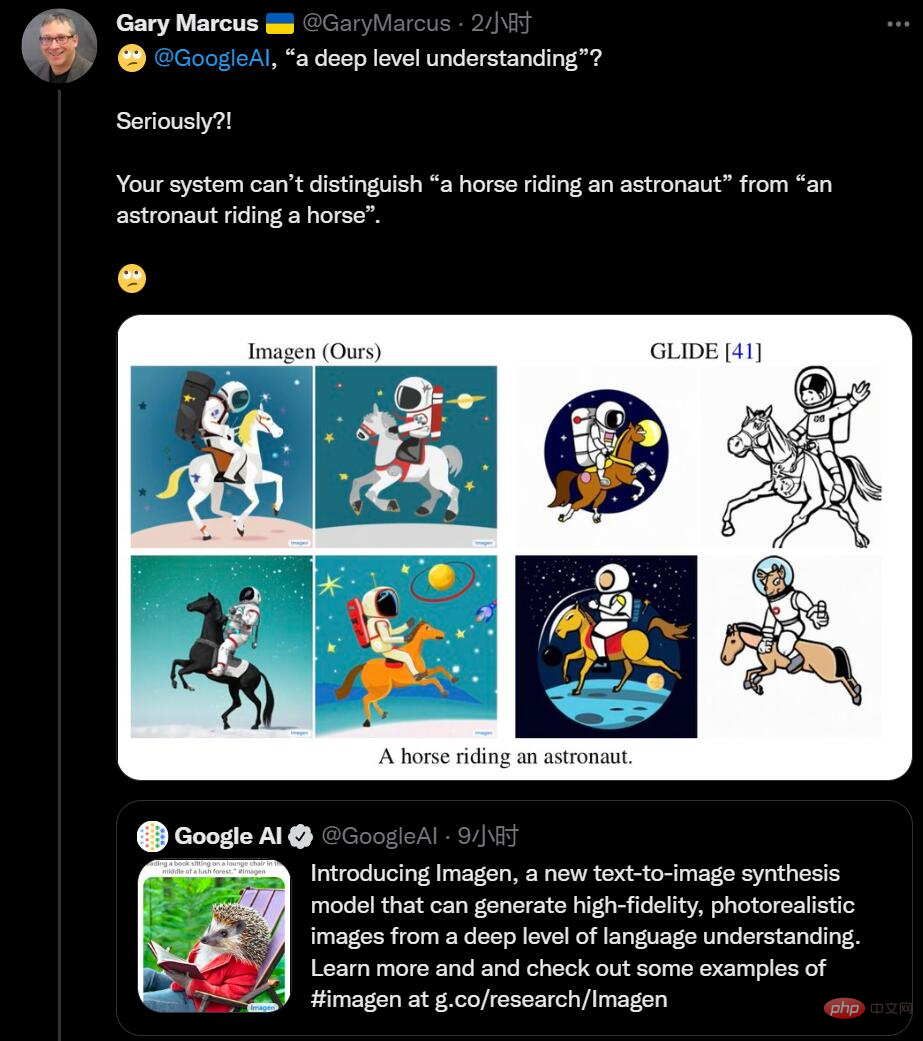
Kürzlich widerlegte sein Artikel „The New Science of Alt Intelligence“ die Ansicht von DeepMind Research Director Nando de Freitas vom „Gewinnen in großem Maßstab“.
Das Folgende ist der Originaltext von Gary Marcus:
Seit Jahrzehnten gibt es im Bereich der KI die Annahme, dass künstliche Intelligenz von natürlicher Intelligenz inspiriert werden sollte. John McCarthy schrieb eine bahnbrechende Arbeit darüber, warum KI gesunden Menschenverstand braucht – „Programme mit gesundem Menschenverstand“; Marvin Minsky schrieb das berühmte Buch „Society of Mind“ und versuchte, sich von der Verhaltensökonomie inspirieren zu lassen Nobelpreisträger für Wirtschaftswissenschaften für seine Beiträge, schrieb die berühmten „Modelle des Denkens“, die darauf abzielten zu erklären, „wie neu entwickelte Computersprachen Theorien psychologischer Prozesse ausdrücken, damit Computer vorhergesagtes menschliches Verhalten simulieren können.“ Wissen Sie, einem großen Teil der aktuellen KI-Forscher (zumindest den einflussreicheren) ist das überhaupt egal. Stattdessen konzentrieren sie sich mehr auf das, was ich „Alt Intelligence“ nenne (danke an Naveen Rao für seinen Beitrag zu diesem Begriff).
Alt Intelligence bedeutet nicht, Maschinen zu bauen, die Probleme auf die gleiche Weise lösen können wie menschliche Intelligenz, sondern vielmehr die Nutzung großer Datenmengen, die aus menschlichem Verhalten gewonnen werden, um Intelligenz zu ersetzen. Derzeit liegt der Schwerpunkt von Alt Intelligence auf der Skalierung. Befürworter solcher Systeme argumentieren, dass wir der wahren Intelligenz und sogar dem Bewusstsein umso näher kommen, je größer das System ist.
Das Studium der Alt-Intelligenz selbst ist nichts Neues, wohl aber die damit verbundene Arroganz.
Seit einiger Zeit sehe ich einige Anzeichen dafür, dass die aktuellen Superstars der künstlichen Intelligenz und sogar die meisten Menschen auf dem gesamten Gebiet der künstlichen Intelligenz die menschliche Erkenntnis ablehnen und Linguistik, kognitive Psychologie, Anthropologie und Wissenschaftler ignorieren oder sich sogar darüber lustig machen Bereiche wie Philosophie.
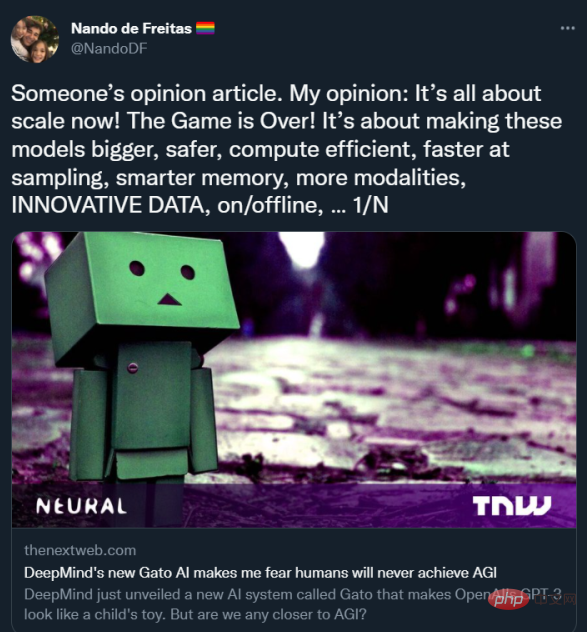
Aber heute Morgen habe ich einen neuen Tweet über Alt Intelligence entdeckt. Nando de Freitas, der Autor des Tweets und Forschungsdirektor bei DeepMind, erklärte, dass es bei der KI „jetzt nur noch um Skalierung geht“. Tatsächlich sind seiner Ansicht nach (vielleicht absichtlich provozierend mit feuriger Rhetorik) die schwierigeren Herausforderungen in der KI bereits gelöst. „Spiel vorbei!“ sagte er.
 Im Wesentlichen ist es nichts Falsches daran, Alt Intelligence zu verfolgen.
Im Wesentlichen ist es nichts Falsches daran, Alt Intelligence zu verfolgen.
Alt Intelligence repräsentiert eine Intuition (oder eine Reihe von Intuitionen) darüber, wie man intelligente Systeme baut. Da noch niemand weiß, wie man Systeme baut, die mit der Flexibilität und Intelligenz der menschlichen Intelligenz mithalten können, ist es ein faires Spiel für die Menschen, viele verschiedene Hypothesen darüber zu verfolgen, wie dies erreicht werden kann. Nando de Freitas verteidigt diese Hypothese so unverblümt wie möglich, und ich nenne sie Scaling-Uber-Alles.
Natürlich wird der Name dem nicht ganz gerecht. De Freitas macht deutlich, dass man das Modell nicht einfach vergrößern und Erfolg erwarten kann. Die Leute haben in letzter Zeit viel skaliert und einige große Erfolge erzielt, sind aber auch auf einige Hindernisse gestoßen. Bevor wir näher darauf eingehen, wie De Freitas mit dem Status Quo umgeht, werfen wir einen Blick darauf, wie der Status Quo aussieht.
StatusSysteme wie DALL-E 2, GPT-3, Flamingo und
Gato mögen aufregend erscheinen, aber niemand, der diese Modelle sorgfältig studiert hat, würde sie mit menschlicher Intelligenz verwechseln. Zum Beispiel kann DALL-E 2 realistische Kunstwerke basierend auf Textbeschreibungen erstellen, wie zum Beispiel „Ein Astronaut auf einem Pferd“:
 Aber es ist auch anfällig für überraschende Fehler, etwa beim Text ist „ein rotes Quadrat auf einem blauen Quadrat“. Die von DALL-E generierten Ergebnisse sind wie im linken Bild dargestellt, und das rechte Bild ist das vom vorherigen Modell generierte Ergebnis. Die Generierungsergebnisse von DALL-E sind eindeutig schlechter als bei früheren Modellen.
Aber es ist auch anfällig für überraschende Fehler, etwa beim Text ist „ein rotes Quadrat auf einem blauen Quadrat“. Die von DALL-E generierten Ergebnisse sind wie im linken Bild dargestellt, und das rechte Bild ist das vom vorherigen Modell generierte Ergebnis. Die Generierungsergebnisse von DALL-E sind eindeutig schlechter als bei früheren Modellen.
Als Ernest Davis, Scott Aaronson und ich uns mit diesem Thema befassten, fanden wir viele ähnliche Beispiele: 
Außerdem hat der scheinbar atemberaubende Flamingo als DeepMind-Senior auch seinen eigenen Fehler Der Forscher Murray Shanahan wies in einem Tweet darauf hin, und Flamingos Hauptautor Jean-Baptiste Alayrac fügte später einige Beispiele hinzu. Shanahan zeigte Flamingo beispielsweise ein Bild wie dieses:
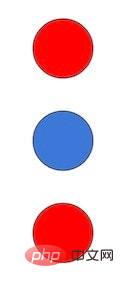
und führte die folgende fehlerhafte Konversation rund um das Bild:
# 🎜🎜## 🎜🎜# scheint „aus dem Nichts gemacht“ zu sein.
scheint „aus dem Nichts gemacht“ zu sein.
Vor einiger Zeit hat DeepMind auch den multimodalen, multitaskingfähigen und vielgestaltigen „Generalisten“-Agenten Gato herausgebracht, aber wenn man sich das Kleingedruckte ansieht, kann man immer noch Unzuverlässigkeit feststellen. Natürlich werden Befürworter des Deep Learning darauf hinweisen, dass Menschen Fehler machen.
Aber jeder ehrliche Mensch wird erkennen, dass diese Fehler darauf hinweisen, dass derzeit etwas defekt ist. Man kann ohne Übertreibung sagen: Wenn meine Kinder regelmäßig solche Fehler machen würden, würde ich alles, was ich tue, aufgeben und sie sofort zum Neurologen bringen.
Seien wir mal ehrlich: Skalierung funktioniert noch nicht, aber möglich ist es zumindest, so zumindest die Theorie von de Freitas – ein klarer Ausdruck des Zeitgeists. Wie bringt de Freitas also Realität und Ehrgeiz in Einklang? Tatsächlich wurden mittlerweile Milliarden von Dollar in Transformer und viele andere verwandte Bereiche investiert, Trainingsdatensätze wurden von Megabyte auf Gigabyte erweitert und Parametergrößen wurden von Millionen auf Billionen erweitert. Allerdings bleiben rätselhafte Irrtümer bestehen, die seit 1988 in zahlreichen Werken ausführlich dokumentiert wurden. 
Dies bestätigte erneut, dass er „größer ist“. als alles andere“ und gab ein Ziel an: Sein Ziel ist nicht nur eine bessere KI, sondern auch AGI.
AGI steht für Artificial General Intelligence, die mindestens so gut, so einfallsreich und breit anwendbar ist wie die menschliche Intelligenz. Der enge Sinn von künstlicher Intelligenz, den wir derzeit erkennen, ist eigentlich alternative Intelligenz (Alt-Intelligenz), und ihre ikonischen Erfolge sind Spiele wie Schach (Deep Blue hat nichts mit menschlicher Intelligenz zu tun) und Go (AlphaGo hat wenig mit menschlicher Intelligenz zu tun). . De Freitas hat ehrgeizigere Ziele und man muss ihm zugute halten, dass er diese sehr offen anspricht. Wie erreicht er also sein Ziel? Um es noch einmal zu wiederholen: de Freitas konzentriert sich auf technische Tools zur Aufnahme größerer Datensätze. Andere Ideen, etwa aus der Philosophie oder der Kognitionswissenschaft, mögen wichtig sein, werden aber ausgeschlossen.
Er sagte: „Die Philosophie der Symbole ist nicht notwendig.“ Vielleicht ist dies eine Widerlegung meiner langjährigen Bewegung, symbolische Manipulation in die Kognitionswissenschaft und künstliche Intelligenz zu integrieren. Die Idee tauchte kürzlich im Nautilus-Magazin wieder auf, obwohl sie noch nicht vollständig ausgearbeitet wurde. Hier ist meine kurze Antwort: Was er sagte: „[neuronale] Netze haben kein Problem damit, [Symbole] zu erstellen und sie zu manipulieren“, ignoriert sowohl die Geschichte als auch die Realität. Was er ignoriert, ist die Geschichte, dass sich viele Enthusiasten neuronaler Netze seit Jahrzehnten gegen Symbole gewehrt haben; er ignoriert die Realität, dass symbolische Beschreibungen wie der oben erwähnte „rote Würfel auf einem blauen Würfel“ immer noch den Verstand des SOTA-Modells 2022 verblüffen können.
Am Ende des Tweets drückte De Freitas seine Zustimmung zu Rich Suttons berühmtem Artikel „Bitter Lessons“ aus:
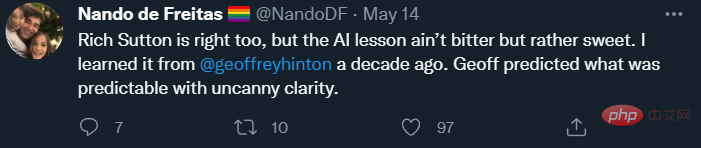
Suttons Argument ist, dass das Einzige, was zu Fortschritten in der KI führen wird, mehr Daten und effizientere Berechnungen sind. Meiner Meinung nach hat Sutton nur halb recht, seine Beschreibung der Vergangenheit ist fast richtig, aber seine induktiven Vorhersagen für die Zukunft sind nicht überzeugend.
Bisher hat Big Data in den meisten Bereichen (sicherlich nicht in allen Bereichen) (vorübergehend) den Sieg über gut konzipiertes Knowledge Engineering verdrängt.
Aber fast alle Software auf der Welt, von Webbrowsern über Tabellenkalkulationen bis hin zu Textverarbeitungsprogrammen, basiert immer noch auf Knowledge Engineering, und Sutton ignoriert dies. Beispielsweise ist die hervorragende Flash Fill-Funktion von Sumit Gulwani ein sehr nützliches System zum einmaligen Lernen, das überhaupt nicht auf der Prämisse von Big Data, sondern auf klassischen Programmiertechniken basiert.
Ich glaube nicht, dass ein reines Deep-Learning-/Big-Data-System damit mithalten kann.
Tatsächlich sind die Hauptprobleme der künstlichen Intelligenz, auf die Kognitionswissenschaftler wie Steve Pinker, Judea Pearl, Jerry Fodor und ich seit Jahrzehnten hinweisen, tatsächlich noch nicht gelöst. Ja, Maschinen können sehr gut Spiele spielen, und Deep Learning hat in Bereichen wie der Spracherkennung große Fortschritte gemacht. Aber keine künstliche Intelligenz verfügt derzeit über genügend Verständnis, um Texte zu erkennen und ein Modell zu erstellen, das normal sprechen und Aufgaben erledigen kann, noch kann sie wie die Computer in den „Star Trek“-Filmen argumentieren und eine zusammenhängende Reaktion hervorrufen.
Wir befinden uns noch im Anfangsstadium der künstlichen Intelligenz.
Bei einigen Problemen mit bestimmten Strategien erfolgreich zu sein, garantiert nicht, dass wir alle Probleme auf ähnliche Weise lösen. Es wäre einfach dumm, dies nicht zu erkennen, insbesondere wenn einige der Fehlermodi (Unzuverlässigkeit, seltsame Fehler, kombinatorische Fehler und Unverständnis) unverändert geblieben sind, seit Fodor und Pinker sie 1988 aufgezeigt haben. Fazit Bringen Sie uns zur Verallgemeinerung auf menschlicher Ebene. Lasst uns einen Bereich fördern, der so aufgeschlossen ist, dass Menschen ihre eigene Arbeit in viele Richtungen entwickeln können, ohne Ideen, die zufällig noch nicht vollständig entwickelt sind, vorzeitig zu verwerfen. Schließlich ist Alt Intelligence möglicherweise nicht der beste Weg zur (allgemeinen) künstlichen Intelligenz.
Wie bereits erwähnt, würde ich mir Gato gerne als „alternative Intelligenz“ vorstellen – eine interessante Erkundung alternativer Wege zum Aufbau von Intelligenz, aber wir müssen es ins rechte Licht rücken: Es wird nicht wie ein Gehirn funktionieren, es wird nicht wie ein Kind funktionieren. Auf diese Weise gelernt, versteht es die Sprache nicht, steht im Widerspruch zu menschlichen Werten und kann nicht darauf vertrauen, dass es wichtige Aufgaben erledigt.
Es ist vielleicht besser als alles andere, was wir derzeit haben, aber es funktioniert immer noch nicht wirklich, und selbst nachdem wir viel investiert haben, ist es für uns an der Zeit, eine Pause einzulegen. 
Das obige ist der detaillierte Inhalt vonIst das KI-Spiel nach dem Aufkommen supergroßer Modelle vorbei? Gary Marcus: Der Weg ist schmal. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Detaillierte Erläuterung der SQLORDSBY -Klausel: Die effiziente Sortierung der Datenreihenfolge -Klausel ist eine Schlüsselanweisung in SQL, die zur Sortierung von Abfrageergebnissen verwendet wird. Es kann in einzelnen Spalten oder mehreren Spalten in den Aufstieg (ASC) oder absteigender Reihenfolge (Desc) angeordnet werden, wodurch die Datenlesbarkeit und die Effizienz der Datenverwaltung erheblich verbessert werden. OrderBy syntax SelectColumn1, Spalte2, ... fromTable_NameOrDByColumn_Name [ASC | Desc]; Column_Name: Sortieren nach Spalte. ASC: Ascending Order Sort (Standard). Desc: Sortieren Sie in absteigender Reihenfolge. OrderBy Hauptmerkmale: Multi-Sortier-Sortierung: Unterstützt mehrere Spaltensortierungen, und die Reihenfolge der Spalten bestimmt die Priorität der Sortierung. seit
 Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Häufige Fehler und Lösungen beim Anschließen mit Datenbanken: Benutzername oder Kennwort (Fehler 1045) Firewall -Blocks -Verbindungsverbindung (Fehler 2003) Timeout (Fehler 10060) Die Verwendung von Socket -Verbindung kann nicht verwendet werden (Fehler 1042).
 So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
Mit der SQL -Insert -Anweisung wird eine Datenbanktabelle neue Zeilen hinzufügen, und ihre Syntax ist: Intable_Name (Spalte1, Spalte2, ..., Columnn) Werte (Value1, Value2, ..., Valuen);. Diese Anweisung unterstützt das Einfügen mehrerer Werte und ermöglicht es, Nullwerte in Spalten eingefügt zu werden. Es ist jedoch erforderlich, sicherzustellen, dass die eingefügten Werte mit dem Datentyp der Spalte kompatibel sind, um zu vermeiden, dass Einzigartigkeitsbeschränkungen verstoßen.
 So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
Fügen Sie einer vorhandenen Tabelle in SQL neue Spalten hinzu, indem Sie die Anweisung für die Änderung Tabelle verwenden. Zu den spezifischen Schritten gehören: Ermittlung des Tabellennamens und Spalteninformationen, Schreiben von Alter Tabellenanweisungen und Ausführungsanweisungen. Fügen Sie beispielsweise eine E -Mail -Spalte in die Tabelle der Kunden hinzu (VARCHAR (50)): Änderung der Tabelle Kunden addieren Sie E -Mail -Varchar (50).
