
 Technologie-Peripheriegeräte
KI
Illustration der zehn am häufigsten verwendeten Algorithmen für maschinelles Lernen!
Technologie-Peripheriegeräte
KI
Illustration der zehn am häufigsten verwendeten Algorithmen für maschinelles Lernen!
Illustration der zehn am häufigsten verwendeten Algorithmen für maschinelles Lernen!

Im Bereich des maschinellen Lernens gibt es ein Sprichwort mit dem Titel „Es gibt kein kostenloses Mittagessen auf der Welt“. Kurz gesagt bedeutet dies, dass kein Algorithmus bei jedem Problem die beste Wirkung erzielen kann wichtig.
Zum Beispiel kann man nicht sagen, dass neuronale Netze immer besser sind als Entscheidungsbäume oder umgekehrt. Die Modellausführung wird von vielen Faktoren beeinflusst, beispielsweise der Größe und Struktur des Datensatzes.
Daher sollten Sie viele verschiedene Algorithmen basierend auf Ihrem Problem ausprobieren und gleichzeitig einen Testdatensatz verwenden, um die Leistung zu bewerten und den besten auszuwählen.
Natürlich muss der Algorithmus, den Sie ausprobieren, für Ihr Problem relevant sein, und der Schlüssel liegt in der Hauptaufgabe des maschinellen Lernens. Wenn Sie beispielsweise Ihr Haus reinigen möchten, können Sie einen Staubsauger, einen Besen oder einen Mopp verwenden, aber Sie würden nicht eine Schaufel nehmen und anfangen, ein Loch zu graben.
Für Neulinge im maschinellen Lernen, die die Grundlagen des maschinellen Lernens verstehen möchten, finden Sie hier die zehn wichtigsten Algorithmen für maschinelles Lernen, die von Datenwissenschaftlern verwendet werden. Wir stellen Ihnen die Eigenschaften dieser zehn besten Algorithmen vor, damit jeder sie besser verstehen und anwenden kann . Komm, schau mal rein.
01 Lineare Regression
Die lineare Regression ist wahrscheinlich einer der bekanntesten und am einfachsten zu verstehenden Algorithmen in der Statistik und im maschinellen Lernen.
Da es bei der prädiktiven Modellierung hauptsächlich darum geht, den Fehler des Modells zu minimieren oder möglichst genaue Vorhersagen auf Kosten der Interpretierbarkeit zu treffen. Wir leihen, verwenden und stehlen Algorithmen aus vielen verschiedenen Bereichen, und dazu sind einige statistische Kenntnisse erforderlich.
Die lineare Regression wird durch eine Gleichung dargestellt, die die lineare Beziehung zwischen der Eingabevariablen (x) und der Ausgabevariablen (y) beschreibt, indem das spezifische Gewicht (B) der Eingabevariablen ermittelt wird.
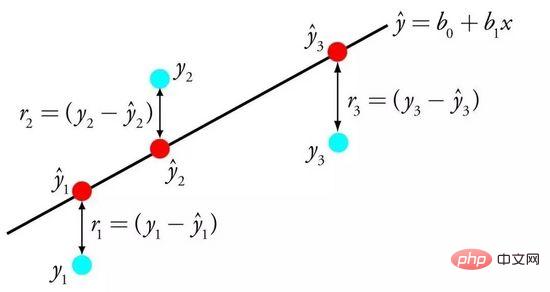
Lineare Regression
Beispiel: y = B0 + B1 * x
Angesichts der Eingabe x werden wir y vorhersagen. Das Ziel des linearen Regressionslernalgorithmus besteht darin, die Werte der Koeffizienten B0 und zu finden B1.
Lineare Regressionsmodelle können mithilfe verschiedener Techniken aus Daten erlernt werden, z. B. lineare Algebra-Lösungen für gewöhnliche kleinste Quadrate und Gradientenabstiegsoptimierung.
Die lineare Regression gibt es seit über 200 Jahren und sie wurde umfassend erforscht. Einige Faustregeln bei der Verwendung dieser Technik bestehen darin, sehr ähnliche (korrelierte) Variablen zu entfernen und nach Möglichkeit Rauschen aus den Daten zu entfernen. Dies ist eine schnelle und einfache Technik und ein guter erster Algorithmus.
02 Logistische Regression
Die logistische Regression ist eine weitere Technik, die maschinelles Lernen aus dem Bereich der Statistik übernimmt. Dies ist eine spezielle Methode für binäre Klassifikationsprobleme (Probleme mit zwei Klassenwerten).
Die logistische Regression ähnelt der linearen Regression darin, dass das Ziel beider darin besteht, den Gewichtungswert jeder Eingabevariablen zu ermitteln. Im Gegensatz zur linearen Regression wird der vorhergesagte Wert der Ausgabe mithilfe einer nichtlinearen Funktion namens Logistikfunktion transformiert.
Logistische Funktionen sehen aus wie ein großes S und wandeln jeden Wert in den Bereich von 0 bis 1 um. Dies ist nützlich, da wir die entsprechenden Regeln auf die Ausgabe der Logistikfunktion anwenden, die Werte in 0 und 1 klassifizieren können (z. B. wenn IF kleiner als 0,5 ist, dann Ausgabe 1) und den Klassenwert vorhersagen können.
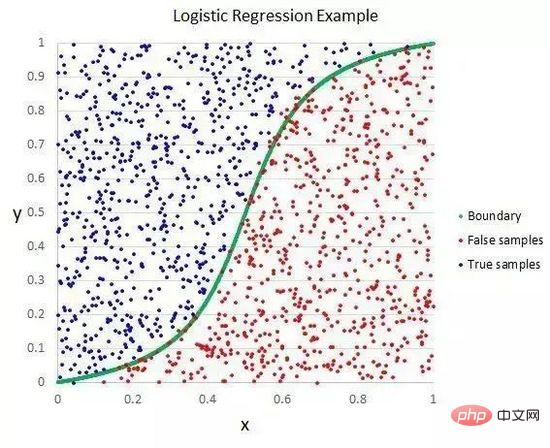
Logistische Regression
Aufgrund der einzigartigen Lernmethode des Modells können Vorhersagen durch logistische Regression auch zur Berechnung der Wahrscheinlichkeit der Zugehörigkeit zu Klasse 0 oder Klasse 1 verwendet werden. Dies ist nützlich bei Problemen, die viele Begründungen erfordern.
Wie die lineare Regression funktioniert auch die logistische Regression besser, wenn Sie Attribute entfernen, die nicht mit der Ausgabevariablen in Zusammenhang stehen, und Attribute, die einander sehr ähnlich (korreliert) sind. Dies ist ein Modell, das schnell lernt und binäre Klassifizierungsprobleme effektiv bewältigt.
03 Lineare Diskriminanzanalyse
Die traditionelle logistische Regression ist auf binäre Klassifizierungsprobleme beschränkt. Wenn Sie mehr als zwei Klassen haben, ist die lineare Diskriminanzanalyse (LDA) die bevorzugte lineare Klassifizierungstechnik.
Die Darstellung von LDA ist sehr einfach. Es besteht aus statistischen Eigenschaften Ihrer Daten, die auf Grundlage jeder Kategorie berechnet werden. Für eine einzelne Eingabevariable umfasst dies:
Der Durchschnittswert für jede Kategorie.
Varianz über alle Kategorien hinweg berechnet.
Lineare Diskriminanzanalyse
LDA wird durchgeführt, indem der Diskriminanzwert jeder Klasse berechnet und eine Vorhersage für die Klasse mit dem Maximalwert erstellt wird. Bei dieser Technik wird davon ausgegangen, dass die Daten eine Gaußsche Verteilung (Glockenkurve) aufweisen. Daher ist es am besten, Ausreißer zuerst manuell aus den Daten zu entfernen. Dies ist ein einfacher, aber leistungsstarker Ansatz für Probleme der Klassifizierungsvorhersagemodellierung.
04 Klassifizierungs- und Regressionsbaum
Der Entscheidungsbaum ist ein wichtiger Algorithmus für maschinelles Lernen.
Das Entscheidungsbaummodell kann durch einen Binärbaum dargestellt werden. Ja, es ist ein Binärbaum aus Algorithmen und Datenstrukturen, nichts Besonderes. Jeder Knoten stellt eine einzelne Eingabevariable (x) und die linken und rechten untergeordneten Elemente dieser Variablen dar (vorausgesetzt, die Variablen sind Zahlen). Die Blattknoten des Baums enthalten die Ausgabevariablen (y), die zur Erstellung von Vorhersagen verwendet werden. Die Vorhersage erfolgt durch Durchlaufen des Baums, Stoppen beim Erreichen eines bestimmten Blattknotens und Ausgeben des Klassenwerts des Blattknotens.
Entscheidungsbäume haben eine schnelle Lerngeschwindigkeit und eine schnelle Vorhersagegeschwindigkeit. Vorhersagen sind für viele Probleme oft genau und Sie müssen keine besondere Vorbereitung für die Daten durchführen. 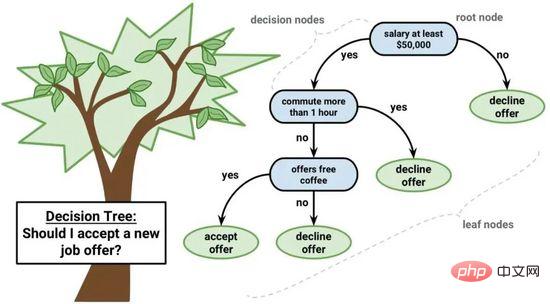
Bayes-Theorem
Der Grund, warum Naive Bayes als naiv bezeichnet wird, liegt darin, dass davon ausgegangen wird, dass jede Eingabevariable unabhängig von ist. Dies ist eine starke Annahme, die für reale Daten unrealistisch ist, aber die Technik ist bei komplexen Problemen im großen Maßstab immer noch sehr effektiv.
06 K Nächster Nachbar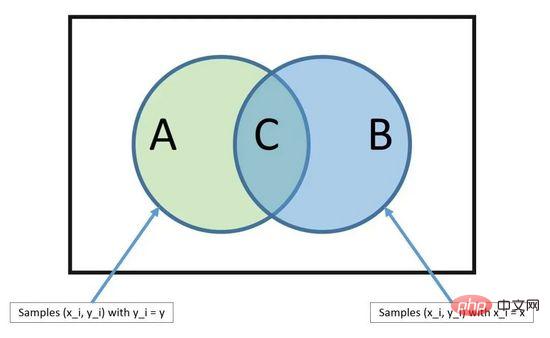
K-Nächste Nachbarn
KNN benötigt möglicherweise viel Speicher oder Platz, um alle Daten zu speichern, aber nur, wenn Die erforderliche Berechnung (oder das Lernen) wird nur durchgeführt, wenn Vorhersagen getroffen werden. Sie können Ihren Trainingssatz auch jederzeit aktualisieren und verwalten, um die Vorhersagegenauigkeit aufrechtzuerhalten.
Das Konzept der Distanz oder Nähe kann in einer hochdimensionalen Umgebung (große Anzahl von Eingabevariablen) zusammenbrechen, was sich negativ auf den Algorithmus auswirken kann. Solche Ereignisse werden als Dimensionsflüche bezeichnet. Dies bedeutet auch, dass Sie nur die Eingabevariablen verwenden sollten, die für die Vorhersage der Ausgabevariablen am relevantesten sind. 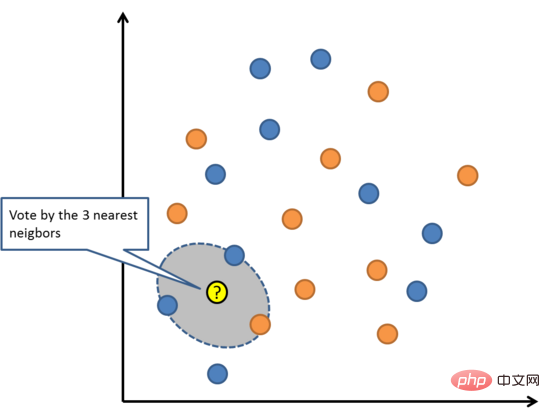
Lernen der Vektorquantisierung
LVQ wird durch eine Sammlung von Codebuchvektoren dargestellt. Beginnen Sie mit der zufälligen Auswahl von Vektoren und iterieren Sie dann mehrmals, um sie an den Trainingsdatensatz anzupassen. Nach dem Lernen kann der Codebuchvektor zur Vorhersage wie K-nächste Nachbarn verwendet werden. Finden Sie den ähnlichsten Nachbarn (beste Übereinstimmung), indem Sie den Abstand zwischen jedem Codebuchvektor und der neuen Dateninstanz berechnen, und geben Sie dann den Klassenwert der Einheit mit der besten Übereinstimmung oder den tatsächlichen Wert im Fall einer Regression als Vorhersage zurück. Die besten Ergebnisse werden erzielt, wenn Sie die Daten auf denselben Bereich beschränken (z. B. zwischen 0 und 1).
Wenn Sie feststellen, dass KNN gute Ergebnisse für Ihren Datensatz liefert, versuchen Sie, LVQ zu verwenden, um den Speicherbedarf für die Speicherung des gesamten Trainingsdatensatzes zu reduzieren. 
Support Vector Machine
Der Abstand zwischen der Hyperebene und dem nächstgelegenen Datenpunkt wird als Grenze bezeichnet, und die Hyperebene mit der größten Grenze ist die beste Wahl. Gleichzeitig beziehen sich nur diese nahe beieinander liegenden Datenpunkte auf die Definition der Hyperebene und die Konstruktion des Klassifikators. Diese Punkte werden als Stützvektoren bezeichnet und unterstützen oder definieren die Hyperebene. In der konkreten Praxis werden wir Optimierungsalgorithmen verwenden, um Koeffizientenwerte zu finden, die die Grenze maximieren.
SVM ist wahrscheinlich einer der leistungsfähigsten sofort einsatzbereiten Klassifikatoren und es lohnt sich, ihn in Ihrem Datensatz auszuprobieren.
09 Bagging und Random Forest
Random Forest ist einer der beliebtesten und leistungsstärksten Algorithmen für maschinelles Lernen. Es handelt sich um einen integrierten Algorithmus für maschinelles Lernen namens Bootstrap Aggregation oder Bagging.
bootstrap ist eine leistungsstarke statistische Methode, mit der eine Menge, beispielsweise der Mittelwert, aus einer Datenstichprobe geschätzt wird. Es nimmt eine große Anzahl von Beispieldaten, berechnet den Durchschnitt und mittelt dann alle Durchschnittswerte, um eine genauere Schätzung des wahren Durchschnitts zu erhalten.
Beim Absacken wird die gleiche Methode verwendet, am häufigsten wird jedoch der Entscheidungsbaum anstelle der Schätzung des gesamten statistischen Modells verwendet. Es führt eine Mehrfachabtastung der Trainingsdaten durch und erstellt dann ein Modell für jede Datenprobe. Wenn Sie eine Vorhersage für neue Daten treffen müssen, erstellt jedes Modell eine Vorhersage und mittelt die Vorhersagen, um eine bessere Schätzung des tatsächlichen Ausgabewerts zu erhalten.
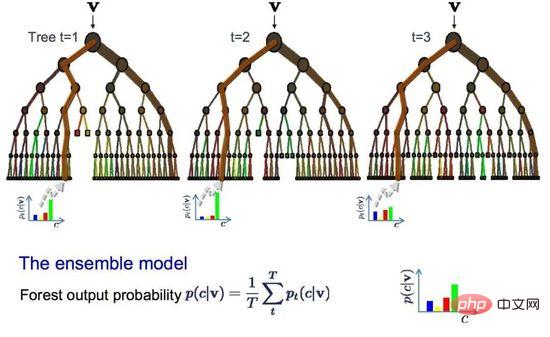
Random Forest
Random Forest ist eine Anpassung des Entscheidungsbaums im Vergleich zur Auswahl des besten Teilungspunkts, Random Forest Wälder erreichen eine suboptimale Segmentierung durch die Einführung von Zufälligkeit.
Daher unterscheiden sich die für jede Datenprobe erstellten Modelle stärker voneinander, sind aber in ihrem eigenen Sinne immer noch genau. Die Kombination von Vorhersageergebnissen ermöglicht eine bessere Schätzung des korrekten potenziellen Ausgabewerts.
Wenn Sie mit Algorithmen mit hoher Varianz (z. B. Entscheidungsbäumen) gute Ergebnisse erzielen, führt das Hinzufügen dieses Algorithmus zu noch besseren Ergebnissen.
10 Boosting und AdaBoost
Boosting ist eine Ensemble-Technik, die aus einigen schwachen Klassifikatoren einen starken Klassifikator erstellt. Es erstellt zunächst ein Modell aus den Trainingsdaten und erstellt dann ein zweites Modell, um zu versuchen, die Fehler des ersten Modells zu korrigieren. Fügen Sie kontinuierlich Modelle hinzu, bis der Trainingssatz eine perfekte Vorhersage liefert oder bis zur Obergrenze hinzugefügt wurde.
AdaBoost ist der erste wirklich erfolgreiche Boosting-Algorithmus, der für die binäre Klassifizierung entwickelt wurde, und es ist auch der beste Ausgangspunkt für das Verständnis von Boosting. Der bekannteste Algorithmus, der derzeit auf AdaBoost basiert, ist das stochastische Gradienten-Boosting. AdaBoost wird häufig bei kurzen Entscheidungsbäumen verwendet. Nachdem der erste Baum erstellt wurde, bestimmt die Leistung jeder Trainingsinstanz im Baum, wie viel Aufmerksamkeit der nächste Baum dieser Trainingsinstanz widmen muss. Schwierig vorhersehbare Trainingsdaten erhalten mehr Gewicht, während leicht vorhersehbare Instanzen weniger gewichtet werden. Modelle werden nacheinander erstellt und jede Modellaktualisierung wirkt sich auf den Lerneffekt des nächsten Baums in der Sequenz aus. Nachdem alle Bäume erstellt wurden, trifft der Algorithmus Vorhersagen zu neuen Daten und gewichtet die Leistung jedes Baums danach, wie genau er bei den Trainingsdaten war.
Da der Algorithmus großen Wert auf die Fehlerkorrektur legt, sind saubere Daten ohne Ausreißer sehr wichtig. 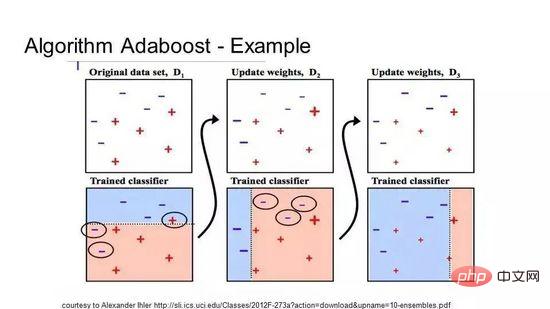
Größe, Qualität und Beschaffenheit der Daten;
Verfügbare Rechenzeit;
Dringlichkeit der Aufgabe;
#🎜 🎜#Was Was möchten Sie mit den Daten tun?- Selbst ein erfahrener Datenwissenschaftler kann nicht wissen, welcher Algorithmus am besten funktioniert, bevor er verschiedene Algorithmen ausprobiert. Obwohl es viele andere Algorithmen für maschinelles Lernen gibt, sind diese Algorithmen die beliebtesten. Wenn Sie neu im Bereich maschinelles Lernen sind, ist dies ein guter Ausgangspunkt.
Das obige ist der detaillierte Inhalt vonIllustration der zehn am häufigsten verwendeten Algorithmen für maschinelles Lernen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1387
1387
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
 Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
01Ausblicksübersicht Derzeit ist es schwierig, ein angemessenes Gleichgewicht zwischen Detektionseffizienz und Detektionsergebnissen zu erreichen. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird. 02 Hintergrund und Motivation Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Objekterkennung bei der Interpretation von Fernerkundungsbildern
 Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
In C++ umfasst die Implementierung von Algorithmen für maschinelles Lernen: Lineare Regression: Wird zur Vorhersage kontinuierlicher Variablen verwendet. Zu den Schritten gehören das Laden von Daten, das Berechnen von Gewichtungen und Verzerrungen, das Aktualisieren von Parametern und die Vorhersage. Logistische Regression: Wird zur Vorhersage diskreter Variablen verwendet. Der Prozess ähnelt der linearen Regression, verwendet jedoch die Sigmoidfunktion zur Vorhersage. Support Vector Machine: Ein leistungsstarker Klassifizierungs- und Regressionsalgorithmus, der die Berechnung von Support-Vektoren und die Vorhersage von Beschriftungen umfasst.
 Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
1. Hintergrund des Baus der 58-Portrait-Plattform Zunächst möchte ich Ihnen den Hintergrund des Baus der 58-Portrait-Plattform mitteilen. 1. Das traditionelle Denken der traditionellen Profiling-Plattform reicht nicht mehr aus. Der Aufbau einer Benutzer-Profiling-Plattform basiert auf Data-Warehouse-Modellierungsfunktionen, um Daten aus mehreren Geschäftsbereichen zu integrieren, um genaue Benutzerporträts zu erstellen Und schließlich muss es über Datenplattformfunktionen verfügen, um Benutzerprofildaten effizient zu speichern, abzufragen und zu teilen sowie Profildienste bereitzustellen. Der Hauptunterschied zwischen einer selbst erstellten Business-Profiling-Plattform und einer Middle-Office-Profiling-Plattform besteht darin, dass die selbst erstellte Profiling-Plattform einen einzelnen Geschäftsbereich bedient und bei Bedarf angepasst werden kann. Die Mid-Office-Plattform bedient mehrere Geschäftsbereiche und ist komplex Modellierung und bietet allgemeinere Funktionen. 2.58 Benutzerporträts vom Hintergrund der Porträtkonstruktion im Mittelbahnsteig 58
