

CLIP (Contrastive Language-Image Pre-training) ist eine maschinelle Lerntechnologie, die Bilder und Texte in natürlicher Sprache genau verstehen und klassifizieren kann, was einen tiefgreifenden Einfluss auf die Bild- und Sprachverarbeitung hat und als beliebtes Diffusionsmodell verwendet wird zugrunde liegender Mechanismus von DALL-E. In diesem Beitrag erfahren Sie, wie Sie CLIP zur Unterstützung der Videosuche anpassen.
Dieser Artikel geht nicht auf die technischen Details des CLIP-Modells ein, sondern zeigt eine weitere praktische Anwendung von CLIP (zusätzlich zum Diffusionsmodell).
Zuerst müssen wir wissen: CLIP verwendet einen Bilddecoder und einen Textencoder, um vorherzusagen, welche Bilder im Datensatz mit welchem Text übereinstimmen.

Durch die Verwendung des vorab trainierten CLIP-Modells von Hugging Face können wir ein einfaches, aber leistungsstarkes Modell erstellen Es handelt sich um eine Videosuchmaschine mit natürlichen Sprachfunktionen, für die kein Feature-Engineering erforderlich ist.
Wir müssen die folgende Software verwenden
Python≥= 3.8,ffmpeg,opencv
Es gibt viele Techniken zum Durchsuchen von Videos anhand von Text. Wir können uns eine Suchmaschine so vorstellen, dass sie aus zwei Teilen besteht: Indizierung und Suche.
Die Videoindizierung umfasst typischerweise eine Kombination aus manuellen und maschinellen Prozessen. Menschen verarbeiten Videos vor, indem sie relevante Schlüsselwörter in Titeln, Tags und Beschreibungen hinzufügen, während automatisierte Prozesse visuelle und akustische Funktionen wie Objekterkennung und Audiotranskription extrahieren. Benutzerinteraktionsmetriken und mehr, die aufzeichnen, welche Teile des Videos am relevantesten sind und wie lange sie relevant bleiben. Alle diese Schritte helfen dabei, einen durchsuchbaren Index Ihrer Videoinhalte zu erstellen.
Eine Übersicht über den Indexierungsprozess ist wie folgt
mport scenedetect as sd video_path = '' # path to video on machine video = sd.open_video(video_path) sm = sd.SceneManager() sm.add_detector(sd.ContentDetector(threshold=27.0)) sm.detect_scenes(video) scenes = sm.get_scene_list()
Sampling der Frames der Szene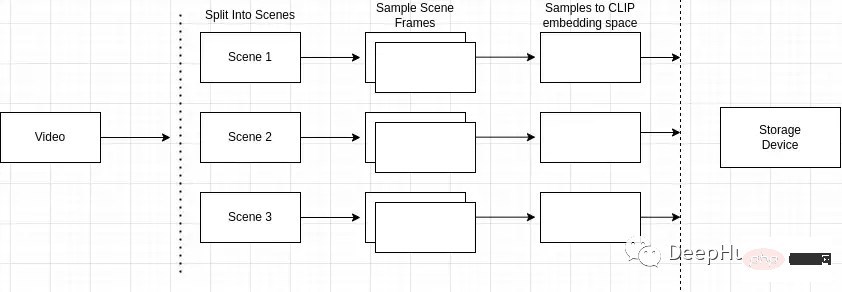
import cv2 cap = cv2.VideoCapture(video_path) every_n = 2 # number of samples per scene scenes_frame_samples = [] for scene_idx in range(len(scenes)): scene_length = abs(scenes[scene_idx][0].frame_num - scenes[scene_idx][1].frame_num) every_n = round(scene_length/no_of_samples) local_samples = [(every_n * n) + scenes[scene_idx][0].frame_num for n in range(3)] scenes_frame_samples.append(local_samples)
from transformers import CLIPProcessor
from PIL import Image
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def clip_embeddings(image):
inputs = clip_processor(images=image, return_tensors="pt", padding=True)
input_tokens = {
k: v for k, v in inputs.items()
}
return input_tokens['pixel_values']
# ...
scene_clip_embeddings = [] # to hold the scene embeddings in the next step
for scene_idx in range(len(scenes_frame_samples)):
scene_samples = scenes_frame_samples[scene_idx]
pixel_tensors = [] # holds all of the clip embeddings for each of the samples
for frame_sample in scene_samples:
cap.set(1, frame_sample)
ret, frame = cap.read()
if not ret:
print('failed to read', ret, frame_sample, scene_idx, frame)
break
pil_image = Image.fromarray(frame)
clip_pixel_values = clip_embeddings(pil_image)
pixel_tensors.append(clip_pixel_values) import torch
import uuid
def save_tensor(t):
path = f'/tmp/{uuid.uuid4()}'
torch.save(t, path)
return path
# ..
avg_tensor = torch.mean(torch.stack(pixel_tensors), dim=0)
scene_clip_embeddings.append(save_tensor(avg_tensor))Videoszenenindex: Welche Szenen gehören zu einem bestimmten Video
Szeneneinbettungsindex: Spezifisch speichern Szenen Daten
Video-Metadaten-Index: Speichern Sie die Metadaten des Videos.
Wir fügen zunächst alle berechneten Metadaten im Video und die eindeutige Kennung des Videos in den Metadatenindex ein. Dieser Schritt ist bereits fertig und sehr einfach. import leveldb
import uuid
def insert_video_metadata(videoID, data):
b = json.dumps(data)
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
video_id = str(uuid.uuid4())
insert_video_metadata(video_id, {
'VideoURI': video_path,
})import leveldb
import uuid
def insert_scene_embeddings(sceneID, data):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
level_instance.Put(sceneID.encode('utf-8'), data)
# ...
for f in scene_clip_embeddings:
scene_id = str(uuid.uuid4())
with open(f, mode='rb') as file:
content = file.read()
insert_scene_embeddings(scene_id, content) import leveldb
import uuid
def insert_video_scene(videoID, sceneIds):
b = ",".join(sceneIds)
level_instance = leveldb.LevelDB('./dbs/scene_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
scene_ids = []
for f in scene_clip_embeddings:
# .. as shown in previous step
scene_ids.append(scene_id)
scene_embedding_index.insert(scene_id, content)
scene_index.insert(video_id, scene_ids) records = []
level_instance = leveldb.LevelDB('./dbs/scene_index')
for k, v in level_instance.RangeIter():
record = (k.decode('utf-8'), str(v.decode('utf-8')).split(','))
records.append(record)import leveldb
def get_tensor_by_scene_id(id):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
b = level_instance.Get(bytes(id,'utf-8'))
return BytesIO(b)
for r in records:
tensors = [get_tensor_by_scene_id(id) for id in r[1]]import torch
from transformers import CLIPProcessor, CLIPModel
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
inputs = processor(text=text, return_tensors="pt", padding=True)
for tensor in tensors:
image_tensor = torch.load(tensor)
inputs['pixel_values'] = image_tensor
outputs = model(**inputs)logits_per_image = outputs.logits_per_image probs = logits_per_image.squeeze() prob_for_tensor = probs.item()
def clip_scenes_avg(tensors, text): avg_sum = 0.0 for tensor in tensors: # ... previous code snippets probs = probs.item() avg_sum += probs.item() return avg_sum / len(tensors)
最后在得到每个视频的概率并对概率进行排序后,返回请求的搜索结果数目。
import leveldb
import json
top_n = 1 # number of search results we want back
def video_metadata_by_id(id):
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
b = level_instance.Get(bytes(id,'utf-8'))
return json.loads(b.decode('utf-8'))
results = []
for r in records:
# .. collect scene tensors
# r[0]: video id
return (clip_scenes_avg, r[0])
sorted = list(results)
sorted.sort(key=lambda x: x[0], reverse=True)
results = []
for s in sorted[:top_n]:
data = video_metadata_by_id(s[1])
results.append({
'video_id': s[1],
'score': s[0],
'video_uri': data['VideoURI']
})就是这样!现在就可以输入一些视频并测试搜索结果。
通过CLIP可以轻松地创建一个频搜索引擎。使用预训练的CLIP模型和谷歌的LevelDB,我们可以对视频进行索引和处理,并使用自然语言输入进行搜索。通过这个搜索引擎使用户可以轻松地找到相关的视频,最主要的是我们并不需要大量的预处理或特征工程。
那么我们还能有什么改进呢?
可以在这里找到本文的代码:https://github.com/GuyARoss/CLIP-video-search/tree/article-01。
以及这个修改版本:https://github.com/GuyARoss/CLIP-video-search。
Das obige ist der detaillierte Inhalt vonErstellen einer Videosuchmaschine mit CLIP. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



