

Der Index ist vorab sortiert, sodass bei der Suche effiziente Algorithmen wie die binäre Suche angewendet werden können. Die Komplexität der allgemeinen sequentiellen Suche beträgt O(n), während die Komplexität der binären Suche O(log2n) beträgt; wenn n sehr groß ist, ist der Effizienzunterschied zwischen den beiden enorm.

Die Betriebsumgebung dieses Tutorials: Windows7-System, MySQL8-Version, Dell G3-Computer.
MySQL ist eine sehr beliebte Datenbank im Internet. Das Design der zugrunde liegenden Speicher- und Datenabruf-Engine ist sehr wichtig. Insbesondere die Speicherform von MySQL-Daten und das Design des Index bestimmen die Gesamtleistung von MySQL .
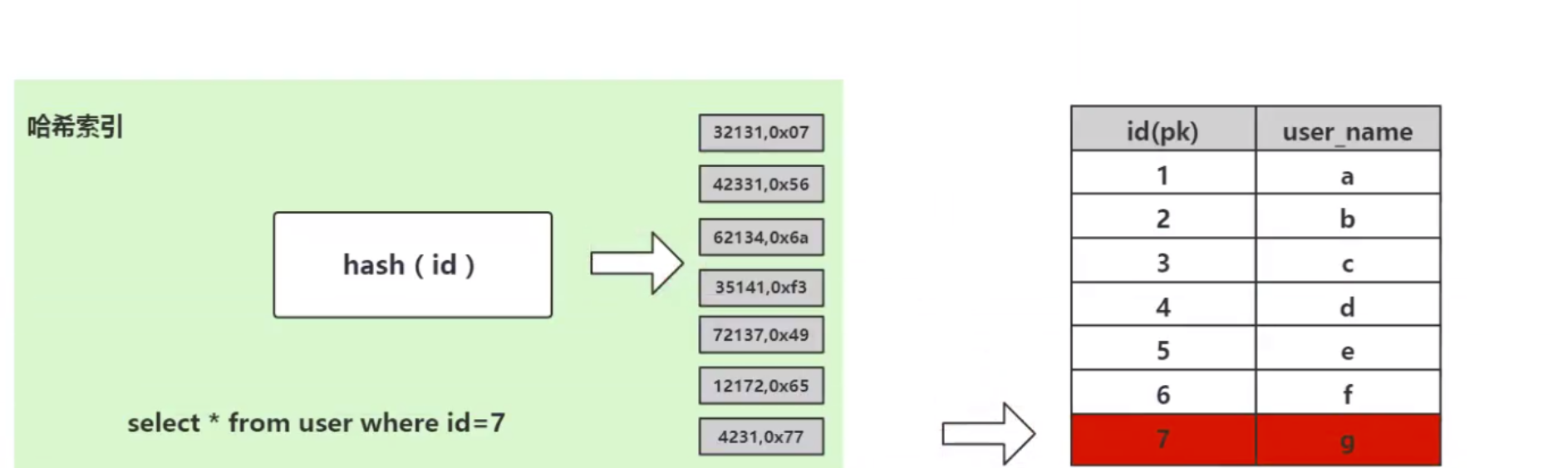
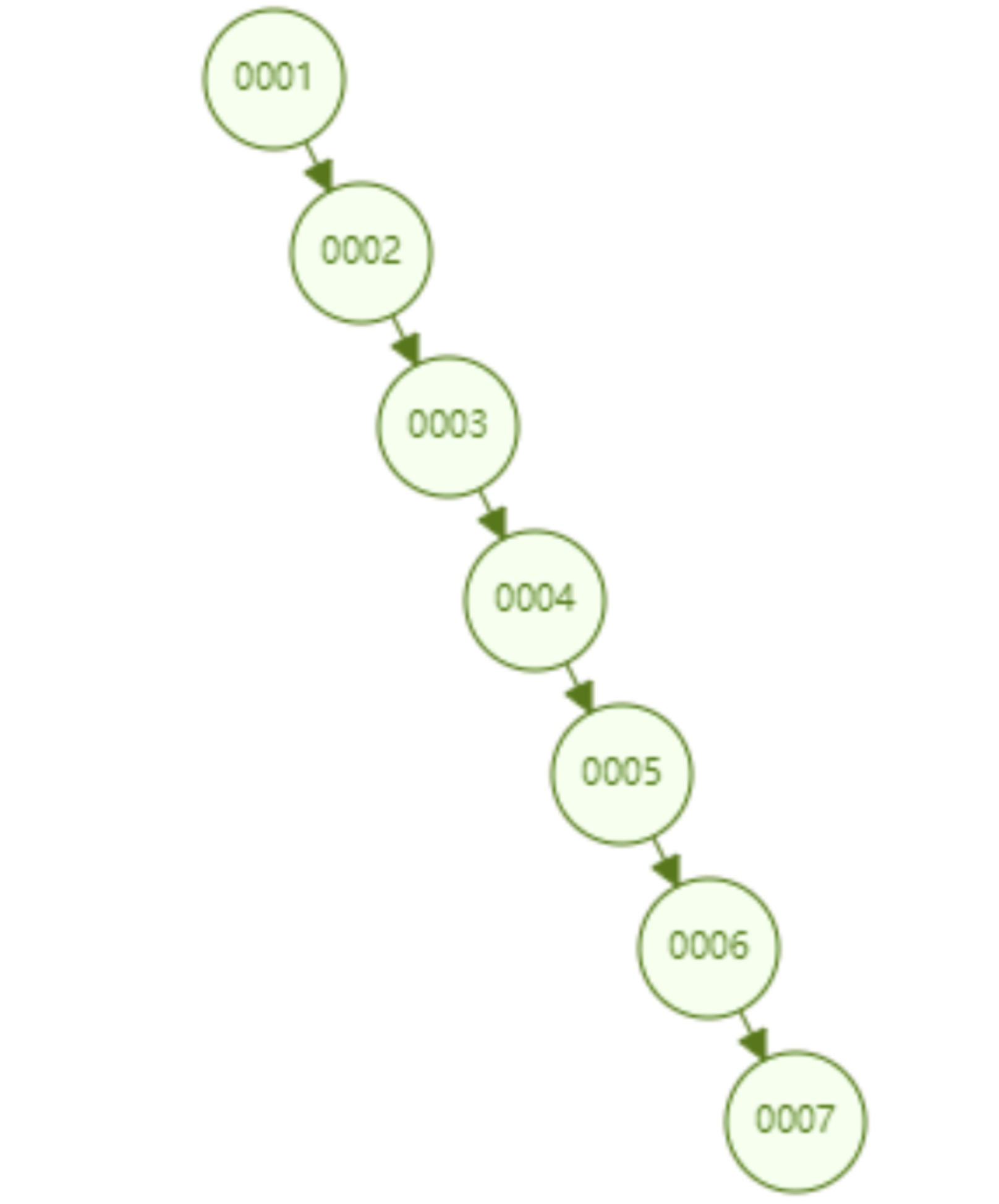
Wir wissen, dass die Funktion eines Index darin besteht, Daten schnell abzurufen, und das Wesentliche beim schnellen Abruf ist die Datenstruktur. Durch die Auswahl verschiedener Datenstrukturen können verschiedene Daten schnell abgerufen werden. In der Datenbank sind effiziente Suchalgorithmen sehr wichtig, da in der Datenbank große Datenmengen gespeichert werden und ein effizienter Index enorme Zeiteinsparungen ermöglichen kann. Wenn MySQL beispielsweise in der folgenden Datentabelle den Indexalgorithmus nicht implementiert, können Sie zum Suchen der Daten mit der ID = 7 nur eine gewaltsame sequentielle Durchquerung verwenden, um die Daten mit der ID = 7 zu finden Sie müssen 7 Mal vergleichen. Wenn diese Tabelle 10 Millionen Daten mit der ID = 1000 W speichert, wird sie 1000 W verglichen. Diese Geschwindigkeit ist nicht akzeptabel. 1. Auswahl der zugrunde liegenden Datenstruktur des MySQL-Index
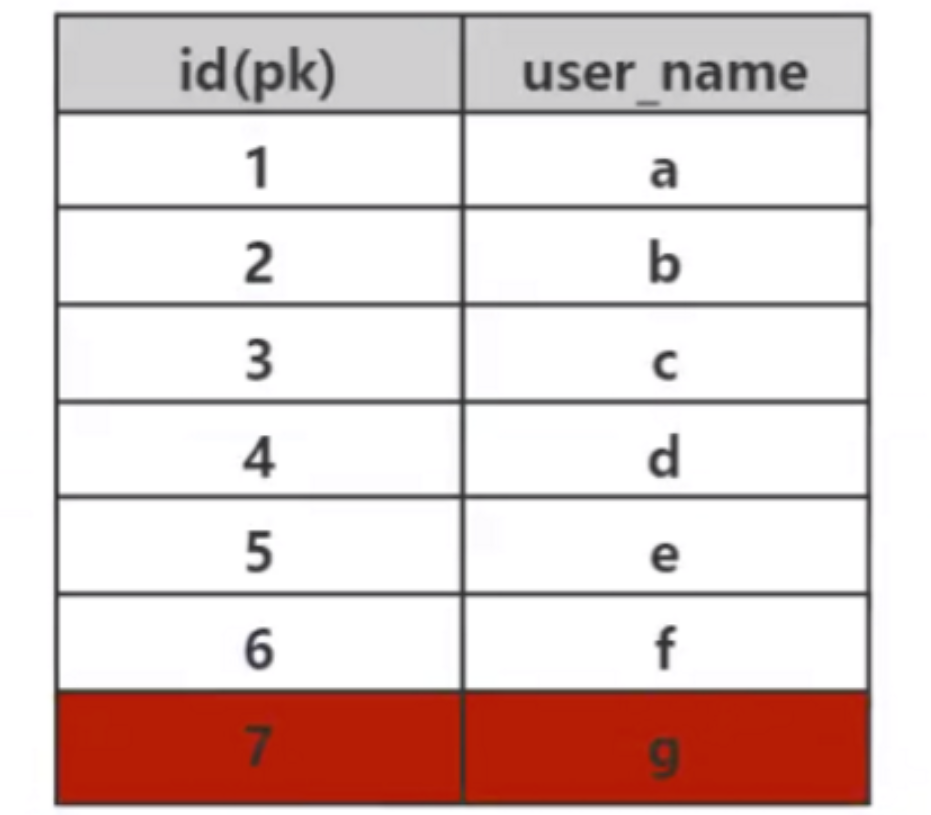
select * from user where id=7;
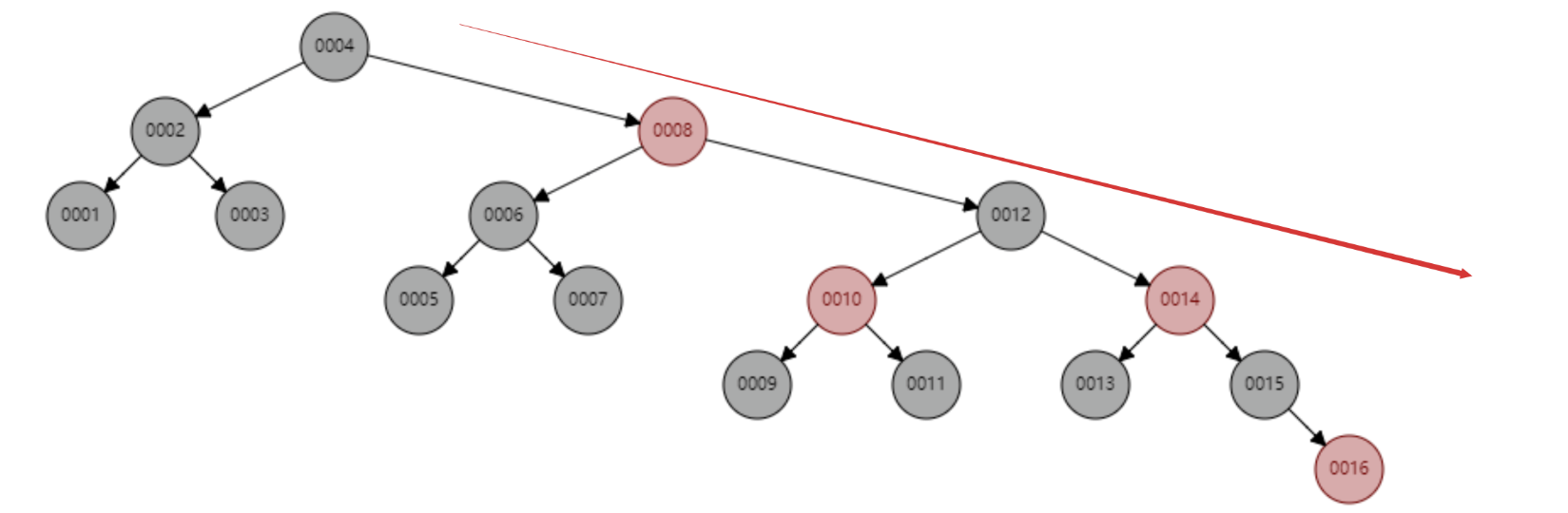
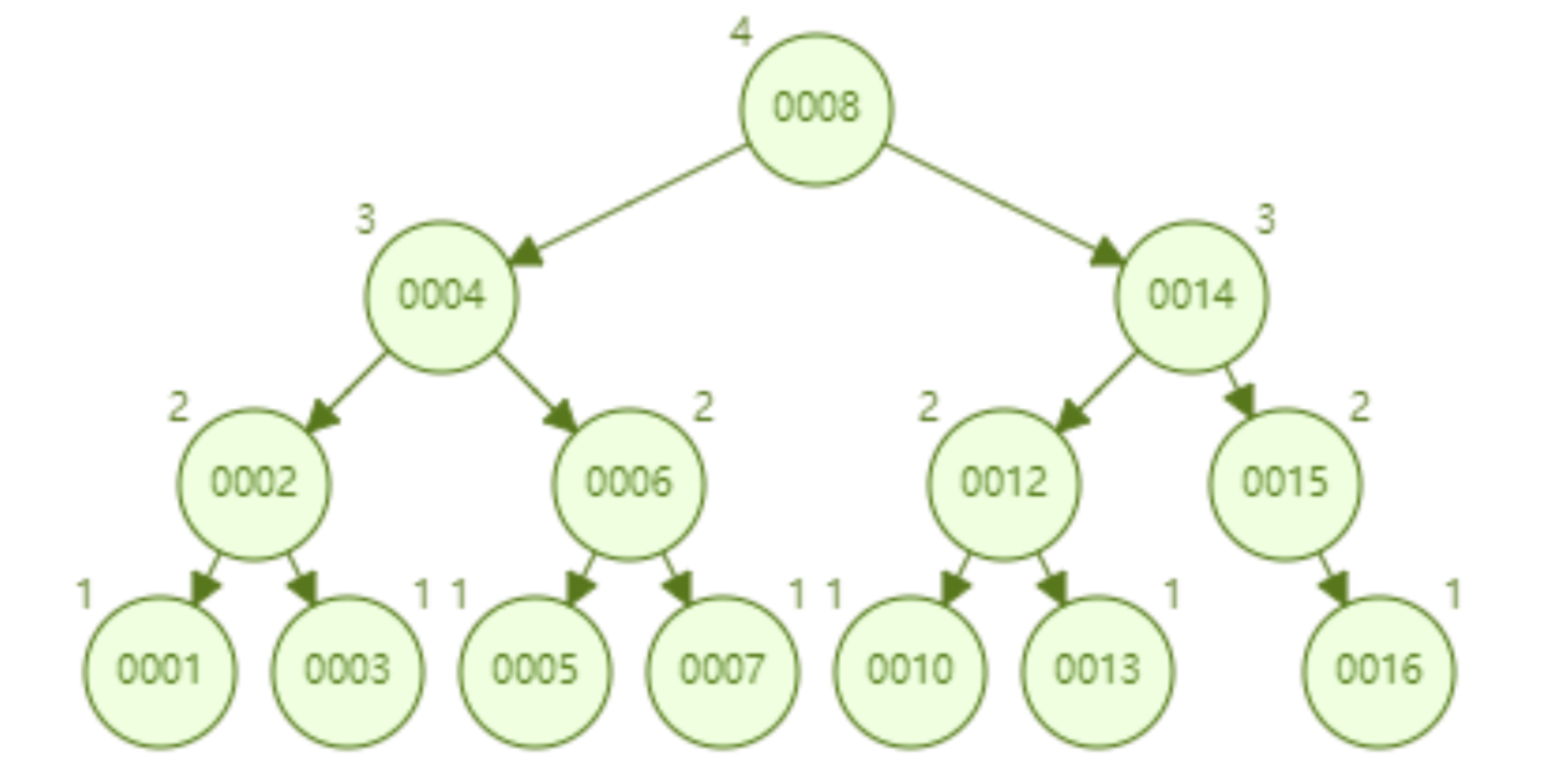
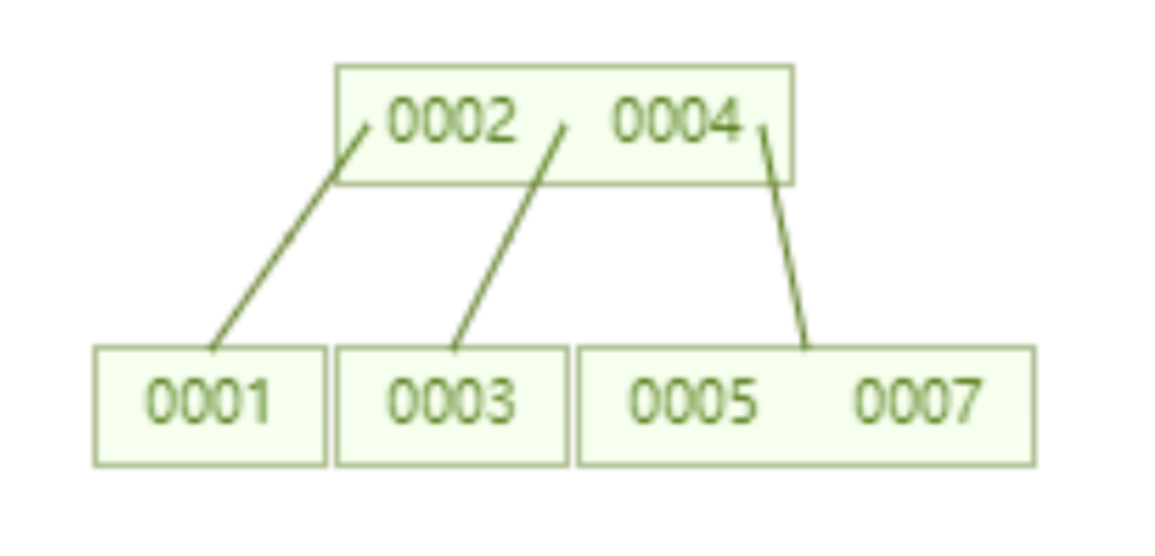
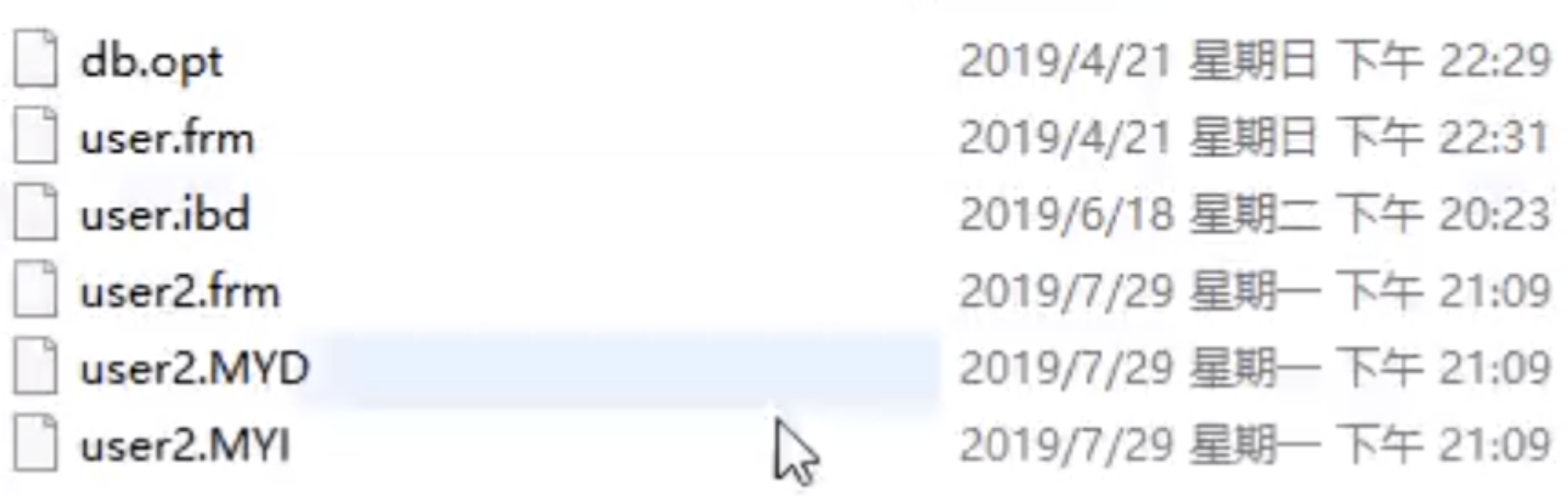
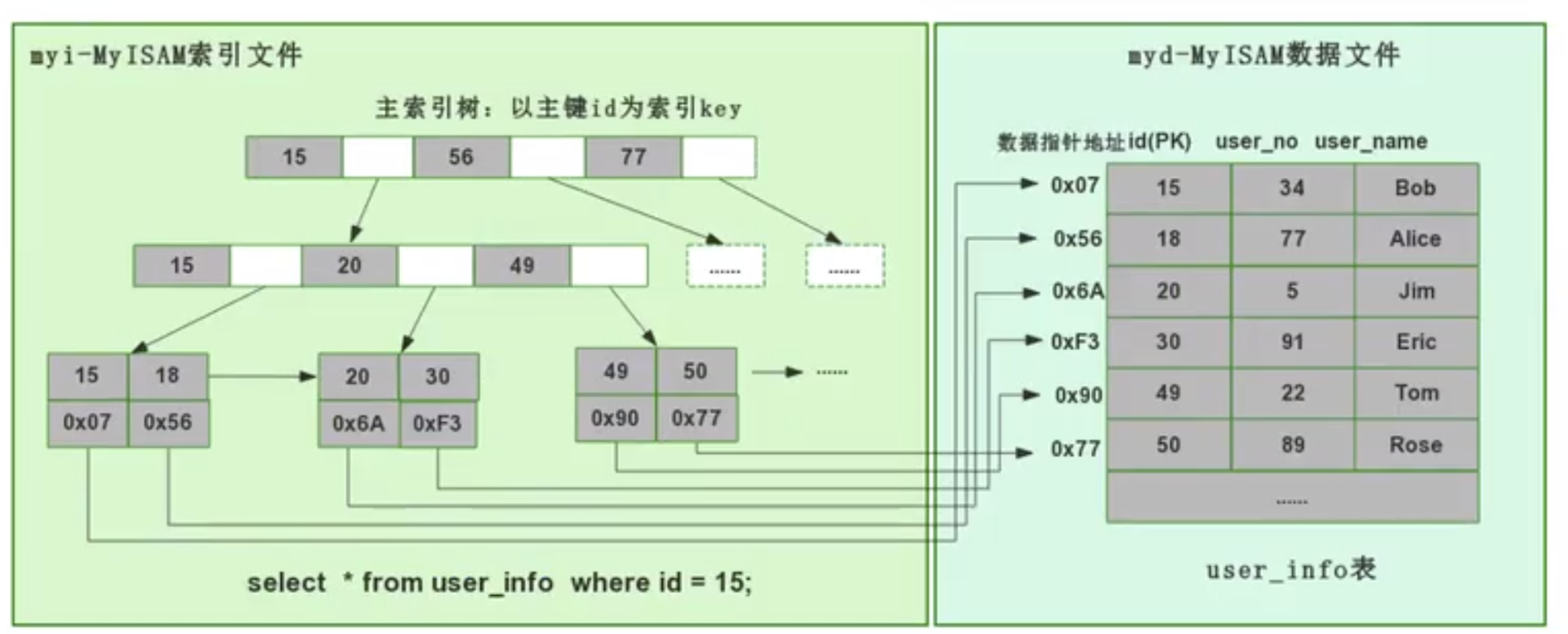
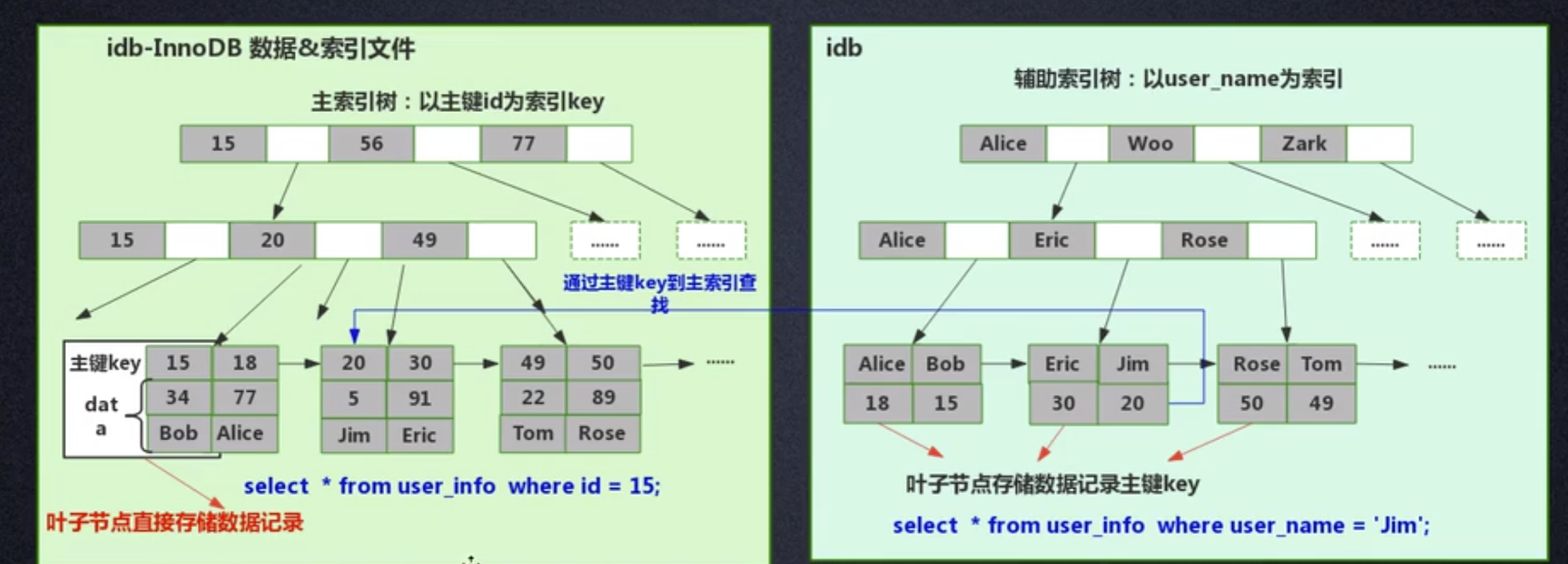
Aber der Hash-Algorithmus hat ein Datenkollisionsproblem, das heißt, die Hash-Funktion berechnet möglicherweise dasselbe Ergebnis für verschiedene Schlüssel. Beispielsweise kann Hash (7) dasselbe Ergebnis wie Hash (199) berechnen, was unterschiedlich ist Der Schlüssel wird auf dasselbe Ergebnis abgebildet, was ein Kollisionsproblem darstellt. Eine gängige Methode zur Lösung des Kollisionsproblems ist die Kettenadressmethode, bei der die kollidierenden Daten mithilfe einer verknüpften Liste verbunden werden. Nach der Berechnung des Hash-Werts müssen Sie auch prüfen, ob der Hash-Wert eine Kollision in der Datenverknüpfungsliste aufweist. Wenn ja, durchlaufen Sie den gesamten Weg bis zum Ende der verknüpften Liste, bis Sie die Daten finden, die dem tatsächlichen Schlüssel entsprechen. 从算法时间复杂度分析来看,哈希算法时间复杂度为 O(1),检索速度非常快。比如查找 id=7 的数据,哈希索引只需要计算一次就可以获取到对应的数据,检索速度非常快。但是 Mysql 并没有采取哈希作为其底层算法,这是为什么呢? 因为考虑到数据检索有一个常用手段就是范围查找,比如以下这个 SQL 语句: 针对以上这个语句,我们希望做的是找出 id>3 的数据,这是很典型的范围查找。如果使用哈希算法实现的索引,范围查找怎么做呢?一个简单的思路就是一次把所有数据找出来加载到内存,然后再在内存里筛选筛选目标范围内的数据。但是这个范围查找的方法也太笨重了,没有一点效率而言。 所以,使用哈希算法实现的索引虽然可以做到快速检索数据,但是没办法做数据高效范围查找,因此哈希索引是不适合作为 Mysql 的底层索引的数据结构。 二叉查找树(BST) 二叉查找树是一种支持数据快速查找的数据结构,如图下所示: 二叉查找树的时间复杂度是 O(lgn),比如针对上面这个二叉树结构,我们需要计算比较 3 次就可以检索到 id=7 的数据,相对于直接遍历查询省了一半的时间,从检索效率上看来是能做到高速检索的。此外二叉树的结构能不能解决哈希索引不能提供的范围查找功能呢? 答案是可以的。观察上面的图,二叉树的叶子节点都是按序排列的,从左到右依次升序排列,如果我们需要找 id>5 的数据,那我们取出节点为 6 的节点以及其右子树就可以了,范围查找也算是比较容易实现。 但是普通的二叉查找树有个致命缺点:极端情况下会退化为线性链表,二分查找也会退化为遍历查找,时间复杂退化为 O(N),检索性能急剧下降。比如以下这个情况,二叉树已经极度不平衡了,已经退化为链表了,检索速度大大降低。此时检索 id=7 的数据的所需要计算的次数已经变为 7 了。 In Datenbanken ist die automatische Inkrementierung von Daten eine sehr häufige Form. Beispielsweise ist der Primärschlüssel einer Tabelle standardmäßig eine automatische Inkrementierung Wenn der Binärbaum als Index verwendet wird, tritt zwangsläufig das lineare Suchproblem auf, das durch den oben eingeführten unausgeglichenen Zustand verursacht wird. Daher weist ein einfacher binärer Suchbaum das Problem einer verringerten Abrufleistung auf, die durch ein Ungleichgewicht verursacht wird, und kann nicht direkt zur Implementierung des zugrunde liegenden Index von MySQL verwendet werden. AVL-Bäume und Rot-Schwarz-Bäume Binäre Suchbäume weisen Ungleichgewichtsprobleme auf. Daher schlagen Wissenschaftler vor, dass der Binärbaum durch automatische Rotation und Anpassung der Baumknoten immer einen grundsätzlich ausgeglichenen Zustand aufrechterhalten kann Binärer Suchbaum kann gepflegt werden Suchbäume für optimale Suchleistung. Zu den Binärbäumen mit sich selbst anpassenden Gleichgewichtszuständen, die auf dieser Idee basieren, gehören AVL-Bäume und Rot-Schwarz-Bäume. Lassen Sie uns zunächst kurz den Rot-Schwarz-Baum vorstellen. Dies ist eine Baumstruktur, die die Baumform automatisch anpasst. Wenn sich der Binärbaum beispielsweise in einem unausgeglichenen Zustand befindet, dreht sich der Rot-Schwarz-Baum automatisch nach links Die rechten Knoten und die Knoten ändern ihre Farbe, um die Form des Baums anzupassen und einen grundlegenden Gleichgewichtszustand aufrechtzuerhalten (Zeitkomplexität ist O (logn)), wodurch sichergestellt wird, dass die Sucheffizienz nicht wesentlich verringert wird. Wenn beispielsweise Datenknoten in aufsteigender Reihenfolge von 1 bis 7 eingefügt werden, degeneriert ein gewöhnlicher binärer Suchbaum zu einer verknüpften Liste, aber ein rot-schwarzer Baum passt die Form des Baums kontinuierlich an, um ein grundlegendes Gleichgewicht aufrechtzuerhalten, wie gezeigt in der Abbildung unten. Die Anzahl der zu vergleichenden Knoten bei der Suche nach id = 7 im folgenden rot-schwarzen Baum beträgt 4, wodurch die gute Sucheffizienz des Binärbaums erhalten bleibt. Der Rot-Schwarz-Baum hat eine gute durchschnittliche Sucheffizienz und es gibt keine extreme O(n)-Situation. Kann der Rot-Schwarz-Baum also als zugrunde liegende Indeximplementierung von MySQL verwendet werden? Tatsächlich haben rot-schwarze Bäume auch einige Probleme. Schauen Sie sich das folgende Beispiel an. Der rot-schwarze Baum fügt nacheinander 1 bis 16 Knoten ein, und die Anzahl der Knoten, die verglichen werden müssen, um die ID = 16 zu finden, beträgt das Sechsfache. Beobachten Sie die Form dieses Baums. Stimmt es, dass die Form des Baums beim sequentiellen Einfügen von Daten immer einen „rechtsgerichteten“ Trend aufweist? Grundsätzlich löst der Rot-Schwarz-Baum den binären Suchbaum nicht vollständig auf. Obwohl dieser „rechtsgerichtete“ Trend weitaus weniger übertrieben ist als der binäre Suchbaum, der zu einer linearen verknüpften Liste degeneriert, ist die grundlegende automatische Inkrementierungsoperation des Primärschlüssels im In der Datenbank beträgt der Primärschlüssel im Allgemeinen Millionen und Dutzende Millionen. Wenn ein solches Problem im Rot-Schwarz-Baum auftritt, wird auch die Suchleistung stark beeinträchtigt. Unsere Datenbank kann dieses bedeutungslose Warten nicht tolerieren. Betrachten Sie nun einen weiteren strengeren selbstausgleichenden Binärbaum, den AVL-Baum. Da der AVL-Baum ein absolut ausgeglichener Binärbaum ist, verbraucht er mehr Leistung bei der Anpassung der Form des Binärbaums. Der AVL-Baum fügt nacheinander 1 bis 7 Knoten ein, und die Häufigkeit, mit der Knoten verglichen werden müssen, um die ID = 7 zu finden, beträgt 3. Der AVL-Baum fügt nacheinander 1 bis 16 Knoten ein, und die Anzahl der Knoten, die verglichen werden müssen, um die ID = 16 zu finden, beträgt 4. In Bezug auf die Sucheffizienz ist die Suchgeschwindigkeit des AVL-Baums höher als die des Rot-Schwarz-Baums (der AVL-Baum umfasst 4 Vergleiche, der Rot-Schwarz-Baum umfasst 6 Vergleiche). Der Form des Baumes nach zu urteilen, haben AVL-Bäume nicht das Problem der „richtigen Neigung“ rot-schwarzer Bäume. Mit anderen Worten: Eine große Anzahl aufeinanderfolgender Einfügungen führt nicht zu einer Verringerung der Abfrageleistung, wodurch das Problem der Rot-Schwarz-Bäume grundsätzlich gelöst wird. Um die Vorteile des AVL-Baums zusammenzufassen: Es scheint, dass der AVL-Baum als Datenstruktur für die Datensuche wirklich gut ist, aber der AVL-Baum ist nicht für die Indexdatenstruktur der MySQL-Datenbank geeignet, denn bedenken Sie dieses Problem: Der Engpass bei der Datenbankabfrage Daten sind Festplatten-E/A. Wenn wir einen AVL-Baum verwenden und jeder Baumknoten nur ein Datenelement speichert, können wir die Daten nur mit einer Festplatten-E/A in den Speicher laden Mit der ID = 7 müssen wir dreimal Festplatten-IO durchführen. Wie zeitaufwändig das ist. Daher müssen wir beim Entwerfen von Datenbankindizes zunächst überlegen, wie wir die Anzahl der Festplatten-E/As so weit wie möglich reduzieren können. Ein Merkmal von Festplatten-E/A ist, dass die Zeit, die zum Lesen von 1-B-Daten und 1-KB-Daten von der Festplatte benötigt wird, grundsätzlich gleich ist. Basierend auf dieser Idee können wir so viele Daten wie möglich auf einem Baumknoten speichern. Ein Festplatten-E/A wird geladen mehr Daten in den Speicher. Dies ist das Designprinzip von B-Tree und B+-Tree. B-Baum Der B-Baum unten ist auf die Speicherung von bis zu zwei Schlüsseln pro Knoten beschränkt. Wenn ein Knoten mehr als zwei Schlüssel hat, wird er automatisch geteilt. Der folgende B-Baum speichert beispielsweise 7 Daten. Sie müssen nur zwei Knoten abfragen, um den spezifischen Speicherort der Daten mit der ID = 7 zu ermitteln. Das heißt, Sie können die angegebenen Daten mit zwei Festplatten-E / A abfragen der AVL-Baum. Das Folgende ist ein B-Baum, der 16 Daten speichert. Ebenso erfordert das Abfragen der Daten mit der ID = 16 das Abfragen und Vergleichen von 4 Knoten Festplatte geht. Es sieht so aus, als ob die Abfrageleistung mit der des AVL-Baums identisch ist. Aber wenn man bedenkt, dass die Zeit, die Festplatten-IO zum Lesen eines Datenelements benötigt, im Grunde die gleiche ist wie das Lesen von 100 Datenelementen, dann kann unsere Optimierungsidee geändert werden in: Lesen Sie so viele Daten wie möglich wie möglich in einem Festplattenspeicher. Dies spiegelt sich direkt in der Struktur des Baums wider, dh der Schlüssel, den jeder Knoten speichern kann, kann entsprechend erhöht werden. Wenn wir das Schlüsselanzahllimit für einen einzelnen Knoten auf 6 setzen, benötigt ein B-Baum, der 7 Datenelemente speichert, 2 Festplatten-IOs, um die Daten mit der ID=7 abzufragen. Ein B-Baum, der 16 Datenelemente speichert, Abfrage-ID= 7 Der für diese Daten erforderliche Festplatten-IO beträgt das Zweifache. Im Vergleich zum AVL-Baum wird die Anzahl der Festplatten-IOs auf die Hälfte reduziert. Also in Bezug auf die Auswahl der Datenbankindexdaten Struktur, B-Baum ist eine sehr gute Wahl. Zusammenfassend bietet B-Tree bei der Verwendung als Datenbankindex die folgenden Vorteile: Baum ist gleich O (h*logn), wobei h die Höhe des Baums und n die Anzahl der Schlüsselwörter in jedem Knoten ist; Zuerst Ein Knoten im B-Baum speichert Daten, während der B+-Baum einen Index (Adresse) speichert, also ein Knoten im B-Baum kann nicht viele Daten speichern, aber ein Knoten des B+-Baums kann viele Indizes speichern, und die Blattknoten des B+-Baums speichern alle Daten. Zweitens werden die Blattknoten des B+-Baums in der Datenphase mit einer verknüpften Liste in Reihe verbunden, um die Bereichssuche zu erleichtern. Nachdem diese beiden Anweisungen ausgeführt wurden, werden die folgenden Dateien im System angezeigt, was darauf hinweist, dass die Daten und Indizes der beiden Engines unterschiedlich organisiert sind. Die von Innodb nach dem Erstellen der Tabelle generierten Dateien sind: Myisam wird danach generiert Erstellen der Tabelle Die Dateien umfassen Beurteilung Aus der generierten Datei werden die zugrunde liegenden Daten und Indizes der beiden Engines auf unterschiedliche Weise organisiert. Die MyISAM-Engine verfügt über eine Datei, die als nicht gruppierte Indexmethode bezeichnet wird Daten und Index in derselben Datei. Dies wird als Clustered-Index-Modus bezeichnet. Im Folgenden wird analysiert, wie diese beiden Engines die B+-Baumdatenstruktur nutzen, um die Engine-Implementierung aus der Perspektive der zugrunde liegenden Implementierung zu organisieren. Die zugrunde liegende Implementierung der MyISAM-Engine (nicht gruppierte Indexmethode) MyISAM verwendet eine nicht gruppierte Indexmethode, das heißt, die Daten und der Index liegen in zwei verschiedenen Dateien. Wenn MyISAM eine Tabelle erstellt, verwendet es den Primärschlüssel als SCHLÜSSEL, um einen Primärindex-B+-Baum zu erstellen. Die Blattknoten des Baums speichern die physische Adresse der entsprechenden Daten. Nachdem wir diese physische Adresse erhalten haben, können wir den spezifischen Datensatz direkt in der MyISAM-Datendatei finden. Wenn wir einem Feld einen Index hinzufügen, generieren wir auch einen Indexbaum für das entsprechende Feld. Die Blattknoten des Indexbaums für das Feld zeichnen auch die physische Adresse der entsprechenden Daten auf. und dann nehmen Sie diese physische Adresse, um den spezifischen Datensatz in der Datendatei zu finden. Die zugrunde liegende Implementierung der Innodb-Engine (Clustered-Index-Methode) InnoDB ist eine Clustered-Index-Methode, sodass Daten und Index in derselben Datei gespeichert werden. Zunächst erstellt InnoDB einen Index-B+-Baum basierend auf der Primärschlüssel-ID als SCHLÜSSEL, wie in der Abbildung unten links gezeigt. Die Blattknoten des B+-Baums speichern beispielsweise die Daten, die der Primärschlüssel-ID entsprechen select * from user_info where id=15, InnoDB Es fragt den B+-Baum des Primärschlüssel-ID-Index ab und findet den entsprechenden user_name='Bob'. In diesem Fall erstellt InnoDB beim Erstellen einer Tabelle automatisch den Primärschlüssel-ID-Indexbaum. Aus diesem Grund muss beim Erstellen einer Tabelle der Primärschlüssel angegeben werden. Wie erstellt InnoDB einen Indexbaum, wenn wir einem Feld in der Tabelle einen Index hinzufügen? Wenn wir beispielsweise einen Index zum Feld „user_name“ hinzufügen möchten, erstellt InnoDB einen B+-Baum für den Index „user_name“. Der SCHLÜSSEL von „user_name“ wird im Knoten gespeichert, und die in den Blattknoten gespeicherten Daten sind der Primärschlüssel „KEY“. Beachten Sie, dass die Blätter den Primärschlüssel KEY speichern! Nach Erhalt des Primärschlüssels KEY geht InnoDB zum Primärschlüssel-Indexbaum, um die entsprechenden Daten basierend auf dem gerade im Benutzernamen-Indexbaum gefundenen Primärschlüssel KEY zu finden. Die Frage ist, warum InnoDB nur bestimmte Daten in den Blattknoten des Primärschlüssel-Indexbaums speichert, andere Indexbäume jedoch keine spezifischen Daten speichern und es nicht erforderlich ist, zuerst den Primärschlüssel zu finden , und dann im Primärschlüssel-Indexbaum Wie wäre es mit dem Finden der entsprechenden Daten? Das ist eigentlich ganz einfach, denn InnoDB muss Speicherplatz sparen. Eine Tabelle kann viele Indizes enthalten. Wenn der Indexbaum jedes Felds bestimmte Daten speichert, wird die Indexdatendatei dieser Tabelle sehr groß (Daten extrem redundant). Unter dem Gesichtspunkt der Speicherplatzersparnis besteht keine Notwendigkeit, in jedem Feldindexbaum spezifische Daten zu speichern. Durch diesen scheinbar „unnötigen“ Schritt wird viel Speicherplatz auf Kosten einer geringeren Abfrageleistung eingespart. Beim Vergleich der Funktionen von InnoDB und MyISAM wurde erwähnt, dass MyISAM eine bessere Abfrageleistung aufweist. Der Grund dafür ist auch aus dem Design der Indexdateidatendatei oben ersichtlich: MyISAM kann den Datensatz direkt lokalisieren, nachdem er den physischen Datensatz direkt gefunden hat Adresse, aber nachdem InnoDB die Blattknoten abgefragt hat, muss es den Primärschlüsselindexbaum erneut abfragen, um die spezifischen Daten zu finden. Dies bedeutet, dass MyISAM die Daten in einem Schritt finden kann, InnoDB jedoch zwei Schritte erfordert. Natürlich ist die Abfrageleistung von MyISAM höher. In diesem Artikel wird zunächst erläutert, welche Datenstruktur besser als Implementierung des zugrunde liegenden Index von MySQL geeignet ist, und anschließend wird die zugrunde liegende Implementierung der beiden klassischen Daten-Engines von MySQL, MyISAM und InnoDB, vorgestellt. Lassen Sie uns abschließend zusammenfassen, wann Sie die Felder in Ihrer Tabelle indizieren müssen: 【Verwandte Empfehlungen: MySQL-Video-Tutorial】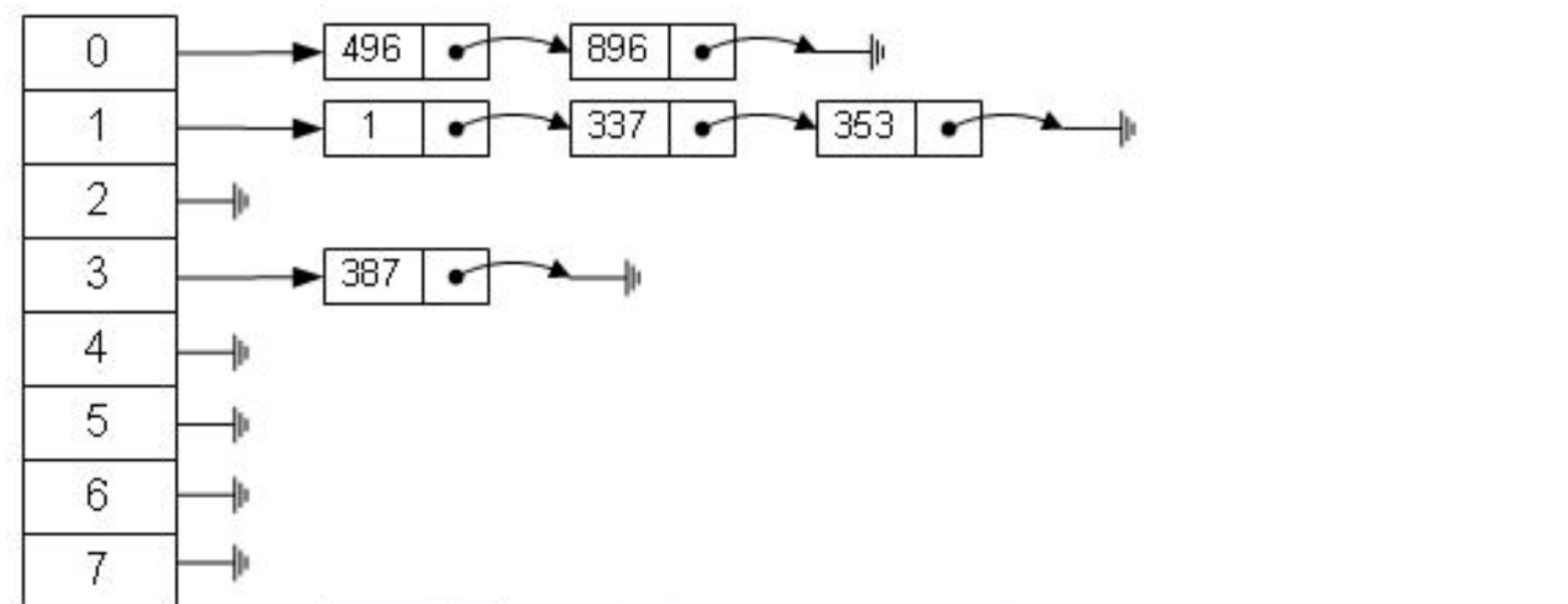
select * from user where id \>3;
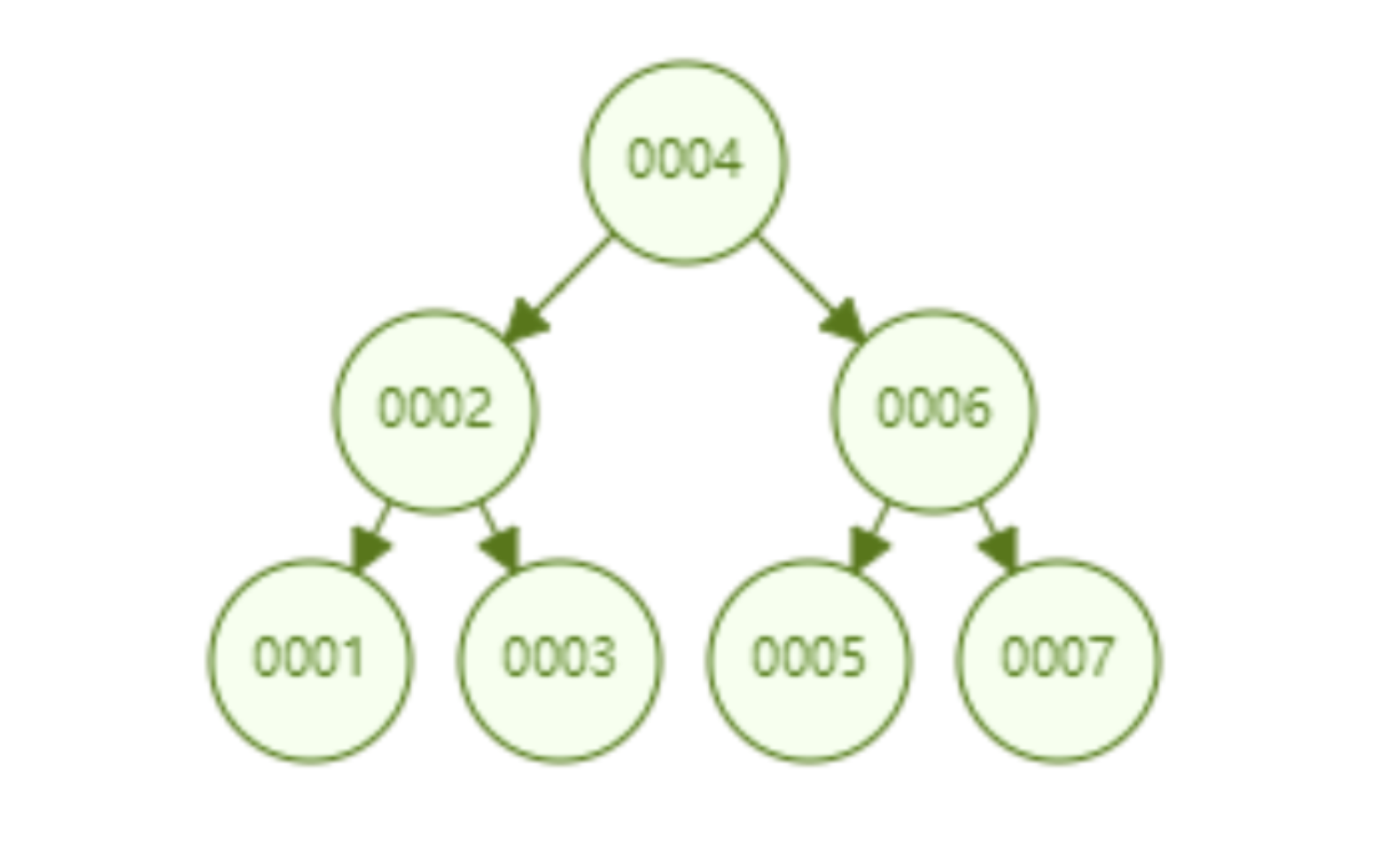
Der rot-schwarze Baum fügt nacheinander 1 bis 7 Knoten ein, und die Anzahl der Knoten, die bei der Suche nach ID = 7 berechnet werden müssen, beträgt 4. 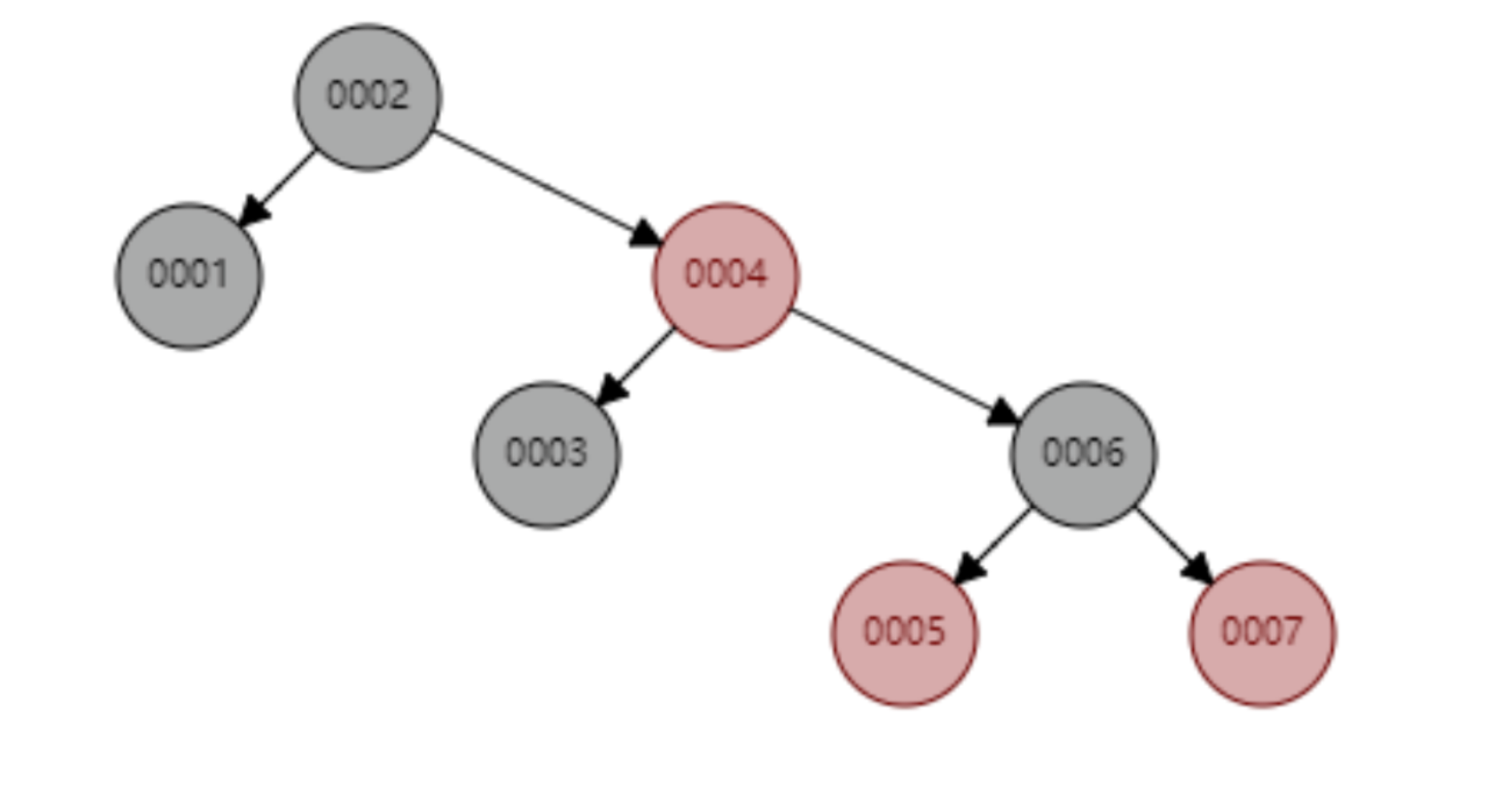
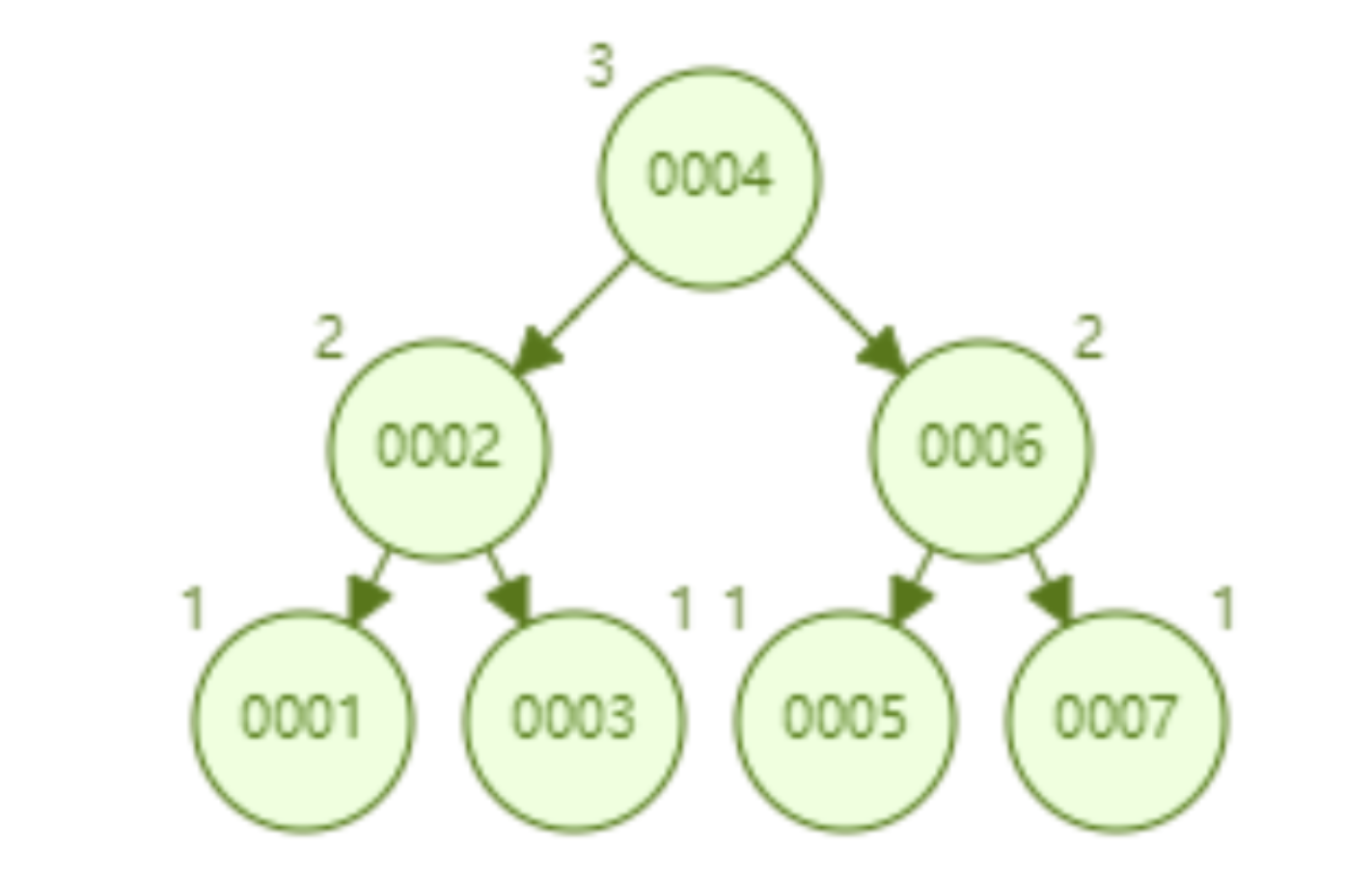
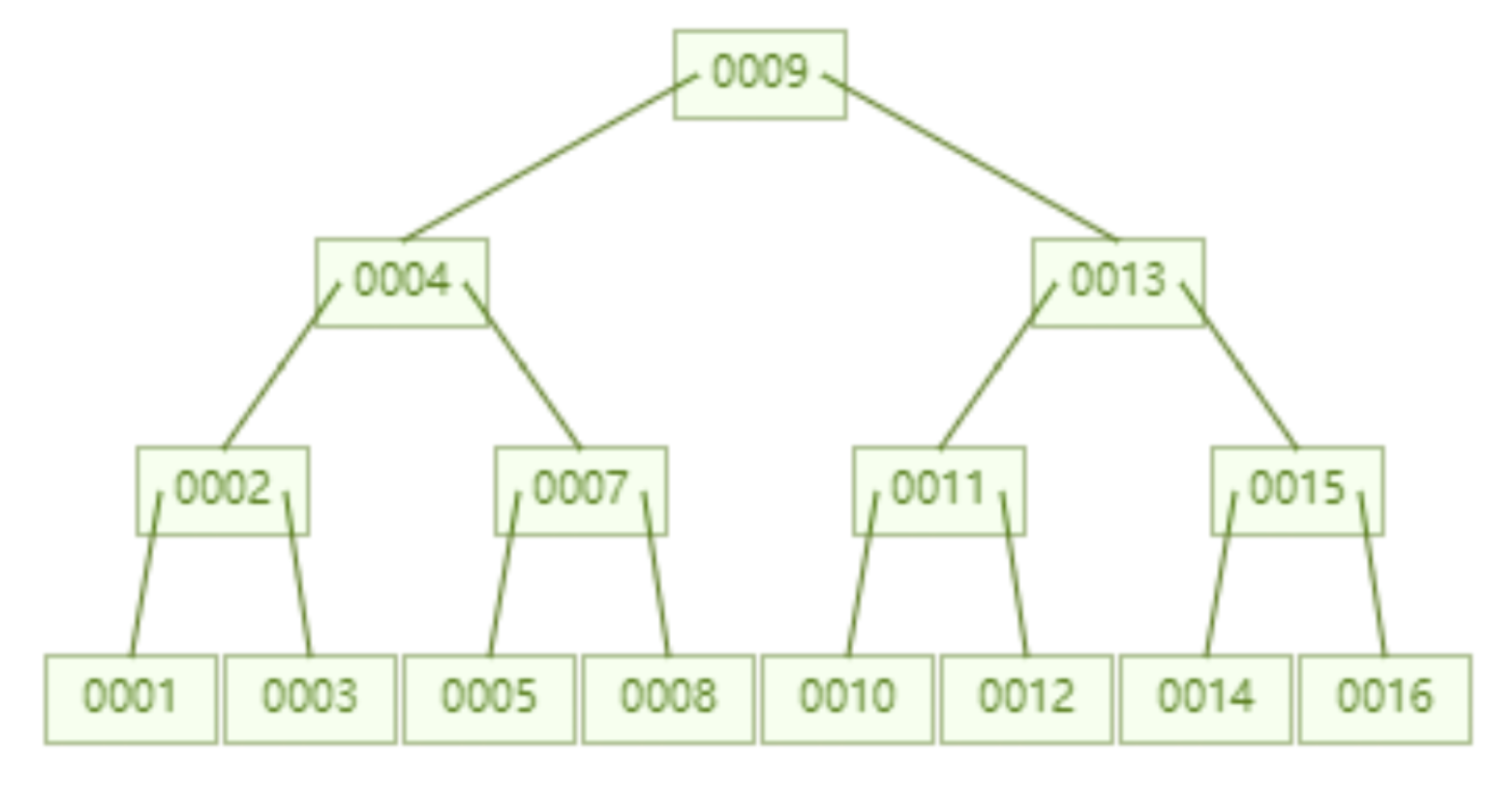
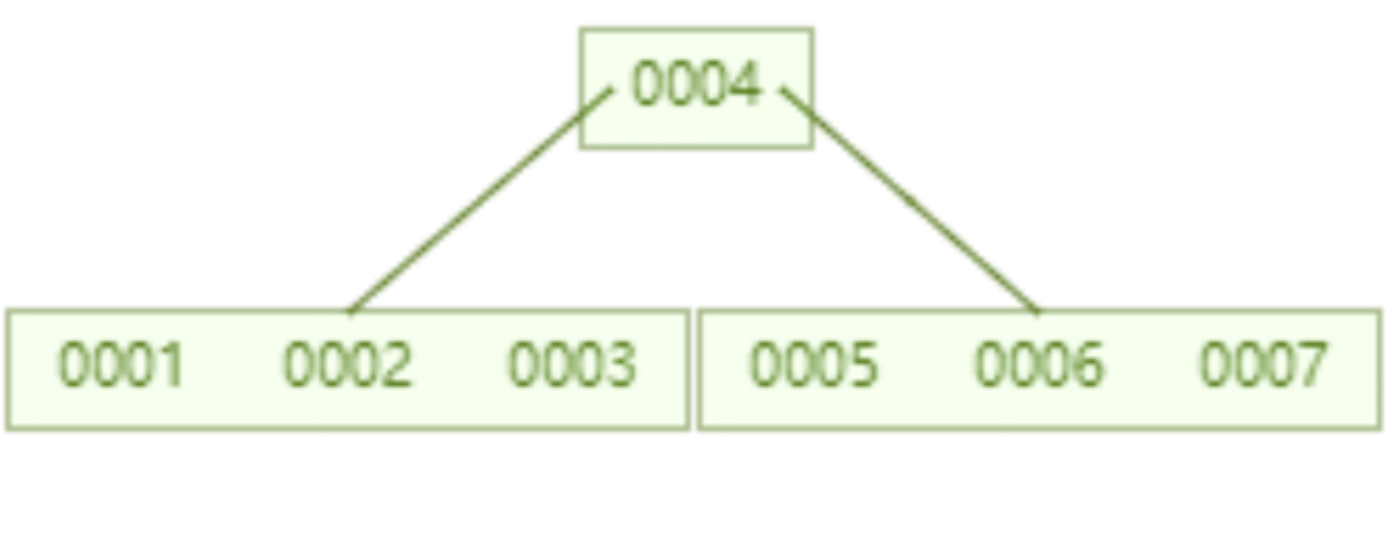

kann die Bereichssuche unterstützen.
B+Baum
 2. Implementierung der Innodb-Engine und der Myisam-Engine
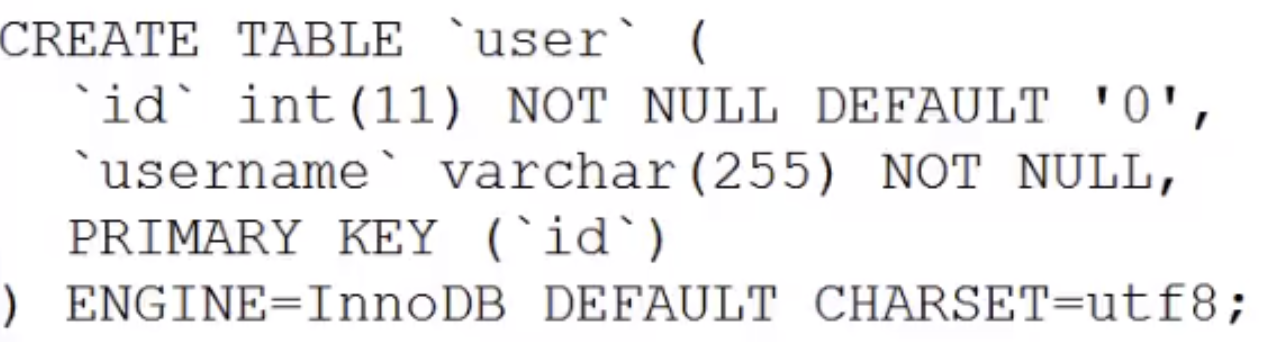
2. Implementierung der Innodb-Engine und der Myisam-Engine MyISAM Obwohl die Datensuchleistung ausgezeichnet ist, unterstützt es keine Transaktionsverarbeitung. Das größte Merkmal von Innodb ist, dass es ACID-kompatible Transaktionsfunktionen und Sperren auf Zeilenebene unterstützt. Sie können die Engine angeben, wenn Mysql eine Tabelle erstellt. Im folgenden Beispiel werden beispielsweise Myisam und Innodb als Daten-Engines für die Benutzertabelle bzw. Benutzer2-Tabelle angegeben.

Das obige ist der detaillierte Inhalt vonWarum ist der MySQL-Index schnell?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen













![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



