

Extrahieren Sie mit Pandas und Python aussagekräftige Funktionen aus Zeitreihendaten, einschließlich gleitender Durchschnitte, Autokorrelation und Fourier-Transformationen.
Die Zeitreihenanalyse ist ein leistungsstarkes Werkzeug zum Verständnis und zur Vorhersage von Trends in verschiedenen Branchen (wie Finanzen, Wirtschaft, Gesundheitswesen usw.). Die Merkmalsextraktion ist ein wichtiger Schritt in diesem Prozess, bei dem Rohdaten in aussagekräftige Merkmale umgewandelt werden, die zum Trainieren von Modellen für Vorhersagen und Analysen verwendet werden können. In diesem Artikel werden wir Techniken zur Extraktion von Zeitreihenmerkmalen mit Python und Pandas untersuchen.
Bevor wir uns mit der Merkmalsextraktion befassen, werfen wir einen kurzen Blick auf die Zeitreihendaten. Zeitreihendaten sind eine Folge von Datenpunkten, die in zeitlicher Reihenfolge indiziert sind. Beispiele für Zeitreihendaten sind Aktienkurse, Temperaturmessungen und Verkehrsdaten. Zeitreihendaten können univariat oder multivariat sein. Univariate Zeitreihendaten haben nur eine Variable, während multivariate Zeitreihendaten mehrere Variablen haben.

Es gibt verschiedene Techniken zur Merkmalsextraktion, die für die Zeitreihenanalyse verwendet werden können. In diesem Artikel werden wir die folgenden Techniken behandeln: #Autokorrelation
import pandas as pd
# create a time series with minute frequency
ts = pd.Series([1, 2, 3, 4, 5], index=pd.date_range('2022-01-01', periods=5, freq='T'))
# downsample to daily frequency
daily_ts = ts.resample('D').sum()
print(daily_ts)Gleitender Durchschnitt Der gleitende Durchschnitt ist eine Methode zur Glättung der Zeit durch Mittelung über ein rollierendes Fenster von Sequenzdaten Techniken. Kann dabei helfen, Rauschen zu entfernen und Trends in den Daten zu erkennen. Pandas bietet die Methode „rolling()“ zur Berechnung des Durchschnitts einer Zeitreihe. Hier ist ein Beispiel für die Berechnung des Durchschnitts einer Zeitreihe:
import pandas as pd # create a time series ts = pd.Series([1, 2, 3, 4, 5]) # calculate the rolling mean with a window size of 3 rolling_mean = ts.rolling(window=3).mean() print(rolling_mean)
Wir erstellen eine Zeitreihe und verwenden dann die Methode „rolling()“, um den gleitenden Durchschnitt mit einer Fenstergröße von 3 zu berechnen.

3、Exponentielle Glättung
Exponentielle Glättung Exponentielle Glättung ist eine Technik zum Glätten von Zeitreihendaten, indem aktuellen Werten mehr Gewicht verliehen wird. Es kann dabei helfen, Rauschen zu entfernen, um Trends in den Daten zu ermitteln. Pandas bietet die Methode ewm() zur Berechnung des exponentiellen gleitenden Durchschnitts.
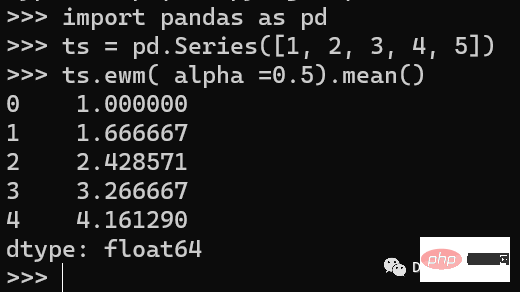
import pandas as pd ts = pd.Series([1, 2, 3, 4, 5]) ts.ewm( alpha =0.5).mean()

Im obigen Beispiel erstellen wir eine Zeitreihe und verwenden dann die ewm()-Methode, um einen exponentiellen gleitenden Durchschnitt mit einem Glättungsfaktor von zu berechnen 0,5.
com: Geben Sie den Abfall basierend auf dem Massenschwerpunkt an Bereich#🎜🎜 #
# ?? Die oben genannten 4 Parameter sind alle angegebene Glättungskoeffizienten α, aber die ersten drei werden basierend auf Bedingungen berechnet, und der letzte wird manuell angegeben, sodass mindestens einer vorhanden sein muss. Im obigen Beispiel haben wir ihn beispielsweise direkt manuell festgelegt 0,5
min_periods Es gibt einen Wert im Fenster. Die minimale Anzahl von Beobachtungen ist standardmäßig 0.
 adjust Ob eine Fehlerkorrektur durchgeführt werden soll. Der Standardwert ist True.
adjust Ob eine Fehlerkorrektur durchgeführt werden soll. Der Standardwert ist True.
adjust =Ture时公式如下:

adjust =False

Autocorrelation 自相关是一种用于测量时间序列与其滞后版本之间相关性的技术。可以识别数据中重复的模式。Pandas提供了autocorr()方法来计算自相关性。
import pandas as pd # create a time series ts = pd.Series([1, 2, 3, 4, 5]) # calculate the autocorrelation with a lag of 1 autocorr = ts.autocorr(lag=1) print(autocorr)

Fourier Transform 傅里叶变换是一种将时间序列数据从时域变换到频域的技术。可以识别数据中的周期性模式。我们可以使用numpy的fft()方法来计算时间序列的快速傅里叶变换。
import pandas as pd import numpy as np # create a time series ts = pd.Series([1, 2, 3, 4, 5]) # calculate the Fourier transform fft = pd.Series(np.fft.fft(ts).real) print(fft)

这里我们只显示了实数的部分。
在本文中,我们介绍了几种使用Python和Pandas的时间序列特征提取技术。这些技术可以帮助将原始时间序列数据转换为可用于分析和预测的有意义的特征,在训练机器学习模型时,这些特征都可以当作额外的数据输入到模型中,可以增加模型的预测能力。
Das obige ist der detaillierte Inhalt vonPython- und Pandas-Codebeispiele für die Extraktion von Zeitreihenmerkmalen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



