

Der Label-Propagation-Algorithmus ist ein halbüberwachter Algorithmus für maschinelles Lernen, der zuvor unbeschrifteten Datenpunkten Labels zuweist. Um diesen Algorithmus beim maschinellen Lernen zu verwenden, verfügt nur ein kleiner Teil der Beispiele über Beschriftungen oder Klassifizierungen. Diese Beschriftungen werden während der Modellierungs-, Anpassungs- und Vorhersageprozesse des Algorithmus an unbeschriftete Datenpunkte weitergegeben.

LabelPropagation ist ein schneller Algorithmus zum Auffinden von Communities in Diagrammen. Es verwendet lediglich die Netzwerkstruktur als Leitfaden zur Erkennung dieser Verbindungen und erfordert keine vordefinierte Zielfunktion oder A-priori-Informationen über die Bevölkerung. Die Tag-Weitergabe erfolgt durch die Weitergabe von Tags im Netzwerk und den Aufbau von Verbindungen auf der Grundlage des Tag-Weitergabeprozesses.
Schließende Tags erhalten normalerweise das gleiche Tag. Ein einzelnes Label kann in dicht verbundenen Knotengruppen dominieren, hat jedoch in dünn verbundenen Regionen Probleme. Beschriftungen werden auf eine eng verbundene Gruppe von Knoten beschränkt, und wenn der Algorithmus abgeschlossen ist, können die Knoten, die am Ende dieselbe Beschriftung haben, als Teil derselben Verbindung betrachtet werden. Der Algorithmus nutzt die Graphentheorie wie folgt:-
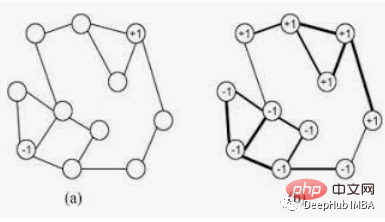
Der LabelPropagation-Algorithmus funktioniert folgendermaßen:-
Um zu demonstrieren, wie der LabelPropagation-Algorithmus funktioniert, verwenden wir den Pima Indians-Datensatz. Beim Erstellen des Programms habe ich die zum Ausführen erforderlichen Bibliotheken importiert.

Kopieren Sie eine Kopie der Daten und verwenden Sie die Beschriftungsspalte als Trainingsziel

Visualisierung mit Matplotlib:

Randomisieren Sie 70 % der Beschriftungen im Datensatz mithilfe eines Zufallszahlengenerators. Anschließend werden zufällige Beschriftungen zugewiesen -1:-
Nach der Vorverarbeitung der Daten definieren Sie die abhängigen und unabhängigen Variablen, nämlich y bzw. X. Die y-Variable ist die letzte Spalte und die

Werfen wir einen Blick auf einen anderen Algorithmus, LabelSpreading.
LabelSpreading
 LabelSpreading kann als die regulierte Form von LabelPropagation betrachtet werden. In der Graphentheorie ist die Laplace-Matrix die Matrixdarstellung des Graphen. Die Formel der Laplace-Matrix lautet:
LabelSpreading kann als die regulierte Form von LabelPropagation betrachtet werden. In der Graphentheorie ist die Laplace-Matrix die Matrixdarstellung des Graphen. Die Formel der Laplace-Matrix lautet:
L ist die Laplace-Matrix, D ist die Gradmatrix und A ist die Adjazenzmatrix.
Das Folgende ist ein einfaches Beispiel für die Beschriftung eines ungerichteten Diagramms und das Ergebnis seiner Laplace-Matrix

In diesem Artikel wird der Sonardatensatz verwendet, um zu demonstrieren, wie die LabelSpreading-Funktion von sklearn verwendet wird.
Hier gibt es mehr Bibliotheken als oben, also erklären Sie kurz:
Nachdem der Import abgeschlossen ist, verwenden Sie Pandas, um in den Datensatz einzulesen:

Ich habe die Heatmap mit Seaborn erstellt:-

Führen Sie zunächst eine einfache Vorverarbeitung durch und löschen Sie stark korrelierte Spalten und reduzieren Sie so die Anzahl der Spalten von 61 auf 58:

Dann mischen und ordnen Sie die Daten neu, sodass Vorhersagen im verschlüsselten Datensatz normalerweise besser sind, um genau zu sein eine Kopie des Datensatzes und definieren Sie y_orig als Trainingsziel:

Verwenden Sie matplotlib, um ein 2D-Streudiagramm der Datenpunkte zu zeichnen:-

Verwenden Sie einen Zufallszahlengenerator, um 60 % des Datensatzes zu randomisieren . Anschließend werden zufällige Beschriftungen zugewiesen -1:-

Nach der Vorverarbeitung der Daten definieren Sie die abhängigen und unabhängigen Variablen, nämlich y bzw. X. Die y-Variable ist die letzte Spalte und die
Mit dieser Methode können wir eine Genauigkeit von 87,98 % erreichen: - 
Einfacher Vergleich: 1. Labelspreading enthält Alpha = 0,2, Alpha wird als Klemmkoeffizient bezeichnet und bezieht sich auf die Verwendung der Informationen seiner Nachbarn. Es handelt sich nicht um die relative Menge der ursprünglichen Beschriftung. Wenn es 0 ist, bedeutet dies, dass die anfänglichen Beschriftungsinformationen beibehalten werden. Wenn es 1 ist, bedeutet dies, dass bei der Einstellung von Alpha=0,2 immer 80 % der ursprünglichen Beschriftung beibehalten werden Informationen;
2. Verwenden Sie Labelpropagation. Die aus den Daten erstellte Original-Label-Spreading minimiert eine Verlustfunktion mit Regularisierungseigenschaften, die eine modifizierte Version des Originaldiagramms iteriert und diese durch Berechnung normalisiert normalisierte Laplace-Matrix Kantengewicht. 
Das obige ist der detaillierte Inhalt vonZwei halbüberwachte Etikettenweitergabealgorithmen in sklearn: LabelPropagation und LabelSpreading. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



