


Microservices folgen Domain Driven Design (DDD) und sind unabhängig von der Entwicklungsplattform. Python-Microservices sind keine Ausnahme. Die objektorientierte Natur von Python3 erleichtert die Modellierung von Diensten im Sinne von DDD.
Die Stärke der Microservice-Architektur liegt in ihrer Mehrsprachigkeit. Das Unternehmen unterteilt seine Funktionalität in eine Reihe von Microservices, und jedes Team kann eine Plattform frei wählen.
Unser Benutzerverwaltungssystem wurde in vier Microservices zerlegt, nämlich Add-, Find-, Such- und Protokolldienste. Zusätzliche Dienste werden auf der Java-Plattform entwickelt und für Ausfallsicherheit und Skalierbarkeit auf Kubernetes-Clustern bereitgestellt. Dies bedeutet nicht, dass auch die restlichen Dienste in Java entwickelt werden müssen. Es steht uns frei, die Plattform zu wählen, die zu unseren einzelnen Diensten passt.
Wählen wir Python als Plattform für die Entwicklung des Suchdienstes. Das Modell zum Finden von Diensten wurde entworfen (siehe Artikel im März 2022), wir müssen dieses Modell nur noch in Code und Konfiguration umwandeln.
Python ist eine Allzweck-Programmiersprache, die es seit etwa 30 Jahren gibt. Schon früh war es die erste Wahl für Automatisierungsskripte. Mit dem Aufkommen von Frameworks wie Django und Flask hat seine Beliebtheit jedoch zugenommen und es wird mittlerweile in verschiedenen Bereichen wie der Entwicklung von Unternehmensanwendungen eingesetzt. Datenwissenschaft und maschinelles Lernen haben das Wachstum weiter vorangetrieben, und Python ist heute eine der drei führenden Programmiersprachen.
Viele Menschen führen den Erfolg von Python auf die einfache Codierung zurück. Dies ist nur ein Teil des Grundes. Solange Ihr Ziel darin besteht, kleine Skripte zu entwickeln, ist Python wie ein Spielzeug, an dem Sie wirklich Freude haben werden. Wenn Sie jedoch in den Bereich der ernsthaften Anwendungsentwicklung im großen Maßstab einsteigen, müssen Sie sich mit einer Menge if und else, Python wird so gut oder so schlecht wie jede andere Plattform. Gehen Sie zum Beispiel objektorientiert vor! Vielen Python-Entwicklern ist möglicherweise nicht einmal bewusst, dass Python Klassen, Vererbung und mehr unterstützt. Python unterstützt zwar eine vollwertige objektorientierte Entwicklung, aber auf seine eigene Art – Pythonic! Lass es uns erkunden! if 和 else,Python 变得与任何其他平台一样好或一样坏。例如,采用一种面向对象的方法!许多 Python 开发人员甚至可能没意识到 Python 支持类、继承等功能。Python 确实支持成熟的面向对象开发,但是有它自己的方式 -- Pythonic!让我们探索一下!
AddService 通过将数据保存到一个 MySQL 数据库中来将用户添加到系统中。FindService 的目标是提供一个 REST API 按用户名查找用户。域模型如图 1 所示。它主要由一些值对象组成,如 User 实体的Name、PhoneNumber 以及 UserRepository。
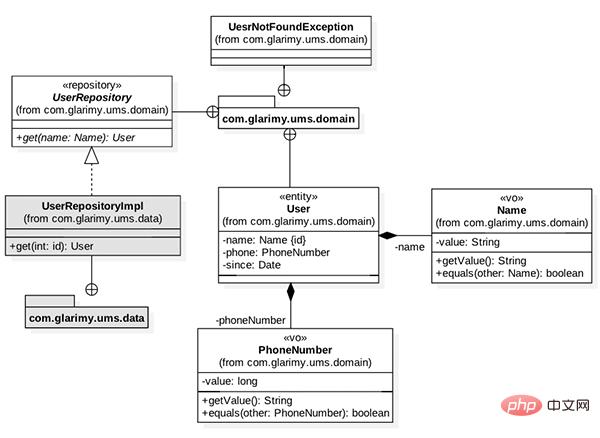
图 1: 查找服务的域模型
让我们从 Name 开始。由于它是一个值对象,因此必须在创建时进行验证,并且必须保持不可变。基本结构如所示:
class Name:value: strdef __post_init__(self):if self.value is None or len(self.value.strip()) < 8 or len(self.value.strip()) > 32:raise ValueError("Invalid Name")如你所见,Name
AddService Fügt Benutzer zum System hinzu, indem Daten in einer MySQL-Datenbank gespeichert werden. FindService< Das Ziel von /code> besteht darin, eine REST-API bereitzustellen, um Benutzer anhand des Benutzernamens zu finden. Das Domänenmodell ist in Abbildung 1 dargestellt. Es besteht hauptsächlich aus einigen Wertobjekten, wie zum Beispiel <code style="background-color: rgb(231, 243, 237); padding: 0px 3px; border-radius: 4px; overflow-wrap: break-word; text- indent : 0px;">User EntityName,PhoneNumber und UserRepository 🎜🎜🎜🎜Abbildung 1: Domänenmodell zum Finden von Diensten🎜🎜🎜Beginnen wir mit Name Da es sich um ein Wertobjekt handelt, muss es bei der Erstellung validiert werden und unveränderlich bleiben. Die Grundstruktur ist wie gezeigt: 🎜
from dataclasses import dataclass@dataclassclass Name:value: strdef __post_init__(self):if self.value is None or len(self.value.strip()) < 8 or len(self.value.strip()) > 32:raise ValueError("Invalid Name")Name Enthält einen Wert vom Typ string. Wir überprüfen dies im Rahmen der Nachinitialisierung. 🎜Python 3.7 提供了 @dataclass 装饰器,它提供了许多开箱即用的数据承载类的功能,如构造函数、比较运算符等。如下是装饰后的 Name 类:
from dataclasses import dataclass@dataclassclass Name:value: strdef __post_init__(self):if self.value is None or len(self.value.strip()) < 8 or len(self.value.strip()) > 32:raise ValueError("Invalid Name")以下代码可以创建一个 Name 对象:
name = Name("Krishna")value 属性可以按照如下方式读取或写入:
name.value = "Mohan"print(name.value)
可以很容易地与另一个 Name 对象比较,如下所示:
other = Name("Mohan")if name == other:print("same")如你所见,对象比较的是值而不是引用。这一切都是开箱即用的。我们还可以通过冻结对象使对象不可变。这是 Name 值对象的最终版本:
from dataclasses import dataclass@dataclass(frozen=True)class Name:value: strdef __post_init__(self):if self.value is None or len(self.value.strip()) < 8 or len(self.value.strip()) > 32:raise ValueError("Invalid Name")PhoneNumber 也遵循类似的方法,因为它也是一个值对象:
@dataclass(frozen=True)class PhoneNumber:value: intdef __post_init__(self):if self.value < 9000000000:raise ValueError("Invalid Phone Number")User 类是一个实体,不是一个值对象。换句话说,User 是可变的。以下是结构:
from dataclasses import dataclassimport datetime@dataclassclass User:_name: Name_phone: PhoneNumber_since: datetime.datetimedef __post_init__(self):if self._name is None or self._phone is None:raise ValueError("Invalid user")if self._since is None:self.since = datetime.datetime.now()你能观察到 User 并没有冻结,因为我们希望它是可变的。但是,我们不希望所有属性都是可变的。标识字段如 _name 和 _since 是希望不会修改的。那么,这如何做到呢?
Python3 提供了所谓的描述符协议,它会帮助我们正确定义 getter 和 setter。让我们使用 @property 装饰器将 getter 添加到 User 的所有三个字段中。
@propertydef name(self) -> Name:return self._name@propertydef phone(self) -> PhoneNumber:return self._phone@propertydef since(self) -> datetime.datetime:return self._since
phone 字段的 setter 可以使用 @<字段>.setter 来装饰:
@phone.setterdef phone(self, phone: PhoneNumber) -> None:if phone is None:raise ValueError("Invalid phone")self._phone = phone通过重写 __str__() 函数,也可以为 User 提供一个简单的打印方法:
def __str__(self):return self.name.value + " [" + str(self.phone.value) + "] since " + str(self.since)
这样,域模型的实体和值对象就准备好了。创建异常类如下所示:
class UserNotFoundException(Exception):pass
域模型现在只剩下 UserRepository 了。Python 提供了一个名为 abc 的有用模块来创建抽象方法和抽象类。因为 UserRepository 只是一个接口,所以我们可以使用 abc 模块。
任何继承自 abc.ABC 的类都将变为抽象类,任何带有 @abc.abstractmethod 装饰器的函数都会变为一个抽象函数。下面是 UserRepository 的结构:
from abc import ABC, abstractmethodclass UserRepository(ABC):@abstractmethoddef fetch(self, name:Name) -> User:pass
UserRepository 遵循仓储模式。换句话说,它在 User 实体上提供适当的 CRUD 操作,而不会暴露底层数据存储语义。在本例中,我们只需要 fetch() 操作,因为 FindService 只查找用户。
因为 UserRepository 是一个抽象类,我们不能从抽象类创建实例对象。创建对象必须依赖于一个具体类实现这个抽象类。数据层 UserRepositoryImpl 提供了 UserRepository 的具体实现:
class UserRepositoryImpl(UserRepository):def fetch(self, name:Name) -> User:pass
由于 AddService 将用户数据存储在一个 MySQL 数据库中,因此 UserRepositoryImpl 也必须连接到相同的数据库去检索数据。下面是连接到数据库的代码。注意,我们正在使用 MySQL 的连接库。
from mysql.connector import connect, Errorclass UserRepositoryImpl(UserRepository):def fetch(self, name:Name) -> User:try:with connect(host="mysqldb",user="root",password="admin",database="glarimy",) as connection:with connection.cursor() as cursor:cursor.execute("SELECT * FROM ums_users where name=%s", (name.value,))row = cursor.fetchone()if cursor.rowcount == -1:raise UserNotFoundException()else:return User(Name(row[0]), PhoneNumber(row[1]), row[2])except Error as e:raise e在上面的片段中,我们使用用户 root / 密码 admin 连接到一个名为 mysqldb 的数据库服务器,使用名为 glarimy 的数据库(模式)。在演示代码中是可以包含这些信息的,但在生产中不建议这么做,因为这会暴露敏感信息。
fetch() 操作的逻辑非常直观,它对 ums_users 表执行 SELECT 查询。回想一下,AddService 正在将用户数据写入同一个表中。如果 SELECT 查询没有返回记录,fetch() 函数将抛出 UserNotFoundException 异常。否则,它会从记录中构造 User 实体并将其返回给调用者。这没有什么特殊的。
最终,我们需要创建应用层。此模型如图 2 所示。它只包含两个类:控制器和一个 DTO。
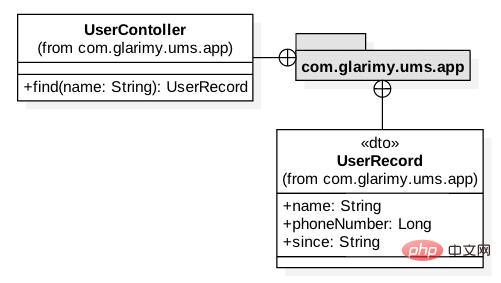
图 2: 添加服务的应用层
众所周知,一个 DTO 只是一个没有任何业务逻辑的数据容器。它主要用于在 FindService 和外部之间传输数据。我们只是提供了在 REST 层中将 UserRecord 转换为字典以便用于 JSON 传输:
class UserRecord:def toJSON(self):return {"name": self.name,"phone": self.phone,"since": self.since}控制器的工作是将 DTO 转换为用于域服务的域对象,反之亦然。可以从 find() 操作中观察到这一点。
class UserController:def __init__(self):self._repo = UserRepositoryImpl()def find(self, name: str):try:user: User = self._repo.fetch(Name(name))record: UserRecord = UserRecord()record.name = user.name.valuerecord.phone = user.phone.valuerecord.since = user.sincereturn recordexcept UserNotFoundException as e:return None
find() 操作接收一个字符串作为用户名,然后将其转换为 Name 对象,并调用 UserRepository 获取相应的 User 对象。如果找到了,则使用检索到的 User`` 对象创建UserRecord`。回想一下,将域对象转换为 DTO 是很有必要的,这样可以对外部服务隐藏域模型。
UserController 不需要有多个实例,它也可以是单例的。通过重写 __new__,可以将其建模为一个单例。
class UserController:def __new__(self):if not hasattr(self, ‘instance’):self.instance = super().__new__(self)return self.instancedef __init__(self):self._repo = UserRepositoryImpl()def find(self, name: str):try:user: User = self._repo.fetch(Name(name))record: UserRecord = UserRecord()record.name = user.name.getValue()record.phone = user.phone.getValue()record.since = user.sincereturn recordexcept UserNotFoundException as e:return None
我们已经完全实现了 FindService 的模型,剩下的唯一任务是将其作为 REST 服务公开。
FindService 只提供一个 API,那就是通过用户名查找用户。显然 URI 如下所示:
GET /user/{name}此 API 希望根据提供的用户名查找用户,并以 JSON 格式返回用户的电话号码等详细信息。如果没有找到用户,API 将返回一个 404 状态码。
我们可以使用 Flask 框架来构建 REST API,它最初的目的是使用 Python 开发 Web 应用程序。除了 HTML 视图,它还进一步扩展到支持 REST 视图。我们选择这个框架是因为它足够简单。 创建一个 Flask 应用程序:
from flask import Flaskapp = Flask(__name__)
然后为 Flask 应用程序定义路由,就像函数一样简单:
@app.route('/user/<name>')def get(name):pass注意 @app.route 映射到 API /user/<name>,与之对应的函数的 get()。
如你所见,每次用户访问 API 如 http://server:port/user/Krishna 时,都将调用这个 get() 函数。Flask 足够智能,可以从 URL 中提取 Krishna 作为用户名,并将其传递给 get() 函数。
get() 函数很简单。它要求控制器找到该用户,并将其与通常的 HTTP 头一起打包为 JSON 格式后返回。如果控制器返回 None,则 get() 函数返回合适的 HTTP 状态码。
from flask import jsonify, abortcontroller = UserController()record = controller.find(name)if record is None:abort(404)else:resp = jsonify(record.toJSON())resp.status_code = 200return resp
最后,我们需要 Flask 应用程序提供服务,可以使用 waitress 服务:
from waitress import serveserve(app, host="0.0.0.0", port=8080)
在上面的片段中,应用程序在本地主机的 8080 端口上提供服务。最终代码如下所示:
from flask import Flask, jsonify, abortfrom waitress import serveapp = Flask(__name__)@app.route('/user/<name>')def get(name):controller = UserController()record = controller.find(name)if record is None:abort(404)else:resp = jsonify(record.toJSON())resp.status_code = 200return respserve(app, host="0.0.0.0", port=8080)FindService 的代码已经准备完毕。除了 REST API 之外,它还有域模型、数据层和应用程序层。下一步是构建此服务,将其容器化,然后部署到 Kubernetes 上。此过程与部署其他服务妹有任何区别,但有一些 Python 特有的步骤。
在继续前进之前,让我们来看下文件夹和文件结构:
+ ums-find-service+ ums- domain.py- data.py- app.py- Dockerfile- requirements.txt- kube-find-deployment.yml
如你所见,整个工作文件夹都位于 ums-find-service 下,它包含了 ums 文件夹中的代码和一些配置文件,例如 Dockerfile、requirements.txt 和 kube-find-deployment.yml。
domain.py 包含域模型,data.py 包含 UserRepositoryImpl,app.py 包含剩余代码。我们已经阅读过代码了,现在我们来看看配置文件。
第一个是 requirements.txt,它声明了 Python 系统需要下载和安装的外部依赖项。我们需要用查找服务中用到的每个外部 Python 模块来填充它。如你所见,我们使用了 MySQL 连接器、Flask 和 Waitress 模块。因此,下面是 requirements.txt 的内容。
Flask==2.1.1Flask_RESTfulmysql-connector-pythonwaitress
第二步是在 Dockerfile 中声明 Docker 相关的清单,如下:
FROM python:3.8-slim-busterWORKDIR /umsADD ums /umsADD requirements.txt requirements.txtRUN pip3 install -r requirements.txtEXPOSE 8080ENTRYPOINT ["python"]CMD ["/ums/app.py"]
总的来说,我们使用 Python 3.8 作为基线,除了移动 requirements.txt 之外,我们还将代码从 ums 文件夹移动到 Docker 容器中对应的文件夹中。然后,我们指示容器运行 pip3 install 命令安装对应模块。最后,我们向外暴露 8080 端口(因为 waitress 运行在此端口上)。
为了运行此服务,我们指示容器使用使用以下命令:
python /ums/app.py
一旦 Dockerfile 准备完成,在 ums-find-service 文件夹中运行以下命令,创建 Docker 镜像:
docker build -t glarimy/ums-find-service
它会创建 Docker 镜像,可以使用以下命令查找镜像:
docker images
尝试将镜像推送到 Docker Hub,你也可以登录到 Docker。
docker logindocker push glarimy/ums-find-service
最后一步是为 Kubernetes 部署构建清单。
在之前的文章中,我们已经介绍了如何建立 Kubernetes 集群、部署和使用服务的方法。我假设仍然使用之前文章中的清单文件来部署添加服务、MySQL、Kafka 和 Zookeeper。我们只需要将以下内容添加到 kube-find-deployment.yml 文件中:
apiVersion: apps/v1kind: Deploymentmetadata:name: ums-find-servicelabels:app: ums-find-servicespec:replicas: 3selector:matchLabels:app: ums-find-servicetemplate:metadata:labels:app: ums-find-servicespec:containers:- name: ums-find-serviceimage: glarimy/ums-find-serviceports:- containerPort: 8080---apiVersion: v1kind: Servicemetadata:name: ums-find-servicelabels:name: ums-find-servicespec:type: LoadBalancerports:- port: 8080selector:app: ums-find-service
上面清单文件的第一部分声明了 glarimy/ums-find-service 镜像的 FindService,它包含三个副本。它还暴露 8080 端口。清单的后半部分声明了一个 Kubernetes 服务作为 FindService 部署的前端。请记住,在之前文章中,mysqldb 服务已经是上述清单的一部分了。
运行以下命令在 Kubernetes 集群上部署清单文件:
kubectl create -f kube-find-deployment.yml
部署完成后,可以使用以下命令验证容器组和服务:
kubectl get services
输出如图 3 所示:

图 3: Kubernetes 服务
它会列出集群上运行的所有服务。注意查找服务的外部 IP,使用 curl 调用此服务:
curl http://10.98.45.187:8080/user/KrishnaMohan
注意:10.98.45.187 对应查找服务,如图 3 所示。
如果我们使用 AddService 创建一个名为 KrishnaMohan 的用户,那么上面的 curl 命令看起来如图 4 所示:

图 4: 查找服务
用户管理系统(UMS)的体系结构包含 AddService 和 FindService,以及存储和消息传递所需的后端服务,如图 5 所示。可以看到终端用户使用 ums-add-service 的 IP 地址添加新用户,使用 ums-find-service 的 IP 地址查找已有用户。每个 Kubernetes 服务都由三个对应容器的节点支持。还要注意:同样的 mysqldb 服务用于存储和检索用户数据。
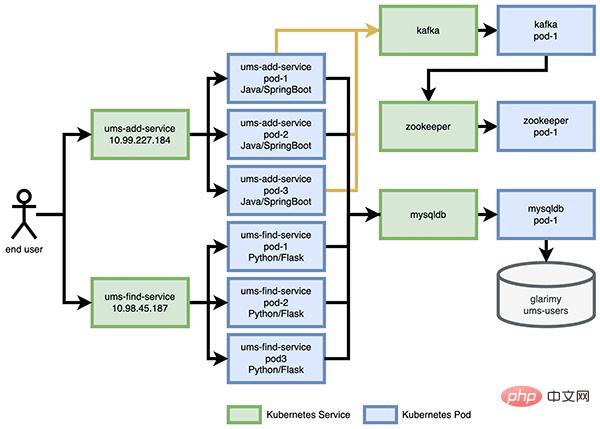
图 5: UMS 的添加服务和查找服务
UMS 系统还包含两个服务:SearchService 和 JournalService。在本系列的下一部分中,我们将在 Node 平台上设计这些服务,并将它们部署到同一个 Kubernetes 集群,以演示多语言微服务架构的真正魅力。最后,我们将观察一些与微服务相关的设计模式。
Das obige ist der detaillierte Inhalt vonVerwenden Sie Flask, um Python-Microservices auf Kubernetes zu erstellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



