
 Technologie-Peripheriegeräte
KI
Reichen modulare maschinelle Lernsysteme aus? Bengio-Lehrer und -Schüler sagen Ihnen die Antwort
Technologie-Peripheriegeräte
KI
Reichen modulare maschinelle Lernsysteme aus? Bengio-Lehrer und -Schüler sagen Ihnen die Antwort
Reichen modulare maschinelle Lernsysteme aus? Bengio-Lehrer und -Schüler sagen Ihnen die Antwort

Deep-Learning-Forscher lassen sich von den Neuro- und Kognitionswissenschaften inspirieren – von versteckten Einheiten und Eingabemethoden bis hin zum Design von Netzwerkverbindungen und Netzwerkarchitekturen – viele bahnbrechende Studien basieren auf der Nachahmung von Gehirnoperationsstrategien. Es besteht kein Zweifel, dass Modularität und Aufmerksamkeit in den letzten Jahren häufig in künstlichen Netzwerken kombiniert eingesetzt wurden und beeindruckende Ergebnisse erzielt haben.
Tatsächlich zeigt die kognitive Neurowissenschaft, dass die Großhirnrinde Wissen auf modulare Weise darstellt, zwischen verschiedenen Modulen kommuniziert und der Aufmerksamkeitsmechanismus die Inhaltsauswahl durchführt. Dies ist die oben erwähnte Kombination von Modularität und Aufmerksamkeit. In neueren Forschungen wurde vermutet, dass dieser Kommunikationsmodus im Gehirn Auswirkungen auf die induktive Verzerrung in tiefen Netzwerken haben könnte. Die spärlichen Abhängigkeiten zwischen diesen Variablen auf hoher Ebene zerlegen das Wissen in rekombinierbare Fragmente, die möglichst unabhängig sind, was das Lernen effizienter macht.
Obwohl sich ein Großteil der neueren Forschung auf solche modularen Architekturen stützt, verwenden Forscher eine Vielzahl von Tricks und Architekturmodifikationen, was es schwierig macht, echte, nutzbare Architekturprinzipien zu analysieren.
Maschinelle Lernsysteme zeigen nach und nach die Vorteile spärlicherer und modularerer Architekturen, die nicht nur eine gute Generalisierungsleistung, sondern auch eine bessere Out-of-Distribution (OoD)-Leistung und Skalierbarkeit bieten Interpretierbarkeit. Ein Schlüssel zum Erfolg solcher Systeme liegt darin, dass davon ausgegangen wird, dass datengenerierende Systeme, die in realen Umgebungen verwendet werden, aus kaum interagierenden Teilen bestehen, und es wäre hilfreich, dem Modell eine ähnliche induktive Ausrichtung zu verleihen. Da diese realen Datenverteilungen jedoch komplex und unbekannt sind, mangelt es auf diesem Gebiet an strengen quantitativen Bewertungen dieser Systeme.
Ein Artikel von drei Forschern der Universität Montreal, Sarthak Mittal, Yoshua Bengio und Guillaume Lajoie, die eine umfassende Bewertung gängiger modularer Architekturen durch einfache und bekannte modulare Datenverteilung durchgeführt haben. Die Studie beleuchtet die Vorteile von Modularität und Sparsity und gibt Einblicke in die Herausforderungen bei der Optimierung modularer Systeme. Der Erstautor und korrespondierende Autor, Sarthak Mittal, ist ein Meisterschüler von Bengio und Lajoie.

- Paper -Adresse: https://arxiv.org/pdf/2206.02713.pdf
- github Adresse: https://github.com/sarthmit/mod_arch
specifical, diese, Die Studie erweitert die Analyse von Rosenbaum et al. und schlägt eine Methode zur Bewertung, Quantifizierung und Analyse gemeinsamer Komponenten modularer Architekturen vor. Zu diesem Zweck entwickelte die Forschung eine Reihe von Benchmarks und Metriken, um die Wirksamkeit modularer Netzwerke zu untersuchen. Daraus ergeben sich wertvolle Erkenntnisse, die nicht nur dabei helfen, herauszufinden, wo aktuelle Ansätze erfolgreich sind, sondern auch, wann und wie diese Ansätze scheitern.
Der Beitrag dieser Forschung kann wie folgt zusammengefasst werden:
- Diese Forschung entwickelt Benchmark-Aufgaben und Metriken auf der Grundlage probabilistischer Auswahlregeln und verwendet Benchmarks und Metriken, um zwei wichtige Phänomene in modularen Systemen zu quantifizieren: Kollaps und Spezialisierung, Spezialisierung.
- Diese Studie extrahiert häufig verwendete modulare induktive Vorspannungen und bewertet sie systematisch anhand einer Reihe von Modellen, die darauf ausgelegt sind, häufig verwendete architektonische Eigenschaften zu extrahieren (monolithische, modulare, modular-optische, GT-modulare Modelle).
- Die Studie ergab, dass die Spezialisierung auf modulare Systeme die Modellleistung erheblich verbessern kann, wenn eine Aufgabe viele latente Regeln enthält, nicht jedoch, wenn nur wenige vorhanden sind.
- Die Studie ergab, dass standardmäßige modulare Systeme sowohl hinsichtlich ihrer Fähigkeit, sich auf die richtigen Informationen zu konzentrieren, als auch hinsichtlich ihrer Spezialisierungsfähigkeit tendenziell suboptimal sind, was auf die Notwendigkeit einer zusätzlichen induktiven Voreingenommenheit hindeutet.
Definition/Terminologie
In diesem Artikel untersuchen wir, wie eine Reihe modularer Systeme allgemeine Aufgaben ausführen, die durch einen synthetischen Datengenerierungsprozess formuliert werden, den wir Regeldaten nennen. Sie stellen die Definition von Schlüsselkomponenten vor, einschließlich (1) Regeln und wie diese Regeln Aufgaben bilden, (2) Module und wie diese Module unterschiedliche Modellarchitekturen übernehmen, (3) Spezialisierung und wie Modelle bewertet werden. Die detaillierten Einstellungen sind in Abbildung 1 unten dargestellt.

Regeln. Um modulare Systeme richtig zu verstehen und ihre Vor- und Nachteile zu analysieren, haben die Forscher einen umfassenden Aufbau in Betracht gezogen, der eine feinkörnige Kontrolle über verschiedene Aufgabenanforderungen ermöglicht. Insbesondere müssen Operationen, die sie Regeln nennen, auf den in Gleichung 1-3 unten gezeigten datengenerierenden Verteilungen erlernt werden.

Angesichts der obigen Verteilung definiert der Forscher eine Regel, um sein Experte zu werden, das heißt, die Regel r ist als p_y(·|x, c = r) definiert, wobei c die darstellende Klassifizierung ist die Kontextvariable, x ist die Eingabesequenz.
Mission. Eine Aufgabe wird durch eine Reihe von Regeln (Datenerzeugungsverteilungen) beschrieben, die in Gleichung 1-3 dargestellt sind. Unterschiedliche Mengen von {p_y(· | x, c)}_c bedeuten unterschiedliche Aufgaben. Für eine bestimmte Anzahl von Regeln wird das Modell auf mehrere Aufgaben trainiert, um aufgabenspezifische Verzerrungen zu beseitigen.
Modul. Ein modulares System besteht aus einer Reihe neuronaler Netzwerkmodule, wobei jedes Modul zur Gesamtleistung beiträgt. Dies lässt sich anhand der folgenden Funktionsform erkennen.

wobei y_m die Ausgabe und p_m die Aktivierung des m^-ten Moduls darstellt.
Modellarchitektur. Die Modellarchitektur beschreibt, welche Architektur für jedes Modul eines modularen Systems oder für einzelne Module eines monolithischen Systems gewählt wird. In diesem Artikel erwägen die Forscher die Verwendung von Multi-Layer-Perceptron (MLP), Multi-Head-Attention (MHA) und Recurrent Neural Network (RNN). Es ist wichtig, dass die Regeln (oder datengenerierenden Verteilungen) an die Modellarchitektur angepasst werden, beispielsweise MLP-basierte Regeln.
Prozess der Datengenerierung
Da die Forscher darauf abzielen, modulare Systeme anhand synthetischer Daten zu erforschen, beschreiben sie den Prozess der Datengenerierung basierend auf dem oben beschriebenen Regelschema. Konkret verwendeten die Forscher einen einfachen Datengenerierungsprozess im Mixed-of-Experts-Stil (MoE) in der Hoffnung, dass unterschiedliche Module für unterschiedliche Experten in den Regeln spezialisiert werden könnten.
Sie erklären den Datengenerierungsprozess für drei Modellarchitekturen: MLP, MHA und RNN. Darüber hinaus gibt es unter jeder Aufgabe zwei Versionen: Regression und Klassifizierung.
MLP. Die Forscher definierten ein für das Lernen geeignetes Datenschema auf Basis modularer MLP-Systeme. Bei diesem Schema zur Generierung synthetischer Daten besteht eine Datenstichprobe aus zwei unabhängigen Zahlen und einer regulären Auswahl, die aus einer bestimmten Verteilung entnommen wird. Unterschiedliche Regeln erzeugen unterschiedliche lineare Kombinationen zweier Zahlen, um eine Ausgabe zu liefern. Das heißt, die Auswahl der linearen Kombination wird gemäß den Regeln dynamisch instanziiert, wie in Gleichung 4-6 unten dargestellt.
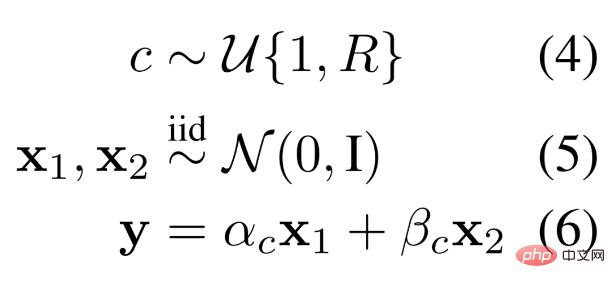

MHA. Jetzt haben Forscher ein Datenschema definiert, das auf das Lernen in einem modularen MHA-System abgestimmt ist. Daher entwarfen sie eine Datengenerierungsverteilung mit der folgenden Eigenschaft: Jede Regel besteht aus unterschiedlichen Such- und Abrufkonzepten und der endgültigen linearen Kombination der abgerufenen Informationen. Forscher beschreiben diesen Prozess mathematisch in der folgenden Gleichung 7-11.

RNN. Für Kreislaufsysteme definierten die Forscher Regeln für ein lineares dynamisches System, bei dem zu jedem Zeitpunkt eine von mehreren Regeln ausgelöst werden kann. Mathematisch wird dieser Prozess in der folgenden Gleichung 12-15 dargestellt.

Modell
Einige frühere Arbeiten behaupteten, dass durchgängig trainierte Modulsysteme monolithischen Systemen überlegen seien, insbesondere in verteilten Umgebungen. Eine detaillierte und tiefgreifende Analyse der Vorteile dieser modularen Systeme und der Frage, ob sie sich aufgrund der Verteilung der Datengenerierung tatsächlich spezialisieren, fehlt jedoch.
Daher betrachteten die Forscher vier Arten von Modellen, die unterschiedliche Spezialisierungsgrade ermöglichen, nämlich monolithisch (einzeln), modular (modular), modular-op und GT-modular. Tabelle 1 unten veranschaulicht diese Modelle.

Monolithisch. Ein monolithisches System ist ein großes neuronales Netzwerk, das einen ganzen Datensatz (x, c) als Eingabe verwendet und darauf basierend eine Vorhersage y^ trifft. Es gibt keine induktive Voreingenommenheit hinsichtlich der Modularität oder Spärlichkeit des im System eingebetteten expliziten Inhalts, und es beruht vollständig auf Backpropagation, um zu lernen, welche funktionale Form zur Lösung der Aufgabe erforderlich ist.
Modular. Ein modulares System besteht aus vielen Modulen, von denen jedes ein neuronales Netzwerk eines bestimmten Architekturtyps (MLP, MHA oder RNN) ist. Jedes Modul m verwendet Daten (x, c) als Eingabe und berechnet eine Ausgabe yˆ_m und einen Konfidenzwert, der über Module hinweg auf die Aktivierungswahrscheinlichkeit p_m normiert wird.
Modular-op. Ein modulares Betriebssystem ist einem modularen System sehr ähnlich, mit einem Unterschied. Anstatt die Aktivierungswahrscheinlichkeit p_m des Moduls m als Funktion von (x, c) zu definieren, stellten die Forscher sicher, dass die Aktivierung nur durch den Regelkontext C bestimmt wird.
GT-Modular. Als Orakel-Benchmark dienen modulare Systeme mit echtem Wert, d. h. perfekt spezialisierte modulare Systeme.
Forscher zeigen, dass Modelle von monolithischen bis hin zu GT-modularen Modellen zunehmend induktive Vorspannungen für Modularität und Sparsität enthalten.
Metriken
Um modulare Systeme zuverlässig zu bewerten, haben Forscher eine Reihe von Metriken vorgeschlagen, die nicht nur die Leistungsvorteile solcher Systeme messen, sondern sie auch in zwei wichtigen Formen bewerten: Zusammenbruch und Spezialisierung.
Leistung. Der erste Satz von Bewertungsmetriken basiert auf der Leistung sowohl in In-Distribution- als auch in Out-of-Distribution-Umgebungen (OoD) und spiegelt die Leistung verschiedener Modelle bei verschiedenen Aufgaben wider. Für die Klassifizierungseinstellung melden wir den Klassifizierungsfehler; für die Regressionseinstellung melden wir den Verlust.
Absturz. Die Forscher schlugen eine Reihe von Metriken vor, Collapse-Avg und Collapse-Worst, um das Ausmaß des Zusammenbruchs zu quantifizieren, dem ein modulares System ausgesetzt ist (d. h. das Ausmaß, in dem Module nicht ausreichend genutzt werden). Abbildung 2 unten zeigt ein Beispiel, in dem Sie sehen können, dass Modul 3 nicht verwendet wird.
Professionalisierung. Um die Kollapsmetriken zu ergänzen, schlagen wir auch den folgenden Satz von Metriken vor, nämlich (1) Ausrichtung, (2) Anpassung und (3) inverse gegenseitige Information, die den Grad der durch ein modulares System erreichten Spezialisierung quantifiziert.
Experimente
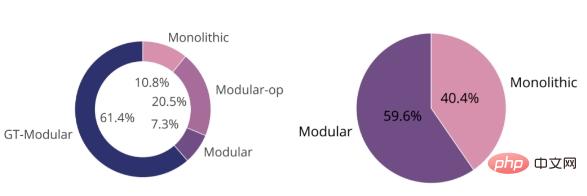
Die Abbildung unten zeigt, dass das GT-Modular-System in den meisten Fällen optimal ist (links), was zeigt, dass eine Spezialisierung von Vorteil ist. Wir sehen auch, dass zwischen dem Standard-End-to-End-Trainingsmodulsystem und dem monolithischen System das erstere das letztere übertrifft, jedoch nicht viel. Zusammengenommen zeigen diese beiden Tortendiagramme, dass aktuelle modulare Systeme für eine ganzheitliche Ausbildung keine gute Spezialisierung erreichen und daher weitgehend suboptimal sind.

Die Studie untersucht dann bestimmte architektonische Entscheidungen und analysiert deren Leistung und Trends anhand einer zunehmenden Anzahl von Regeln.

Abbildung 4 zeigt, dass ein perfekt spezialisiertes System (GT-Modular) zwar Vorteile bringen würde, ein typisches modulares System für End-to-End-Schulungen jedoch suboptimal ist und diese Vorteile nicht erzielen kann, insbesondere bei zunehmender Regelmenge . Darüber hinaus übertreffen solche durchgängigen modularen Systeme zwar häufig monolithische Systeme, der Vorteil ist jedoch meist nur gering.

In Abbildung 7 sehen wir auch die Trainingsmodi verschiedener Modelle. Im Durchschnitt aller anderen Einstellungen umfasst der Durchschnitt sowohl den Klassifizierungsfehler als auch den Regressionsverlust. Wie man sieht, führt eine gute Spezialisierung nicht nur zu einer besseren Leistung, sondern beschleunigt auch das Training.

Die folgende Abbildung zeigt zwei Kollapsmetriken: Collapse-Avg und Collapse-Worst. Darüber hinaus zeigt die folgende Abbildung auch drei Spezialisierungsindikatoren, Ausrichtung, Anpassung und inverse gegenseitige Information für verschiedene Modelle mit unterschiedlicher Anzahl von Regeln: 🎜#
#🎜🎜 # #🎜 🎜 # # 🎜🎜#
# 🎜🎜#
Das obige ist der detaillierte Inhalt vonReichen modulare maschinelle Lernsysteme aus? Bengio-Lehrer und -Schüler sagen Ihnen die Antwort. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Das intelligente Fahrsystem Qiankun ADS3.0 von Huawei wird im August auf den Markt kommen und erstmals auf dem Xiangjie S9 eingeführt
Jul 30, 2024 pm 02:17 PM
Das intelligente Fahrsystem Qiankun ADS3.0 von Huawei wird im August auf den Markt kommen und erstmals auf dem Xiangjie S9 eingeführt
Jul 30, 2024 pm 02:17 PM
Am 29. Juli nahm Yu Chengdong, Huawei-Geschäftsführer, Vorsitzender von Terminal BG und Vorsitzender von Smart Car Solutions BU, an der Übergabezeremonie des 400.000sten Neuwagens von AITO Wenjie teil, hielt eine Rede und kündigte an, dass die Modelle der Wenjie-Serie dies tun werden Dieses Jahr auf den Markt kommen Im August wurde die Huawei Qiankun ADS 3.0-Version auf den Markt gebracht und es ist geplant, die Upgrades sukzessive von August bis September voranzutreiben. Das Xiangjie S9, das am 6. August auf den Markt kommt, wird erstmals mit dem intelligenten Fahrsystem ADS3.0 von Huawei ausgestattet sein. Mit Hilfe von Lidar wird Huawei Qiankun ADS3.0 seine intelligenten Fahrfähigkeiten erheblich verbessern, über integrierte End-to-End-Funktionen verfügen und eine neue End-to-End-Architektur von GOD (allgemeine Hinderniserkennung)/PDP (prädiktiv) einführen Entscheidungsfindung und Kontrolle), Bereitstellung der NCA-Funktion für intelligentes Fahren von Parkplatz zu Parkplatz und Aktualisierung von CAS3.0
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Immer neu! Upgrade der Huawei Mate60-Serie auf HarmonyOS 4.2: KI-Cloud-Erweiterung, Xiaoyi-Dialekt ist so einfach zu bedienen
Jun 02, 2024 pm 02:58 PM
Immer neu! Upgrade der Huawei Mate60-Serie auf HarmonyOS 4.2: KI-Cloud-Erweiterung, Xiaoyi-Dialekt ist so einfach zu bedienen
Jun 02, 2024 pm 02:58 PM
Am 11. April kündigte Huawei erstmals offiziell den 100-Maschinen-Upgradeplan für HarmonyOS 4.2 an. Dieses Mal werden mehr als 180 Geräte an dem Upgrade teilnehmen, darunter Mobiltelefone, Tablets, Uhren, Kopfhörer, Smart-Screens und andere Geräte. Im vergangenen Monat haben mit dem stetigen Fortschritt des HarmonyOS4.2-Upgradeplans für 100 Maschinen auch viele beliebte Modelle, darunter Huawei Pocket2, Huawei MateX5-Serie, Nova12-Serie, Huawei Pura-Serie usw., mit der Aktualisierung und Anpassung begonnen, was bedeutet, dass dass es mehr Benutzer von Huawei-Modellen geben wird, die das gemeinsame und oft neue Erlebnis von HarmonyOS genießen können. Den Rückmeldungen der Benutzer zufolge hat sich das Erlebnis der Modelle der Huawei Mate60-Serie nach dem Upgrade von HarmonyOS4.2 in allen Aspekten verbessert. Vor allem Huawei M
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
