

Sechs magische integrierte Funktionen in Python


Das Leben ist kurz, Anfänger lernen Python!
Ich bin ein Neuling, heute werden wir 6 magische integrierte Funktionen auf einmal teilen. In vielen Computerbüchern werden sie meist auch als Funktionen höherer Ordnung eingeführt. Und in meiner täglichen Arbeit nutze ich sie oft, um Code schneller und verständlicher zu machen.
Lambda-Funktion
Die Lambda-Funktion wird zum Erstellen anonymer Funktionen, also Funktionen ohne Namen, verwendet. Es ist nur ein Ausdruck und der Funktionskörper ist viel einfacher als def. Anonyme Funktionen werden verwendet, wenn wir eine Funktion erstellen müssen, die eine einzelne Operation ausführt und in einer Zeile geschrieben werden kann.
lambda [arg1 [,arg2,.....argn]]:expression
Der Körper eines Lambda ist ein Ausdruck, kein Codeblock. In Lambda-Ausdrücken kann nur eine begrenzte Logik gekapselt werden. Zum Beispiel:
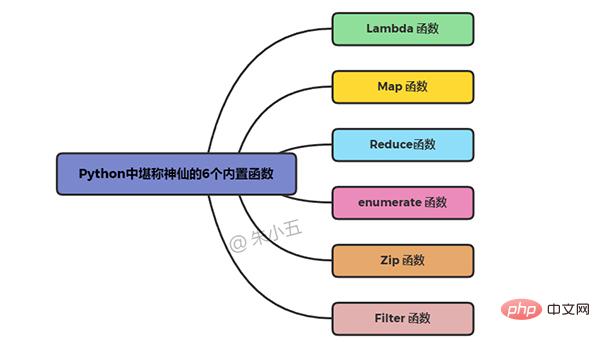
lambda x: x+2
Wenn wir jederzeit auch die durch def definierte Funktion aufrufen möchten, können wir einem solchen Funktionsobjekt die Lambda-Funktion zuweisen.
add2 = lambda x: x+2 add2(10)
Ausgabeergebnis:
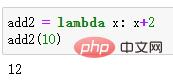
Mit der Lambda-Funktion kann der Code erheblich vereinfacht werden. Hier ist ein weiteres Beispiel.
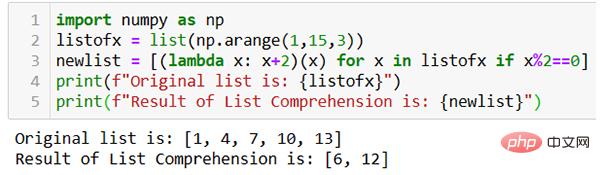
Wie im Bild oben gezeigt, wird die Ergebnisliste newlist mit einer Codezeile mithilfe der Lambda-Funktion generiert.
Map-Funktion
map()-Funktion ordnet eine Funktion allen Elementen einer Eingabeliste zu.
map(function,iterable)
Zum Beispiel erstellen wir zunächst eine Funktion, um ein Eingabewort in Großbuchstaben zurückzugeben, und wenden diese Funktion dann auf alle Elemente in den Listenfarben an.
def makeupper(word): return word.upper() colors=['red','yellow','green','black'] colors_uppercase=list(map(makeupper,colors)) colors_uppercase
Ausgabeergebnis:

Darüber hinaus können wir auch die anonyme Funktion Lambda verwenden, um mit der Kartenfunktion zusammenzuarbeiten, was rationalisiert werden kann.
colors=['red','yellow','green','black'] colors_uppercase=list(map(lambda x: x.upper(),colors)) colors_uppercase
Wenn wir die Map-Funktion nicht verwenden, müssen wir eine for-Schleife verwenden.
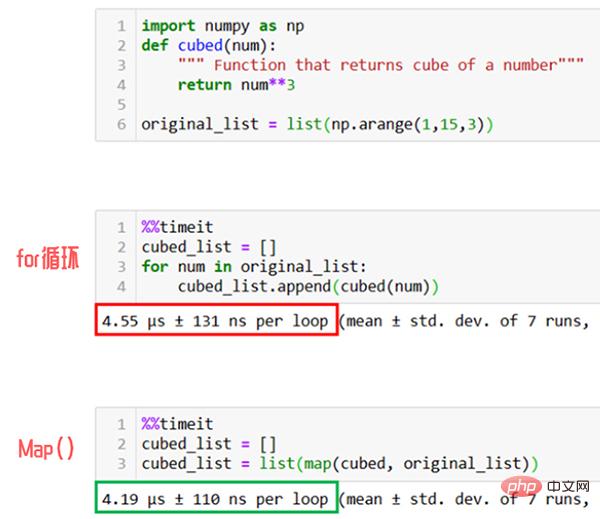
Wie in der Abbildung oben gezeigt, ist die Map-Funktion bei tatsächlicher Verwendung 1,5-mal schneller als die for-Schleifenmethode zum sequentiellen Auflisten von Elementen.
Reduce-Funktion
Reduce() ist eine sehr nützliche Funktion, wenn Sie einige Berechnungen für eine Liste durchführen und das Ergebnis zurückgeben müssen. Wenn Sie beispielsweise das Produkt aller Elemente einer Liste von ganzen Zahlen berechnen müssen, können Sie die Funktion „Reduzieren“ verwenden. [1]
Der größte Unterschied zwischen ihr und einer Funktion besteht darin, dass die Mapping-Funktion (Funktion) in Reduce() zwei Parameter empfängt, während Map einen Parameter empfängt.
reduce(function, iterable[, initializer])
Als nächstes verwenden wir ein Beispiel, um den Codeausführungsprozess von Reduce() zu demonstrieren.
from functools import reduce def add(x, y) : # 两数相加 return x + y numbers = [1,2,3,4,5] sum1 = reduce(add, numbers) # 计算列表和
Das Ergebnis sum1 = 15 wird erhalten und der Codeausführungsprozess wird in der folgenden Animation gezeigt.
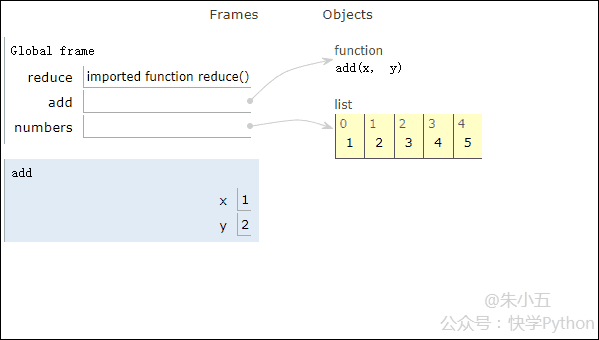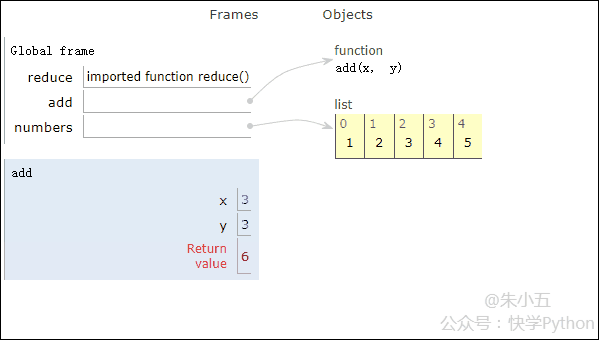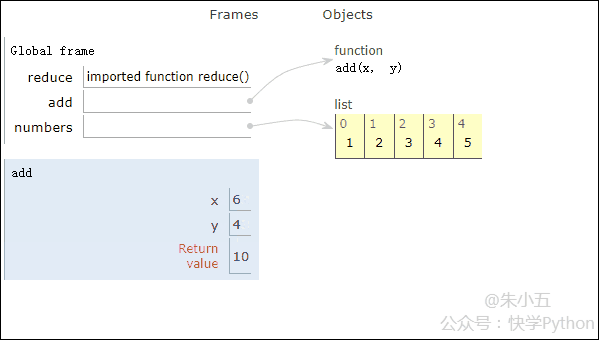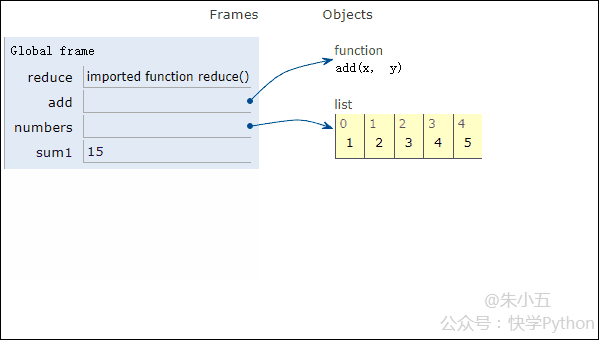
▲Animation des Codeausführungsprozesses
In Kombination mit der obigen Abbildung werden wir sehen, dass Reduce eine Additionsfunktion add() auf eine Liste [1,2,3,4,5] und die Zuordnung anwendet Funktion empfängt mit zwei Parametern, Reduce() akkumuliert das Ergebnis weiterhin mit dem nächsten Element der Liste.
Darüber hinaus können wir auch die anonyme Funktion Lambda verwenden, um mit der Reduzierungsfunktion zusammenzuarbeiten, was rationalisiert werden kann.
from functools import reduce numbers = [1,2,3,4,5] sum2 = reduce(lambda x, y: x+y, numbers)
Die Ausgabesumme2 = 15 wird erhalten, was mit dem vorherigen Ergebnis übereinstimmt.
Hinweis: Reduce() wurde seit Python3 in das Functools-Modul verschoben. Durchlaufbare Datenobjekte (wie Listen, Tupel oder Zeichenfolgen) werden in einer Indexsequenz zusammengefasst, die Daten und Datenindizes gleichzeitig auflistet, was im Allgemeinen in verwendet wird for-Schleifen. Die Syntax lautet wie folgt:
enumerate(iterable, start=0)
Die beiden Parameter sind eine Sequenz, ein Iterator oder ein anderes Objekt, das die Iteration unterstützt. Der andere ist die Startposition des Index. Standardmäßig beginnt er bei 0. Sie können auch den Startpunkt anpassen der Zähler Startnummer.
colors = ['red', 'yellow', 'green', 'black'] result = enumerate(colors)
Wenn wir eine Farbliste haben, die Farben speichert, erhalten wir nach der Ausführung ein Aufzählungsobjekt. Es kann direkt in einer for-Schleife verwendet oder in eine Liste konvertiert werden. Die spezifische Verwendung ist wie folgt.
for count, element in result:
print(f"迭代编号:{count},对应元素:{element}")
Zip 函数
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表[3]。
我们还是用两个列表作为例子演示:
colors = ['red', 'yellow', 'green', 'black'] fruits = ['apple', 'pineapple', 'grapes', 'cherry'] for item in zip(colors,fruits): print(item)
输出结果:
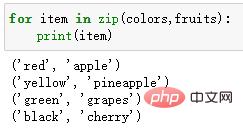
当我们使用zip()函数时,如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
prices =[100,50,120] for item in zip(colors,fruits,prices): print(item)

Filter 函数
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表,其语法如下所示[4]。
filter(function, iterable)
比如举个例子,我们可以先创建一个函数来检查单词是否为大写,然后使用filter()函数过滤出列表中的所有奇数:
def is_odd(n): return n % 2 == 1 old_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] new_list = filter(is_odd, old_list) print(newlist)
输出结果:

今天分享的这6个内置函数,在使用 Python 进行数据分析或者其他复杂的自动化任务时非常方便。
Das obige ist der detaillierte Inhalt vonSechs magische integrierte Funktionen in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
 So machen Sie Datenvorverarbeitung mit Pytorch auf CentOS
Apr 14, 2025 pm 02:15 PM
So machen Sie Datenvorverarbeitung mit Pytorch auf CentOS
Apr 14, 2025 pm 02:15 PM
Effizient verarbeiten Pytorch-Daten zum CentOS-System, die folgenden Schritte sind erforderlich: Abhängigkeit Installation: Aktualisieren Sie zuerst das System und installieren Sie Python3 und PIP: Sudoyumupdate-Judoyuminstallpython3-Tysudoyuminstallpython3-Pip-y, Download und installieren Sie Cudatoolkit und Cudnn-Model von der NVIDIA-offiziellen Website. Konfiguration der virtuellen Umgebung (empfohlen): Verwenden Sie Conda, um eine neue virtuelle Umgebung zu erstellen und zu aktivieren, zum Beispiel: condacreate-n
