


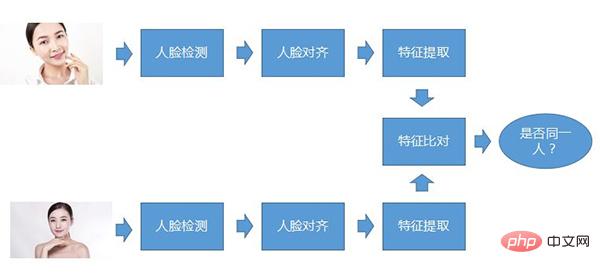
Um zwei Punkte zusammenzufassen: Erstens: Um dieselbe Person zu erkennen, unabhängig davon, wie sich Ihr Status ändert, können Sie wissen, dass Sie Sie selbst sind. Zweitens: Unterscheiden Sie verschiedene Personen. Möglicherweise sehen die beiden Personen sehr ähnlich aus oder beide Personen tragen Make-up. Unabhängig davon, wie sich der Status ändert, kann die Gesichtserkennung erkennen, dass es sich um zwei verschiedene Personen handelt.
Die Gesichtserkennung selbst ist eine Art biometrische Technologie, die hauptsächlich ein Mittel zur Identitätsauthentifizierung darstellt. In Bezug auf die Genauigkeit ist die Gesichtserkennung nicht die höchste. Die Gesichtserkennung wird durch viele andere Bedingungen beeinflusst, beispielsweise durch die Beleuchtung. Der Vorteil der Gesichtserkennung besteht darin, dass sie im Allgemeinen keine große Mitarbeit des Benutzers erfordert. Heutzutage sind Überwachungskameras an verschiedenen Orten, einschließlich Computerkameras, Videoeingabegeräten für Mobiltelefone und Kameraausrüstung, sehr beliebt geworden kann Gesichtserkennung durchführen. Daher kann die Neuinvestition bei der Einführung der Gesichtserkennung sehr gering sein, was ihr Vorteil ist.
Der Kernprozess der Gesichtserkennung Der sogenannte Kernprozess bedeutet, dass dieser Prozess grundsätzlich vorhanden ist, unabhängig von der Art des Gesichtserkennungssystems. Erstens, Gesichtserkennung, zweiter Schritt, Gesichtsausrichtung und dritter Schritt, Merkmalsextraktion. Beim Vergleich müssen die beiden Gesichter miteinander verglichen werden dieselbe Person.
Die Gesichtserkennung dient dazu, festzustellen, ob in einer großen Szene ein Gesicht vorhanden ist, die Position des Gesichts zu ermitteln und es auszuschneiden. Es handelt sich um eine Art Objekterkennungstechnologie und bildet die Grundlage für die gesamte Gesichtserkennungsaufgabe. Die grundlegende Methode der Gesichtserkennung besteht darin, das Fenster auf der Bildpyramide zu verschieben, mithilfe eines Klassifikators Kandidatenfenster auszuwählen und die Position mithilfe eines Regressionsmodells zu korrigieren.
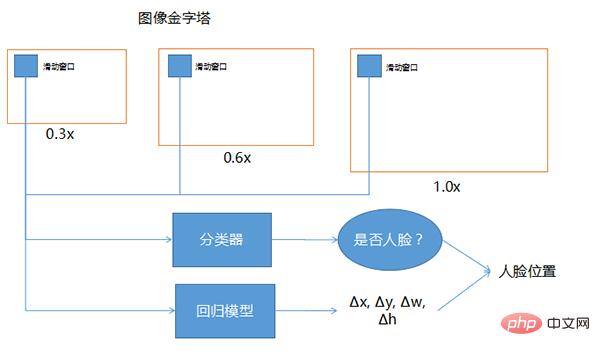
Die drei oben gezeichneten Fenster, eines ist 0,3-fach, 0,6-fach und 1,0-fach. Wenn die Position des Gesichts unsicher ist und die Größe nicht identifiziert werden kann, kann diese Technologie verwendet werden, um das Bild selbst anders zu gestalten Größen und das Schiebefenster sind gleich groß. Die Größe der Bildeingabe in das tiefe Netzwerk ist im Allgemeinen festgelegt, sodass das Schiebefenster vorne grundsätzlich festgelegt ist. Damit das feste Schiebefenster unterschiedliche Bereiche abdecken kann, wird die Größe des gesamten Bildes auf unterschiedliche Proportionen skaliert. Die hier gezeigten Werte 0,3, 0,6 und 1,0 sind nur Beispiele. In der Praxis kann es noch viele weitere unterschiedliche Vielfache geben.
Der Klassifikator bezieht sich auf die Betrachtung jeder Position des Schiebefensters, um festzustellen, ob es sich um ein Gesicht handelt, da die Position, an der das Schiebefenster gleitet, möglicherweise nicht das gesamte Gesicht umfasst oder größer als das gesamte Gesicht ist. Um genauere Gesichter zu finden, kann das Einfügen des Schiebefensters in das Regressionsmodell dabei helfen, die Genauigkeit der Gesichtserkennung zu korrigieren.
Bei der Eingabe handelt es sich um ein Schiebefenster, bei dem bei der Ausgabe angegeben wird, welche Richtung korrigiert werden soll und wie stark es korrigiert werden muss, also sind Δx, Δy, Δw, Δh seine Koordinaten und wie stark ist seine Breite Die Höhe sollte korrigiert werden. Nachdem Sie den Korrekturbetrag ermittelt und mithilfe des Klassifikators festgestellt haben, dass es sich um ein Fenster eines menschlichen Gesichts handelt, kann durch die Kombination dieser beiden eine genauere Position des menschlichen Gesichts ermittelt werden.
Das Obige ist der Prozess der Gesichtserkennung und kann auch auf die Erkennung anderer Objekte angewendet werden
Unabhängig von der Art des Modells ist es in zwei Aspekte unterteilt: Geschwindigkeit und Genauigkeit
(1) Geschwindigkeit ist die Erkennungsgeschwindigkeit bei der angegebenen Auflösung. Der Grund, warum die Auflösung angegeben wird, liegt darin, dass jedes Mal, wenn das Schiebefenster an eine Position verschoben wird, eine Klassifizierungs- und Regressionsbeurteilung vorgenommen werden muss Das Bild ist größer. Je größer die Anzahl der Fenster, desto länger dauert die gesamte Gesichtserkennung.
Um die Qualität eines Algorithmus oder Modells zu bewerten, muss man sich dessen Erkennungsgeschwindigkeit bei einer festen Auflösung ansehen. Welchen Wert wird diese Erkennungsgeschwindigkeit im Allgemeinen haben? Es kann die Zeit sein, die zum Erkennen des Gesichts eines Bildes benötigt wird, z. B. 100 Millisekunden, 200 Millisekunden, 50 Millisekunden, 30 Millisekunden usw.
Eine andere Möglichkeit, die Geschwindigkeit auszudrücken, sind heutzutage häufig 25 fps oder 30 fps, was bedeutet, wie viele Bilder pro Sekunde verarbeitet werden können. Der Vorteil von fps kann verwendet werden, um zu beurteilen, ob eine Gesichtserkennung möglich ist . Solange die FPS-Zahl der Gesichtserkennung größer ist als die FPS-Zahl der Kamera, kann dies in Echtzeit erreicht werden, andernfalls ist dies nicht möglich.
(2) Wird die Geschwindigkeit von der Anzahl der Gesichter im selben Bild beeinflusst? Die meisten davon werden nicht beeinflusst, da sie hauptsächlich von der Anzahl der Schiebefenster und der Anzahl der Treffer beeinflusst wird besonders schwer, hat aber eine leichte Wirkung.
Präzision wird im Wesentlichen durch die Rückrufrate, die Falscherkennungsrate und die ROC-Kurve bestimmt. Die Erinnerungsrate bezieht sich auf den Anteil des Fotos, der ein menschliches Gesicht darstellt, und das reale Modell bestimmt, dass es sich um ein menschliches Gesicht handelt. Die Falscherkennungsrate und die negative Stichprobenfehlerrate beziehen sich auf den Anteil des Fotos, der kein menschliches Gesicht darstellt Gesicht, wird aber fälschlicherweise als menschliches Gesicht eingeschätzt.
ACC-Genauigkeit
Die ACC-Berechnungsmethode besteht darin, die richtige Anzahl von Proben durch die Gesamtzahl der Proben zu dividieren. Nehmen Sie beispielsweise 10.000 Fotos zur Gesichtserkennung auf, andere nicht. von. Bestimmen Sie dann das richtige Verhältnis.
Aber es gibt ein Problem mit dieser Genauigkeit. Wenn Sie sie zur Beurteilung verwenden, ist sie für das Verhältnis von positiven und negativen Proben völlig irrelevant, d Negativproben, nur Pflege im Allgemeinen. Wenn die Genauigkeit dieses Modells 90 % beträgt, kennen andere den Unterschied zwischen positiven und negativen Proben nicht. Einschließlich der Klassifizierung, einschließlich der Regression, verwendet das Klassifizierungsmodell im Allgemeinen zunächst eine Regression, um ein sogenanntes Konfidenzniveau zu erhalten kleiner als der gleiche Wert ist, wird davon ausgegangen, dass dies nicht der Fall ist.
Das statistische ACC-Modell ist anpassbar, d. h. durch Anpassen des Konfidenzniveaus ändert sich die Genauigkeit.
Der ACC-Wert selbst wird also stark vom Anteil der Stichprobe beeinflusst, daher ist es etwas problematisch, ihn zur Charakterisierung der Qualität eines Modells zu verwenden, wenn der Testindikator angibt, dass er 99,9 % erreicht hat, wenn man nur diesen Wert betrachtet ist ein Vergleich, oder diese Statistik ist voreingenommen. Um dieses Problem zu lösen, wird im Allgemeinen eine Kurve namens ROC verwendet, um die Genauigkeit dieses Modells zu charakterisieren. ROC-Empfängerbetriebskennlinie. Abszisse: FPR (Falsch-Positiv-Rate), also der negative Stichprobenfehler Rate
Vertikale Koordinate: TPR (True Positive Rate), die korrekte Rate positiver Proben kann die Leistung des Algorithmus bei positiven Proben und negativen Proben unterscheiden, und die Form der Kurve hat nichts mit dem Verhältnis positiver Proben zu tun und Negativproben.
Die ROC-Kurve (Receiver Operating Characteristic) dient dazu, auf der Abszisse und auf der Ordinate die negative Probenfehlerrate und die positive Probenkorrekturrate zu markieren. In diesem Fall wird das gleiche Modell keinen Punkt in diesem Diagramm sehen, oder es ist nicht A einzelnes Datenelement, sondern eine Zeile. Diese Linie ist der Konfidenzschwellenwert. Je höher Sie ihn einstellen, desto strenger ist er, und je niedriger er ist, desto weniger streng ist er. Darüber hinaus kann es die Auswirkungen von Änderungen der Konfidenzschwelle widerspiegeln. 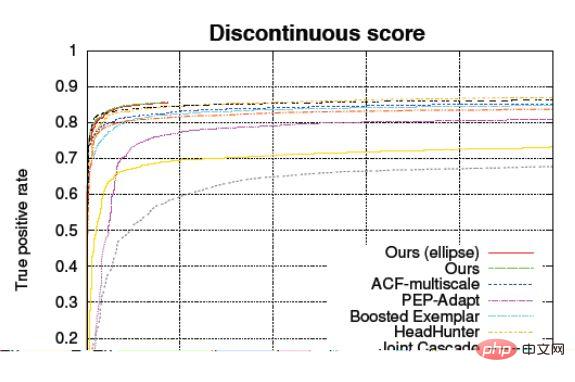
Der Zweck der Gesichtsausrichtung besteht darin, die Gesichtstextur so weit wie möglich an die Standardposition anzupassen und die Schwierigkeit der Gesichtserkennung zu verringern.
Um die Schwierigkeit künstlich zu verringern, können Sie es zunächst ausrichten, d. h. die erkannten Augen, die Nase und der Mund der Person befinden sich beim Vergleich des Modells alle in derselben Position Sucht man nach dem gleichen Ort, besteht immer noch ein großer Unterschied darin, ob sie gleich oder ähnlich sind. Daher können wir diesen Schritt der Ausrichtung durchführen. Die übliche Methode, die wir jetzt verwenden, besteht darin, die Schlüsselmerkmalspunkte in diesem Bild zu finden. und mehr als sechzig Punkte. Es gibt alle Arten von Spots, darunter mehr als 80 Spots. Aber für die Gesichtserkennung reichen grundsätzlich fünf.
Algorithmus zur Extraktion von Gesichtsmerkmalen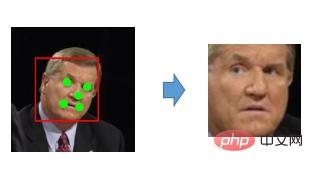
Kaskadierende tiefe neuronale Netze, das heißt, um das Gesicht zu erhalten, müssen Sie zunächst die Positionen von fünf Punkten ableiten. Wenn Sie dafür ein einzelnes Modell verwenden, muss dieses Modell sehr kompliziert sein.
Das heißt, nach der ersten Eingabe in das Netzwerk wird eine Schätzung durchgeführt, die jedoch weniger genau ist. Es weiß ungefähr, wo sich die fünf Punkte des menschlichen Gesichts befinden. Fügen Sie dann diese fünf Punkte und das Originalbild in das zweite Netzwerk ein, um den ungefähren Korrekturbetrag zu erhalten. Nachdem Sie die grundlegenden fünf Punkte ermittelt haben, ist es besser, die genauen fünf Punkte direkt aus dem Originalbild zu ermitteln. Dieser Punkt ist etwas einfacher. Daher kann durch die Verwendung dieser Methode der schrittweisen Verfeinerung und Kaskadierung mehrerer Netzwerke ein besseres Gleichgewicht zwischen Geschwindigkeit und Genauigkeit erreicht werden. Wenn wir dies jetzt tun, verwenden wir im Wesentlichen zwei Schichten und es ist ungefähr gleich.
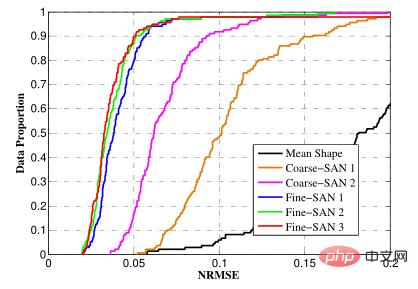
NRMSE (Normalisierter mittlerer quadratischer Fehler), der der normalisierte mittlere quadratische Fehler ist
, wird verwendet, um die Differenz zwischen den Koordinaten jedes Merkmalspunkts und dem beschrifteten zu messen Koordinaten.
Um den Vergleich von Gesichtern unterschiedlicher Größe zu ermöglichen, wird statistisch der sogenannte normalisierte quadratische Mittelfehler verwendet. Beispiel: Wir zeichnen fünf Punkte auf Papier und lassen dann die Maschine den Abstand zwischen diesen fünf Punkten ermitteln. Je näher der angegebene Wert am tatsächlichen Abstand liegt, desto genauer ist die Vorhersage. Im Allgemeinen weist der vorhergesagte Wert eine gewisse Abweichung auf. Wie kann dieser Genauigkeitswert ausgedrückt werden? Wir drücken es normalerweise durch den Durchschnittswert oder den quadratischen Mittelwert der Entfernung aus. Wenn jedoch dieselbe Maschine Bilder unterschiedlicher Größe vorhersagt, erscheinen die Genauigkeitswerte unterschiedlich, denn je größer das Bild, desto höher ist der absolute Wert des Fehlers. Das gleiche Prinzip gilt für Gesichter unterschiedlicher Größe. Daher besteht unsere Lösung darin, die ursprüngliche Größe des menschlichen Gesichts zu berücksichtigen. Im Allgemeinen ist der Nenner der Abstand zwischen den menschlichen Augen oder der diagonale Abstand des menschlichen Gesichts und dividiert dann den Abstandsunterschied durch den Abstand zwischen den Augen. oder durch die Diagonale des Gesichts dividieren. In diesem Fall können Sie einen Wert erhalten, der sich grundsätzlich nicht mit der Größe des Gesichts ändert, und ihn zur Bewertung verwenden.
(1) Zweck: Feststellen, ob zwei ausgerichtete Gesichter zur selben Person gehören
(2) Schwierigkeit: Das gleiche Gesicht zeigt in unterschiedlichen Situationen unterschiedliche Zustände, z. B. soll besonders von der Beleuchtung betroffen sein, Rauch, Make-up usw. Der zweite Grund liegt in der Zuordnung verschiedener Parameter zu zweidimensionalen Fotos. Die sogenannte Zuordnung zu zweidimensionalen Parametern bedeutet, dass das Originalgesicht so aussieht, wie es bei der Aufnahme des Bildes der Fall ist Die Entfernung von ihm und der Fokus haben Auswirkungen auf die Genauigkeit, den Aufnahmewinkel und die Lichtakkumulation, die dazu führen, dass dasselbe Gesicht in unterschiedlichen Zuständen erscheint. Der dritte ist der Einfluss des Alters und der plastischen Chirurgie.
(1) Traditionelle Methode
1 Manuelles Extrahieren einiger Merkmale wie HOG, SIFT, Wavelet-Transformation usw. Im Allgemeinen erfordern die extrahierten Merkmale möglicherweise feste Parameter, d. h. Kein Training oder Lernen ist erforderlich, verwenden Sie einfach einen festen Algorithmus und vergleichen Sie diese Funktion.
(2) Tiefenmethode
Die Mainstream-Methode ist die Tiefenmethode, also das tiefe Faltungs-Neuronale Netzwerk. Dieses Netzwerk verwendet im Allgemeinen DCNN, um die vorherigen Methoden zur Merkmalsextraktion zu ersetzen, also auf einem Bild Um einige verschiedene Merkmale im Gesicht einer Person herauszuarbeiten, gibt es in DCNN viele Parameter, die von Menschen gelernt und nicht erzählt werden.
Dann kann der erhaltene Satz von Merkmalen im Allgemeinen 128-dimensionale, 256-dimensionale oder 512-dimensionale oder 1024-dimensionale Dimensionen haben. Um den Abstand zwischen Merkmalsvektoren zu beurteilen, wird im Allgemeinen der euklidische Abstand oder die Kosinusähnlichkeit verwendet.
Die Bewertungsindikatoren für den Gesichtsvergleich sind auch in Geschwindigkeit und Genauigkeit unterteilt. Die Geschwindigkeit umfasst die Berechnungszeit eines einzelnen Gesichtsmerkmalsvektors und die Vergleichsgeschwindigkeit. Die Genauigkeit umfasst ACC und ROC. Da es bereits eingeführt wurde, konzentrieren wir uns hier auf die Vergleichsgeschwindigkeit.
Ein gewöhnlicher Vergleich ist eine einfache Operation, bei der der Abstand zwischen zwei Punkten berechnet wird. Möglicherweise müssen Sie nur einmal ein inneres Produkt durchführen, bei dem es sich um das innere Produkt zweier Vektoren handelt. Wenn die Gesichtserkennung jedoch auf einen 1:N-Vergleich stößt, Wenn die N-Bibliothek sehr groß ist und Sie ein Foto erhalten und es in der N-Bibliothek durchsuchen, ist die Anzahl der Suchvorgänge sehr groß. Wenn die N-Bibliothek beispielsweise eine Million umfasst, müssen Sie möglicherweise eine Million durchsuchen Dies entspricht einer Million Vergleichen. Derzeit gibt es noch Anforderungen für die Gesamtzeit, daher wird es verschiedene Technologien geben, um diesen Vergleich zu beschleunigen.
umfassen hauptsächlich Gesichtsverfolgung, Qualitätsbewertung und Erkennung lebender Körper.
● Gesichtsverfolgung
Wenn bei Überwachungs- und anderen Video-Gesichtserkennungsszenarien der gesamte Gesichtserkennungsprozess für jedes Bild derselben vorbeigehenden Person durchgeführt wird, verschwendet dies nicht nur Rechenressourcen, sondern kann auch zu einer schlechten Qualität führen Da Frames zu Fehlerkennungen führen, muss festgestellt werden, welche Gesichter derselben Person gehören. Und wählen Sie geeignete Fotos zur Erkennung aus, was die Gesamtleistung des Modells erheblich verbessert.
Heutzutage verwenden nicht nur die Gesichtsverfolgung, sondern auch verschiedene Objektverfolgungs- oder Fahrzeugverfolgungsalgorithmen Trackingalgorithmen, die nicht oder nicht immer auf Erkennung basieren. Nachdem beispielsweise ein Objekt zu Beginn erkannt wurde, wird es überhaupt nicht erkannt und verwendet nur den Tracking-Algorithmus, um dies zu tun. Gleichzeitig nimmt jedes Tracking viel Zeit in Anspruch, um eine sehr hohe Genauigkeit zu erreichen und Verluste zu vermeiden.
Um zu verhindern, dass das verfolgte Gesicht nicht mit der Reichweite der Gesichtserkennung übereinstimmt, wird im Allgemeinen ein Gesichtsdetektor zur Erkennung verwendet. In einigen Szenarien ist eine relativ einfache Gesichtserkennung erforderlich zwischen Geschwindigkeit und Qualität erreicht werden.
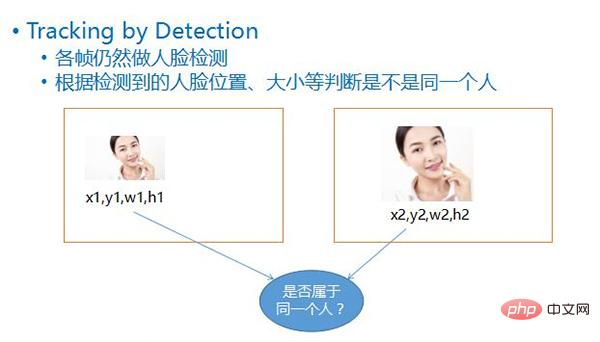
Diese Erkennungsmethode wird als Tracking by Detection bezeichnet. Das heißt, die Gesichtserkennung erfolgt weiterhin in jedem Bild, nachdem das Gesicht anhand der vier Werte jedes Gesichts, also seiner Koordinatenposition, erkannt wurde , seine Breite, Hoch, durch den Vergleich der Position und Größe des Gesichts in den beiden Frames davor und danach können Sie wahrscheinlich ableiten, ob die beiden Gesichter zum selben sich bewegenden Objekt gehören.
● Optionale Intervall-Vollbilderkennung
bedeutet, dass bei der Verfolgung durch Erkennung eine Vollbilderkennung für die beiden Bilder davor und danach durchgeführt werden kann. Die sogenannte Vollbilderkennung bedeutet, dass der gesamte Bildschirm gescannt wird. Diese Methode ist jedoch sehr zeitaufwändig, daher wird manchmal eine andere Methode verwendet, bei der alle paar Bilder ein Vollbild erstellt wird. Die Position wird sich nicht allzu sehr ändern die Position des vorherigen Frames nach oben, unten, links und rechts, und wenn wir versuchen, ihn erneut zu erkennen, besteht oft eine hohe Wahrscheinlichkeit, dass er erkannt wird, und die meisten Frames können übersprungen werden.
Warum müssen wir alle paar Bilder eine Vollbilderkennung durchführen?
Damit soll verhindert werden, dass neue Objekte eingehen. Wenn Sie nur anhand der Position des vorherigen Objekts suchen, kann es sein, dass neue Objekte beim Eintreffen nicht erkannt werden. Um dies zu verhindern, können Sie fünf oder zehn Bilder warten und versuchen Sie es erneut.
● Gesichtsqualitätsbewertung
Aufgrund der Einschränkungen der Gesichtserkennungs-Trainingsdaten usw. ist es unmöglich, bei Gesichtern in allen Staaten eine gute Leistung zu erbringen. Wählen Sie nur Gesichter mit einem hohen Grad an Übereinstimmung aus und senden Sie sie zur Erkennung, um die Gesamtleistung des Systems zu verbessern.
① Die Größe des Gesichts, das zur Erkennung verwendet wird, verringert den Erkennungseffekt erheblich.
② Die Gesichtshaltung bezieht sich auf den Drehwinkel in drei Achsen, der im Allgemeinen mit den für das Erkennungstraining verwendeten Daten zusammenhängt. Wenn während des Trainings die meisten Gesichter mit kleinen Körperhaltungen verwendet werden, ist es am besten, bei der eigentlichen Erkennung keine Gesichter mit großen Auslenkungen auszuwählen, da sie sonst nicht anwendbar sind.
③ Grad der Unschärfe, dieser Faktor ist sehr wichtig. Wenn das Foto Informationen verloren hat, kommt es zu Problemen bei der Erkennung.
④ Wenn Augen, Nase usw. abgedeckt sind, können die Merkmale dieses Bereichs nicht erfasst werden oder die erhaltenen Merkmale sind falsch. Es handelt sich um Merkmale eines Okklusionsobjekts, die sich auf die spätere Erkennung auswirken. Wenn festgestellt werden kann, dass es verdeckt ist, verwerfen Sie es oder führen Sie eine spezielle Verarbeitung durch, z. B. indem Sie es nicht in das Erkennungsmodell aufnehmen.
● Live-Erkennung
Dies ist ein Problem, das bei allen Gesichtserkennungssystemen auftritt. Wenn nur Gesichter erkannt werden, können auch Fotos weitergeleitet werden. Um zu verhindern, dass das System angegriffen wird, werden einige Beurteilungen vorgenommen, um festzustellen, ob es sich um ein echtes Gesicht oder ein falsches Gesicht handelt.
Grundsätzlich gibt es derzeit drei Methoden:
① Bei den Bargeldabhebungsautomaten vieler Banken muss der Benutzer kooperieren, z. B. indem er den Benutzer auffordert, zu blinzeln oder den Kopf zu drehen, um festzustellen, ob der Benutzer blinzelte oder nicht, drehte sich um und machte die gleiche Kooperation. Daher gibt es ein Problem mit der dynamischen Erkennung, das heißt, sie erfordert viel Mitarbeit des Benutzers, sodass die Benutzererfahrung etwas schlecht ist.
② Statische Erkennung bedeutet, nicht anhand von Handlungen zu urteilen, sondern lediglich anhand des Fotos selbst zu beurteilen, ob es sich um ein echtes Gesicht oder ein falsches Gesicht handelt. Es basiert auf häufig verwendeten Angriffsmethoden, die relativ praktisch sind. Nehmen Sie beispielsweise ein Mobiltelefon oder einen Bildschirm und verwenden Sie den Bildschirm zum Angriff.
Die Leuchtkraft dieser Art von Bildschirm unterscheidet sich von der Leuchtkraft eines menschlichen Gesichts unter tatsächlichen Lichtverhältnissen. Beispielsweise kann ein Monitor mit 16 Millionen Lichtfarben nicht die Leuchtkraft von sichtbarem Licht, also allen Bändern, erreichen sind fortlaufend. Alle können verschickt werden. Daher kann das menschliche Auge bei der Aufnahme dieser Art von Bildschirm im Vergleich zur primären Abbildung in der realen natürlichen Umgebung auch einige Veränderungen und einige Unnatürlichkeiten erkennen. Nachdem Sie diese Unnatürlichkeit in ein Trainingsmodell eingearbeitet haben, können Sie anhand dieses subtilen Unterschieds immer noch beurteilen, ob es sich um ein echtes Gesicht handelt.
③ Stereoerkennung: Wenn Sie zwei Kameras oder eine Kamera mit Tiefeninformationen verwenden, können Sie die Entfernung jedes erfassten Punkts von der Kamera ermitteln, was einer 3D-Bildgebung von Personen entspricht. Auf diese Weise können Sie einen Bildschirm verwenden Schießen Sie, und der Bildschirm muss eine flache Person sein. Erkennen Sie, dass es sich bei der flachen Person definitiv nicht um eine echte Person handelt. Dabei wird eine dreidimensionale Erkennungsmethode verwendet, um flache Gesichter auszuschließen.
Foto-1:1-Erkennungssystem
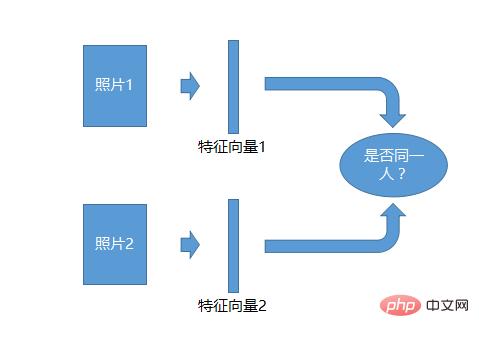 Das 1:1-Erkennungssystem ist das einfachste. Nehmen Sie zwei Fotos auf, generieren Sie für jedes Foto einen Merkmalsvektor und vergleichen Sie dann die beiden Merkmalsvektoren, um festzustellen, ob sie gleich sind. Einzelpersonen können identifiziert werden.
Das 1:1-Erkennungssystem ist das einfachste. Nehmen Sie zwei Fotos auf, generieren Sie für jedes Foto einen Merkmalsvektor und vergleichen Sie dann die beiden Merkmalsvektoren, um festzustellen, ob sie gleich sind. Einzelpersonen können identifiziert werden.
Foto 1: Erkennungssystem von N
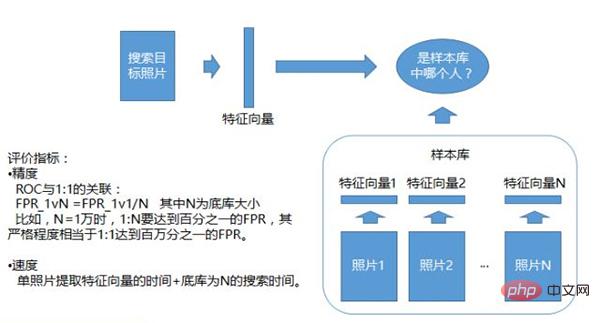 1: Erkennungssystem von N, das bestimmt, ob sich das Fotomaterial in derselben Beispielbibliothek befindet. Diese Beispielbibliothek wird im Voraus erstellt. Es kann eine Whitelist oder eine Blacklist geben. Von jeder Person wird eine Reihe von Merkmalsvektoren generiert. Dies dient als Beispielbibliothek. Die hochgeladenen Fotos werden mit allen Merkmalen in der Beispielbibliothek verglichen, um festzustellen, welches der Person am ähnlichsten ist.
1: Erkennungssystem von N, das bestimmt, ob sich das Fotomaterial in derselben Beispielbibliothek befindet. Diese Beispielbibliothek wird im Voraus erstellt. Es kann eine Whitelist oder eine Blacklist geben. Von jeder Person wird eine Reihe von Merkmalsvektoren generiert. Dies dient als Beispielbibliothek. Die hochgeladenen Fotos werden mit allen Merkmalen in der Beispielbibliothek verglichen, um festzustellen, welches der Person am ähnlichsten ist.
Video-1:1-Erkennungssystem
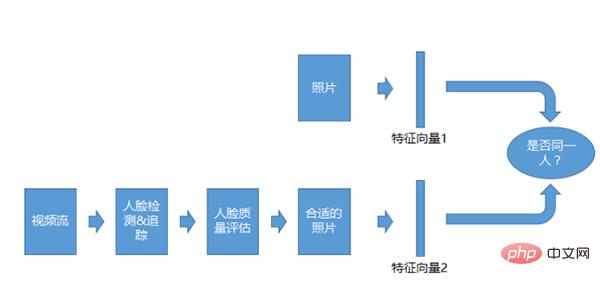 Das Video-1:1-Erkennungssystem ähnelt dem 1:1-System für Fotos, das Vergleichsobjekt sind jedoch keine Fotos, sondern Videostreams. Nachdem wir den Videostream erhalten haben, führen wir eine Erkennung, Verfolgung und Qualitätsbewertung durch und vergleichen ihn dann, nachdem wir die entsprechenden Fotos erhalten haben.
Das Video-1:1-Erkennungssystem ähnelt dem 1:1-System für Fotos, das Vergleichsobjekt sind jedoch keine Fotos, sondern Videostreams. Nachdem wir den Videostream erhalten haben, führen wir eine Erkennung, Verfolgung und Qualitätsbewertung durch und vergleichen ihn dann, nachdem wir die entsprechenden Fotos erhalten haben.
Video 1:N-Erkennungssystem
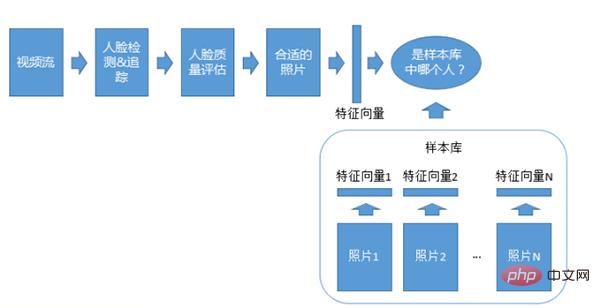 Das Video 1:N-Anpassungssystem ähnelt dem 1:N-Fotosystem, außer dass der Videostream zur Erkennung verwendet wird und auch Erkennung, Verfolgung und Qualität erforderlich sind .
Das Video 1:N-Anpassungssystem ähnelt dem 1:N-Fotosystem, außer dass der Videostream zur Erkennung verwendet wird und auch Erkennung, Verfolgung und Qualität erforderlich sind .
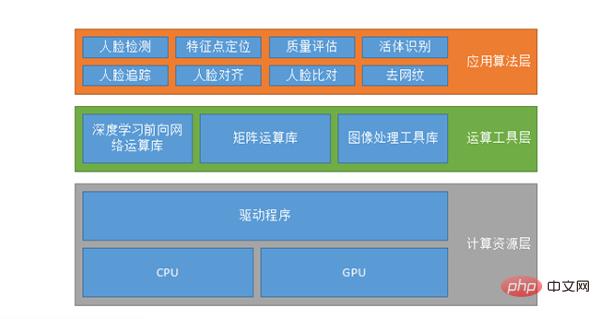 Die sogenannte Systemkonfiguration ist nicht unbedingt ein Gesichtserkennungssystem, sie ist wahrscheinlich für verschiedene KI-Systeme gleich. Die erste ist die Rechenressourcenschicht, die auf der CPU oder GPU ausgeführt wird und möglicherweise auch CUDA, CUDN usw. unterstützt.
Die sogenannte Systemkonfiguration ist nicht unbedingt ein Gesichtserkennungssystem, sie ist wahrscheinlich für verschiedene KI-Systeme gleich. Die erste ist die Rechenressourcenschicht, die auf der CPU oder GPU ausgeführt wird und möglicherweise auch CUDA, CUDN usw. unterstützt.
Die zweite ist die Computer-Tool-Schicht, einschließlich der Deep-Learning-Forward-Network-Computing-Bibliothek, der Matrix-Computing-Bibliothek und der Bildverarbeitungs-Tool-Bibliothek. Da es für jeden, der Algorithmen erstellt, unmöglich ist, Datenoperationen selbst zu schreiben, verwenden sie einige vorhandene Datenoperationsbibliotheken wie TensorFlow, MXNET oder Caffe usw. oder können ihren eigenen Satz schreiben.
Das obige ist der detaillierte Inhalt vonEin langer Artikel mit 10.000 Wörtern, populärwissenschaftlich über Gesichtserkennungsalgorithmen und -systeme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Algorithmus zum Ersetzen von Seiten
Algorithmus zum Ersetzen von Seiten
 Verwendung der Excel-Suchfunktion
Verwendung der Excel-Suchfunktion
 So entsperren Sie das Oppo-Telefon, wenn ich das Passwort vergessen habe
So entsperren Sie das Oppo-Telefon, wenn ich das Passwort vergessen habe
 So lösen Sie das Problem, dass der Druckprozessor nicht vorhanden ist
So lösen Sie das Problem, dass der Druckprozessor nicht vorhanden ist
 So registrieren Sie ein Bitcoin-Wallet
So registrieren Sie ein Bitcoin-Wallet
 So lösen Sie das Problem, dass document.cookie nicht abgerufen werden kann
So lösen Sie das Problem, dass document.cookie nicht abgerufen werden kann
 Die Rolle des Basis-Tags
Die Rolle des Basis-Tags
 Linux-Netzwerkkarte anzeigen
Linux-Netzwerkkarte anzeigen
 Lösung außerhalb des zulässigen Bereichs
Lösung außerhalb des zulässigen Bereichs








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



