

Im vorherigen Kapitel haben wir etwas über Iteratoren gelernt, die ein großartiges Werkzeug sind, insbesondere wenn Sie große Datenmengen verarbeiten müssen. Das Erstellen eigener Iteratoren in Python ist jedoch etwas umständlich und zeitaufwändig. Sie müssen eine neue Klasse definieren, die das Iteratorprotokoll implementiert (Methoden __iter__() und __next__()). In diesem Kurs müssen Sie den internen Status der Variablen selbst verwalten und aktualisieren. Wenn in der Methode __next__() kein zurückzugebender Wert vorhanden ist, muss außerdem eine StopIteration-Ausnahme ausgelöst werden.
Gibt es eine bessere Möglichkeit, es umzusetzen? Die Antwort ist ja! Dies ist die Generatorlösung von Python. Werfen wir einen Blick darauf.
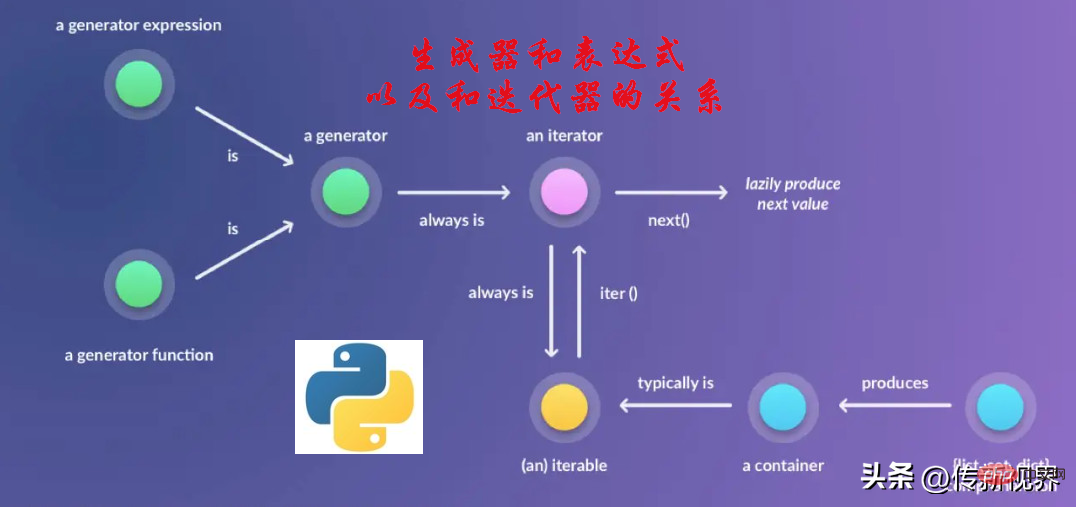
Um eigene Iteratoren effizienter zu erstellen, ist es schön, in Python eine elegante Lösung dafür zu haben. Der von Python bereitgestellte Generator (Generator) wird verwendet, um uns bei der einfachen Erstellung von Iteratoren zu helfen. Mit Generator können Sie eine Funktion deklarieren, die sich wie ein Iterator verhält, d. h. sie kann in einer for-Schleife verwendet werden. Einfach ausgedrückt ist ein Generator eine Funktion, die ein Iteratorobjekt zurückgibt. Dies ist also auch eine einfache Möglichkeit, einen Iterator zu erstellen. Beim Erstellen eines Iterators müssen Sie nicht über die gesamte erforderliche Arbeit nachdenken (wie das Iterationsprotokoll und den internen Status usw.), da der Generator alles übernimmt.
Als nächstes gehen wir noch einen Schritt weiter und lernen ganz einfach, wie Generatoren in Python funktionieren und wie man sie definiert.
Wie im vorherigen Abschnitt erwähnt, ist ein Generator eine spezielle Art von Funktion in Python. Diese Funktion gibt keinen einzelnen Wert zurück, sondern ein Iteratorobjekt. In einer Generatorfunktion verwendet der Rückgabewert eine Yield-Anweisung anstelle einer Return-Anweisung. Eine einfache Generatorfunktion ist unten definiert:
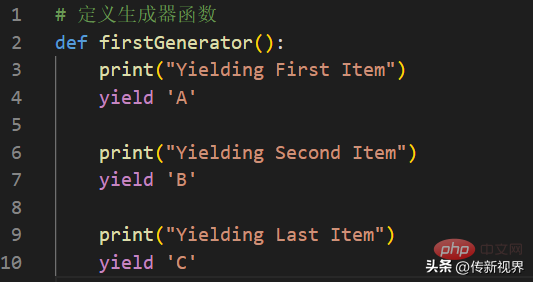
Codelistenfragment-01
In der obigen Liste definieren wir eine Generatorfunktion. Diese Funktion führt die yield-Anweisung anstelle des return-Schlüsselworts aus. Die yield-Anweisung macht diese Funktion zu einem Generator. Wenn wir diese Funktion aufrufen, gibt sie ein Iteratorobjekt zurück (erzeugt es). Werfen wir einen Blick auf den Aufruf des Generators:
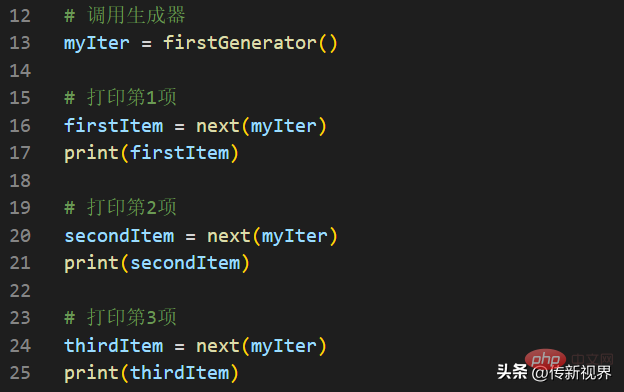
Code List Fragment-02
Der Aufruf eines Generators ähnelt normalerweise dem Erstellen eines Objekts, dem Aufrufen der Generatorfunktion und dem Zuweisen einer Variablen.
Die Ausgabe des Programmlaufs ist wie folgt:
Yielding First Item A Yielding Second Item B Yielding Last Item C
Im Anwendungsgeneratorcode rufen wir die Funktion firstGenerator() auf, die ein Generator ist und ein Iteratorobjekt zurückgibt. Wir nennen diesen Iterator myIter. Rufen Sie dann die Funktion next() für dieses Iteratorobjekt auf. Bei jedem next()-Aufruf führt der Iterator die yield-Anweisungen in ihrer jeweiligen Reihenfolge aus und gibt ein Element zurück.
Den Regeln zufolge sollte diese Generatorfunktion nicht das Schlüsselwort return enthalten. Denn wenn dies der Fall ist, beendet die Return-Anweisung die Funktion und die Iteratoranforderungen werden nicht erfüllt.
Jetzt definieren wir mithilfe einer for-Schleife einen praktischeren Generator. In diesem Beispiel definieren wir einen Generator, der kontinuierlich eine Zahlenfolge beginnend bei 0 bis zu einem bestimmten Höchstwert generiert.
Die Codeliste lautet wie folgt:
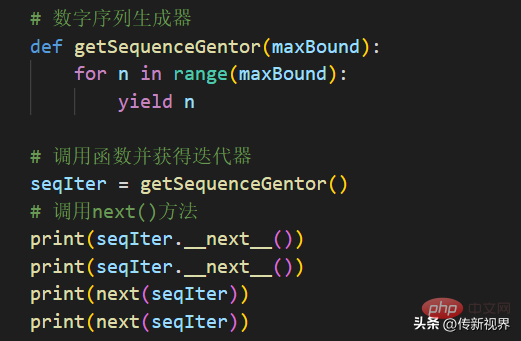
Codeliste Snippet-03
Die Ausgabe beim Ausführen des Programms ähnelt der folgenden:
0 1 2 3
In der obigen Auflistung definieren wir eine Generatorfunktion, die eine Ganzzahl generiert von 0 bis zu einer bestimmten Zahl. Wie Sie sehen können, befindet sich die yield-Anweisung innerhalb der for-Schleife. Beachten Sie, dass der Wert von n automatisch in aufeinanderfolgenden next()-Aufrufen gespeichert wird.
Zu beachten ist, dass beim Definieren eines Generators der Rückgabewert eine Yield-Anweisung sein muss. Dies bedeutet nicht, dass eine Return-Anweisung nicht in einem Generator erscheinen kann. Es ist nur so, dass die Return-Anweisung, die einen Nicht-None-Wert zurückgibt, normalerweise am Ende des Generators platziert wird, um der StopIteration-Ausnahme zusätzliche Informationen hinzuzufügen, damit der Aufrufer damit umgehen kann. Ein Beispiel lautet wie folgt:
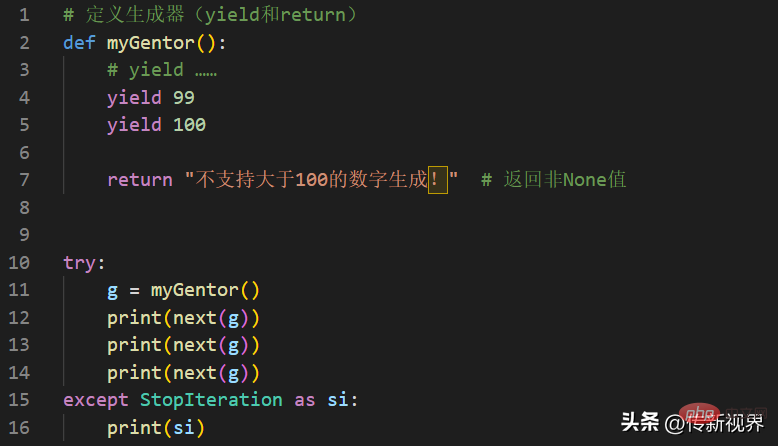
Codelistenfragment-04
Das Folgende ist das Ausgabeergebnis der Ausführung des Programms ohne Ausnahmebehandlung, das dem Folgenden ähnelt:
99 100 Traceback (most recent call last): File "……", line 11, in <module> print(next(g)) StopIteration: 不支持大于100的数字生成!
Wenn das Programm mit Ausnahmen abgefangen wird ( try-außer), die angezeigten Ergebnisse sind prägnanter, versuchen Sie es selbst auszuführen.
如果一个函数至少包含一个yield语句,那么它就是生成器函数。如果需要,还可以包含其他yield或return语句。yield和return关键字都将从函数中返回一些东西。
return和yield关键字之间的差异对于生成器来说非常重要。return语句会完全终止函数,而yield语句会暂停函数,保存它的所有状态,然后在后续的调用中继续执行。
我们调用生成器函数的方式和调用普通函数一样。但在执行过程中,生成器在遇到yield关键字时暂停。它将迭代器流的当前值发送到调用环境,并等待下一次调用。同时,它在内部保存局部变量及其状态。
以下是生成器函数与普通函数不同的关键点:
我们用一个简单的例子来演示普通函数和生成器函数之间的区别。在这个例子中,我们要计算前n个正整数的和。为此,我们将定义一个函数,该函数给出前n个正数的列表。我们将以两种方式实现这个函数,一个普通函数和一个生成器函数。
普通函数代码如下:
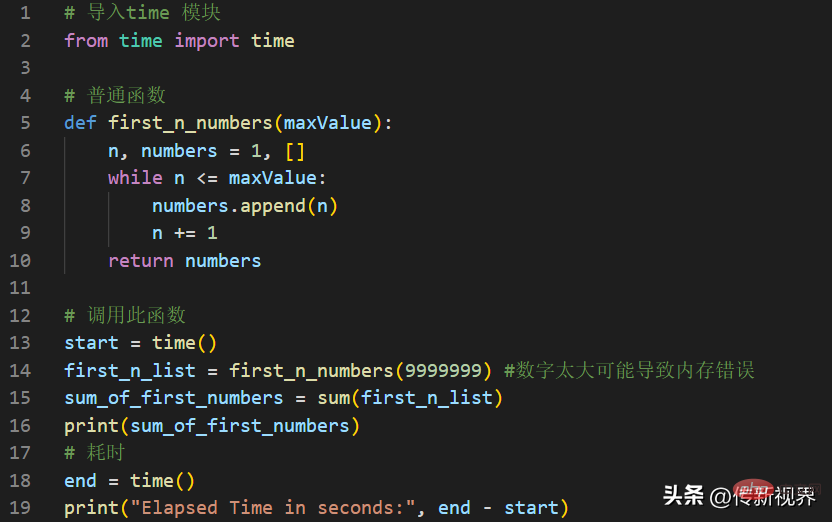
代码清单片段-05
运行程序输出结果类似如下:
49999995000000 Elapsed Time in seconds: 1.2067763805389404
在代码清单中,我们定义一个普通函数,它返回前n个正整数的列表。当我们调用这个函数时,它需要一段时间来完成执行,因为它创建的列表非常庞大。它还使用了大量内存来完成此任务。
现在让我们为相同的操作定义一个生成器函数来实现,代码清单如下:
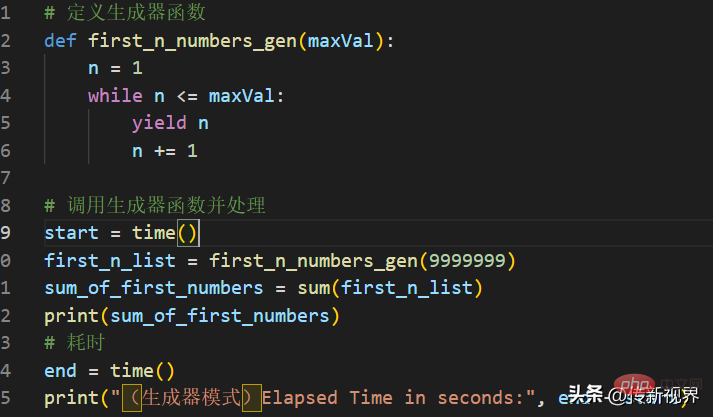
代码清单片段-06
运行程序结果类似如下:
49999995000000 (生成器模式)Elapsed Time in seconds: 1.0013225078582764
正如在生成器清单中所见,生成器在更短的时间内完成相同的任务,并且使用更少的内存资源。因为生成器是一个一个地生成项,而不是返回完整的列表。
性能改进的主要原因(当我们使用生成器时)是值的惰性生成。这种按需值生成的方式,会降低内存使用量。生成器的另一个优点是,你不需要等到所有元素都生成后才开始使用它们。
有时候,我们需要简单的生成器来执行代码中相对简单的任务。这正是生成器表达式(Generator Expression)用武之地。可以使用生成器表达式轻松地动态创建简单的生成器。
生成器表达式类似于Python中的lambda函数。但要记住,lambda是匿名函数,它允许我们动态地创建单行函数。就像lambda函数一样,生成器表达式创建的是匿名生成器函数。
生成器表达式的语法看起来像一个列表推导式。不同之处在于,我们在生成器表达式中使用圆括号而不是方括号。请看示例:
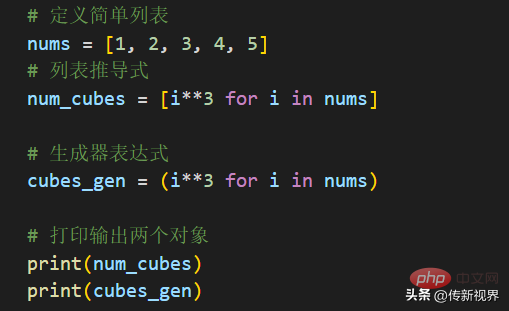
运行结果类似如下:
49999995000000 (生成器模式)Elapsed Time in seconds: 1.0013225078582764
在上述清单中,我们在生成器表达式的帮助下定义了一个简单的生成器。下面是语法:cubes_gen = (i**3 for i in nums)。你可以在输出中看到生成器对象。正如所已经知的,为了能够在生成器中获取项,我们要么显式调用next()方法,要么使用for循环遍历生成器。接下来就打印cubes_gen对象中的项:
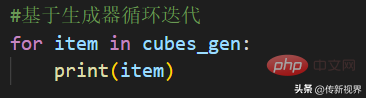
运行程序,遍历出的元素项结果是否和列表推导式一样。
我们再看一个例子。来定义一个生成器,将字符串中的字母转换为大写字母。然后调用next()方法打印前两个字母。代码示例如下:
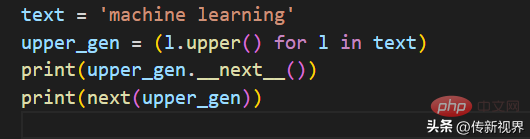
运行输出结果如下:
M A
生成器是非常棒的工具,特别是当需要在相对有限的内存中处理大型数据时。以下是在Python中使用生成器的一些主要好处:
1)内存效率:
假设有一个返回结果非常大序列的普通函数。例如,一个包含数百万项的列表。你必须等待这个函数完成所有的执行,并将整个列表返回给你。就时间和内存资源而言,这显然是低效的。另一方面,如果你使用生成器函数,它将一个一个地返回项,你将有机会继续执行下一行代码。而不需要等待函数执行列表中的所有项。因为生成器一次只给你一项。
2)延迟计算:
生成器提供了延迟(惰性)计算求值的功能。延迟计算是在真正需要值时计算值,而不是在实例化时计算值。假设你有一个大数据集要计算,延迟计算允许你在整个数据集仍在计算生成中可立即开始使用数据。因为如果使用生成器,则不需要整个数据集。
3)易实现和可读性:
生成器非常容易实现,并且提供了好的代码可读性。记住,如果你使用生成器,你不需要担心__iter__()和__next__()方法。你所需要的只是函数中一个简单的yield语句。
4)处理无限流:
当你需要表示无限的数据流时,生成器是非常棒的工具。例如,一个无限计数器。理论上,你不能在内存中存储无限流的,因为你无法确定存储无限流需要多少的内存大小。这是生成器真正发挥作用的地方,因为它一次只产生一项,它可以表示无限的数据流。它不需要将所有的数据流存储在内存中。
主要介绍了生成器相关知识,用于更好的自定义迭代器。内容包括何为生成器?如何自定义生成器以及和普通函数的关键区别?如何实现生成器表达式?并总结了生成器的有点。通过这篇文章,相信你能更轻松高效的掌握Python常规的生成器方方面面。
Das obige ist der detaillierte Inhalt vonPython-Programmierung: Wie bekomme ich Generatoren und Ausdrücke? Kommen Sie und servieren Sie es!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



