
 Backend-Entwicklung
Python-Tutorial
Ich habe Python verwendet, um meine WeChat-Freunde zu crawlen, sie sind so ...
Backend-Entwicklung
Python-Tutorial
Ich habe Python verwendet, um meine WeChat-Freunde zu crawlen, sie sind so ...
Ich habe Python verwendet, um meine WeChat-Freunde zu crawlen, sie sind so ...


Mit der Popularität von WeChat beginnen immer mehr Menschen, WeChat zu nutzen. WeChat hat sich nach und nach von einer einfachen sozialen Software zu einer Lebensart entwickelt. Menschen brauchen WeChat für die tägliche Kommunikation, und WeChat wird auch für die Arbeitskommunikation benötigt. Jeder Freund in WeChat repräsentiert eine andere Rolle, die Menschen in der Gesellschaft spielen.

Der heutige Artikel führt eine Datenanalyse zu WeChat-Freunden basierend auf Python durch. Die hier ausgewählten Hauptdimensionen sind: Geschlecht, Avatar, Signatur, Standort, hauptsächlich Die Die Ergebnisse werden in Form von Diagrammen und Wortwolken dargestellt. Für Textinformationen werden Worthäufigkeitsanalysen und Stimmungsanalysen verwendet. Wie das Sprichwort sagt: Wenn ein Arbeiter seine Arbeit gut machen will, muss er zuerst seine Werkzeuge schärfen. Bevor ich diesen Artikel offiziell beginne, möchte ich kurz die in diesem Artikel verwendeten Module von Drittanbietern vorstellen:
itchat: Die WeChat-Webversionsschnittstelle kapselt die Python-Version, die in diesem Artikel zum Abrufen von WeChat-Freundesinformationen verwendet wird .
jieba: Die Python-Version der stotternden Wortsegmentierung, die in diesem Artikel zum Segmentieren von Textinformationen verwendet wird.
matplotlib: Ein Diagrammzeichnungsmodul in Python, das in diesem Artikel zum Zeichnen von Säulendiagrammen und Kreisdiagrammen verwendet wird.
snownlp: Ein chinesisches Wortsegmentierungsmodul in Python, das in diesem Artikel verwendet wird Emotionale Urteile über Textinformationen fällen.
PIL: Bildverarbeitungsmodul in Python, das in diesem Artikel zum Verarbeiten von Bildern verwendet wird.
numpy: Numerisches Berechnungsmodul in Python, das in diesem Artikel in Verbindung mit dem Wordcloud-Modul verwendet wird.
wordcloud: Das Wortwolkenmodul in Python wird in diesem Artikel zum Zeichnen von Wortwolkenbildern verwendet.
TencentYoutuyun: Das von Tencent Youtu bereitgestellte Python-Versions-SDK wird in diesem Artikel verwendet, um Gesichter zu erkennen und Bild-Tag-Informationen zu extrahieren.
Die oben genannten Module können über pip installiert werden. Detaillierte Anweisungen zur Verwendung der einzelnen Module finden Sie in der jeweiligen Dokumentation.
1. Datenanalyse
Die Voraussetzung für die Analyse von WeChat-Freundesdaten ist die Verwendung des itchat-Moduls. Wir übergeben die folgenden beiden Zeilen Der Code kann implementiert werden:
itchat.auto_login(hotReload = True) friends = itchat.get_friends(update = True)
Genau wie beim Anmelden bei der Webversion von WeChat können wir uns anmelden, indem wir den QR-Code mit unserem Mobiltelefon scannen. Das hier zurückgegebene Freundesobjekt ist eine Sammlung. und das erste Element ist der aktuelle Benutzer. Daher verwenden wir im folgenden Datenanalyseprozess immer „friends[1:]“ als ursprüngliche Eingabedaten. Wenn Sie mich als Beispiel nehmen, können Sie feststellen, dass es „Geschlecht“, „Stadt“ und „Provinz“ gibt , HeadImgUrl und Signature sind vier Felder. Unsere folgende Analyse beginnt mit diesen vier Feldern:

2. Geschlecht des Freundes
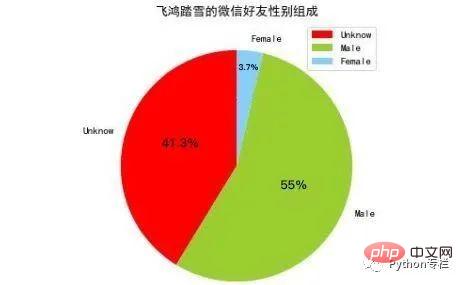
#🎜🎜 # Um das Geschlecht von Freunden zu analysieren, müssen wir zunächst die Geschlechtsinformationen aller Freunde abrufen. Hier extrahieren wir die Geschlechtsinformationen jedes Freundes und zählen dann die Zahlen von männlich, weiblich und unbekannt. Für eine Liste können Sie das Matplotlib-Modul verwenden, um ein Kreisdiagramm zu zeichnen. Der Code ist wie folgt implementiert:def analyseSex(firends): sexs = list(map(lambda x:x['Sex'],friends[1:])) counts = list(map(lambda x:x[1],Counter(sexs).items())) labels = ['Unknow','Male','Female'] colors = ['red','yellowgreen','lightskyblue'] plt.figure(figsize=(8,5), dpi=80) plt.axes(aspect=1) plt.pie(counts, #性别统计结果 labels=labels, #性别展示标签 colors=colors, #饼图区域配色 labeldistance = 1.1, #标签距离圆点距离 autopct = '%3.1f%%', #饼图区域文本格式 shadow = False, #饼图是否显示阴影 startangle = 90, #饼图起始角度 pctdistance = 0.6 #饼图区域文本距离圆点距离 ) plt.legend(loc='upper right',) plt.title(u'%s的微信好友性别组成' % friends[0]['NickName']) plt.show()
def analyseHeadImage(frineds):
# Init Path
basePath = os.path.abspath('.')
baseFolder = basePath + '\HeadImages\'
if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open('face.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()这里我们会在当前目录新建一个HeadImages目录,用于存储所有好友的头像,然后我们这里会用到一个名为FaceApi类,这个类由腾讯优图的SDK封装而来,这里分别调用了人脸检测和图像标签识别两个API接口,前者会统计”使用人脸头像”和”不使用人脸头像”的好友各自的数目,后者会累加每个头像中提取出来的标签。其分析结果如下图所示:
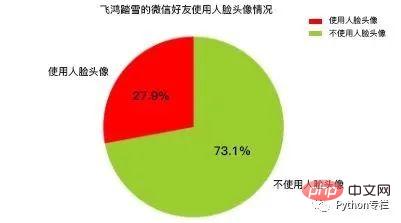
可以注意到,在所有微信好友中,约有接近1/4的微信好友使用了人脸头像, 而有接近3/4的微信好友没有人脸头像,这说明在所有微信好友中对”颜值 “有自信的人,仅仅占到好友总数的25%,或者说75%的微信好友行事风格偏低调为主,不喜欢用人脸头像做微信头像。
其次,考虑到腾讯优图并不能真正的识别”人脸”,我们这里对好友头像中的标签再次进行提取,来帮助我们了解微信好友的头像中有哪些关键词,其分析结果如图所示:

通过词云,我们可以发现:在微信好友中的签名词云中,出现频率相对较高的关键字有:女孩、树木、房屋、文本、截图、卡通、合影、天空、大海。这说明在我的微信好友中,好友选择的微信头像主要有日常、旅游、风景、截图四个来源。
好友选择的微信头像中风格以卡通为主,好友选择的微信头像中常见的要素有天空、大海、房屋、树木。通过观察所有好友头像,我发现在我的微信好友中,使用个人照片作为微信头像的有15人,使用网络图片作为微信头像的有53人,使用动漫图片作为微信头像的有25人,使用合照图片作为微信头像的有3人,使用孩童照片作为微信头像的有5人,使用风景图片作为微信头像的有13人,使用女孩照片作为微信头像的有18人,基本符合图像标签提取的分析结果。
4. 好友签名
分析好友签名,签名是好友信息中最为丰富的文本信息,按照人类惯用的”贴标签”的方法论,签名可以分析出某一个人在某一段时间里状态,就像人开心了会笑、哀伤了会哭,哭和笑两种标签,分别表明了人开心和哀伤的状态。
这里我们对签名做两种处理,第一种是使用结巴分词进行分词后生成词云,目的是了解好友签名中的关键字有哪些,哪一个关键字出现的频率相对较高;第二种是使用SnowNLP分析好友签名中的感情倾向,即好友签名整体上是表现为正面的、负面的还是中立的,各自的比重是多少。这里提取Signature字段即可,其核心代码如下:
def analyseSignature(friends):
signatures = ''
emotions = []
pattern = re.compile("1fd.+")
for friend in friends:
signature = friend['Signature']
if(signature != None):
signature = signature.strip().replace('span', '').replace('class', '').replace('emoji', '')
signature = re.sub(r'1f(d.+)','',signature)
if(len(signature)>0):
nlp = SnowNLP(signature)
emotions.append(nlp.sentiments)
signatures += ' '.join(jieba.analyse.extract_tags(signature,5))
with open('signatures.txt','wt',encoding='utf-8') as file:
file.write(signatures)
# Sinature WordCloud
back_coloring = np.array(Image.open('flower.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=960,
height=720,
margin=15
)
wordcloud.generate(signatures)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('signatures.jpg')
# Signature Emotional Judgment
count_good = len(list(filter(lambda x:x>0.66,emotions)))
count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions)))
count_bad = len(list(filter(lambda x:x<0.33,emotions)))
labels = [u'负面消极',u'中性',u'正面积极']
values = (count_bad,count_normal,count_good)
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel(u'情感判断')
plt.ylabel(u'频数')
plt.xticks(range(3),labels)
plt.legend(loc='upper right',)
plt.bar(range(3), values, color = 'rgb')
plt.title(u'%s的微信好友签名信息情感分析' % friends[0]['NickName'])
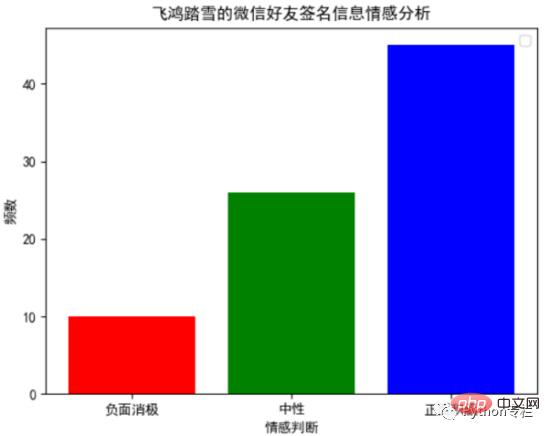
plt.show()通过词云,我们可以发现:在微信好友的签名信息中,出现频率相对较高的关键词有:努力、长大、美好、快乐、生活、幸福、人生、远方、时光、散步。

通过以下柱状图,我们可以发现:在微信好友的签名信息中,正面积极的情感判断约占到55.56%,中立的情感判断约占到32.10%,负面消极的情感判断约占到12.35%。这个结果和我们通过词云展示的结果基本吻合,这说明在微信好友的签名信息中,约有87.66%的签名信息,传达出来都是一种积极向上的态度。
5. 好友位置
分析好友位置,主要通过提取Province和City这两个字段。Python中的地图可视化主要通过Basemap模块,这个模块需要从国外网站下载地图信息,使用起来非常的不便。
百度的ECharts在前端使用的比较多,虽然社区里提供了pyecharts项目,可我注意到因为政策的改变,目前Echarts不再支持导出地图的功能,所以地图的定制方面目前依然是一个问题,主流的技术方案是配置全国各省市的JSON数据。
这里我使用的是BDP个人版,这是一个零编程的方案,我们通过Python导出一个CSV文件,然后将其上传到BDP中,通过简单拖拽就可以制作可视化地图,简直不能再简单,这里我们仅仅展示生成CSV部分的代码:
def analyseLocation(friends):
headers = ['NickName','Province','City']
with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:
writer = csv.DictWriter(csvFile, headers)
writer.writeheader()
for friend in friends[1:]:
row = {}
row['NickName'] = friend['NickName']
row['Province'] = friend['Province']
row['City'] = friend['City']
writer.writerow(row)下图是BDP中生成的微信好友地理分布图,可以发现:我的微信好友主要集中在宁夏和陕西两个省份。
6. 总结
这篇文章是我对数据分析的又一次尝试,主要从性别、头像、签名、位置四个维度,对微信好友进行了一次简单的数据分析,主要采用图表和词云两种形式来呈现结果。总而言之一句话,”数据可视化是手段而并非目的”,重要的不是我们在这里做了这些图出来,而是从这些图里反映出来的现象,我们能够得到什么本质上的启示,希望这篇文章能让大家有所启发。
Das obige ist der detaillierte Inhalt vonIch habe Python verwendet, um meine WeChat-Freunde zu crawlen, sie sind so .... Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
 So machen Sie Datenvorverarbeitung mit Pytorch auf CentOS
Apr 14, 2025 pm 02:15 PM
So machen Sie Datenvorverarbeitung mit Pytorch auf CentOS
Apr 14, 2025 pm 02:15 PM
Effizient verarbeiten Pytorch-Daten zum CentOS-System, die folgenden Schritte sind erforderlich: Abhängigkeit Installation: Aktualisieren Sie zuerst das System und installieren Sie Python3 und PIP: Sudoyumupdate-Judoyuminstallpython3-Tysudoyuminstallpython3-Pip-y, Download und installieren Sie Cudatoolkit und Cudnn-Model von der NVIDIA-offiziellen Website. Konfiguration der virtuellen Umgebung (empfohlen): Verwenden Sie Conda, um eine neue virtuelle Umgebung zu erstellen und zu aktivieren, zum Beispiel: condacreate-n
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
