
 Backend-Entwicklung
Python-Tutorial
Zehn häufig verwendete Verlustfunktionserklärungen und Python-Codeimplementierungen
Backend-Entwicklung
Python-Tutorial
Zehn häufig verwendete Verlustfunktionserklärungen und Python-Codeimplementierungen
Zehn häufig verwendete Verlustfunktionserklärungen und Python-Codeimplementierungen

Was ist die Verlustfunktion?
Die Verlustfunktion ist ein Algorithmus, der den Grad der Übereinstimmung zwischen dem Modell und den Daten misst. Eine Verlustfunktion ist eine Möglichkeit, die Differenz zwischen tatsächlichen Messungen und vorhergesagten Werten zu messen. Je höher der Wert der Verlustfunktion, desto fehlerhafter ist die Vorhersage, und je niedriger der Wert der Verlustfunktion, desto näher liegt die Vorhersage am wahren Wert. Die Verlustfunktion wird für jede einzelne Beobachtung (Datenpunkt) berechnet. Die Funktion, die die Werte aller Verlustfunktionen mittelt, wird als Kostenfunktion bezeichnet. Ein einfacheres Verständnis besteht darin, dass die Verlustfunktion für eine einzelne Stichprobe gilt, während die Kostenfunktion für alle Stichproben gilt.
Verlustfunktionen und Metriken
Einige Verlustfunktionen können auch als Bewertungsmetriken verwendet werden. Aber Verlustfunktionen und Metriken haben unterschiedliche Zwecke. Während Metriken verwendet werden, um das endgültige Modell zu bewerten und die Leistung verschiedener Modelle zu vergleichen, wird die Verlustfunktion während der Modellerstellungsphase als Optimierer für das zu erstellende Modell verwendet. Die Verlustfunktion leitet das Modell an, wie der Fehler minimiert werden kann.
Das heißt, die Verlustfunktion weiß, wie das Modell trainiert wird, und der Messindex erklärt die Leistung des Modells.
Warum eine Verlustfunktion verwenden?
Da die Verlustfunktion die Differenz zwischen dem vorhergesagten Wert und dem tatsächlichen Wert misst, können sie als Leitfaden für das Modelltraining verwendet werden . Verbesserung (die übliche Gradientenabstiegsmethode). Wenn sich beim Erstellen des Modells das Gewicht des Merkmals ändert und bessere oder schlechtere Vorhersagen getroffen werden, müssen Sie die Verlustfunktion verwenden, um zu beurteilen, ob das Gewicht des Merkmals im Modell geändert werden muss und in welche Richtung die Änderung geht .
Wir können beim maschinellen Lernen verschiedene Verlustfunktionen verwenden, abhängig von der Art des Problems, das wir lösen möchten, der Datenqualität und -verteilung sowie dem von uns verwendeten Algorithmus habe 10 gängige Verlustfunktionen zusammengestellt:
Regressionsproblem
1 Mittlerer quadratischer Fehler (MSE)
# 🎜🎜#Der mittlere quadratische Fehler bezieht sich auf die quadrierte Differenz zwischen allen vorhergesagten Werten und dem wahren Wert und mittelt diese. Wird oft bei Regressionsproblemen verwendet.def MSE (y, y_predicted):sq_error = (y_predicted - y) ** 2sum_sq_error = np.sum(sq_error)mse = sum_sq_error/y.sizereturn mse
def MAE (y, y_predicted):error = y_predicted - yabsolute_error = np.absolute(error)total_absolute_error = np.sum(absolute_error)mae = total_absolute_error/y.sizereturn mae
def RMSE (y, y_predicted):sq_error = (y_predicted - y) ** 2total_sq_error = np.sum(sq_error)mse = total_sq_error/y.sizermse = math.sqrt(mse)return rmse
def MBE (y, y_predicted):error = y_predicted - ytotal_error = np.sum(error)mbe = total_error/y.sizereturn mbe
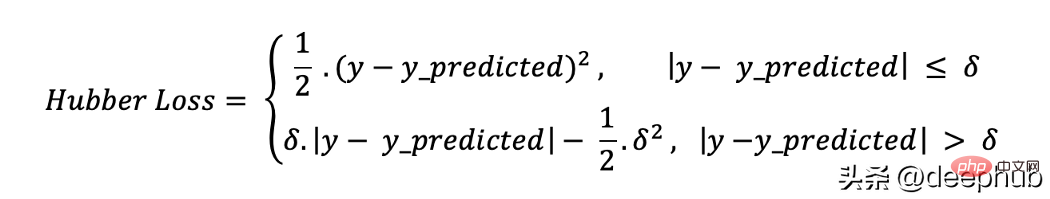

def hubber_loss (y, y_predicted, delta)delta = 1.35 * MAEy_size = y.sizetotal_error = 0for i in range (y_size):erro = np.absolute(y_predicted[i] - y[i])if error < delta:hubber_error = (error * error) / 2else:hubber_error = (delta * error) / (0.5 * (delta * delta))total_error += hubber_errortotal_hubber_error = total_error/y.sizereturn total_hubber_error
6. Maximum-Likelihood-Verlust (Likelihood Loss/LHL)
Diese Verlustfunktion wird hauptsächlich für binäre Klassifizierungsprobleme verwendet. Die Wahrscheinlichkeit jedes vorhergesagten Werts wird multipliziert, um einen Verlustwert zu erhalten, und die zugehörige Kostenfunktion ist der Durchschnitt aller beobachteten Werte. Nehmen wir das folgende Beispiel einer binären Klassifizierung, bei der die Klasse [0] oder [1] ist. Wenn die Ausgabewahrscheinlichkeit gleich oder größer als 0,5 ist, ist die vorhergesagte Klasse [1], andernfalls ist sie [0]. Ein Beispiel für die Ausgabewahrscheinlichkeit lautet wie folgt:
[0.3, 0.7, 0.8, 0.5, 0.6, 0.4]
Die entsprechende Vorhersageklasse ist:
# 🎜🎜#[ 0 , 1 , 1 , 1 , 1 , 0]Und die eigentliche Klasse ist: [0 , 1 , 1 , 0 , 1 , 0 ]#🎜🎜 #Der Verlust wird nun anhand der wahren Klassen- und Ausgabewahrscheinlichkeiten berechnet. Wenn die wahre Klasse [1] ist, verwenden wir die Ausgabewahrscheinlichkeit, wenn die wahre Klasse [0] ist, verwenden wir die 1-Wahrscheinlichkeit:
((1–0,3)+0,7+0,8+ (1–0,5 )+0,6+(1–0,4)) / 6 = 0,65
Der Python-Code lautet wie folgt:
def LHL (y, y_predicted):likelihood_loss = (y * y_predicted) + ((1-y) * (y_predicted))total_likelihood_loss = np.sum(likelihood_loss)lhl = - total_likelihood_loss / y.sizereturn lhl
7, Binary Cross Entropy (BCE)
#🎜 🎜#Diese Funktion ist eine Modifikation des logarithmischen Likelihood-Verlusts. Das Stapeln von Zahlenfolgen kann sehr sichere, aber falsche Vorhersagen benachteiligen. Die allgemeine Formel der binären Kreuzentropieverlustfunktion lautet: – (y . log (p) + (1 – y) . log (1 – p))# 🎜🎜#Lassen Sie uns weiterhin die Werte aus dem obigen Beispiel verwenden:
Ausgabewahrscheinlichkeit = [0,3, 0,7, 0,8, 0,5, 0,6, 0,4]
Tatsächlich Klasse = [0, 1, 1 , 0, 1, 0]
– (0 . log (0,3) + (1–0) . log (1–0,3)) = 0,155#🎜🎜 #
— (1 . log(0.7) + (1–1) . log (0.3)) = 0.155
— (1 . log(0.8) + (1–1) . log (0.2)) = 0.097
— (0 . log (0.5) + (1–0) . log (1–0.5)) = 0.301
— (1 . log(0.6) + (1–1) . log (0.4)) = 0.222
— (0 . log (0.4) + (1–0) . log (1–0.4)) = 0.222
那么代价函数的结果为:
(0.155 + 0.155 + 0.097 + 0.301 + 0.222 + 0.222) / 6 = 0.192
Python的代码如下:
def BCE (y, y_predicted):ce_loss = y*(np.log(y_predicted))+(1-y)*(np.log(1-y_predicted))total_ce = np.sum(ce_loss)bce = - total_ce/y.sizereturn bce
8、Hinge Loss 和 Squared Hinge Loss (HL and SHL)
Hinge Loss被翻译成铰链损失或者合页损失,这里还是以英文为准。
Hinge Loss主要用于支持向量机模型的评估。错误的预测和不太自信的正确预测都会受到惩罚。 所以一般损失函数是:
l(y) = max (0 , 1 — t . y)
这里的t是真实结果用[1]或[-1]表示。
使用Hinge Loss的类应该是[1]或[-1](不是[0])。为了在Hinge loss函数中不被惩罚,一个观测不仅需要正确分类而且到超平面的距离应该大于margin(一个自信的正确预测)。如果我们想进一步惩罚更高的误差,我们可以用与MSE类似的方法平方Hinge损失,也就是Squared Hinge Loss。
如果你对SVM比较熟悉,应该还记得在SVM中,超平面的边缘(margin)越高,则某一预测就越有信心。如果这块不熟悉,则看看这个可视化的例子:
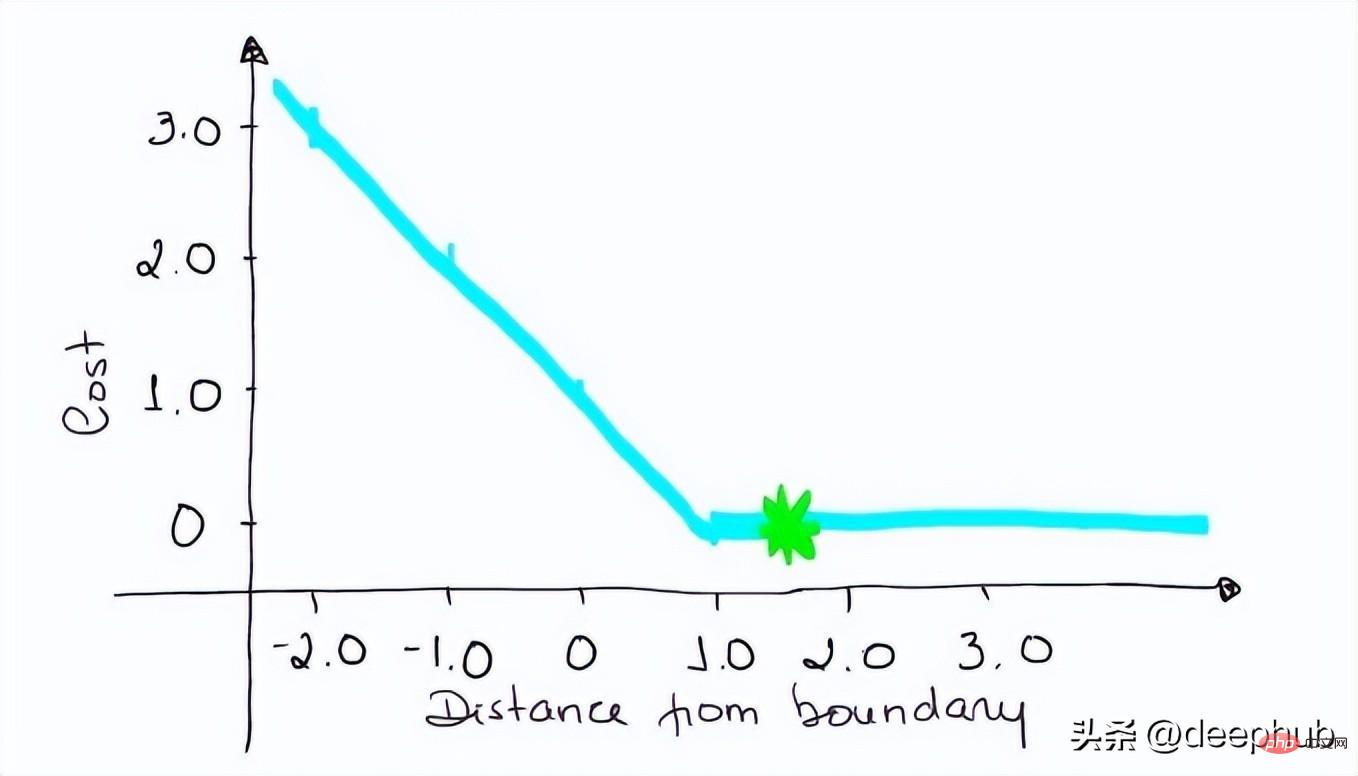
如果一个预测的结果是1.5,并且真正的类是[1],损失将是0(零),因为模型是高度自信的。
loss= Max (0,1 - 1* 1.5) = Max (0, -0.5) = 0
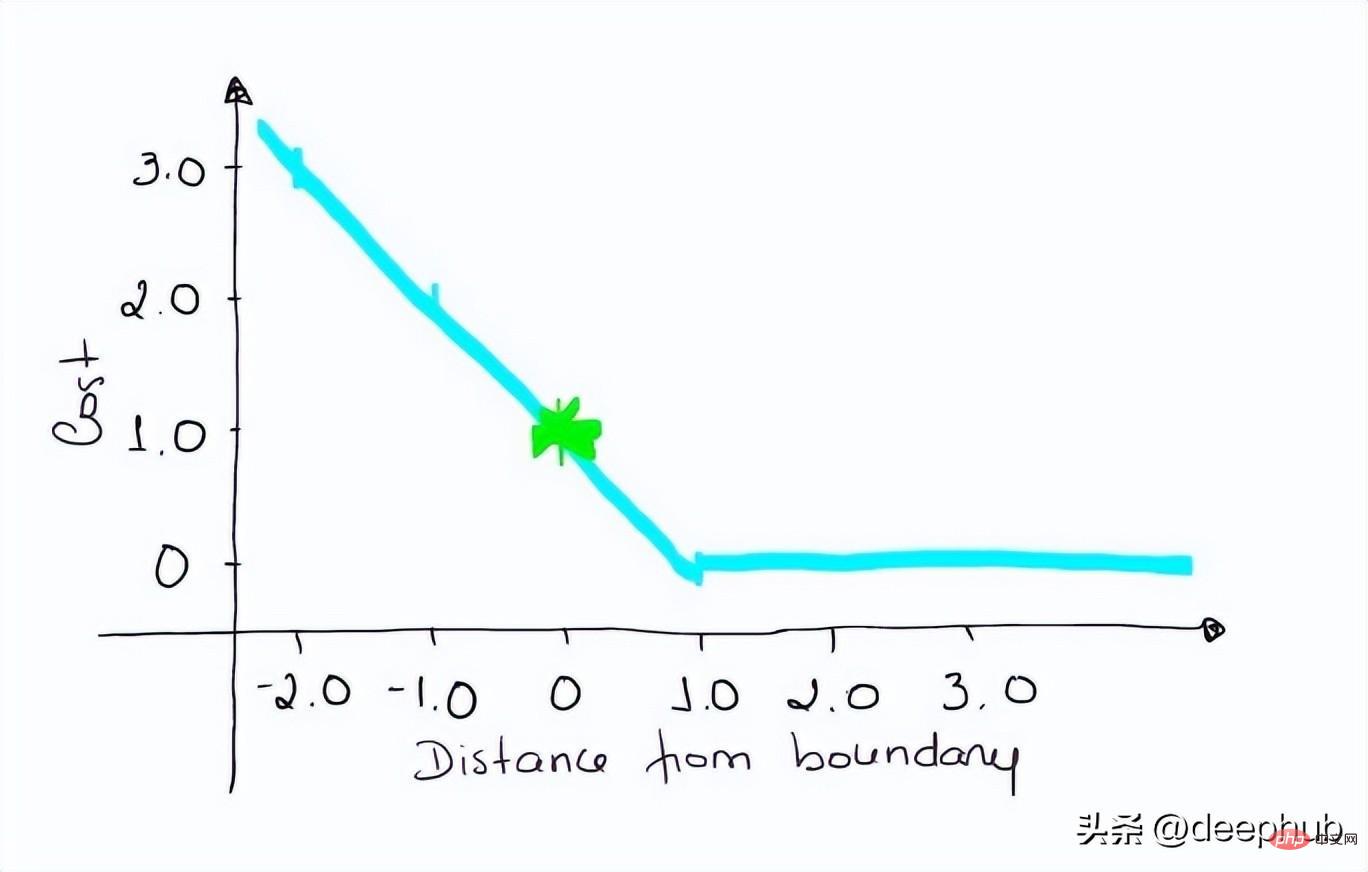
如果一个观测结果为0(0),则表示该观测处于边界(超平面),真实的类为[-1]。损失为1,模型既不正确也不错误,可信度很低。
loss = max (0 , 1–(-1) * 0) = max (0 , 1) = 1
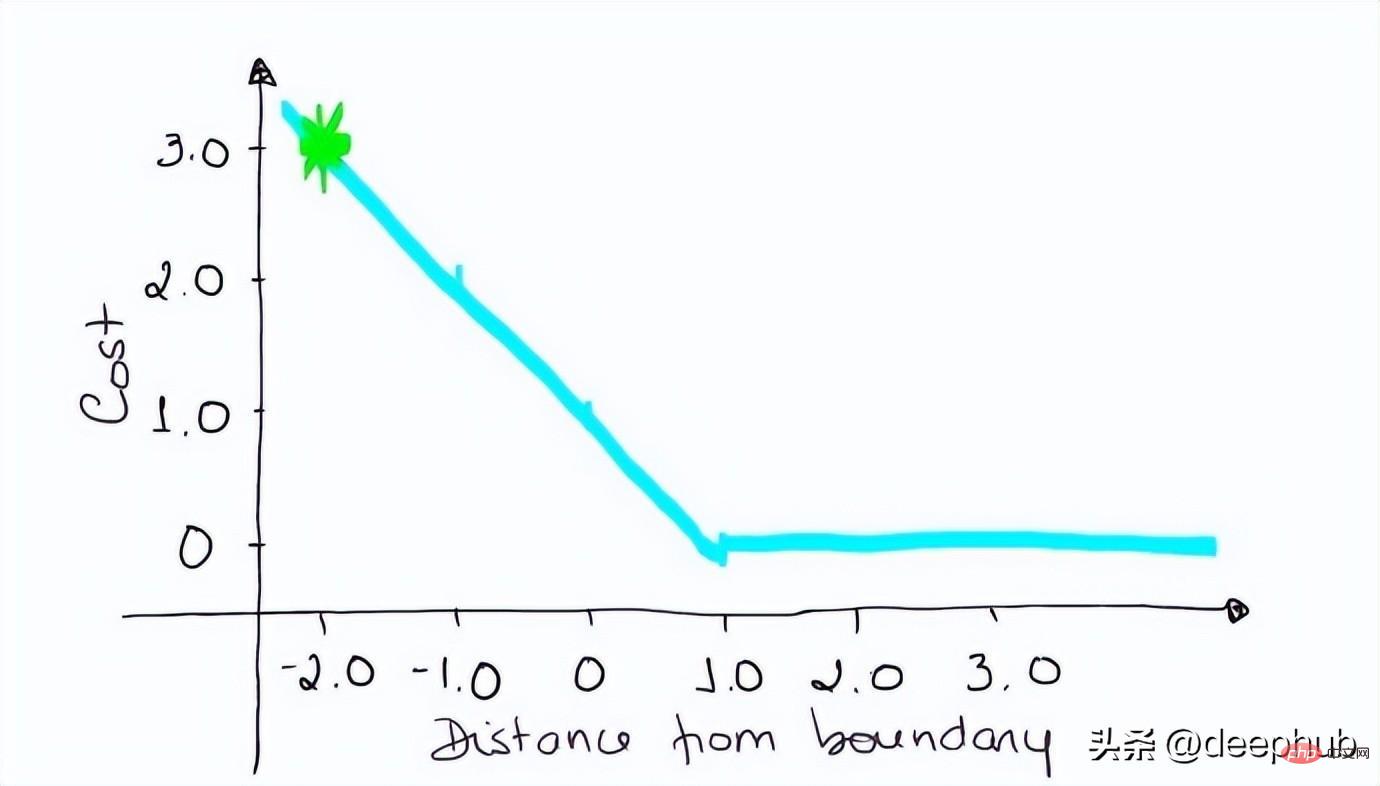
如果一次观测结果为2,但分类错误(乘以[-1]),则距离为-2。损失是3(非常高),因为我们的模型对错误的决策非常有信心(这个是绝不能容忍的)。
loss = max (0 , 1 — (-1) . 2) = max (0 , 1+2) = max (0 , 3) = 3
python代码如下:
#Hinge Lossdef Hinge (y, y_predicted):hinge_loss = np.sum(max(0 , 1 - (y_predicted * y)))return hinge_loss#Squared Hinge Lossdef SqHinge (y, y_predicted):sq_hinge_loss = max (0 , 1 - (y_predicted * y)) ** 2total_sq_hinge_loss = np.sum(sq_hinge_loss)return total_sq_hinge_loss
多分类
9、交叉熵(CE)
在多分类中,我们使用与二元交叉熵类似的公式,但有一个额外的步骤。首先需要计算每一对[y, y_predicted]的损失,一般公式为:
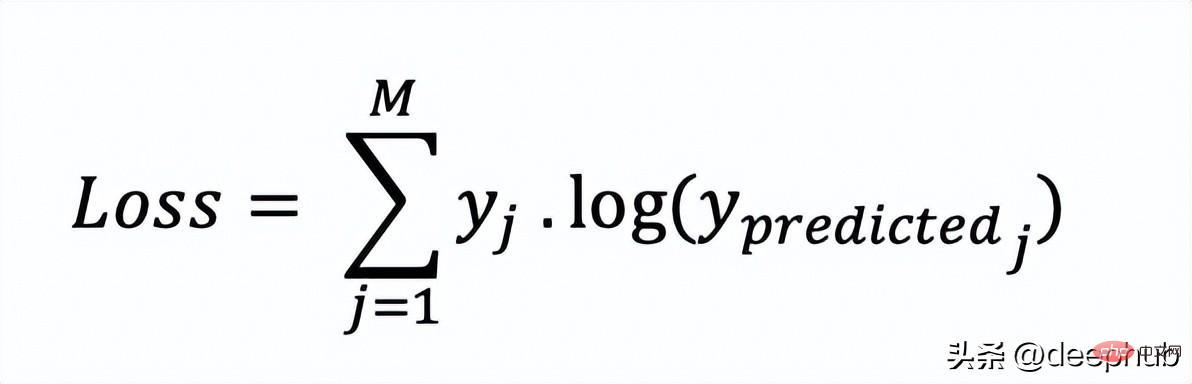
如果我们有三个类,其中单个[y, y_predicted]对的输出是:

这里实际的类3(也就是值=1的部分),我们的模型对真正的类是3的信任度是0.7。计算这损失如下:
Loss = 0 . log (0.1) + 0 . log (0.2) + 1 . log (0.7) = -0.155
为了得到代价函数的值,我们需要计算所有单个配对的损失,然后将它们相加最后乘以[-1/样本数量]。代价函数由下式给出:
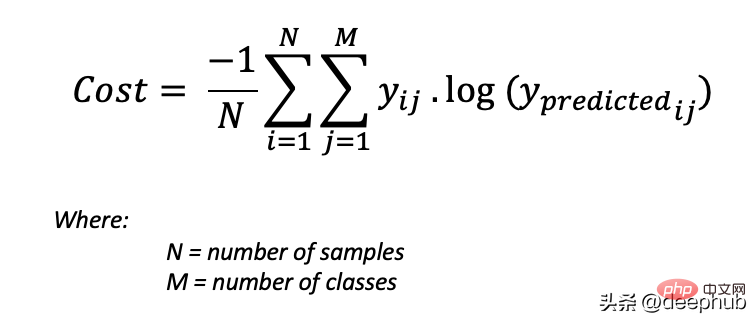
使用上面的例子,如果我们的第二对:
Loss = 0 . log (0.4) + 1. log (0.4) + 0. log (0.2) = -0.40
那么成本函数计算如下:
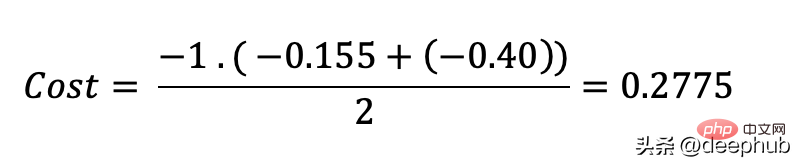
使用Python的代码示例可以更容易理解:
def CCE (y, y_predicted):cce_class = y * (np.log(y_predicted))sum_totalpair_cce = np.sum(cce_class)cce = - sum_totalpair_cce / y.sizereturn cce
10、Kullback-Leibler 散度 (KLD)
又被简化称为KL散度,它类似于分类交叉熵,但考虑了观测值发生的概率。 如果我们的类不平衡,它特别有用。
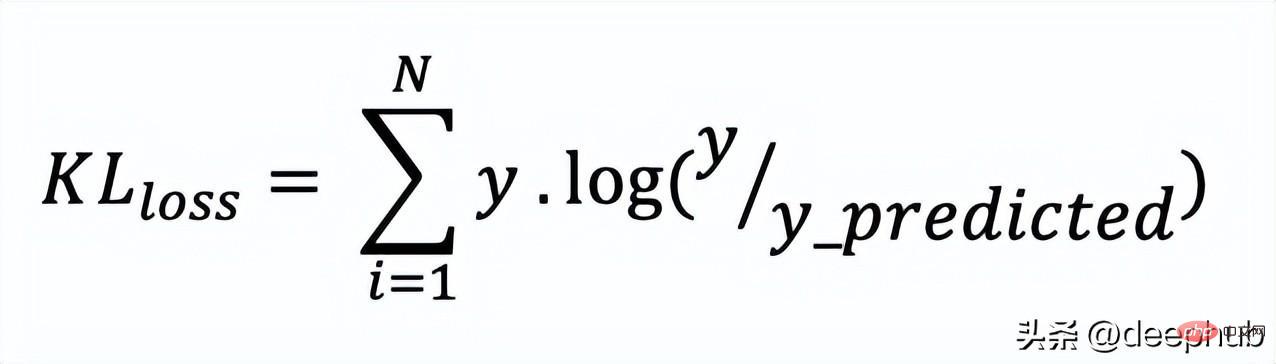
def KL (y, y_predicted):kl = y * (np.log(y / y_predicted))total_kl = np.sum(kl)return total_kl
以上就是常见的10个损失函数,希望对你有所帮助。
Das obige ist der detaillierte Inhalt vonZehn häufig verwendete Verlustfunktionserklärungen und Python-Codeimplementierungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Ist die Konversionsgeschwindigkeit beim Umwandeln von XML in PDF auf Mobiltelefon schnell?
Apr 02, 2025 pm 10:09 PM
Ist die Konversionsgeschwindigkeit beim Umwandeln von XML in PDF auf Mobiltelefon schnell?
Apr 02, 2025 pm 10:09 PM
Die Geschwindigkeit der mobilen XML zu PDF hängt von den folgenden Faktoren ab: der Komplexität der XML -Struktur. Konvertierungsmethode für mobile Hardware-Konfiguration (Bibliothek, Algorithmus) -Codierungsoptimierungsmethoden (effiziente Bibliotheken, Optimierung von Algorithmen, Cache-Daten und Nutzung von Multi-Threading). Insgesamt gibt es keine absolute Antwort und es muss gemäß der spezifischen Situation optimiert werden.
 Wie konvertiere ich XML -Dateien in PDF auf Ihrem Telefon?
Apr 02, 2025 pm 10:12 PM
Wie konvertiere ich XML -Dateien in PDF auf Ihrem Telefon?
Apr 02, 2025 pm 10:12 PM
Mit einer einzigen Anwendung ist es unmöglich, XML -zu -PDF -Konvertierung direkt auf Ihrem Telefon zu vervollständigen. Es ist erforderlich, Cloud -Dienste zu verwenden, die in zwei Schritten erreicht werden können: 1. XML in PDF in der Cloud, 2. Zugriff auf die konvertierte PDF -Datei auf dem Mobiltelefon konvertieren oder herunterladen.
 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 09:45 PM
Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 09:45 PM
Es gibt keine App, die alle XML -Dateien in PDFs umwandeln kann, da die XML -Struktur flexibel und vielfältig ist. Der Kern von XML zu PDF besteht darin, die Datenstruktur in ein Seitenlayout umzuwandeln, für das XML analysiert und PDF generiert werden muss. Zu den allgemeinen Methoden gehören das Parsen von XML mithilfe von Python -Bibliotheken wie ElementTree und das Generieren von PDFs unter Verwendung der ReportLab -Bibliothek. Für komplexe XML kann es erforderlich sein, XSLT -Transformationsstrukturen zu verwenden. Wenn Sie die Leistung optimieren, sollten Sie Multithread- oder Multiprozesse verwenden und die entsprechende Bibliothek auswählen.
 So konvertieren Sie XML in Bilder
Apr 03, 2025 am 07:39 AM
So konvertieren Sie XML in Bilder
Apr 03, 2025 am 07:39 AM
XML kann mithilfe eines XSLT -Konverters oder einer Bildbibliothek in Bilder konvertiert werden. XSLT -Konverter: Verwenden Sie einen XSLT -Prozessor und Stylesheet, um XML in Bilder zu konvertieren. Bildbibliothek: Verwenden Sie Bibliotheken wie Pil oder Imagemagick, um Bilder aus XML -Daten zu erstellen, z. B. Zeichnen von Formen und Text.
 Empfohlenes XML -Formatierungswerkzeug
Apr 02, 2025 pm 09:03 PM
Empfohlenes XML -Formatierungswerkzeug
Apr 02, 2025 pm 09:03 PM
XML -Formatierungs -Tools können Code nach Regeln eingeben, um die Lesbarkeit und das Verständnis zu verbessern. Achten Sie bei der Auswahl eines Tools auf die Anpassungsfunktionen, den Umgang mit besonderen Umständen, die Leistung und die Benutzerfreundlichkeit. Zu den häufig verwendeten Werkzeugtypen gehören Online-Tools, IDE-Plug-Ins und Befehlszeilen-Tools.
 Wie konvertieren Sie XML mit hoher Qualität auf Ihr Telefon in PDF?
Apr 02, 2025 pm 09:48 PM
Wie konvertieren Sie XML mit hoher Qualität auf Ihr Telefon in PDF?
Apr 02, 2025 pm 09:48 PM
Konvertieren Sie XML in PDF mit hoher Qualität auf Ihrem Mobiltelefon müssen: XML in der Cloud analysieren und PDFs mithilfe einer serverlosen Computerplattform generieren. Wählen Sie eine effiziente Bibliothek für XML -Parser- und PDF -Generation. Fehler korrekt behandeln. Nutzen Sie die Cloud -Computing -Leistung voll, um schwere Aufgaben auf Ihrem Telefon zu vermeiden. Passen Sie die Komplexität gemäß den Anforderungen an, einschließlich der Verarbeitung komplexer XML-Strukturen, der Erzeugung von mehrseitigen PDFs und dem Hinzufügen von Bildern. Drucken Sie Protokollinformationen zum Debuggen. Optimieren Sie die Leistung, wählen Sie effiziente Parser- und PDF -Bibliotheken aus und können asynchrone Programmier- oder Vorverarbeitungs -XML -Daten verwenden. Gewährleisten Sie eine gute Codequalität und -wartbarkeit.
 Wie konvertiere ich XML in PDF auf Android -Telefon?
Apr 02, 2025 pm 09:51 PM
Wie konvertiere ich XML in PDF auf Android -Telefon?
Apr 02, 2025 pm 09:51 PM
Das Konvertieren von XML in PDF direkt auf Android-Telefonen kann durch die integrierten Funktionen nicht erreicht werden. Sie müssen das Land in den folgenden Schritten speichern: XML -Daten in Formate konvertieren, die vom PDF -Generator (z. B. Text oder HTML) erkannt wurden. Konvertieren Sie HTML mithilfe von HTML -Generationsbibliotheken wie Flying Saucer in PDF.
