
 Backend-Entwicklung
Python-Tutorial
Schreiben Sie ein Python-Programm, um den Geldfluss von Sektoren zu crawlen
Backend-Entwicklung
Python-Tutorial
Schreiben Sie ein Python-Programm, um den Geldfluss von Sektoren zu crawlen
Schreiben Sie ein Python-Programm, um den Geldfluss von Sektoren zu crawlen


Anhand des obigen Beispiels zum Crawlen des Kapitalflusses einzelner Aktien sollten Sie lernen, Ihren eigenen Crawling-Code zu schreiben. Konsolidieren Sie es nun und machen Sie eine ähnliche kleine Übung. Sie müssen Ihr eigenes Python-Programm schreiben, um den Geldfluss von Online-Sektoren zu crawlen. Die gecrawlte URL lautet http://data.eastmoney.com/bkzj/hy.html und die Anzeigeoberfläche ist in Abbildung 1 dargestellt.金 Abbildung 1 Die Schnittstelle der Fondsfluss-Website
1, suchen Sie nach JS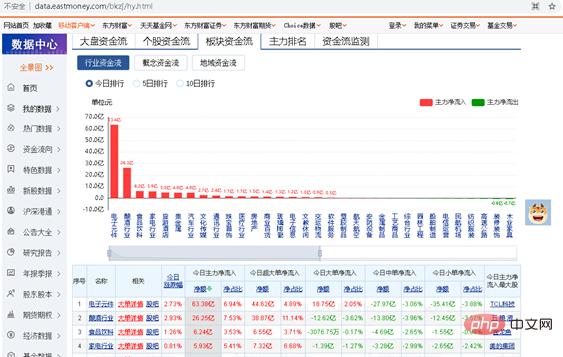
Abbildung 2 Suchen Sie die Webseite, die JS entspricht
Geben Sie dann die URL in den Browser ein. Die URL ist relativ lang. 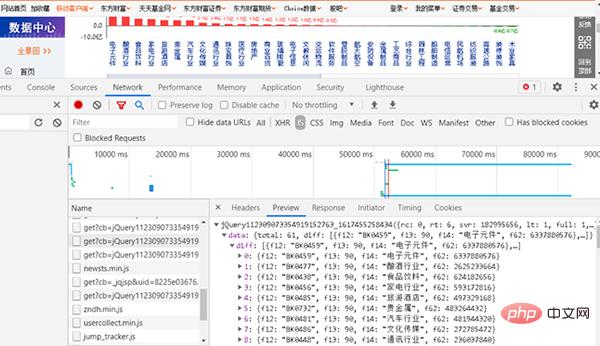
Abbildung 3 Abrufen von Abschnitten und Geldflüssen von der Website
Der dieser URL entsprechende Inhalt ist der Inhalt, den wir crawlen möchten. 
# coding=utf-8 import requests url=" http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_ 1617455258436&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3 e90d46a5&fs=m%3A90+t%3A2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2 Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124" r = requests.get(url)
Abbildung 4 Antwortstatus
3, str in JSON-Standardformat bereinigen 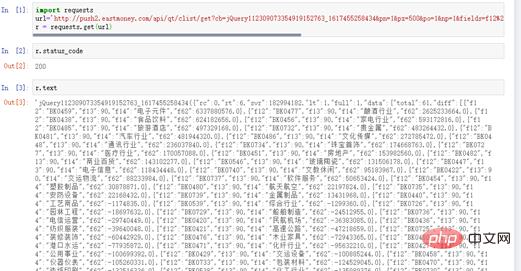
r_text=r.text.split("{}".format("jQuery112309073354919152763_1617455258436"))[1]
r_textr_text_qu=r_text.rstrip(';')
r_text_json=json.loads(r_text_qu[1:-1])['data']['diff']
dfcf_code={"f12":"code","f2":"价格","f3":"涨幅","f14":"name","f62":"主净入√","f66":"超净入","f69":"超占比", "f72":"大净入","f75":"大占比","f78":"中净入","f81":"中占比","f84":"小净入","f87":"小占比","f124":"不知道","f184":"主占比√"}
result_=pd.DataFrame(r_text_json).rename(columns=dfcf_code)
result_["主净入√"]=round(result_["主净入√"]/100000000,2)#一亿,保留2位
result_=result_[result_["主净入√"]>0]
result_["超净入"]=round(result_["超净入"]/100000000,2)#一亿,保留2位
result_["大净入"]=round(result_["大净入"]/100000000,2)#一亿,保留2位
result_["中净入"]=round(result_["中净入"]/100000000,2)#一亿,保留2位
result_["小净入"]=round(result_["小净入"]/100000000,2)#一亿,保留2位
result_
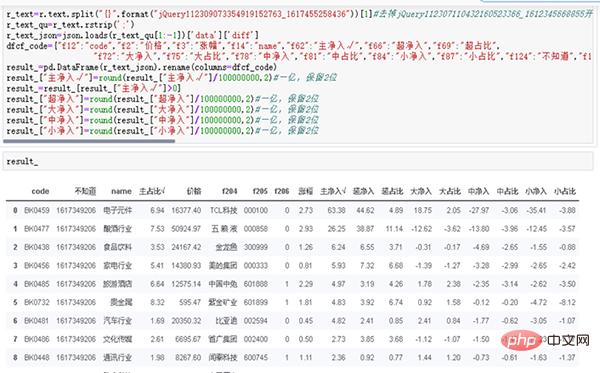 (3) Verwenden Sie Crawler, um Daten zu erhalten und zu speichern.
(3) Verwenden Sie Crawler, um Daten zu erhalten und zu speichern.
Durch Fallanalysen und tatsächliche Auseinandersetzungen müssen wir lernen, unseren eigenen Code zum Crawlen von Finanzdaten zu schreiben und ihn in das JSON-Standardformat konvertieren zu können. Führen Sie die täglichen Daten-Crawling- und Datenspeicherungsarbeiten durch, um eine effektive Datenunterstützung für zukünftige historische Tests und historische Datenanalysen bereitzustellen.
Natürlich können fähige Leser die Ergebnisse in Datenbanken wie MySQL, MongoDB oder sogar der Cloud-Datenbank Mongo Atlas speichern. Der Autor wird sich hier nicht auf die Erklärung konzentrieren. Wir konzentrieren uns ausschließlich auf das Studium des quantitativen Lernens und der Strategie. Durch die Verwendung des TXT-Formats zum Speichern von Daten kann das Problem der frühen Datenspeicherung vollständig gelöst werden, und die Daten sind außerdem vollständig und effektiv.
Das obige ist der detaillierte Inhalt vonSchreiben Sie ein Python-Programm, um den Geldfluss von Sektoren zu crawlen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So laden Sie Deepseek Xiaomi herunter
Feb 19, 2025 pm 05:27 PM
So laden Sie Deepseek Xiaomi herunter
Feb 19, 2025 pm 05:27 PM
Wie lade ich Deepseek Xiaomi herunter? Suchen Sie nach "Deepseek" im Xiaomi App Store. Identifizieren Sie Ihre Anforderungen (Suchdateien, Datenanalyse) und finden Sie die entsprechenden Tools (z. B. Dateimanager, Datenanalyse -Software), die Deepseek -Funktionen enthalten.
 Wie fragst du ihn Deepseek?
Feb 19, 2025 pm 04:42 PM
Wie fragst du ihn Deepseek?
Feb 19, 2025 pm 04:42 PM
Der Schlüssel zur effektiven Verwendung von Deepseek liegt darin, die Fragen klar zu stellen: Die Fragen direkt und spezifisch ausdrücken. Geben Sie spezifische Details und Hintergrundinformationen an. Für komplexe Anfragen sind mehrere Blickwinkel und Widerrufs der Meinungen enthalten. Konzentrieren Sie sich auf bestimmte Aspekte, wie z. B. Leistungs Engpässe im Code. Denken Sie kritisch über die Antworten nach, die Sie erhalten, und fällen Sie anhand Ihres Fachwissens Urteile.
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:18 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:18 PM
Verwenden Sie einfach die Suchfunktion, die mit Deepseek geliefert wird. Für Suchvorgänge, die unpopulär, neueste Informationen oder Probleme sind, die berücksichtigt werden müssen, müssen jedoch Schlüsselwörter angepasst oder spezifischere Beschreibungen verwendet werden, sie mit anderen Echtzeitinformationsquellen kombinieren und verstehen, dass Deepseek nur ein Tool ist, das erfordert aktive, klare und raffinierte Suchstrategien.
 So programmieren Sie Deepseek
Feb 19, 2025 pm 05:36 PM
So programmieren Sie Deepseek
Feb 19, 2025 pm 05:36 PM
Deepseek ist keine Programmiersprache, sondern ein tiefes Suchkonzept. Die Implementierung von Deepseek erfordert eine Auswahl auf der Grundlage vorhandener Sprachen. Für verschiedene Anwendungsszenarien ist es erforderlich, die entsprechende Sprache und Algorithmen auszuwählen und maschinelles Lernen zu kombinieren. Codequalität, Wartbarkeit und Tests sind von entscheidender Bedeutung. Nur durch die Auswahl der richtigen Programmiersprache können Algorithmen und Tools entsprechend Ihren Anforderungen und das Schreiben von Code von hochwertigem Code erfolgreich implementiert werden.
 So verwenden Sie Deepseek, um Konten zu begleichen
Feb 19, 2025 pm 04:36 PM
So verwenden Sie Deepseek, um Konten zu begleichen
Feb 19, 2025 pm 04:36 PM
Frage: Ist Deepseek für die Buchhaltung verfügbar? Antwort: Nein, es handelt sich um ein Data Mining- und Analyse -Tool, mit dem Finanzdaten analysiert werden können, aber es gibt nicht die Funktionen zur Erzeugung von Buchhaltungsdaten für Buchhaltungsdaten für Buchhaltungssoftware. Um Deepseek zur Analyse von Finanzdaten zu analysieren, muss das Schreiben von Code geschrieben werden, um Daten mit Kenntnissen von Datenstrukturen, Algorithmen und Deepseek -APIs zu verarbeiten, um potenzielle Probleme zu berücksichtigen (z. B. Programmierkenntnisse, Lernkurven, Datenqualität)
 Sozugreifen Sie auf Deepseekapi - Deepseekapi Access Tutorial Tutorial
Mar 12, 2025 pm 12:24 PM
Sozugreifen Sie auf Deepseekapi - Deepseekapi Access Tutorial Tutorial
Mar 12, 2025 pm 12:24 PM
Detaillierte Erläuterung von Deepseekapi -Zugriff und -anruf: Quick Start Guide In diesem Artikel können Sie ausführlich auf Deepseekapi zugreifen und anrufen und Ihnen helfen, leistungsstarke KI -Modelle problemlos zu verwenden. Schritt 1: Holen Sie sich den API -Schlüssel, um auf die offizielle Website von Deepseek zuzugreifen, und klicken Sie in der oberen rechten Ecke auf die "Plattform". Sie erhalten eine bestimmte Anzahl freier Token (zur Messung der API -Verwendung verwendet). Klicken Sie im Menü links auf "Apikeys" und dann auf "Apikey erstellen". Nennen Sie Ihren Apikey (z. B. "Test") und kopieren Sie den generierten Schlüssel sofort. Stellen Sie sicher, dass Sie diesen Schlüssel richtig speichern, da er nur einmal angezeigt wird
 Großes Update von Pi Coin: Die PI Bank kommt!
Mar 03, 2025 pm 06:18 PM
Großes Update von Pi Coin: Die PI Bank kommt!
Mar 03, 2025 pm 06:18 PM
Pinetwork startet Pibank, eine revolutionäre Mobile -Banking -Plattform! PiNetwork today released a major update on Elmahrosa (Face) PIMISRBank, referred to as PiBank, which perfectly integrates traditional banking services with PiNetwork cryptocurrency functions to realize the atomic exchange of fiat currencies and cryptocurrencies (supports the swap between fiat currencies such as the US dollar, euro, and Indonesian rupiah with cryptocurrencies such as PiCoin, USDT, and USDC). Was ist der Charme von Pibank? Lass uns herausfinden! Die Hauptfunktionen von Pibank: One-Stop-Management von Bankkonten und Kryptowährungsvermögen. Unterstützen Sie Echtzeittransaktionen und übernehmen Sie Biospezies
 Was sind die aktuellen KI-Slicing-Tools?
Nov 29, 2024 am 10:40 AM
Was sind die aktuellen KI-Slicing-Tools?
Nov 29, 2024 am 10:40 AM
Hier sind einige beliebte KI-Slicing-Tools: TensorFlow DataSetPyTorch DataLoaderDaskCuPyscikit-imageOpenCVKeras ImageDataGenerator
