
 Backend-Entwicklung
Python-Tutorial
Automatisiertes Testen: mehrere gängige Programmiermuster in Python
Backend-Entwicklung
Python-Tutorial
Automatisiertes Testen: mehrere gängige Programmiermuster in Python
Automatisiertes Testen: mehrere gängige Programmiermuster in Python


In diesem Kapitel wird der Inhalt im Zusammenhang mit „Python-Syntaxspezifikationen und Datentypen“ aktualisiert, hauptsächlich damit jeder versteht, welche Arten von Programmiermodellen Python hat, und die grundlegende Syntax von Python beherrscht. Machen Sie sich mit der Ausgabe und der grundlegenden Anwendung von Befehlszeilenparametern vertraut. Nachdem Sie die Datentypen von Python verstanden haben, können Sie weitere verwandte Vorgänge ausführen.
Gemeinsame Programmiermuster
①Interaktive Python-Befehlsprogrammierung.
②Python-Skriptprogrammierung.
③Chinesische Kodierungsverarbeitung.
1. Interaktiver Befehlsprogrammiermodus
Der interaktive Befehlsprogrammiermodus ist ein typischer zeilenweiser Leseausführungsmodus.
Wenn das Programm nur eine Zeile oder weniger hat, ist dieser Programmiermodus eine typische Anwendungsmethode.
In der folgenden Abbildung wird der PythonIDLE-Editor zum Programmieren verwendet. Der Programmiermodus dieses Editors ist ein typisches interaktives Befehlscodierungssymbol.
>>>> ist die Eingabeaufforderung für die Eingabe interaktiver Befehle. Jedes Mal, wenn Sie nach der Eingabe die Eingabetaste drücken, wird der Befehl vom Python-Parser ausgeführt.
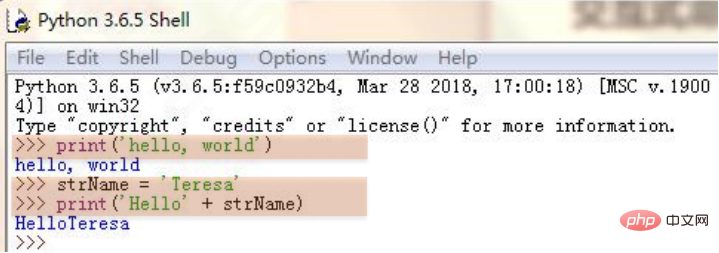
2. Skriptprogrammiermodus
Wenn wir komplexere oder größere Codeabschnitte schreiben müssen, scheint es zwingend erforderlich nicht bequem genug.
Daher bietet Python einen Skriptprogrammiermodus. Sie können eine Skriptdatei mit dem Suffix *.py erstellen und eine große Menge Code in die Datei schreiben, was die Wartung und Aktualisierung des Codes erleichtert. Sie können ihn dann mithilfe interaktiver Befehle oder IDE-Tools ausführen.
3. Zeichenprogrammierung
String ist ein Datentyp. Bei Zeichenfolgen besteht jedoch ein besonderes Kodierungsproblem.
Da Computer nur Zahlen verarbeiten können, müssen Sie den Text vor der Verarbeitung zunächst in Zahlen umwandeln, wenn Sie Text verarbeiten möchten.
Ergänzung: Geschichte der Entwicklung der Zeichenkodierung
Die frühesten Computer wurden mit 8 Bits als Byte entwickelt, sodass ein Byte darstellen kann. Die größte ganze Zahl ist 255 (binär 11111111 = dezimal). 255). Wenn Sie eine größere Ganzzahl darstellen möchten, müssen Sie mehr Bytes verwenden. Beispielsweise ist die maximale Ganzzahl, die durch zwei Bytes dargestellt werden kann, 65535, und die maximale Ganzzahl, die durch 4 Bytes dargestellt werden kann, ist 4294967295.
Da der Computer von Amerikanern erfunden wurde, wurden zunächst nur 127 Zeichen in den Computer codiert, bei denen es sich um englische Groß- und Kleinbuchstaben, Zahlen und einige Symbole handelt. Diese Codierungstabelle wird beispielsweise als ASCII-Codierung bezeichnet. Der Code für den Großbuchstaben A ist 65 und der Code für den Kleinbuchstaben z ist 122.
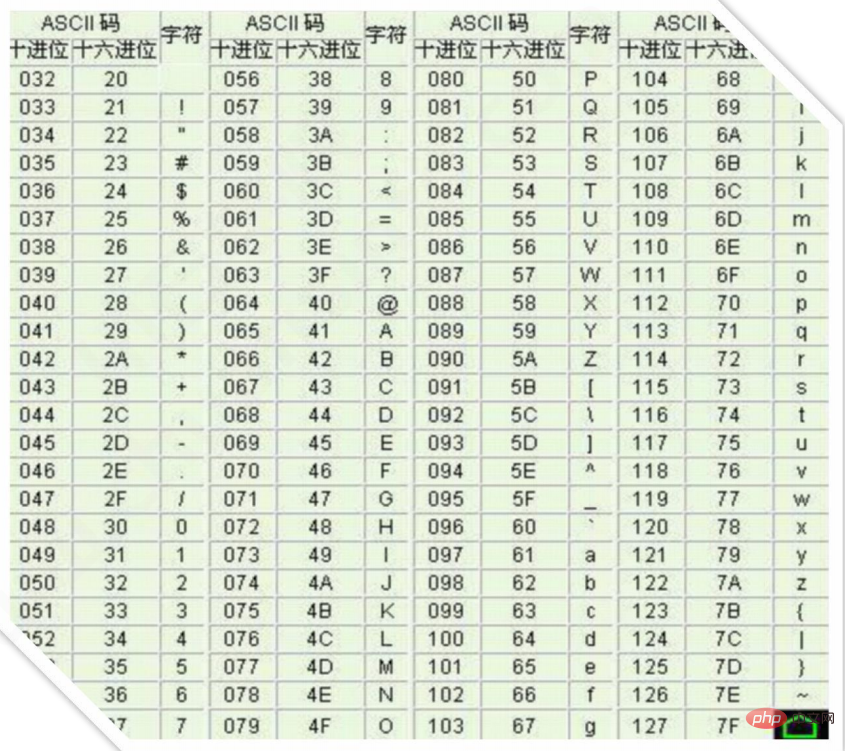
Erweiterung: Unicode-Zeichensatz
Der Grund, warum Python3 das chinesische verstümmelte Problem gut lösen kann, ist, dass es alle Strings kombiniert sind alle mit Unicode zeichencodiert.
● Unicode vereint alle Sprachen in einem Satz von Codes, sodass keine verstümmelten Zeichen entstehen.
● Unicode entwickelt sich ebenfalls ständig weiter, aber die am häufigsten verwendete Methode ist die Verwendung von zwei Bytes zur Darstellung eines Zeichens (wenn Sie auf ein sehr seltenes Zeichen stoßen, benötigen Sie 4 Bytes). Die meisten Betriebssysteme und die meisten Programmiersprachen, die wir sehen, unterstützen jetzt Unicode.
Die ASCII-Kodierung beträgt 1 Byte, während die Unicode-Kodierung normalerweise 2 Byte beträgt.
Erweiterung: UTF-8-Zeichensatz
Ein neues Problem tritt erneut auf: Bei Vereinheitlichung in die Unicode-Kodierung verschwindet das Problem mit dem verstümmelten Code. Wenn der Text, den Sie schreiben, jedoch grundsätzlich ausschließlich auf Englisch verfasst ist, benötigt die Unicode-Kodierung doppelt so viel Speicherplatz wie die ASCII-Kodierung, was hinsichtlich der Speicherung und Übertragung sehr unwirtschaftlich ist.
Die Geburtsstunde der Lösung: Es gibt eine weitere UTF-8-Kodierung, die die Unicode-Kodierung in „Variable-Längen-Kodierung“ umwandelt.
● Die UTF-8-Kodierung kodiert ein Unicode-Zeichen entsprechend unterschiedlicher Zahlengrößen in 1-6 Bytes, und chinesische Zeichen sind normalerweise 3 Bytes groß Zeichen werden in 4-6 Bytes kodiert.
● Wenn der Text, den Sie übertragen möchten, eine große Anzahl englischer Zeichen enthält, kann die Verwendung der UTF-8-Kodierung Platz sparen.
● Die UTF-8-Kodierung hat einen zusätzlichen Vorteil: Die ASCII-Kodierung kann tatsächlich als Teil der UTF-8-Kodierung betrachtet werden. Daher ist dies bei einer großen Anzahl historischer Legacy-Software möglich, die nur die ASCII-Kodierung unterstützt in UTF kodiert werden. Arbeiten Sie weiter unter -8-Kodierung.
Besonderer Hinweis: Die Unicode-Kodierung wird einheitlich im Computerspeicher verwendet.
Python3-Zeichenkodierung
In der Python3-Version werden Zeichenfolgen in Unicode codiert, was bedeutet, dass Python-Zeichenfolgen mehrere Sprachen unterstützen.
Für die Kodierung eines einzelnen Zeichens stellt Python die Funktion ord() bereit, um die dezimale Ganzzahldarstellung eines einzelnen Zeichens zu erhalten, und die Funktion chr(), um die Kodierung in das entsprechende Zeichen umzuwandeln.
Beispiel:
>>> ord(‘A’) 65 >>> ord(‘中’) 20013 >>> chr(66) ‘B’ >>> chr(25991) ‘文’
Python-Quellcode ist ebenfalls eine Textdatei. Wenn Ihr Quellcode also Chinesisch enthält, müssen Sie beim Speichern des Quellcodes angeben, dass er als UTF-8-Kodierung gespeichert werden soll . Wenn der Python-Interpreter Quellcode liest, schreiben wir diese Zeile normalerweise an den Anfang der Datei, damit er in UTF-8-Kodierung gelesen werden kann.
#-*- coding:utf-8 *-
Der Kommentar soll den Python-Interpreter anweisen, den Quellcode gemäß der UTF-8-Codierung zu lesen. Andernfalls ist die chinesische Ausgabe, die Sie in den Quellcode schreiben, möglicherweise verstümmelt.
Das obige ist der detaillierte Inhalt vonAutomatisiertes Testen: mehrere gängige Programmiermuster in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1209
24
52
1209
24

 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
