
 Technologie-Peripheriegeräte
KI
Auf dem kontradiktorischen Gradienten basierendes Explorationsmodell und seine Anwendung bei der Klickvorhersage
Technologie-Peripheriegeräte
KI
Auf dem kontradiktorischen Gradienten basierendes Explorationsmodell und seine Anwendung bei der Klickvorhersage
Auf dem kontradiktorischen Gradienten basierendes Explorationsmodell und seine Anwendung bei der Klickvorhersage

1. Zusammenfassung
Ranking-Modelle spielen eine wichtige Rolle in Werbe-, Empfehlungs- und Suchsystemen. Im Ranking-Modul steht die Technologie zur Schätzung der Klickrate an erster Stelle. Derzeit verwenden die meisten Technologien zur Vorhersage der Klickrate in der Branche Deep-Learning-Algorithmen, um tiefe neuronale Netze basierend auf dem Datenlaufwerk zu trainieren. Das entsprechende Problem, das durch den Datenlaufwerk verursacht wird, besteht jedoch darin, dass neue Projekte im Empfehlungssystem ein Kaltstartproblem haben.
Exploration-Exploitation (E&E)-Methode wird normalerweise verwendet, um Datenzyklusprobleme in großen Online-Empfehlungssystemen zu lösen. Frühere Forschungen gingen in der Regel davon aus, dass eine hohe Unsicherheit bei Modellvorhersagen ein hohes Renditepotenzial mit sich bringt, weshalb sich die meiste Forschungsliteratur auf die Schätzung der Unsicherheit konzentrierte. Bei Online-Empfehlungssystemen, die Streaming-Training verwenden, hat die Explorationsstrategie einen größeren Einfluss auf die Sammlung von Trainingsbeispielen, was sich wiederum auf das weitere Lernen des Modells auswirkt. Die meisten aktuellen Explorationsstrategien können jedoch nicht gut modellieren, wie sich die untersuchten Proben auf das anschließende Modelllernen auswirken. Aus diesem Grund haben wir ein Pseudo-Explorationsmodul entwickelt, um die Auswirkungen auf das anschließende Lernen des Empfehlungsmodells zu simulieren, nachdem die Stichprobe erfolgreich erkundet und angezeigt wurde.
Der Quasi-Explorationsprozess wird durch das Hinzufügen kontradiktorischer Störungen zur Modelleingabe realisiert. Wir liefern auch die entsprechende theoretische Analyse und den Beweis dieses Prozesses. Auf dieser Grundlage nennen wir diese Methode eine Explorationsstrategie, die auf einem kontradiktorischen Gradienten basiert (Adversarial Gradient Driven Exploration, im Folgenden als AGE bezeichnet). Um die Effizienz der Exploration zu verbessern, schlagen wir außerdem eine dynamische Gating-Einheit zum Filtern von Proben mit geringem Wert vor, um eine Verschwendung von Ressourcen für die Exploration mit geringem Wert zu vermeiden. Um die Wirksamkeit des AGE-Algorithmus zu überprüfen, haben wir nicht nur zahlreiche Experimente mit öffentlichen akademischen Datensätzen durchgeführt, sondern das AGE-Modell auch auf der Display-Werbeplattform Alimama eingesetzt und gute Online-Erträge erzielt. Diese Arbeit wurde als vollständiges Papier in den KDD 2022 Research Track aufgenommen. Sie können gerne gelesen und mitgeteilt werden.
Artikel: Adversarial Gradient Driven Exploration for Deep Click-Through-Rate Prediction
Download: https://arxiv.org/abs/2112.11136
2. Hintergrund
In Werbesystemen, Click-Through-Rate (CTR)-Vorhersagemodell Für das Training wird normalerweise die Streaming-Methode verwendet, und die Quelle der Streaming-Daten wird durch das online bereitgestellte CTR-Modell erzeugt, wodurch das sogenannte Datenschleifenproblem entsteht. Da Kaltstart- und Long-Tail-Anzeigen nicht vollständig angezeigt werden, fehlen dem CTR-Modell Trainingsdaten für diese Anzeigen. Dies führt auch dazu, dass die Schätzung dieser Anzeigen durch das Modell große Fehler aufweisen kann, was die Anzeige dieser Anzeigen erschwert Es ist schwierig, den Kaltstart abzuschließen. Starten Sie den Vorgang. Konkret zeigt Abbildung 1 die Beziehung zwischen der tatsächlichen Klickrate einer Anzeige und der Anzahl der Impressionen: In unserem System muss eine neue Anzeige durchschnittlich etwa 10.000 Mal angezeigt werden, bevor ihre Klickrate einen Konvergenzzustand erreicht . Dies bringt ein häufiges Problem für viele Online-Systeme mit sich, nämlich wie man diese Werbung kaltstartet und gleichzeitig das Benutzererlebnis gewährleistet.
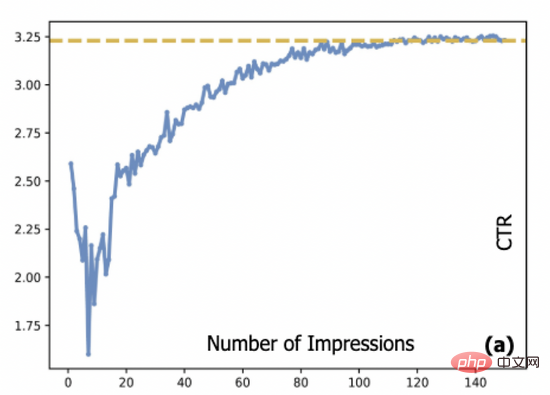
Abbildung 1: Die Beziehung zwischen der Werbe-CTR und der Anzahl der Impressionen
Explorations- und Exploitation-Algorithmen (E&E) werden normalerweise verwendet, um die oben genannten Probleme zu lösen. In Empfehlungs- oder Werbesystemen modellieren gängige Methoden (wie Contextual Multi-Armed Bandits, Contextual Multi-Armed Bandits) dieses Problem im Allgemeinen wie folgt. Bei jedem Schritt wählt das System eine Aktion basierend auf Richtlinie P aus (d. h. empfiehlt dem Benutzer einen Artikel _ _). Um die kumulativen Belohnungen zu maximieren (normalerweise gemessen als Gesamtklicks), muss das System abwägen, ob der aktuelle Schwerpunkt auf Erkundung oder Ausbeutung liegt. Frühere Untersuchungen betrachten eine hohe Unsicherheit im Allgemeinen als Maß für potenzielle Renditen. Einerseits muss Strategie P Projekten mit größerem aktuellen Nutzen Priorität einräumen, um den aktuellen Nutzen zu maximieren, andererseits muss der Algorithmus auch Operationen mit größerer Unsicherheit auswählen, um eine Exploration zu erreichen. Wenn es zur Darstellung der Strategie der Abwägung von Exploration und Ausbeutung verwendet wird, kann die endgültige Bewertung des Projekts durch das System durch die folgende Formel ausgedrückt werden:
Unsicherheitsschätzung ist zum Kernmodul vieler E&E-Algorithmen geworden. Die Unsicherheit kann durch Datenvariabilität, Messrauschen und Modellinstabilität (z. B. Zufälligkeit von Parametern) entstehen, darunter Monte-Carlo-MC-Dropout, Bayesianisches neuronales Netzwerk und Gaußsche Prozesse sowie die Unsicherheitsmodellierung auf der Grundlage von Gradientennormen. Modellgewichte) usw. Auf dieser Grundlage gibt es zwei typische Explorationsstrategien: UCB-basierte Methoden verwenden in der Regel die Obergrenze potenzieller Renditen als Endergebnis [1,2], während auf Thompson-Stichproben basierende Methoden durch Stichproben aus der geschätzten Wahrscheinlichkeitsverteilung erfolgen [3]. ].
3. Einführung in die Methode
Wir glauben, dass die obige Methode keinen vollständigen geschlossenen Kreislauf der Erkundung berücksichtigt. Bei datengesteuerten Online-Systemen ergibt sich der ultimative Vorteil der Exploration aus den Feedback-Daten, die aus dem Explorationsprozess gewonnen werden, sowie aus den Feedback-Daten für das Training und die Aktualisierung des Modells. Die Unsicherheit der Modellschätzung selbst spiegelt nicht vollständig die gesamte Rückkopplungsschleife wider. Zu diesem Zweck haben wir ein Quasi-Explorationsmodul eingeführt, um die Auswirkungen von Feedback-Daten auf das Modell nach Abschluss der Explorationsaktion zu simulieren und damit die Wirksamkeit der Exploration zu messen. Die Analyse ergab, dass die Wirksamkeit der Exploration nicht nur von der geschätzten Unsicherheit des Modells abhängt, sondern auch von der Größe der „Gegenstörung“. Die sogenannte kontradiktorische Störung bezieht sich auf den Störungsvektor mit einer festen Modullänge, der zur Eingabe des Modells hinzugefügt wird und die größte Änderung in der Modellausgabe verursacht. In der Arbeit haben wir auch bewiesen, dass, nachdem das Modell einmal mit den untersuchten Daten trainiert wurde, die Erwartung einer Änderung in der Modellausgabe dem Hinzufügen eines inkrementellen Vektors entspricht, dessen Modul die Unsicherheit ist und dessen Störungsvektor der kontradiktorische Gradient zum Eingabevektor ist . Wir haben bestätigt, dass die Modellierung auf diese Weise die spätere Auswirkung der untersuchten Proben auf das Modell in einem geschlossenen Regelkreis abschätzen und so den wahren Wert der untersuchten Proben abschätzen kann.
Wir nennen diese Methode Adversarial Gradient Driven Exploration, kurz AGE. Das AGE-Modell besteht aus zwei Teilen: dem Pseudo-Explorationsmodul und der dynamischen Gating-Einheit. Seine Gesamtstruktur ist in Abbildung 2 dargestellt.
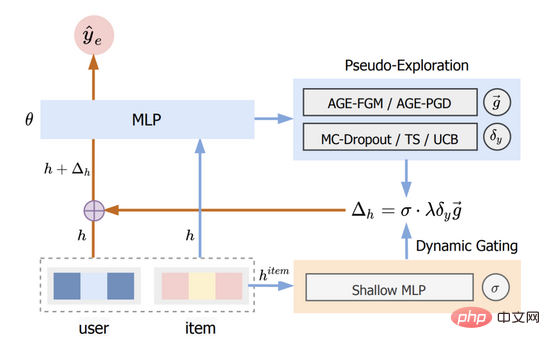
Abbildung 2: AGE-Strukturdiagramm
Siehe Abschnitt 3.1 für Einzelheiten und Abschnitt 3.3 für Einzelheiten. 3.1 Pseudo-Explorationsmodul um die Auswirkungen der Exploration auf das Modell abzuschätzen. Nach der Ableitung haben wir festgestellt, dass der obige Prozess durch Formel (2) abgeschlossen werden kann, die die Punktzahl der Stichprobe nach der Untersuchung durch das Modell darstellt, die wir für die endgültige Rangfolge verwenden.
Die obige Formel bedeutet, dass wir keine Operationen an den ursprünglichen Modellparametern durchführen müssen. Wir müssen lediglich das Produkt aus kontradiktorischem Gradienten, geschätzter Unsicherheit und manuell eingestellten Hyperparametern zur Eingabedarstellung hinzufügen, um die Simulation des Modells abzuschließen geschätzte Punktzahlen. Darunter die Berechnungsmethode für Parameter, die im nächsten Abschnitt vorgestellt wird. Später in diesem Abschnitt werden wir den detaillierten Ableitungsprozess der Formel (2) im vorgeschlagenen Explorationsmodul vorstellen.
3.1.2 Detaillierte Ableitung
Für jede Datenprobe wirkt sich das Modelltraining auf zwei Teile der Parameter aus: die der Probe entsprechende Darstellung (einschließlich Produkt, Benutzereinbettung usw.) und die Modellparameter. Da das Ziel der Modellparameter beim Training darin besteht, sich an alle Stichproben und nicht an eine einzelne Stichprobe anzupassen, können wir davon ausgehen, dass das Training einer einzelnen Stichprobe hauptsächlich die Darstellung der Stichprobe beeinflusst, während die Modellparameter selbst nur geringfügige Anpassungen erfordern. Daher werden wir in nachfolgenden Studien die Anpassung ignorieren und uns nur auf die Änderungen in den Darstellungen konzentrieren, die den Stichproben entsprechen. Unter der Annahme, dass die wahre Bezeichnung der Probe, die die Darstellung enthält, während des Trainings vorliegt, müssen wir die Anzahl der Aktualisierungen ermitteln, um die Verlustfunktion zu minimieren. Auf dieser Grundlage definieren wir:
, was die im Training verwendete Verlustfunktion darstellt, und die Kreuzentropieverlustfunktion wird im Allgemeinen bei CTR-Vorhersageaufgaben verwendet. Gleichzeitig beschränken wir die maximale Änderung der Darstellung. Um das Schreiben zu vereinfachen, schreiben wir die rechte Seite der obigen Formel als.
Gemäß dem Mittelwertsatz von Lagrange können wir, wenn die zweite Norm von nahe bei 0 liegt, die obige Verlustfunktionsformel (3) wie folgt ableiten: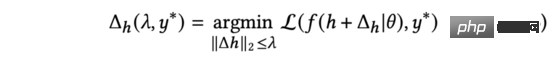
In der Praxis ersetzen wir den normalisierten Gradienten in Gleichung (5). Durch Ableitung der Kettenregel kann diese in zwei Teile erweitert werden: und . Wenn wir weiter rechnen, erhalten wir: 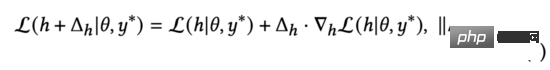
In der obigen Gleichung werden wir neu skalieren, um die Gleichung wahr zu halten. Obwohl die Bedeutung unterschiedlich ist, handelt es sich bei allen um manuell angepasste Hyperparameter, sodass wir die Ersetzung direkt abschließen können. Wir vereinfachen Formel (6) weiter als: 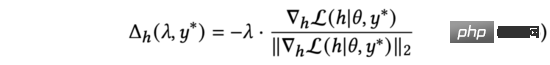
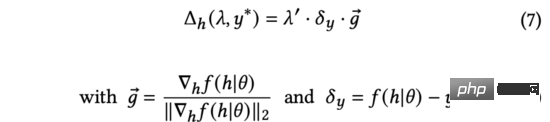
In der obigen Formel stellt der normalisierte Gradient die Richtung der Ableitung der Modellausgabe relativ zur Eingabedarstellung dar. Da zum Zeitpunkt der Erkundung kein echtes Benutzerfeedback verfügbar ist, verwenden wir die Schätzunsicherheit, um den Unterschied zwischen der vorhergesagten Punktzahl und dem echten Benutzerfeedback zu messen.
In Formel (7) finden wir die analytische Lösung, die die Änderung der Modellvorhersageausgabe unter den Einschränkungen von maximieren kann (die Ableitung ist die gleiche wie Formel (3) bis Formel (5)). Darüber hinaus stellen wir auch fest, dass der obige Prozess des Hinzufügens von Eingabedarstellungen die gleiche Form hat wie eine gegnerische Störung (siehe Gleichung (9)).
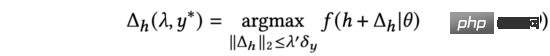
Daher verwenden wir als Ersatz in Formel (7) einen kontradiktorischen Gradienten und bezeichnen unsere Methode als kontradiktorischen Gradienten-basierten Erkundungsalgorithmus.
Formel (9) zeigt, dass der effektivste Weg zur Untersuchung von AGE darin besteht, gegnerische Störungen zur Darstellungseingabe hinzuzufügen und die Ausgabe des gestörten Modells als Rangfolgefaktor zu verwenden: die Richtung des durch den gegnerischen Gradienten dargestellten Störungsvektors als die Eingabe und der Vorhersageunsicherheitsgrad der Störung. Daher können wir nach Erhalt der Summe die folgende Formel verwenden, um den Modellvorhersagewert nach der Erkundung zu berechnen, nämlich die oben genannte Formel (2).
3.2 Implementierungsdetails
In AGE verwenden wir die MC-Dropout-Methode, um die Unsicherheit abzuschätzen. Insbesondere weist MC-Dropout jedem Neuron im Tiefenmodell ein zufälliges Maskengewicht zu. Die spezifische Methode ist in der folgenden Formel (11) dargestellt. Ein Vorteil dieser Methode besteht darin, dass wir die Unsicherheit direkt ermitteln können, ohne die ursprüngliche Struktur des Modells zu ändern. Im tatsächlichen Betrieb kann die Unsicherheit ausgedrückt werden, indem die Varianz des Ausfalls durch die Idee von UCB berechnet wird, oder indem man sich auf die Zufallsstichprobenmethode von Thompson bezieht, indem man die Differenz zwischen der Stichprobe und dem Mittelwert berechnet, also die Formel ( 12) und Formel (13) ).
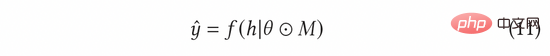
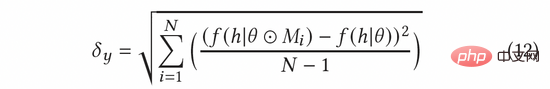
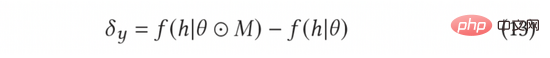
Der normalisierte kontradiktorische Gradient kann gemäß der Fast-Gradient-Methode (FGM) in Formel (8) berechnet werden. Um den kontradiktorischen Gradienten genauer zu berechnen, können wir außerdem die Methode des proximalen Gradientenabstiegs (PGD) verwenden, um den Gradienten iterativ in mehreren Schritten zu aktualisieren, wie in Gleichung (14) gezeigt.
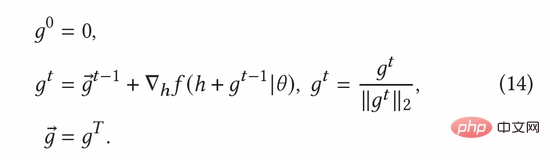
3.3 Dynamische Gating-Einheit
In der Praxis haben wir festgestellt, dass nicht alle Anzeigen eine Erkundung wert sind. In einem allgemeinen Top-K-Werbesystem ist die Anzahl der Anzeigen, die Endbenutzern angezeigt werden können, relativ gering. Daher ist der explorative Wert für Anzeigen mit niedrigen Klickraten (z. B. Anzeigen von geringer Qualität selbst) angesichts der Geschäftsattribute des Werbesystems immer noch sehr gering, selbst wenn das Modell eine hohe Unsicherheit bei der Vorhersage dieser Anzeigen aufweist . . Obwohl wir durch Erkundung eine große Menge an Daten zu diesen Anzeigen erhalten können, sodass diese Anzeigen vom Modell vollständig trainiert und genauer geschätzt werden können, ist es aufgrund der niedrigen Klickrate dieser Anzeigen nicht möglich, diese Anzeigen zu erhalten Selbst nach vollständiger Erkundung ist eine solche Erkundung zweifellos ineffizient. In diesem Artikel haben wir eine einfache Heuristik ausprobiert, um die Erkundung effizienter zu gestalten: Wenn die geschätzte Punktzahl des Modells für die Anzeige höher ist als die durchschnittliche Klickrate für die Anzeige in allen Gruppen, wird die Erkundung andernfalls nicht durchgeführt.
Um die durchschnittliche Klickrate von Anzeigen zu berechnen, führen wir das Modul Dynamic Gating Threshold Unit (DGU) ein. DGU verwendet nur werbeseitige Funktionen als Eingabe, um die durchschnittliche Klickrate von Anzeigen zu schätzen. Wenn die geschätzte Klickrate des Modells niedriger ist als die vom DGU-Modul geschätzte durchschnittliche Klickrate für Werbung, wird keine Erkundung durchgeführt. Andernfalls wird eine normale Erkundung durchgeführt. Der Prozess wird in der folgenden Formel dargestellt:
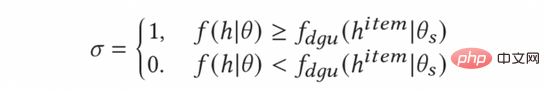
Abschließend werden wir ihn in Formel (10) einsetzen, um die endgültige und vollständige Berechnungsmethode des AGE-Explorationsmodells wie folgt zu erhalten.
4. Experimentelle Auswertung . Es lässt sich beobachten, dass die auf der Thompson Sampling (TS)-Methode erstellten Basismodelle besser sind als die auf UCB basierenden Modelle, was beweist, dass TS ein besserer Algorithmus zur Messung der Modellunsicherheit ist. Darüber hinaus können wir beobachten, dass der AGE-Algorithmus alle Basismethoden übertrifft, was auch die Wirksamkeit der AGE-Methode beweist. Insbesondere übertreffen sowohl AGE-TS als auch AGE-UCB die besten Basislinien UR-Gradient-TS und UR-Gradient-UCB [4] mit Verbesserungswerten von 5,41 % bzw. 15,3 %. Die AGE-TS-Methode steigert die Klicks im Vergleich zur Basismethode ohne Exploration um satte 28,0 %. Es ist erwähnenswert, dass die AGE-basierten UCB- und TS-Algorithmen AGE-UCB und AGE-TS ähnliche Ergebnisse erzielen, was bei den Gradienten-basierten UCB- und TS-Algorithmen nicht der Fall ist, was auch beweist, dass AGE die Instabilität von kompensieren kann die UCB-Methode.Tabelle 1: Offline-Versuchsergebnisse
Wir haben auch eine große Anzahl von Ablationsexperimenten durchgeführt, um die Wirksamkeit jedes Moduls zu beweisen. Wie in Tabelle 2 gezeigt, sind die Schwellenwerteinheit, der kontradiktorische Gradient und die Unsicherheitseinheit unverzichtbar. Um die Wirkung von DGU weiter zu bestimmen, haben wir verschiedene Parameter mit festem Schwellenwert ausprobiert und schließlich festgestellt, dass ihre Wirkung nicht so gut war wie der dynamische Schwellenwert von DGU. 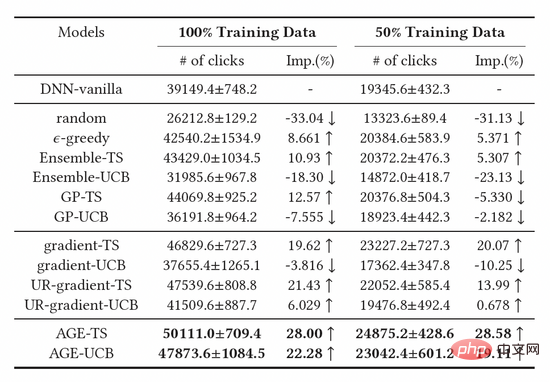
Tabelle 2: Ergebnisse des Ablationsexperiments
4.2 Online-Experiment 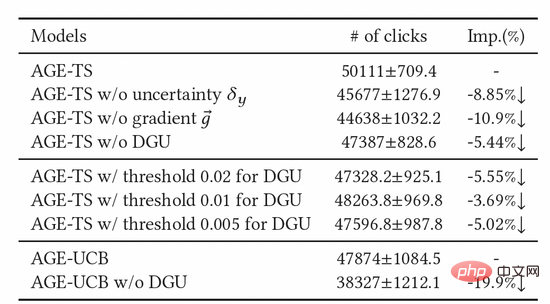
Abbildung 3: Fair-Bucket-Experimentplan
Wie in Tabelle 3 gezeigt, wurden die oben genannten Indikatoren effektiv verbessert. Unter diesen übertrifft AGE alle anderen Methoden deutlich: CTR und PV sind 6,4 % bzw. 3,0 % höher als das Basismodell. Gleichzeitig verbessert die Verwendung des AGE-Modells auch die Vorhersagegenauigkeit des Modells, dh die Vorhersagegenauigkeit PCOC liegt näher bei 1. Noch wichtiger ist, dass auch der AFR-Indikator um 5,5 % gestiegen ist, was zeigt, dass unsere Explorationsmethode das Werbeerlebnis effektiv verbessern kann. 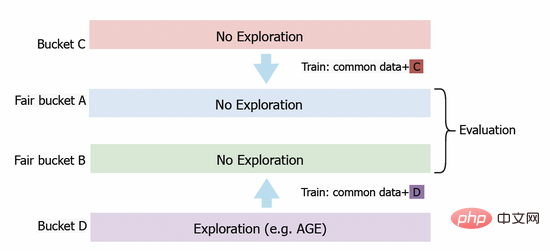
Tabelle 3: Online-Experimentergebnisse
5. Zusammenfassung 
Das obige ist der detaillierte Inhalt vonAuf dem kontradiktorischen Gradienten basierendes Explorationsmodell und seine Anwendung bei der Klickvorhersage. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 So machen Sie das Löschen vom Startbildschirm im iPhone rückgängig
Apr 17, 2024 pm 07:37 PM
So machen Sie das Löschen vom Startbildschirm im iPhone rückgängig
Apr 17, 2024 pm 07:37 PM
Sie haben etwas Wichtiges von Ihrem Startbildschirm gelöscht und versuchen, es wiederherzustellen? Es gibt verschiedene Möglichkeiten, App-Symbole wieder auf dem Bildschirm anzuzeigen. Wir haben alle Methoden besprochen, die Sie anwenden können, um das App-Symbol wieder auf dem Startbildschirm anzuzeigen. So machen Sie das Entfernen vom Startbildschirm auf dem iPhone rückgängig. Wie bereits erwähnt, gibt es mehrere Möglichkeiten, diese Änderung auf dem iPhone wiederherzustellen. Methode 1 – App-Symbol in der App-Bibliothek ersetzen Sie können ein App-Symbol direkt aus der App-Bibliothek auf Ihrem Startbildschirm platzieren. Schritt 1 – Wischen Sie seitwärts, um alle Apps in der App-Bibliothek zu finden. Schritt 2 – Suchen Sie das App-Symbol, das Sie zuvor gelöscht haben. Schritt 3 – Ziehen Sie einfach das App-Symbol aus der Hauptbibliothek an die richtige Stelle auf dem Startbildschirm. Dies ist das Anwendungsdiagramm
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
