

Erstellung eines Automotive-Wissensgraphen zur Empfehlung

Hintergrund
1. Einführung
Das Konzept des Wissensgraphen wurde erstmals 2012 von Google mit dem Ziel vorgeschlagen, eine intelligentere Suchmaschine zu schaffen, und 2013 später Es wurde in der Wissenschaft und Industrie populär. Mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz werden Wissensgraphen derzeit in großem Umfang in den Bereichen Suche, Empfehlung, Werbung, Risikokontrolle, intelligente Planung, Spracherkennung, Roboter und anderen Bereichen eingesetzt.
2. Entwicklungsstand
Als Kerntechnologie der künstlichen Intelligenz kann der Wissensgraph das Problem des tiefen Lernens lindern, das auf riesigen Trainingsdaten und großer Rechenleistung beruht Es ist vielseitig einsetzbar, lässt sich an verschiedene nachgelagerte Aufgaben anpassen und ist gut interpretierbar. Daher setzen große Internetunternehmen auf der ganzen Welt aktiv ihre eigenen Wissensgraphen ein.
Facebook veröffentlichte beispielsweise 2013 Open Graph, das für die intelligente Suche in sozialen Netzwerken verwendet wurde, und Baidu startete 2014 den Knowledge Graph, der hauptsächlich im Such-, Assistenten- und ToB-Geschäft eingesetzt wurde Im Jahr 2015 hat Alibaba Produktwissensdiagramme eingeführt, die eine Schlüsselrolle in Front-End-Einkaufsführern, Plattform-Governance und intelligenten Fragen und Antworten spielen. Das von Tencent im Jahr 2017 eingeführte Tencent Cloud Knowledge Graph unterstützt effektiv Szenarien wie die Finanzsuche und die Vorhersage von Unternehmensrisiken. Meituan hat Meituan im Jahr 2018 eingeführt. Tuannao Knowledge Graph wurde in mehreren Unternehmen implementiert, beispielsweise bei intelligenten Suchempfehlungen und intelligenten Händlerabläufen.
3. Ziele und Vorteile
Derzeit konzentriert sich die Domain-Map hauptsächlich auf Geschäftsfelder wie E-Commerce , medizinische Versorgung und Finanzen Es mangelt jedoch an einer systematischen Leitmethode für den Aufbau eines semantischen Netzwerks und eines Wissensgraphen des Automobilwissens. Dieser Artikel nimmt als Beispiel Kenntnisse im Automobilbereich und konzentriert sich auf Entitäten und Beziehungen wie Autoserien, Modelle, Händler, Hersteller, Marken usw., um eine Idee für die Erstellung einer Domänenkarte von Grund auf zu liefern, und beschreibt die Schritte und Einzelheiten Methoden zur Erstellung einer Wissenslandkarte und stellt einige typische Anwendungen vor, die auf dieser Karte basieren.
Die Datenquelle ist unter anderem die Autohome-Website, eine Automobil-Serviceplattform, die aus mehreren Bereichen wie Einkaufsführer, Informationen, Bewertungen und Mundpropaganda besteht Eine große Menge an Automobildaten wird organisiert und ausgewertet, indem ein Wissensgraph erstellt wird, um autobezogene Inhalte zu organisieren und auszuwerten, umfassende Wissensinformationen bereitzustellen, Interessen auf strukturierte Weise genau zu beschreiben und mehrere Dimensionen zu unterstützen B. Kaltstart, Rückruf, Sortierung und Anzeige empfohlener Benutzer. Bringen Sie Auswirkungen auf die Geschäftsverbesserung.
2. Graphkonstruktion
1. Konstruktionsherausforderung
Wissensgraph ist eine semantische Darstellung der realen Welt und seine Grundeinheit ist [Entität ] -Relationship-Entity], [Entity-Attribute-Attribute Value] Triplett (Triplett), Entitäten sind durch Beziehungen miteinander verbunden und bilden so ein semantisches Netzwerk. Die Diagrammerstellung wird größere Herausforderungen mit sich bringen, aber nach der Erstellung kann sie in mehreren Szenarien wie Datenanalyse, Empfehlungsberechnung und Interpretierbarkeit einen hohen Anwendungswert zeigen.
Aufbauherausforderungen:
- Schema ist schwer zu definieren: Derzeit gibt es keinen einheitlichen und ausgereiften Ontologiekonstruktionsprozess und keine einheitliche Domäne -spezifische Ontologiedefinitionen In der Regel ist die Mitwirkung von Experten erforderlich. und unstrukturierte Daten, angesichts der Daten mit unterschiedlichen Strukturen sind Wissenstransfer und Mining schwieriger; Automodelle erfordern Kenntnisse in vielen Bereichen wie Mechanik, Elektrotechnik, Werkstoffe, Mechanik usw., und bei solchen Zusammenhängen muss sichergestellt werden, dass die Kenntnisse korrekt genug sind Für eine effiziente Erstellung sind außerdem Experten und Algorithmen erforderlich. Die Qualität der Daten ist nicht garantiert: Die Gewinnung oder Extraktion von Informationen erfordert eine Wissensfusion oder manuelle Überprüfung, bevor sie als Wissen zur Unterstützung nachgelagerter Anwendungen verwendet werden kann.
- Vorteil:
Reichhaltige semantische Informationen: Durch relationales Denken können neue Beziehungskanten entdeckt und umfangreichere semantische Informationen erhalten werden;
Starke Interpretierbarkeit: Explizite Argumentationspfadvergleichstiefe Lernergebnisse sind besser interpretierbar;- Hohe Qualität und kontinuierliche Akkumulation: Entwerfen Sie eine angemessene Wissensspeicherlösung basierend auf Geschäftsszenarien, um eine Wissensaktualisierung und -akkumulation zu erreichen.
- 2. Diagrammarchitekturdesign
- Die technische Architektur ist hauptsächlich in drei Schichten unterteilt: Konstruktionsschicht, Speicherschicht und Anwendungsschicht :
-
- Konstruktionsschicht: umfasst Schemadefinition, strukturierte Datentransformation, unstrukturiertes Data Mining und Wissensfusion;
- Speicherschicht: umfasst Wissensspeicherung und -indizierung, Wissensaktualisierung, Metadatenverwaltung und unterstützt grundlegende Wissensabfragen;
- Serviceschicht: einschließlich Intelligentes Denken, strukturierte Abfragen und andere geschäftsbezogene nachgelagerte Anwendungsschichten.

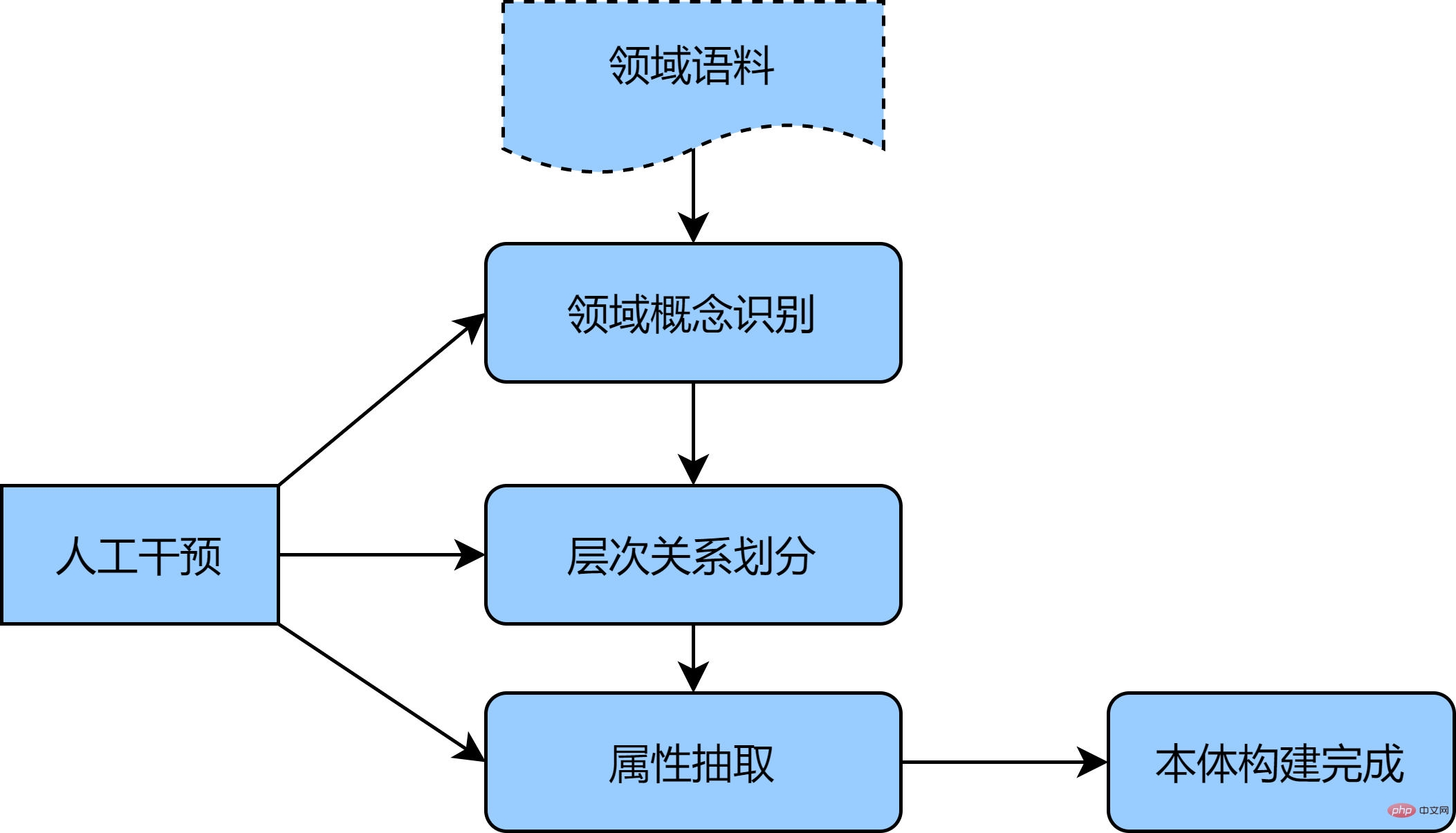
3. Spezifische Konstruktionsschritte und -prozesse
Gemäß dem Architekturdiagramm kann der spezifische Konstruktionsprozess in vier Schritte unterteilt werden: Ontologieentwurf, Wissenserwerb, Wissenslagerung sowie Entwurf und Nutzung von Anwendungsdiensten.
3.1 Ontologiekonstruktion
Ontologie ist eine anerkannte Sammlung von Konzepten Die Konstruktion der Ontologie bezieht sich auf die Konstruktion der Ontologiestruktur und des Wissensrahmens des Wissensgraphen basierend auf der Definition der Ontologie.
Die Hauptgründe für die Erstellung eines auf Ontologie basierenden Diagramms sind folgende:
- Klare Fachbegriffe, Beziehungen und Domänenaxiome. Wenn ein Datenelement den durch Schema vordefinierten Entitätsobjekten und -typen entsprechen muss, ist dies zulässig aktualisiert werden, um Wissen in der Karte zu erhalten.
- Trennung von Domänenwissen und Betriebswissen Durch Schema erhalten Sie ein makroskopisches Verständnis der Diagrammstruktur und der zugehörigen Definitionen, ohne dass Sie Tripel zusammenfassen und organisieren müssen.
- Erreichen Sie ein gewisses Maß an Wiederverwendung von Domänenwissen. Bevor Sie eine Ontologie erstellen, können Sie zunächst untersuchen, ob eine relevante Ontologie erstellt wurde, sodass Sie die vorhandene Ontologie verbessern und erweitern können, um mit halbem Aufwand das Doppelte des Ergebnisses zu erzielen.
- Eine auf der Ontologie basierende Definition kann die Situation vermeiden, dass das Diagramm von der Anwendung getrennt wird oder die Kosten für die Änderung des Diagrammschemas höher sind als für die Neuerstellung. Beispielsweise kann das Speichern von „BMW x3“ und „2022 BMW x3“ als Autoentitäten zu Verwirrung in den Instanzbeziehungen und einer schlechten Benutzerfreundlichkeit führen. Diese Situation kann durch die Konvertierung von „Auto“ in die Ontologie-Designphase gelöst werden Unterteilung der Unterkategorien „Autoserie“ und „Modell“ in „Klasseneinheiten“.
Je nach Wissensabdeckung können Wissensgraphen in allgemeine Wissensgraphen und Domänenwissensgraphen unterteilt werden. Derzeit gibt es viele Fälle von allgemeinen Wissensgraphen, wie z. B. den Wissensgraphen von Google, Satori und Probase von Microsoft usw Domänendiagramme sind wie folgt: Karten bestimmter Branchen wie Finanzen und E-Commerce. Allgemeine Diagramme legen mehr Wert auf die Breite und betonen die Integration mehrerer Entitäten, stellen jedoch keine hohen Anforderungen an die Genauigkeit. Es ist schwierig, Axiome, Regeln und Einschränkungen mithilfe von Ontologiebibliotheken zu begründen und zu verwenden ist kleiner, aber die Tiefe des Wissens ist tiefer und wird oft in einem bestimmten Berufsfeld aufgebaut.
In Anbetracht der Anforderungen an die Genauigkeit erfolgt die Erstellung der Domänenontologie in der Regel manuell, z. B. die repräsentative Sieben-Schritte-Methode, die IDEF5-Methode usw. [1] Die Kernidee dieser Art von Methode basiert auf vorhandenen Strukturierte Daten, Führen Sie eine Ontologieanalyse durch, fassen Sie eine Ontologie zusammen und erstellen Sie sie, die dem Anwendungszweck und -umfang entspricht, und optimieren und überprüfen Sie dann die Ontologie, um die erste Version der Ontologiedefinition zu erhalten. Wenn Sie eine größere Domänen-Ontologie erhalten möchten, können Sie diese aus einem unstrukturierten Korpus ergänzen. Da der manuelle Erstellungsprozess relativ umfangreich ist, wird in diesem Artikel der Automobilbereich als Beispiel herangezogen, um eine halbautomatische Ontologie-Konstruktionsmethode bereitzustellen sind wie folgt:
- Zunächst wird eine große Menge an unstrukturiertem Automobilkorpus (wie Autoberatung, Neuwagen-Einkaufsratgeberartikel usw.) als anfänglicher individueller Konzeptsatz gesammelt und statistische Methoden oder unbeaufsichtigte Modelle (TF- IDF, BERT usw.) werden verwendet, um Zeichen- und Wortmerkmale zu erhalten.
- Zweitens wird der BIRCH-Clustering-Algorithmus verwendet, um die Konzepte in Hierarchien zu unterteilen, zunächst die hierarchische Beziehung zwischen Konzepten zu konstruieren und eine manuelle Konzeptüberprüfung und -induktion durchzuführen die Clustering-Ergebnisse, um die äquivalenten, übergeordneten und untergeordneten Konzepte der Ontologie zu erhalten;
- Schließlich wird das Volumen verwendet. Das kumulative neuronale Netzwerk wird mit der Fernüberwachungsmethode kombiniert, um die Entitätsbeziehungen der Ontologieattribute zu extrahieren, und wird durch manuelle Identifizierung ergänzt der Konzepte von Klassen und Attributen in der Ontologie, um die Ontologie der Automobildomäne zu konstruieren.
Die obige Methode kann Deep-Learning-Technologien wie BERT effektiv nutzen, um die internen Beziehungen zwischen Korpussen besser zu erfassen, Clustering verwenden, um jedes Modul der Ontologie hierarchisch aufzubauen, und es durch manuelle Eingriffe ergänzen, um die Vorläufigkeit schnell und genau abzuschließen Ontologie. Das Bild unten ist ein schematisches Diagramm der halbautomatischen Ontologiekonstruktion:
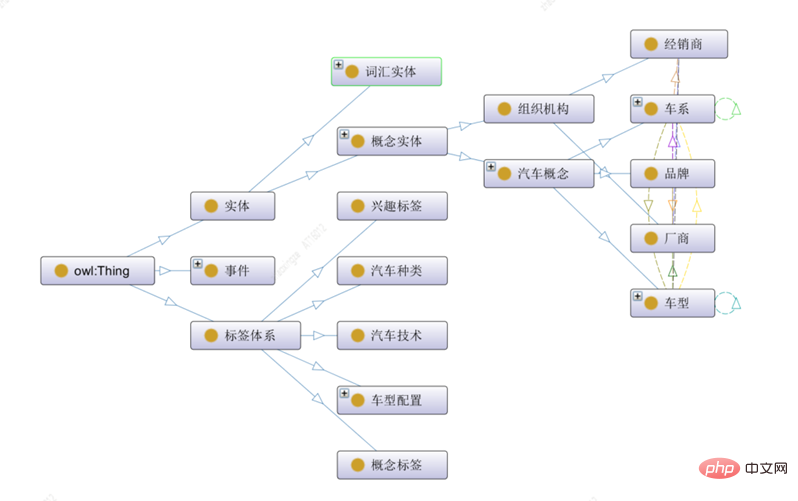
Mit dem Protégé Ontologiekonstruktionstool [2] können Sie Ontologiekonzeptklassen, Beziehungen, Attribute und Instanzen erstellen ist ein visuelles Beispiel für die Konstruktion von Ontologien:
Dieser Artikel unterteilt die Ontologiekonzepte der obersten Ebene im Automobilbereich in drei Kategorien: Entitäten, Ereignisse und Etikettensysteme:
1) Die Entitätsklasse stellt konzeptionelle Entitäten mit spezifischen Bedeutungen dar, einschließlich lexikalischer Entitäten und Automobilentitäten. Die Automobilentitäten umfassen auch Unterentitätstypen wie Organisationen und Automobilkonzepte.
2) Das Etikettensystem stellt das Etikettensystem jeder Dimension dar , Einschließlich Inhaltsklassifizierung, Konzept-Tags, Interessen-Tags und anderen in der materiellen Dimension beschriebenen Tags
3) Ereignisklassen repräsentieren die objektiven Fakten einer oder mehrerer Rollen, und es besteht eine evolutionäre Beziehung zwischen verschiedenen Arten von Ereignissen.
Protégé kann verschiedene Arten von Schemakonfigurationsdateien exportieren, darunter die Strukturkonfigurationsdatei Owl.xml wie in der Abbildung unten dargestellt. Diese Konfigurationsdatei kann direkt geladen und in MYSQL und JanusGraph verwendet werden, um eine automatische Schemaerstellung zu realisieren.
3.2 Wissenserwerb
Die Datenquellen von Wissensgraphen umfassen normalerweise drei Arten von Datenstrukturen, nämlich strukturierte Daten, halbstrukturierte Daten und unstrukturierte Daten. Für verschiedene Arten von Datenquellen sind die Schlüsseltechnologien zur Wissensextraktion und die technischen Schwierigkeiten, die gelöst werden müssen, unterschiedlich.
3.2.1 Strukturierte Wissenstransformation
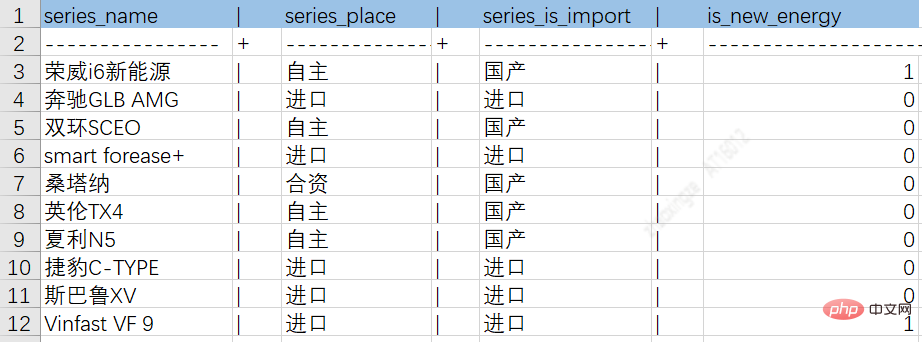
Strukturierte Daten sind die direkteste Wissensquelle für Diagramme. Sie können grundsätzlich durch vorläufige Konvertierung verwendet werden, die Kosten sind daher im Allgemeinen am niedrigsten Priorität für Diagrammdaten eingeräumt. Strukturierte Daten können mehrere Datenbankquellen umfassen und erfordern normalerweise die Verwendung von ETL-Methoden zum Konvertieren des Modells. ETL bezieht sich auf Extrahieren (Extrahieren), Transformieren (Konvertieren) und Laden (Laden) zum Lesen von Daten aus verschiedenen ursprünglichen Geschäftssystemen . Die Voraussetzung aller Konvertierungen besteht darin, die extrahierten Daten nach vorgefertigten Regeln zu konvertieren, sodass die ursprünglich heterogenen Datenformate wie geplant inkrementell oder vollständig importiert werden können das Lager.
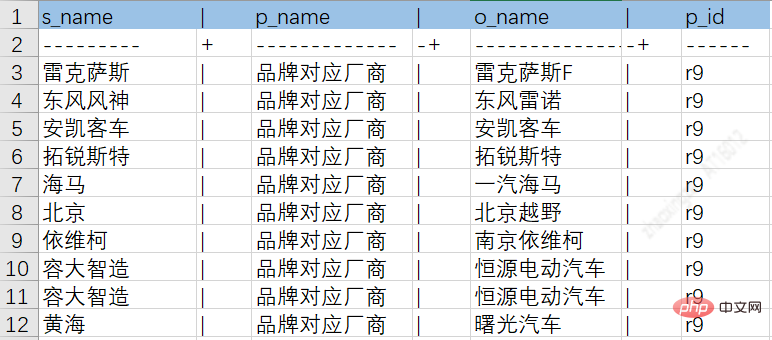
Durch den oben genannten ETL-Prozess können Daten aus verschiedenen Quellen in Zwischentabellen abgelegt werden, wodurch die spätere Wissensspeicherung erleichtert wird. Das folgende Bild ist ein Beispieldiagramm für Autoserien-Entitätsattribute und Beziehungstabellen:
Autoserien- und Markenbeziehungstabelle:
3.2.2 Unstrukturierte Wissensextraktion – Dreifache Extraktion
Zusätzlich zu strukturiert Daten: Auch in unstrukturierten Daten stecken enorme Mengen an Wissensinformationen (Triples). Im Allgemeinen ist die Menge an unstrukturierten Daten in einem Unternehmen viel größer als strukturierte Daten. Durch das Mining unstrukturierter Daten kann der Wissensgraph erheblich erweitert und bereichert werden.
Herausforderungen des Dreifachextraktionsalgorithmus
Problem 1: Innerhalb einer einzelnen Domäne sind Dateiinhalt und -format vielfältig, erfordern eine große Menge annotierter Daten und die Kosten sind hoch
Problem 2: Der Migrationseffekt zwischen Die domänenübergreifende Skalierung ist kostspielig. Modelle sind grundsätzlich für bestimmte Szenarien in bestimmten Branchen konzipiert.
Lösungsidee, das Paradigma von Pre-Train + Finetune, Pre-Training: Die schwere Basis ermöglicht es dem Modell, „mehr zu sehen“ und die umfangreichen und branchenübergreifenden unbeschrifteten Dokumente voll auszunutzen, um ein einheitliches Pre-Training zu trainieren. Trainingsbasis. Verbessern Sie die Fähigkeit des Modells, verschiedene Arten von Dokumenten darzustellen und zu verstehen.
Feinabstimmung: Leichter Algorithmus zur Dokumentenstrukturierung. Basierend auf dem Vortraining wird ein leichter, dokumentorientierter strukturierter Algorithmus erstellt, um die Etikettierungskosten zu senken.
Vortrainingsmethode für DokumenteEs gibt vorhandene Vortrainingsmodelle für Dokumente. Wenn der Text kurz ist, kann Bert das gesamte Dokument vollständig codieren, während viele der Attributwerte länger sind Die zu extrahierenden Zeichen umfassen mehr als 1024 Zeichen und die Codierung von Bert führt dazu, dass die Attributwerte abgeschnitten werden.
Zielt auf die Vor- und Nachteile von Langtext-Vortrainingsmethoden abDie Sparse-Attention-Methode optimiert die Berechnung von O(n2) zu O(n) durch Optimierung der Selbstaufmerksamkeit, wodurch die Eingabetextlänge erheblich verbessert wird . Obwohl die Textlänge des normalen Modells von 512 auf 4096 erhöht wurde, kann das Fragmentierungsproblem von abgeschnittenem Text immer noch nicht vollständig gelöst werden. Baidu schlug ERNIE-DOC [3] unter Verwendung der Recurrence Transformer-Methode vor, mit der theoretisch unbegrenzter Text modelliert werden kann. Da für die Modellierung die Eingabe aller Textinformationen erforderlich ist, ist sie sehr zeitaufwändig.
Die beiden oben genannten Vortrainingsmethoden basierend auf Langtext berücksichtigen keine Dokumentmerkmale wie räumliche (Spartial), visuelle (Visual) und andere Informationen. Und die auf dem Textdesign basierende PretrainTask ist für den reinen Text als Ganzes konzipiert, ohne die logische Struktur des Dokuments.
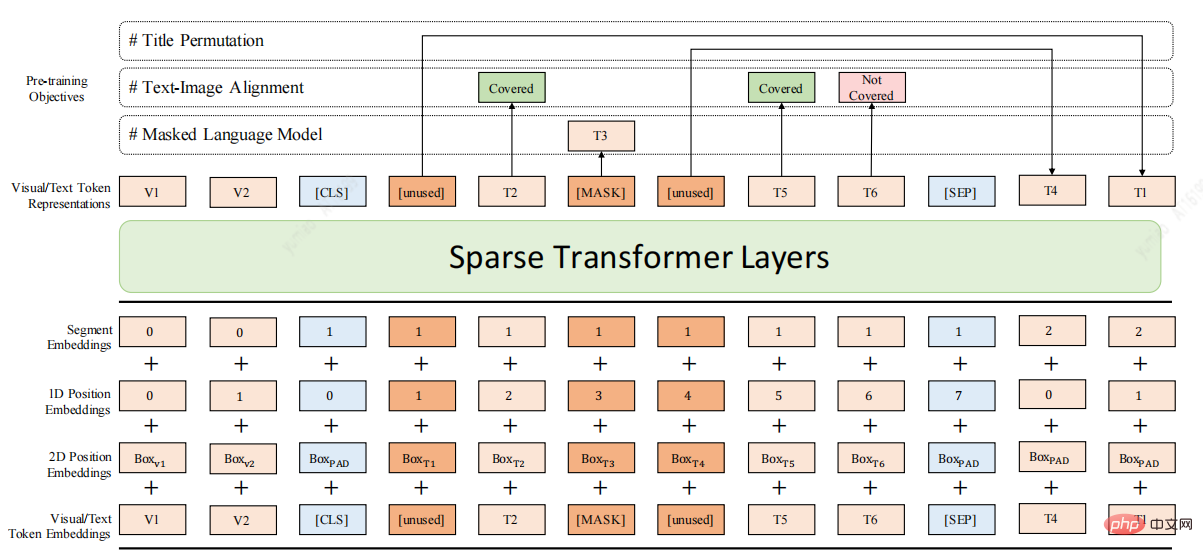
Angesichts der oben genannten Mängel finden Sie hier ein Dokument zum Vortrainingsmodell DocBert [4], DocBert-Modelldesign:
Verwenden Sie umfangreiche (Millionen Ebenen) unbeschriftete Dokumentdaten für das Vortraining und erstellen Sie selbstüberwachtes Lernen basierend auf der Textsemantik (Text), den Layoutinformationen (Layout) und den visuellen Funktionen (Visual) des Dokumentaufgaben, damit das Modell die Dokumentsemantik und Strukturinformationen besser verstehen kann.
1.Layout-fähiges MLM: Berücksichtigen Sie die Positions- und Schriftgrößeninformationen des Textes im Mask-Sprachmodell, um ein semantisches Verständnis für das Dokumentlayout zu erreichen.
2.Text-Bild-Ausrichtung: Fusion visueller Dokumentmerkmale, Rekonstruktion des maskierten Texts im Bild, Unterstützung des Modells beim Erlernen der Ausrichtungsbeziehung zwischen verschiedenen Text-, Layout- und Bildmodi.
3.Titelpermutation: Erstellen Sie die Titelrekonstruktionsaufgabe auf selbstüberwachte Weise, um die Fähigkeit des Modells zu verbessern, die logische Struktur des Dokuments zu verstehen.
4.Sparse Transformer Layers: Verwenden Sie die Sparse Attention-Methode, um die Fähigkeit des Modells zur Verarbeitung langer Dokumente zu verbessern.
3.2.3 Bergbaukonzepte, Interessenwort-Tags, bezogen auf Autoserien und Entitäten
Zusätzlich zu strukturiert und unstrukturiert Durch die Gewinnung von Tripeln aus dem Text analysiert Autohome auch die in den Materialien enthaltenen Klassifizierungen, Konzept-Tags und Interessenschlüsselwort-Tags und stellt die Verbindung zwischen den Materialien und Fahrzeugeinheiten her, wodurch neues Wissen in den Automobil-Wissensgraphen eingebracht wird. Im Folgenden finden Sie eine Einführung in einige der von Autohome durchgeführten Arbeiten und Überlegungen zum Inhaltsverständnis aus der Perspektive der Klassifizierung, Konzept-Tags und Interessenwort-Tags.
Das Klassifizierungssystem dient als Grundlage für die Inhaltsbeschreibung und bietet eine grobkörnige Klassifizierung von Materialien. Das etablierte einheitliche Content-System basiert eher auf manueller Definition und ist durch KI-Modelle gegliedert. Was die Klassifizierungsmethoden betrifft, verwenden wir aktives Lernen, um Daten zu kennzeichnen, die schwer zu klassifizieren sind. Wir verwenden auch Datenverbesserung, kontradiktorisches Training und Schlüsselwortfusion, um den Klassifizierungseffekt zu verbessern.
Die Konzeptbezeichnungsgranularität liegt zwischen Klassifizierungs- und Interessenwortbezeichnungen, was feiner als die Klassifizierungsgranularität und vollständiger als das Interessenwort zur Beschreibung von Punkten ist Interesse Wir haben drei Dimensionen etabliert: Fahrzeugvision, menschliche Vision und Inhaltsvision, um die Etikettendimension zu bereichern und die Etikettengranularität zu verfeinern. Umfangreiche und spezifische Material-Tags erleichtern die Suche und Empfehlung einer Tag-basierten Modelloptimierung und können für die Tag-Reichweite verwendet werden, um Benutzer und Sekundärverkehr anzulocken. Das Mining von Konzept-Tags kombiniert den Einsatz maschineller Mining-Methoden für wichtige Daten wie Abfragen und Generalisierungsanalysen. Durch manuelle Überprüfung erhalten wir eine Reihe von Konzept-Tags und verwenden ein Multi-Label-Modell zur Klassifizierung.
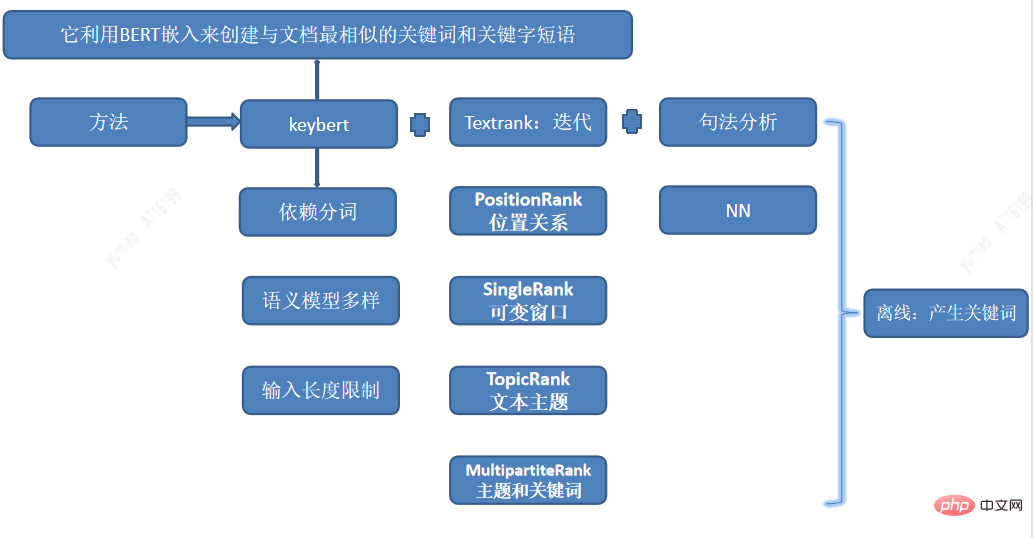
Interessenwort-Tags sind die feinkörnigen Tags und werden den Benutzerinteressen zugeordnet, sodass personalisierte Empfehlungen besser abgegeben werden können. Das Keyword-Mining verwendet eine Kombination mehrerer Methoden zum Mining von Interessenwörtern, einschließlich Keybert, um wichtige Teilzeichenfolgen zu extrahieren, und kombiniert TextRank, PositionRank, Singlerank, TopicRank, MultipartiteRank usw. + syntaktische Analysemethoden, um Kandidaten für Interessenwörter zu generieren.
Die ausgegrabenen Wörter weisen eine relativ hohe Ähnlichkeit auf, daher müssen Synonyme identifiziert und die manuelle Effizienz verbessert werden, sodass wir sie auch durch semantisches Clustering automatisieren Ähnlichkeitserkennung. Zu den für das Clustering verwendeten Funktionen gehören Word2vec, Bert Emding und andere künstliche Funktionen. Mithilfe der Clustering-Methode und schließlich durch manuelle Korrektur haben wir offline einen Stapel hochwertiger Schlüsselwörter generiert.
Für Etiketten mit unterschiedlicher Granularität oder auf Materialebene müssen wir das Etikett dem Auto zuordnen. Zuerst berechnen wir das Etikett des jeweiligen Titelartikels und identifizieren dann die Entitäten im Titelartikel , und erhalten Sie mehrere Label-Entitäts-Pseudo-Labels. Basierend auf einer großen Menge an Korpus werden Labels mit hoher Wahrscheinlichkeit des gemeinsamen Vorkommens schließlich als Label der Entität markiert. Durch die oben genannten drei Aufgaben haben wir reichhaltige und umfangreiche Etiketten erhalten. Durch die Verknüpfung dieser Tags mit Autoserien und -entitäten wird unsere Autokarte erheblich bereichert und Auto-Tags erstellt, die die Aufmerksamkeit der Medien und Benutzer auf sich ziehen.
3.2.4 Verbesserung der menschlichen Effizienz:
Wie erhält man bei größeren Trainingsstichproben eine bessere Modellqualität, wie löst man das Problem der hohen Etikettierungskosten und des langen Etikettierungszyklus? Dringendes Problem gelöst werden. Erstens können wir halbüberwachtes Lernen nutzen, um riesige, unbeschriftete Daten für das Vortraining zu nutzen. Dann wird eine aktive Lernmethode verwendet, um den Wert der annotierten Daten zu maximieren und iterativ hochinformative Proben für die Annotation auszuwählen. Schließlich kann die Fernüberwachung genutzt werden, um den Wert des vorhandenen Wissens zu nutzen und den Zusammenhang zwischen Aufgaben zu entdecken. Nachdem Sie beispielsweise die Karte und den Titel erhalten haben, können Sie mithilfe der Fernüberwachungsmethode NER-Trainingsdaten basierend auf der Karte erstellen.
3.3 知识入库
知识图谱中的知识是通过RDF结构来进行表示的,其基本单元是事实。每个事实是一个三元组(S, P, O),在实际系统中,按照存储方式的不同,知识图谱的存储可以分为基于RDF表结构的存储和基于属性图结构的存储。图库更多是采用属性图结构的存储,常见的存储系统有Neo4j、JanusGraph、OritentDB、InfoGrid等。
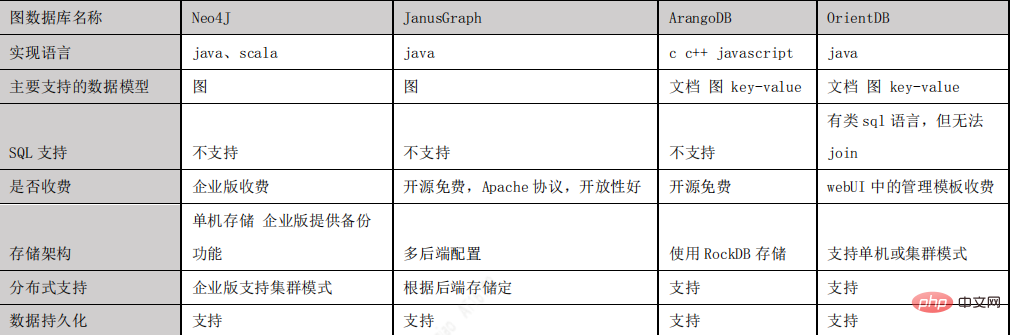
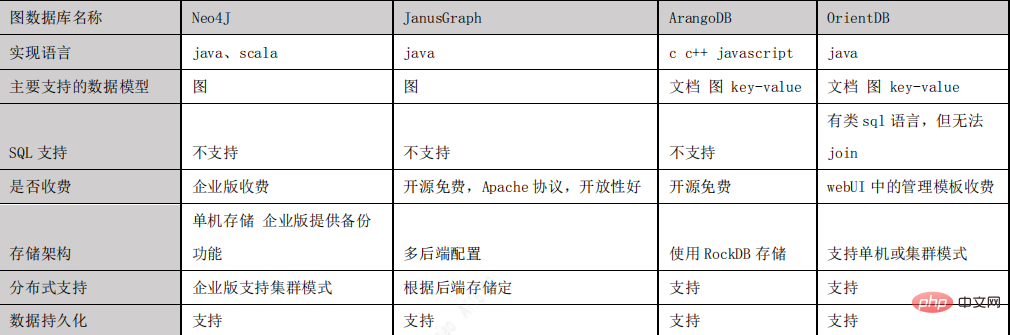
图数据库选择
通过JanusGraph 与 Neo4J、ArangoDB、OrientDB 这几种主流图数据库的对比,我们最终选择JanusGraph 作为项目的图数据库,之所以选择 JanusGraph,主要有以下原因:
- 基于 Apache 2 许可协议开放源码,开放性好。
- 支持使用 Hadoop 框架进行全局图分析和批量图处理。
- 支持很大的并发事务处理和图操作处理。通过添加机器横向扩展 JanusGraph 的事务 处理能力,可以在毫秒级别相应大图的复杂查询。
- 原生支持 Apache TinkerPop 描述的当前流行的属性图数据模型。
- 原生支持图遍历语言 Gremlin。
- 下图是主流图数据库对比:
Janusgraph介绍
JanusGraph[5]是一个图形数据库引擎。其本身专注于紧凑图序列化、丰富图数据建模、高效的查询执行。图库schema 构成可以用下面一个公式来表示:
janusgraph schema = vertex label + edge label + property keys
这里值得注意的是property key通常用于graph index。
为了更好的图查询性能janusgraph建立了索引,索引分为Graph Index,Vertex-centric Indexes。Graph Index包含组合索引(Composite Index)和混合索引(Mixed Index).
组合索引仅限相等查找。(组合索引不需要配置外部索引后端,通过主存储后端支持(当然也可以配置hbase,Cassandra,Berkeley))
举例:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">mgmt</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">buildIndex</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'byNameAndAgeComposite'</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Vertex</span>.<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">class</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">addKey</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">name</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">addKey</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">age</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">buildCompositeIndex</span>() <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">#构建一个组合索引“name</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">-</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">age”</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'age'</span>, <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">30</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'小明'</span>)<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">#查找</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">名字为小明年龄30的节点</span>
Nach dem Login kopieren混合索引需要ES作为后端索引以支持除相等以外的多条件查询(也支持相等查询,但相等查询,组合索引更快)。根据是否需要分词分为full-text search,和string search
JanusGraph数据存储模型
了解Janusgraph存储数据的方式,有助于我们更好的利用该图库。JanusGraph 以邻接列表格式存储图形,这意味着图形存储为顶点及其邻接列表的集合。
顶点的邻接列表包含顶点的所有入射边(和属性)。JanusGraph 将每个邻接列表作为一行存储在底层存储后端中。 (64 位)顶点 ID(JanusGraph 唯一分配给每个顶点)是指向包含顶点邻接列表的行的键。
每个边和属性都存储为行中的一个单独的单元格,允许有效的插入和删除。 因此,特定存储后端中每行允许的最大单元数也是JanusGraph 可以针对该后端支持的顶点的最大度数。如果存储后端支持key-order,则邻接表将按顶点 id 排序,JanusGraph可以分配顶点 id,以便对图进行有效分区。 分配 id 使得经常共同访问的顶点具有绝对差异小的 id。
3.4 图谱查询服务
Janusgraph进行图搜索用的是gremlin语言,我们提供了统一的图谱查询服务,外部使用不用关心gremlin语言的具体实现,采用通用的接口进行查询。我们分为三个接口:条件搜索接口,以节点为中心向外查询,和节点间路径查询接口。下面是几个gremlin实现的例子:
- 条件搜索:查询10万左右,销量最高的车:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'price'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">gt</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">8</span>)).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'price'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">lt</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">12</span>)).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">order</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">by</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'sales'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">desc</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">valueMap</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">limit</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">1</span>)
Nach dem Login kopieren输出:
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span>{<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">name</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xuanyi</span>], <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">price</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span>], <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sales</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">45767</span>]}Nach dem Login kopieren轩逸销量最高,为45767
- 以节点为中心向外查询:查询以小明为中心,2度的节点
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">repeat</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">out</span>()).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">times</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">2</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">valueMap</span>()
Nach dem Login kopieren- 节点间路径查询:荐给小明推荐两篇文章,这两篇文章分别介绍的是卡罗拉和轩逸,查询小明和 这两篇文章的路径:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">repeat</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">out</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">simplePath</span>()).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">until</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">or</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"car"</span>,<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'kaluola'</span>),<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"car"</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>,<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'xuanyi'</span>))).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">by</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"name"</span>)
Nach dem Login kopieren输出
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">around</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">w</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">kaluola</span>]<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">around</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">w</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xuanyi</span>]
Nach dem Login kopieren发现小明和这两篇文章之间有个节点“10万左右”
3. Wissensgraph in empfohlenen Anwendungen
Der Wissensgraph enthält eine große Menge nichteuropäischer Daten. Auf KG basierende Empfehlungsanwendungen nutzen effektiv nichteuropäische Daten, um die Genauigkeit des Empfehlungssystems zu verbessern Empfehlungssystem zu erreichen, was herkömmliche Systeme nicht erreichen können. Auf KG basierende Empfehlungen können in drei Kategorien unterteilt werden: basierend auf der KG-Darstellungstechnologie (KGE), der pfadbasierten Methode und dem graphischen neuronalen Netzwerk. In diesem Kapitel werden die Bewerbungen und Papiere von KG in drei Aspekten vorgestellt: Kaltstart, Grund und Rangfolge in Empfehlungssystemen.
3.1 Anwendung des Wissensgraphen bei der Empfehlung eines Kaltstarts
Der Wissensgraph kann die in KG verborgenen Beziehungen höherer Ordnung aus Benutzer-Element-Interaktionen modellieren, wodurch die Datenspärlichkeit, die durch Benutzer verursacht wird, die eine begrenzte Anzahl von Verhaltenseigenschaften aufrufen, gut gelöst werden kann und kann zur Lösung des Kaltstartproblems eingesetzt werden. Auch in der Branche gibt es entsprechende Studien zu diesem Thema.
Sang et al. [6] schlugen eine zweikanalige neuronale Interaktionsmethode namens Knowledge Graph Enhanced Recurrent Neural Collaborative Filtering (KGNCF-RRN) vor, die die langfristigen Beziehungsabhängigkeiten von KG-Kontext und Benutzer-Element-Interaktionen ausnutzt .
(1) Für den kontextuellen Interaktionskanal von KG wird ein Residual Recurrent Network (RRN) vorgeschlagen, um eine kontextbasierte Pfadeinbettung zu konstruieren, und Residual Learning wird in das traditionelle Recurrent Neural Network (RNN) integriert, um das Langzeitverhalten effektiv zu kodieren von KG Relationale Abhängigkeit. Anschließend werden Selbstaufmerksamkeitsnetzwerke auf Pfadeinbettungen angewendet, um die Mehrdeutigkeit verschiedener Benutzerinteraktionsverhaltensweisen zu erfassen.
(2) Für den Benutzer-Element-Interaktionskanal werden Benutzer- und Element-Einbettungen in das neu gestaltete 2D-Interaktionsdiagramm eingegeben.
(3) Schließlich wird zusätzlich zur zweikanaligen neuronalen Interaktionsmatrix ein Faltungs-Neuronales Netzwerk verwendet, um die komplexe Korrelation zwischen Benutzern und Elementen zu lernen. Diese Methode kann umfangreiche semantische Informationen erfassen und auch komplexe implizite Beziehungen zwischen Benutzern und Elementen für Empfehlungen erfassen.
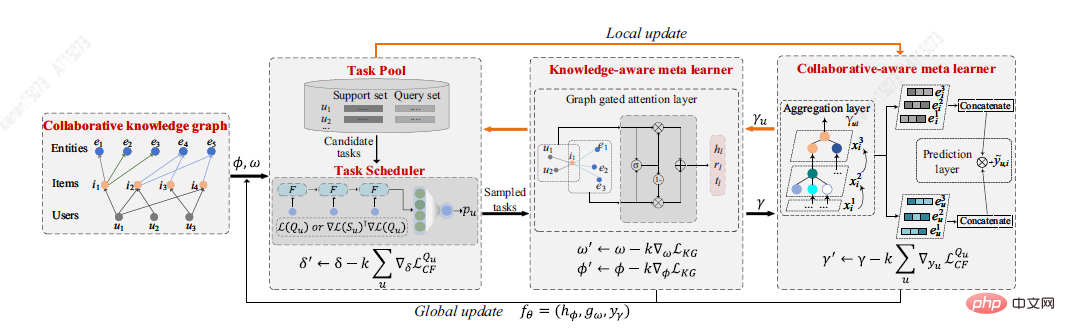
Du Y et al. [7] schlugen eine neue Lösung für das Kaltstartproblem vor, die auf dem Meta-Lernrahmen MetaKG basiert, einschließlich kollaborativem Meta-Lerner und wissensbewusstem Meta-Lerner, der Benutzerpräferenzen und Entitäts-Kaltstartwissen erfasst . Die kollaborativ bewusste Meta-Lerner-Lernaufgabe zielt darauf ab, die bevorzugte Wissensrepräsentation jedes Benutzers zusammenzufassen. Im Gegensatz dazu besteht die wissensbewusste Lernaufgabe des Meta-Lernenden darin, verschiedene vom Benutzer bevorzugte Wissensdarstellungen global zu verallgemeinern. Unter der Anleitung von zwei Lernenden kann MetaKG hochrangige Kooperationsbeziehungen und semantische Darstellungen effektiv erfassen und sich problemlos an Kaltstartszenarien anpassen. Darüber hinaus hat der Autor auch eine adaptive Aufgabe entworfen, die KG-Informationen zum Lernen adaptiv auswählen kann, um zu verhindern, dass das Modell durch Rauschinformationen gestört wird. Die MetaKG-Architektur ist in der folgenden Abbildung dargestellt.
3.2 Anwendung des Wissensgraphen bei der Generierung von Empfehlungsgründen
Empfehlungsgründe können die Interpretierbarkeit des Empfehlungssystems verbessern, sodass Benutzer den Berechnungsprozess zur Generierung von Empfehlungsergebnissen verstehen und auch die Gründe dafür erklären können die Beliebtheit von Artikeln. Benutzer verstehen das Prinzip der Generierung empfohlener Ergebnisse durch Empfehlungsgründe, was das Vertrauen der Benutzer in die empfohlenen Ergebnisse des Systems stärken und sie im Falle von Empfehlungsfehlern toleranter gegenüber falschen Ergebnissen machen kann.
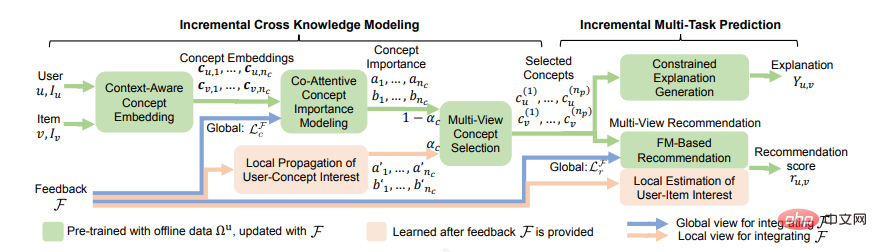
Die frühesten interpretierbaren Empfehlungen basierten auf Vorlagen. Der Vorteil von Vorlagen besteht darin, dass sie Lesbarkeit und hohe Genauigkeit gewährleisten. Allerdings müssen die Vorlagen manuell sortiert werden, und sie sind nicht sehr allgemein gehalten, was bei den Leuten ein repetitives Gefühl vermittelt. Später wurde eine Freiformform entwickelt, die keine Voreinstellungen erforderte, und ein Wissensdiagramm wurde hinzugefügt, wobei einer der Pfade als Erklärung verwendet wurde, und es gab einige generative Methoden, die mit KG-Pfaden kombiniert wurden. Jeder Punkt oder jede Kante wurde ausgewählt Im Modell handelt es sich um einen Argumentationsprozess, der dem Benutzer demonstriert werden kann. Kürzlich schlugen Chen Z [8] und andere ein inkrementelles Multitasking-Lernframework ECR vor, das eine enge Zusammenarbeit zwischen Empfehlungsvorhersage, Erklärungsgenerierung und Benutzerfeedback-Integration erreichen kann. Es besteht aus zwei Teilen. Der erste Teil, Inkrementelle Cross-Knowledge-Modellierung, lernt das übertragene Cross-Wissen in der Empfehlungsaufgabe und der Erklärungsaufgabe und erklärt, wie das Cross-Wissen durch inkrementelles Lernen aktualisiert werden kann. Im zweiten Teil, der inkrementellen Multitasking-Vorhersage, wird erläutert, wie Erklärungen auf der Grundlage von Querwissen generiert werden und wie Empfehlungswerte auf der Grundlage von Querwissen und Benutzerfeedback vorhergesagt werden.
3.3 Anwendung des Wissensdiagramms bei der Empfehlungssortierung
KG kann eine Interaktion zwischen Benutzerelementen herstellen, indem Elemente mit unterschiedlichen Attributen verknüpft werden, und UESR-Elementdiagramme und KG zu einem großen Bild höherer Ordnung kombinieren Beziehungen zwischen Gegenständen. Die traditionelle Empfehlungsmethode besteht darin, das Problem als überwachte Lernaufgabe zu modellieren. Diese Methode ignoriert die intrinsische Beziehung zwischen Elementen (z. B. die Konkurrenzproduktbeziehung zwischen Camry und Accord) und kann keine synergistischen Signale aus dem Benutzerverhalten erhalten. Im Folgenden werden zwei Artikel zur KG-Anwendung im Empfehlungsranking vorgestellt.
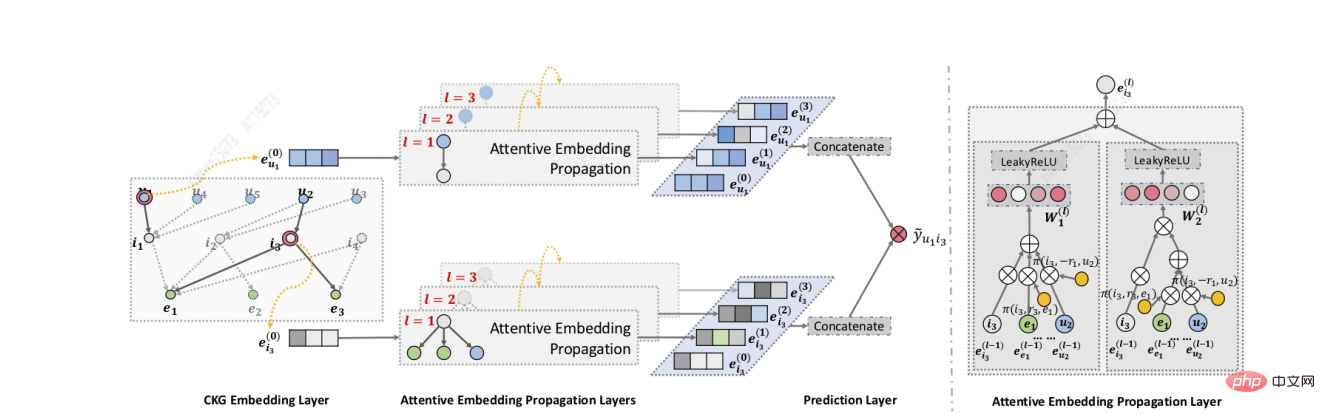
Wang[9] und andere haben den KGAT-Algorithmus entwickelt. Erstens verwenden sie GNN, um die Einbettung iterativ zu verbreiten und zu aktualisieren, sodass sie schnell Verbindungen höherer Ordnung erfassen können. Zweitens verwenden sie den Aufmerksamkeitsmechanismus während der Aggregation Die Gewichtung jedes Nachbarn während des Ausbreitungsprozesses spiegelt schließlich die Bedeutung von Verbindungen höherer Ordnung wider. KGAT kann umfangreichere, unspezifische Verbindungen höherer Ordnung erfassen.
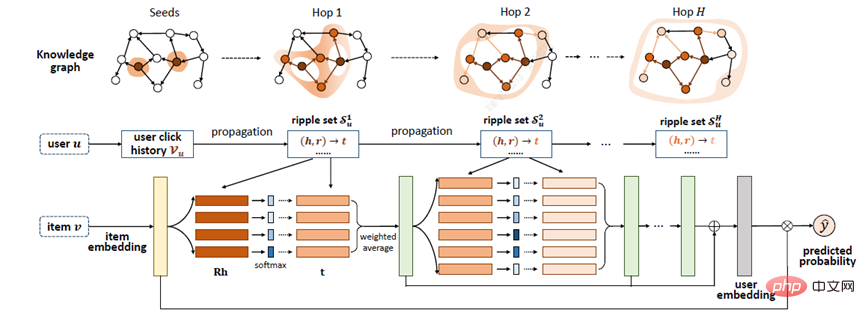
Zhang[20] und andere schlugen das RippleNet-Modell vor, dessen Schlüsselidee die Interessenausbreitung ist: RippleNet verwendet die historischen Interessen des Benutzers als Samensatz in KG und erweitert dann die Interessen des Benutzers entlang der Verbindungen nach außen der KG, die die Interessenverteilung des Nutzers an der KG bildet. Der größte Vorteil von RippleNet besteht darin, dass es automatisch mögliche Pfade von Elementen, auf die Benutzer im Verlauf geklickt haben, zu Kandidatenelementen ermitteln kann, ohne dass Metapfade oder Metadiagramme manuell entworfen werden müssen.
RippleNet verwendet Benutzer U und Element V als Eingabe und gibt die vorhergesagte Wahrscheinlichkeit aus, dass Benutzer U auf Element V klickt. Für Benutzer U, der sein historisches Interesse V_{u} als Keim nimmt, ist in der Abbildung zu sehen, dass der anfängliche Startpunkt zwei ist und sich dann weiter auf die Umgebung ausbreitet. Gegeben sei itemV und jedes Tripel left(h_{i},r_{i},t_{i}right) im 1-Hop-Ripple-Set V_{u_{}^{1}} des Benutzers U, indem V zugeordnete Wahrscheinlichkeiten verglichen werden zu Knoten h_{i} und Beziehungen r_{i} in Tripeln.
Nach Erhalt der relevanten Wahrscheinlichkeiten multiplizieren Sie die Enden der Tripel in V_{u_{}^{1}} mit den entsprechenden relevanten Wahrscheinlichkeiten, um eine gewichtete Summe zu erhalten, um das historische Interesse erster Ordnung von Benutzer U in Bezug auf zu erhalten zu V Als Reaktion darauf wird das Interesse des Benutzers von V_{u} auf o_{u}^{1} übertragen, was als o_{u}^{2}, o_{u}^{3} ... berechnet werden kann. o_{u}^{n }, und dann können die Eigenschaften von U über Artikel V berechnet werden, um alle seine Bestellantworten zu verschmelzen.
IV. Zusammenfassung
Zusammenfassend haben wir uns hauptsächlich auf Empfehlungen konzentriert, den detaillierten Prozess der Diagrammerstellung vorgestellt und die damit verbundenen Schwierigkeiten und Herausforderungen analysiert. Gleichzeitig fasst es auch viele wichtige Arbeiten zusammen und gibt konkrete Lösungsansätze, Ideen und Anregungen. Abschließend wird die Anwendung einschließlich des Wissensgraphen vorgestellt, insbesondere die Rolle und Verwendung des Wissensgraphen im Bereich der Empfehlung, einschließlich Kaltstart, Interpretierbarkeit und Rückrufranking.
Zitat:
[1] Kim S, Oh S G. Extrahieren und Anwenden von Bewertungskriterien für die Qualitätsbewertung der Ontologie[J]. Library Hi Tech, 2019.
[2]Schützling: https://www.php.cn/link/9d405c24be657bbf7a5244815a908922
[3] Ding S, Shang J, Wang S, et al . ERNIE-DOC: The Retrospective Long-Document Modeling Transformer[J]. 2019.
[5]JanusGraph,
https://www.php.cn/link/fc0de4e0396fff257ea362983c2dda5a[6] Sang L, Xu M, Qian S, et al. Wissensgraph verbessert Neuronale kollaborative Filterung mit restlichem wiederkehrendem Netzwerk[J]. Neurocomputing, 2021, 454: 417-429.
[7] Du Y, Zhu X, Chen L, et al. MetaKG: Meta-Learning auf Knowledge Graph für Kaltstart Empfehlung[J]. arXiv e-prints, 2022.
[8] Chen Z, Wang Rim International Conference on Artificial Intelligence {IJCAI-PRICAI-2020.
[9] Wang X, He X, Cao Y, et al. KGAT: Knowledge Graph Attention Network for Recommendation[J]. [10]Wang H, Zhang F, Wang J, et al. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems, 2018.


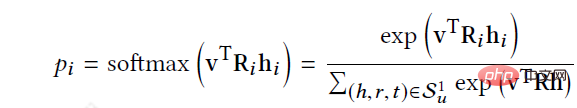
Das obige ist der detaillierte Inhalt vonErstellung eines Automotive-Wissensgraphen zur Empfehlung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
