
 Technologie-Peripheriegeräte
KI
Neue Arbeit von Jeff Dean und anderen: Wenn man Sprachmodelle aus einem anderen Blickwinkel betrachtet, ist der Maßstab nicht groß genug und kann nicht entdeckt werden
Technologie-Peripheriegeräte
KI
Neue Arbeit von Jeff Dean und anderen: Wenn man Sprachmodelle aus einem anderen Blickwinkel betrachtet, ist der Maßstab nicht groß genug und kann nicht entdeckt werden
Neue Arbeit von Jeff Dean und anderen: Wenn man Sprachmodelle aus einem anderen Blickwinkel betrachtet, ist der Maßstab nicht groß genug und kann nicht entdeckt werden

In den letzten Jahren hatten Sprachmodelle einen revolutionären Einfluss auf die Verarbeitung natürlicher Sprache (NLP). Es ist bekannt, dass die Erweiterung von Sprachmodellen, wie z. B. Parametern, zu einer besseren Leistung und Stichprobeneffizienz bei einer Reihe nachgelagerter NLP-Aufgaben führen kann. In vielen Fällen lässt sich der Einfluss der Skalierung auf die Leistung oft durch Skalierungsgesetze vorhersagen, und die meisten Forscher haben vorhersehbare Phänomene untersucht.
Im Gegenteil, 16 Forscher, darunter Jeff Dean, Percy Liang usw., arbeiteten an der Arbeit „Emergent Abilities of Large Language Models“ zusammen. Sie diskutierten das Phänomen der Unvorhersehbarkeit großer Sprachmodelle und nannten es die Entstehung großer Sprachmodelle . Neue Fähigkeiten. Die sogenannte Emergenz bedeutet, dass einige Phänomene im kleineren Modell nicht existieren, aber im größeren Modell. Sie glauben, dass diese Fähigkeit des Modells emergent ist.
Emergenz als Idee wird seit langem in Bereichen wie Physik, Biologie und Informatik diskutiert. Dieser Artikel beginnt mit einer allgemeinen Definition von Emergenz, die auf der Forschung von Steinhardt basiert und auf den Artikel „Mehr“ aus dem Jahr 1972 zurückgeht Is Different vom Nobelpreisträger und Physiker Philip Anderson.
Dieser Artikel untersucht die Entstehung der Modellgröße, gemessen durch Trainingsberechnungen und Modellparameter. Konkret definiert dieser Artikel die entstehenden Fähigkeiten großer Sprachmodelle als Fähigkeiten, die in kleinen Modellen nicht vorhanden sind, aber in großen Modellen vorhanden sind. Daher können große Modelle nicht durch einfache Extrapolation der Leistungsverbesserungen kleiner Modelle vorhergesagt werden. maßstabsgetreue Modelle. Diese Studie untersucht die neuen Fähigkeiten von Modellen, die in einer Reihe früherer Arbeiten beobachtet wurden, und klassifiziert sie in Umgebungen wie Small-Shot-Cueing und Boosted-Cueing.
Diese neu entstehende Fähigkeit des Modells inspiriert zukünftige Forschungen darüber, warum diese Fähigkeiten erworben werden und ob größere Maßstäbe mehr neu entstehende Fähigkeiten erwerben, und unterstreicht die Bedeutung dieser Forschung.

Papieradresse: https://arxiv.org/pdf/2206.07682.pdf
Kleine Beispiel-Prompting-Aufgabe
Dieses Papier diskutiert zunächst die Emergenzfähigkeit im Prompt-Paradigma. Beispielsweise kann das Modell in der GPT-3-Eingabeaufforderung bei einer vorab trainierten Sprachmodell-Aufgabenaufforderung die Antwort ohne weiteres Training oder Gradientenaktualisierungen der Parameter abschließen. Darüber hinaus schlugen Brown et al. eine Eingabeaufforderung für kleine Stichproben vor, bei der sie einige Eingabe- und Ausgabebeispiele im Modellkontext (Eingabe) als Eingabeaufforderungen (Präambel) verwendeten und das Modell dann aufforderten, unsichtbare Inferenzaufgaben auszuführen. Abbildung 1 zeigt eine Beispielaufforderung.
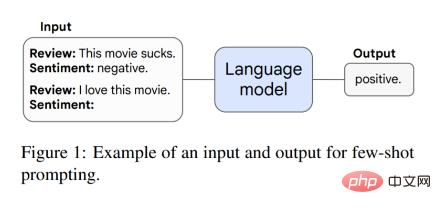

Wenn das Modell eine stochastische Leistung und einen bestimmten Maßstab aufweist, kann es Aufgaben durch kleine Beispielaufforderungen ausführen. Zu diesem Zeitpunkt werden neue Fähigkeiten angezeigt, und dann ist die Modellleistung viel höher zufällige Leistung. Die folgende Abbildung zeigt die 8 neuen Funktionen von 5 Sprachmodellreihen (LaMDA, GPT-3, Gopher, Chinchilla und PaLM).

BIG-Bench: Abbildung 2A-D zeigt vier aufkommende Aufgaben zur Eingabeaufforderung mit wenigen Schüssen aus BIG-Bench, einer Suite von mehr als 200 Benchmarks zur Sprachmodellbewertung. Abbildung 2A zeigt einen arithmetischen Benchmark, der die Addition und Subtraktion dreistelliger Zahlen sowie die Multiplikation zweistelliger Zahlen testet. Tabelle 1 enthält weitere neue Funktionen von BIG-Bench.

Erweiterte Trinkgeldstrategie
Obwohl Hinweise für kleine Stichproben derzeit die gebräuchlichste Art der Interaktion mit großen Sprachmodellen sind, wurden in neueren Arbeiten mehrere andere Hinweise und Strategien zur Feinabstimmung vorgeschlagen, um die Fähigkeiten von Sprachmodellen weiter zu verbessern. In diesem Artikel wird eine Technologie auch dann als neue Fähigkeit betrachtet, wenn sie keine Verbesserung zeigt oder schädlich ist, bevor sie auf ein ausreichend großes Modell angewendet wird.
Mehrstufiges Denken: Für Sprachmodelle und NLP-Modelle waren Argumentationsaufgaben, insbesondere solche, die mehrstufiges Denken beinhalten, schon immer eine große Herausforderung. Eine neue Aufforderungsstrategie namens Chain-of-Thinking ermöglicht es Sprachmodellen, diese Art von Problem zu lösen, indem sie sie anleitet, eine Reihe von Zwischenschritten zu generieren, bevor sie eine endgültige Antwort geben. Wie in Abbildung 3A dargestellt, übertraf die Gedankenketten-Eingabeaufforderung bei der Skalierung auf 1023 Trainings-FLOPs (~100 Milliarden Parameter) nur die Standard-Eingabeaufforderung ohne Zwischenschritte.
Anweisung folgt): Wie in Abbildung 3B gezeigt, stellten Wei et al. fest, dass Anweisung -Feinabstimmungstechniken beeinträchtigen die Modellleistung und können die Leistung nur verbessern, wenn die Trainings-FLOPs auf 10^23 (~100B Parameter) erweitert werden.
Programmausführung: Wie in Abbildung 3C gezeigt, hilft die Verwendung des Scratchpads bei der domäneninternen Auswertung der 8-Bit-Addition nur ∼9·10 ^19 Trainings-FLOPs ( 40M Parameter) oder größere Modelle. Abbildung 3D zeigt, dass diese Modelle auch auf eine 9-Bit-Addition außerhalb der Domäne verallgemeinert werden können, die in ∼1,3 · 10^20 Trainings-FLOPs (100 Millionen Parameter) auftritt.

Dieser Artikel befasst sich nur mit der aufkommenden Macht von Sprachmodellen Eine sinnvolle Leistung kann nur in einem bestimmten Rechenmaßstab beobachtet werden. Diese neue Fähigkeit von Modellen kann eine Vielzahl von Sprachmodellen, Aufgabentypen und experimentellen Szenarien umfassen. Die Existenz dieses Aufkommens bedeutet, dass eine zusätzliche Skalierung die Fähigkeiten von Sprachmodellen weiter erweitern kann. Diese Fähigkeit ist das Ergebnis kürzlich entdeckter Sprachmodellerweiterungen und ob weitere Erweiterungen zu weiteren neuen Fähigkeiten führen werden, könnten wichtige zukünftige Forschungsrichtungen im Bereich NLP sein.
Weitere Informationen finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonNeue Arbeit von Jeff Dean und anderen: Wenn man Sprachmodelle aus einem anderen Blickwinkel betrachtet, ist der Maßstab nicht groß genug und kann nicht entdeckt werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laraveleloquent-Modellab Abruf: Das Erhalten von Datenbankdaten Eloquentorm bietet eine prägnante und leicht verständliche Möglichkeit, die Datenbank zu bedienen. In diesem Artikel werden verschiedene eloquente Modellsuchtechniken im Detail eingeführt, um Daten aus der Datenbank effizient zu erhalten. 1. Holen Sie sich alle Aufzeichnungen. Verwenden Sie die Methode All (), um alle Datensätze in der Datenbanktabelle zu erhalten: UseApp \ Models \ post; $ posts = post :: all (); Dies wird eine Sammlung zurückgeben. Sie können mit der Foreach-Schleife oder anderen Sammelmethoden auf Daten zugreifen: foreach ($ postas $ post) {echo $ post->
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
