
 Technologie-Peripheriegeräte
KI
IBM entwickelt den Cloud-nativen KI-Supercomputer Vela, um zig Milliarden Parametermodelle flexibel einzusetzen und zu trainieren
Technologie-Peripheriegeräte
KI
IBM entwickelt den Cloud-nativen KI-Supercomputer Vela, um zig Milliarden Parametermodelle flexibel einzusetzen und zu trainieren
IBM entwickelt den Cloud-nativen KI-Supercomputer Vela, um zig Milliarden Parametermodelle flexibel einzusetzen und zu trainieren

ChatGPT ist im Internet beliebt und auch das dahinter stehende KI-Modelltraining hat große Aufmerksamkeit erregt. IBM Research gab kürzlich bekannt, dass der von ihm entwickelte cloudnative Supercomputer Vela schnell bereitgestellt und zum Trainieren grundlegender KI-Modelle verwendet werden kann. Seit Mai 2022 nutzen Dutzende Forscher des Unternehmens diesen Supercomputer, um KI-Modelle mit zig Milliarden Parametern zu trainieren.
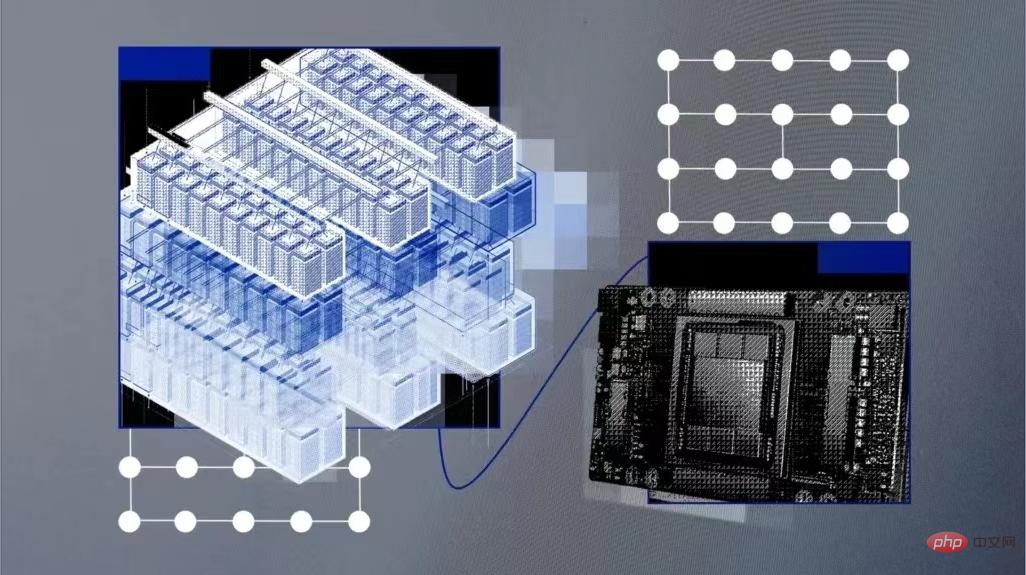
Basismodelle sind KI-Modelle, die auf großen Mengen unbeschrifteter Daten trainiert werden, und ihre Vielseitigkeit bedeutet, dass sie mit nur einer Feinabstimmung für eine Reihe verschiedener Aufgaben verwendet werden können. Ihr Ausmaß ist enorm und erfordert enorme und kostspielige Rechenleistung. Experten sagen daher, dass die Rechenleistung der größte Engpass bei der Entwicklung der nächsten Generation groß angelegter Basismodelle sein wird und deren Training viel Rechenleistung und Zeit erfordert.
Trainingsmodelle, die Dutzende oder Hunderte von Milliarden Parametern ausführen können, erfordern den Einsatz leistungsstarker Computerhardware, einschließlich Netzwerken, parallelen Dateisystemen und Bare-Metal-Knoten. Diese Hardware ist schwierig bereitzustellen und teuer im Betrieb. Microsoft hat im Mai 2020 einen KI-Supercomputer für OpenAI gebaut und ihn auf der Azure-Cloud-Plattform gehostet. Laut IBM sind sie jedoch hardwaregesteuert, was die Kosten erhöht und die Flexibilität einschränkt.
Cloud AI Supercomputer
Daher hat IBM ein System namens Vela entwickelt, das „speziell auf groß angelegte KI ausgerichtet ist“.
Vela kann je nach Bedarf in jedem Cloud-Rechenzentrum von IBM bereitgestellt werden und ist selbst eine „virtuelle Cloud“. Dieser Ansatz reduziert zwar die Rechenleistung im Vergleich zu bauphysikalischen Supercomputern, schafft aber eine flexiblere Lösung. Cloud-Computing-Lösungen bieten Ingenieuren Ressourcen über API-Schnittstellen, einfacheren Zugriff auf das breite IBM Cloud-Ökosystem für eine tiefere Integration und die Möglichkeit, die Leistung nach Bedarf zu skalieren.
IBM-Ingenieure erklärten, dass Vela auf Datensätze im IBM Cloud Object Storage zugreifen kann, anstatt ein benutzerdefiniertes Speicher-Backend zu erstellen. Bisher musste diese Infrastruktur separat in Supercomputern aufgebaut werden.
Die Schlüsselkomponente jedes KI-Supercomputers ist eine große Anzahl von GPUs und die sie verbindenden Knoten. Vela konfiguriert tatsächlich jeden Knoten als virtuelle Maschine (und nicht als Bare-Metal-Maschine). Dies ist die gebräuchlichste Methode und wird allgemein als die idealste Methode für das KI-Training angesehen.
Wie ist Vela aufgebaut?
Einer der Nachteile virtueller Cloud-Computer besteht darin, dass die Leistung nicht garantiert werden kann. Um Leistungseinbußen entgegenzuwirken und Bare-Metal-Leistung innerhalb virtueller Maschinen bereitzustellen, haben IBM-Ingenieure einen Weg gefunden, die Leistung des gesamten Knotens (einschließlich GPU, CPU, Netzwerk und Speicher) freizuschalten und Lastverluste auf weniger als 5 % zu reduzieren.
Dazu gehört die Konfiguration eines Bare-Metal-Hosts für die Virtualisierung, die Unterstützung der VM-Skalierung, der Large-Page- und Single-Root-IO-Virtualisierung sowie die realistische Darstellung aller Geräte und Verbindungen innerhalb der VM. Dazu gehört auch die Anpassung von Netzwerkkarten an CPUs und GPUs und deren Wie man einander überbrückt. Nach Abschluss dieser Arbeit stellten sie fest, dass die Leistung der virtuellen Maschinenknoten „nahezu Bare-Metal“ war.
Darüber hinaus engagieren sie sich auch für die Entwicklung von KI-Knoten mit großem GPU-Speicher und großen Mengen an lokalem Speicher zum Zwischenspeichern von KI-Trainingsdaten, Modellen und fertigen Produkten. Bei Tests mit PyTorch stellten sie fest, dass sie durch die Optimierung der Workload-Kommunikationsmuster auch den Engpass relativ langsamer Ethernet-Netzwerke im Vergleich zu schnelleren Netzwerken wie Infiniband, die im Supercomputing verwendet werden, überbrücken konnten.
In Bezug auf die Konfiguration verwendet jeder Vela acht 80-GB-A100-GPUs, zwei skalierbare Intel Xeon-Prozessoren der zweiten Generation, 1,5 TB Speicher und vier 3,2-TB-NVMe-Festplatten und kann in jedem Cloud-Rechenzentrum von IBM bereitgestellt werden auf der ganzen Welt.
IBM-Ingenieure sagten: „Die richtigen Werkzeuge und die richtige Infrastruktur sind ein Schlüsselfaktor für die Verbesserung der F&E-Effizienz. Viele Teams entscheiden sich für den bewährten Weg, traditionelle Supercomputer für KI zu bauen … Wir arbeiten immer an einer Verbesserung.“ Lösung, um die doppelten Vorteile von Hochleistungsrechnen und High-End-Benutzerproduktivität zu bieten“
Das obige ist der detaillierte Inhalt vonIBM entwickelt den Cloud-nativen KI-Supercomputer Vela, um zig Milliarden Parametermodelle flexibel einzusetzen und zu trainieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
In diesem Artikel wird beschrieben, wie das Protokollformat von Apache auf Debian -Systemen angepasst wird. Die folgenden Schritte führen Sie durch den Konfigurationsprozess: Schritt 1: Greifen Sie auf die Apache -Konfigurationsdatei zu. Die Haupt -Apache -Konfigurationsdatei des Debian -Systems befindet sich normalerweise in /etc/apache2/apache2.conf oder /etc/apache2/httpd.conf. Öffnen Sie die Konfigurationsdatei mit Root -Berechtigungen mit dem folgenden Befehl: Sudonano/etc/apache2/apache2.conf oder sudonano/etc/apache2/httpd.conf Schritt 2: Definieren Sie benutzerdefinierte Protokollformate, um zu finden oder zu finden oder
 Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Tomcat -Protokolle sind der Schlüssel zur Diagnose von Speicherleckproblemen. Durch die Analyse von Tomcat -Protokollen können Sie Einblicke in das Verhalten des Speicherverbrauchs und des Müllsammlung (GC) erhalten und Speicherlecks effektiv lokalisieren und auflösen. Hier erfahren Sie, wie Sie Speicherlecks mit Tomcat -Protokollen beheben: 1. GC -Protokollanalyse zuerst aktivieren Sie eine detaillierte GC -Protokollierung. Fügen Sie den Tomcat-Startparametern die folgenden JVM-Optionen hinzu: -xx: printgCDetails-xx: printgCDatESTAMPS-XLOGGC: GC.Log Diese Parameter generieren ein detailliertes GC-Protokoll (GC.Log), einschließlich Informationen wie GC-Typ, Recycling-Objektgröße und Zeit. Analyse gc.log
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
In diesem Artikel wird beschrieben, wie Sie Firewall -Regeln mit Iptables oder UFW in Debian -Systemen konfigurieren und Syslog verwenden, um Firewall -Aktivitäten aufzuzeichnen. Methode 1: Verwenden Sie IptableSiptables ist ein leistungsstarkes Befehlszeilen -Firewall -Tool im Debian -System. Vorhandene Regeln anzeigen: Verwenden Sie den folgenden Befehl, um die aktuellen IPTables-Regeln anzuzeigen: Sudoiptables-L-N-V Ermöglicht spezifische IP-Zugriff: ZBELTE IP-Adresse 192.168.1.100 Zugriff auf Port 80: sudoiptables-ainput-ptcp--dort80-s192.16
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 Wo ist der Debian Nginx Log Path
Apr 12, 2025 pm 11:33 PM
Wo ist der Debian Nginx Log Path
Apr 12, 2025 pm 11:33 PM
Im Debian -System sind die Standardspeicherorte des Zugriffsprotokolls von NGINX wie folgt wie folgt: Zugriffsprotokoll (AccessLog):/var/log/nginx/access.log Fehlerprotokoll (FehlerLog):/var/log/nginx/fehler Wenn Sie den Speicherort der Protokolldatei während des Installationsprozesses geändert haben, überprüfen Sie bitte Ihre Nginx-Konfigurationsdatei (normalerweise in /etc/nginx/nginx.conf oder/etc/nginx/seiten-AVailable/Verzeichnis). In der Konfigurationsdatei
