
 Backend-Entwicklung
Python-Tutorial
Python-Gesichtserkennungssystem mit einer Offline-Erkennungsrate von bis zu 99 %, Open Source~
Backend-Entwicklung
Python-Tutorial
Python-Gesichtserkennungssystem mit einer Offline-Erkennungsrate von bis zu 99 %, Open Source~
Python-Gesichtserkennungssystem mit einer Offline-Erkennungsrate von bis zu 99 %, Open Source~


In der Vergangenheit umfasste die Gesichtserkennung hauptsächlich Technologien und Systeme wie Gesichtsbilderfassung, Gesichtserkennungsvorverarbeitung, Identitätsbestätigung und Identitätssuche. Mittlerweile hat sich die Gesichtserkennung langsam auf die Fahrererkennung, die Fußgängerverfolgung und sogar die dynamische Objektverfolgung in ADAS ausgeweitet.
Daraus ist ersichtlich, dass sich das Gesichtserkennungssystem von der einfachen Bildverarbeitung zur Echtzeit-Videoverarbeitung entwickelt hat. Darüber hinaus hat sich der Algorithmus von traditionellen statistischen Methoden wie Adaboots und PCA zu Deep-Learning-Methoden wie CNN und RCNN und deren Modifikationen gewandelt. Mittlerweile hat eine beträchtliche Anzahl von Menschen damit begonnen, sich mit der 3D-Gesichtserkennung zu beschäftigen, und diese Art von Projekt wird derzeit von Wissenschaft, Industrie und dem Land unterstützt.
Werfen wir zunächst einen Blick auf den aktuellen Forschungsstand. Wie aus den oben genannten Entwicklungstrends hervorgeht, besteht die aktuelle Hauptforschungsrichtung darin, Deep-Learning-Methoden zur Lösung der Video-Gesichtserkennung einzusetzen.
Hauptforscher:
Wie folgt: Professor Shan Shiguang vom Institut für Computertechnologie der Chinesischen Akademie der Wissenschaften, Professor Li Ziqing vom Institut für Biometrie der Chinesischen Akademie der Wissenschaften, Professor Su Guangda von der Tsinghua-Universität, Professor Tang Xiaoou von die Chinesische Universität Hongkong, Ross B. Girshick usw.
Wichtige Open-Source-Projekte:
SeetaFace Gesichtserkennungs-Engine. Die Engine wurde von der Gesichtserkennungs-Forschungsgruppe unter der Leitung des Forschers Shan Shiguang vom Institut für Computertechnologie der Chinesischen Akademie der Wissenschaften entwickelt. Der Code ist auf Basis von C++ implementiert und ist nicht auf Bibliotheksfunktionen Dritter angewiesen. Die Open-Source-Lizenz ist BSD-2 und kann von Wissenschaft und Industrie kostenlos genutzt werden.
Hauptsoftware-API/SDK:
- face++. Face++.com ist eine Cloud-Service-Plattform, die kostenlose Gesichtserkennung, Gesichtserkennung, Gesichtsattributanalyse und andere Dienste bereitstellt. Face++ ist eine neue Cloud-Plattform für Gesichtstechnologie im Besitz von Beijing Megvii Technology Co., Ltd. Im Dark Horse-Wettbewerb gewann Face++ die jährliche Meisterschaft und erhielt die Investition von Lenovo Star.
- Himmelsbiometrie. Es umfasst hauptsächlich Gesichtserkennung, Gesichtserkennung und Gesichtsgruppierung.
Hauptbildbibliotheken für die Gesichtserkennung:
Zu den derzeit veröffentlichten besseren Gesichtsbildbibliotheken gehören LFW (Labeled Faces in the Wild) und YFW (Youtube Faces in the Wild). Der aktuelle experimentelle Datensatz stammt im Wesentlichen aus LFW, und die Genauigkeit der aktuellen Bildgesichtserkennung hat im Grunde 99 % erreicht. Die vorhandene Bilddatenbank ist erschöpft. Das Folgende ist eine Zusammenfassung der vorhandenen Gesichtsbilddatenbank:

Heutzutage gibt es in China immer mehr Unternehmen, die Gesichtserkennung durchführen, und auch die Anwendungen sind sehr breit gefächert. Unter ihnen hat Hanwang Technology den höchsten Marktanteil. Die Forschungsrichtungen und der aktuelle Status der wichtigsten Unternehmen sind wie folgt:
- Hanwang Technology: Hanwang Technology führt hauptsächlich Gesichtserkennungsauthentifizierung durch, die hauptsächlich in Zugangskontrollsystemen, Anwesenheitssystemen usw. verwendet wird.
- iFlytek: iFlytek hat mit Unterstützung des Teams von Professor Tang Xiaoou an der Chinesischen Universität Hongkong eine Gesichtserkennungstechnologie entwickelt, die auf dem Gaußschen Gesicht basiert. Die Erkennungsrate dieser Technologie auf LFW beträgt derzeit 98,52 %. Das Unternehmen Die Erkennungsrate von DEEPID2 auf LFW hat 99,4 % erreicht.
- Sichuan University Zhisheng: Der aktuelle Forschungsschwerpunkt des Unternehmens ist die 3D-Gesichtserkennung, und es hat sich auf die Industrialisierung von 3D-Vollgesichtskameras usw. ausgeweitet.
- SenseTime: Das Unternehmen widmet sich hauptsächlich dem Durchbruch der Kerntechnologie „Deep Learning“ der künstlichen Intelligenz und der Entwicklung von Branchenlösungen für künstliche Intelligenz und Big-Data-Analyse. Derzeit beschäftigt es sich mit Gesichtserkennung, Texterkennung, Erkennung menschlicher Körper und Fahrzeugen Erkennung: Es verfügt über eine starke Wettbewerbsfähigkeit in Bereichen wie Objekterkennung und Bildverarbeitung. Bei der Gesichtserkennung gibt es 106 Gesichtserkennungsschlüsselpunkte.
Der Prozess der Gesichtserkennung
Die Gesichtserkennung ist hauptsächlich in vier Teile unterteilt: Gesichtserkennung, Gesichtsausrichtung, Gesichtsüberprüfung und Gesichtserkennung.
Gesichtserkennung (Gesichtserkennung):
Erkennen Sie das Gesicht im Bild und rahmen Sie das Ergebnis mit einem rechteckigen Rahmen ein. In openCV gibt es einen Harr-Klassifikator, der direkt verwendet werden kann.
Gesichtsausrichtung:
Korrigieren Sie die Haltung des erkannten Gesichts, um das Gesicht so „positiv“ wie möglich zu machen. Zu den Korrekturmethoden gehören die 2D-Korrektur und die 3D-Korrektur. Die 3D-Korrekturmethode kann eine bessere Erkennung von Seitenflächen ermöglichen.
Bei der Gesichtskorrektur gibt es einen Schritt zur Erkennung der Position von Merkmalspunkten. Diese Merkmalspunktpositionen sind hauptsächlich die linke Seite der Nase, die Unterseite der Nasenlöcher, die Pupillenposition und die Unterseite der Oberlippe usw. Sobald Sie diese Funktionen kennen, führen Sie nach dem Klicken auf die Position eine positionsgesteuerte Verformung durch, und die Fläche wird „korrigiert“. Wie im Bild unten gezeigt:
Hier ist eine Technologie, die 2014 von MSRA eingeführt wurde: Joint Cascade Face Detection and Alignment (ECCV14). Dieser Artikel führt sowohl die Erkennung als auch die Ausrichtung direkt in 30 ms durch.
Gesichtsüberprüfung:
Gesichtsüberprüfung: Die Gesichtsüberprüfung basiert auf dem Paarvergleich, sodass die Antwort „Ja“ oder „Nein“ lautet. Bei der spezifischen Operation wird ein Testbild bereitgestellt und dann wird nacheinander ein Paarabgleich durchgeführt. Wenn der Abgleich erfolgreich ist, bedeutet dies, dass das Testbild und das abgeglichene Gesicht die Gesichter derselben Person sind.
Diese Methode wird (sollte) im Allgemeinen in Punch-In-Systemen zum Scannen von Gesichtern in kleinen Büros verwendet. Die spezifische Vorgehensweise ist ungefähr der folgende Prozess: Geben Sie die Gesichtsfotos der Mitarbeiter einzeln offline ein (ein Mitarbeiter gibt im Allgemeinen mehr als ein Gesicht ein). ) Nachdem die Kamera das Bild erfasst hat, wenn der Mitarbeiter zum Einchecken über sein Gesicht wischt, führt er zunächst eine Gesichtserkennung durch, führt dann eine Gesichtskorrektur durch und führt dann wie oben erwähnt eine Gesichtsüberprüfung durch. Dies bedeutet, dass die Person, deren Gesicht gescannt wird, zu diesem Büro gehört und die Gesichtsüberprüfung in diesem Schritt abgeschlossen ist.
Bei der Offline-Eingabe von Mitarbeitergesichtern können wir das Gesicht mit dem Namen der Person abgleichen, sodass wir nach erfolgreicher Gesichtsüberprüfung wissen, wer die Person ist.
Der Vorteil des oben genannten Systems besteht darin, dass es geringe Entwicklungskosten verursacht und für kleine Büros geeignet ist. Der Nachteil besteht darin, dass es während der Aufnahme nicht blockiert werden kann und außerdem eine relativ gerade Gesichtshaltung erfordert (wir besitzen dieses System). , habe es aber noch nie erlebt). Die folgende Abbildung gibt eine schematische Erklärung:
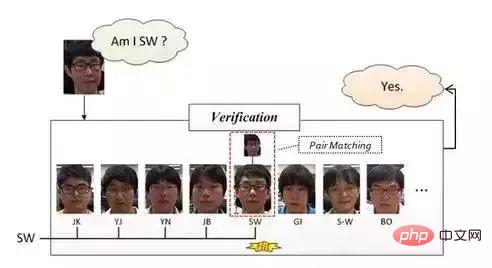
Gesichtsidentifikation/-erkennung:
Gesichtsidentifikation oder Gesichtserkennung, Gesichtserkennung ist wie in der Abbildung unten dargestellt, sie möchte im Vergleich zu „Wer bin ich?“ antworten Da der Paarvergleich bei der Gesichtsüberprüfung verwendet wird, werden in der Erkennungsphase weitere Klassifizierungsmethoden verwendet. Es klassifiziert tatsächlich Bilder (Gesichter), nachdem die beiden vorherigen Schritte ausgeführt wurden, nämlich Gesichtserkennung und Gesichtskorrektur.
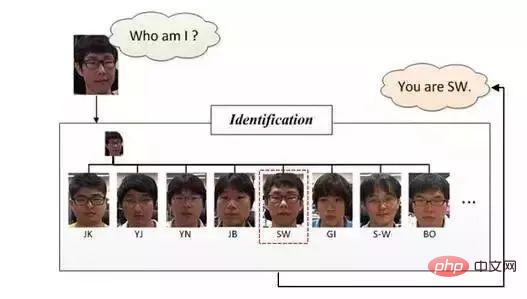
Anhand der Einführung der oben genannten vier Konzepte können wir verstehen, dass die Gesichtserkennung hauptsächlich drei große, unabhängige Module umfasst:
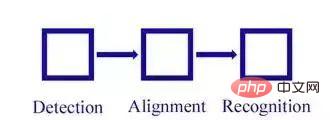
Wir werden die obigen Schritte im Detail aufteilen und das folgende Prozessdiagramm erhalten:
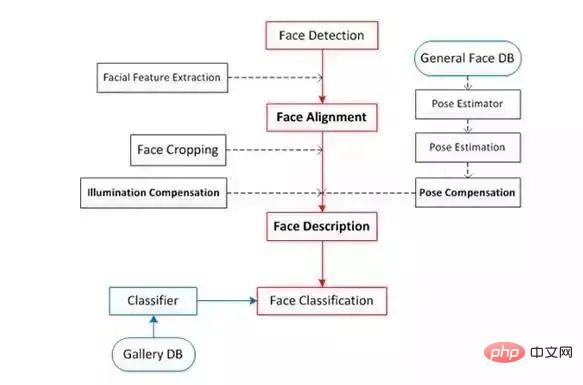
Gesichtserkennungsklassifizierung
Mit der Entwicklung der Gesichtserkennungstechnologie wird die Gesichtserkennungstechnologie nun hauptsächlich in drei Kategorien unterteilt: eine ist die bildbasierte Erkennungsmethode und die andere ist die videobasierte Erkennung. Die dritte Methode ist die drei -dimensionale Gesichtserkennungsmethode.
Bildbasierte Erkennungsmethode:
Bei diesem Verfahren handelt es sich um ein statisches Bilderkennungsverfahren, bei dem hauptsächlich Bildverarbeitung zum Einsatz kommt. Zu den Hauptalgorithmen gehören PCA, EP, Kernel-Methode, Bayesian Framwork, SVM, HMM, Adaboot und andere Algorithmen. Aber im Jahr 2014 erzielte die Gesichtserkennung mit der Deep-Learning-Technologie einen großen Durchbruch, der durch 97,25 % von Deep Face und 97,27 % von Face ++ repräsentiert wurde. Gleichzeitig beträgt der Trainingssatz von Deep Face 4 Millionen Sätze Chinesische Universität Hongkong Der Gesichtstrainingssatz ist 2w.
Echtzeit-Erkennungsmethode basierend auf Video:
Dieser Prozess ist im Tracking-Prozess der Gesichtserkennung zu sehen, bei dem nicht nur die Position und Größe des Gesichts im Video ermittelt, sondern auch die Übereinstimmung zwischen diesen ermittelt werden muss unterschiedliche Gesichter zwischen den Bildern.
DeepFace
Referenzpapiere (Daten):
1. DeepFace: Die Lücke zur Leistung auf menschlicher Ebene bei der Gesichtsverifizierung schließen
2. http://blog.csdn.net/zouxy09/article/details/8781543
3. Ableitungsblog des Faltungs-Neuronalen Netzwerks. http://blog.csdn.net/zouxy09/article/details/9993371/
4. Hinweis zum Faltungs-Neuronalen Netzwerk
5. DeepFace-Blogbeitrag: / blog.csdn.net/Hao_Zhang_Vision/article/details/52831399?locationNum=2&fps=1
DeepFace wurde von FaceBook vorgeschlagen, und DeepID und FaceNet erschienen später. Darüber hinaus ist DeepFace in DeepID und FaceNet zu sehen, sodass man sagen kann, dass DeepFace die Grundlage von CNN bei der Gesichtserkennung ist. Derzeit hat Deep Learning auch bei der Gesichtserkennung sehr gute Ergebnisse erzielt. Hier beginnen wir also mit DeepFace.
Im Lernprozess von DeepFace werden wir nicht nur die von DeepFace verwendeten Methoden vorstellen, sondern auch andere Hauptalgorithmen vorstellen, die derzeit in diesem Schritt verwendet werden, und eine einfache und umfassende Beschreibung der vorhandenen Bildgesichtserkennungstechnologie geben.
Grundgerüst von DeepFace
1. Grundprozess der Gesichtserkennung
Gesichtserkennung -> Gesichtsausrichtung -> Gesichtserkennung -> Gesichtserkennung
2.1 Vorhandene Technologie:
Haarklassifikator:
Die Gesichtserkennung (Erkennung) verfügt bereits über einen Haarklassifikator, der direkt in opencv verwendet werden kann und auf dem Viola-Jones-Algorithmus basiert.
Adaboost-Algorithmus (Kaskadenklassifikator):
1. Referenzpapier: Robuste Echtzeit-Gesichtserkennung.
2. Referenz-Chinesischer Blog: http://blog.csdn.net/cyh_24/article/details/39755661
3. Blog: http://blog.sina.com.cn/s/blog_7769660f01019ep0.html
2.2 Im Artikel verwendete Methode
Dieser Artikel verwendet die Gesichtserkennungsmethode basierend auf Erkennungspunkten (Fiducial Point Detector).
- Wählen Sie zunächst 6 Referenzpunkte, 2 Augenzentren, 1 Nasenpunkt und 3 Punkte am Mund aus.
- Verwenden Sie SVR, um den Referenzpunkt durch LBP-Funktionen zu lernen.
Der Effekt ist wie folgt:

3. Gesichtsausrichtung (Gesichtsausrichtung)
2D-Ausrichtung:
- Führen Sie nach der Erkennung einen zweidimensionalen Zuschnitt des Bildes durch, skalieren, drehen und übersetzen Sie das Bild in sechs Ankerstandorte. Schneiden Sie den Gesichtsteil aus.
3D-Ausrichtung:
- Suchen Sie ein 3D-Modell und verwenden Sie dieses 3D-Modell, um das 2D-Gesicht in ein 3D-Gesicht zuzuschneiden. 67 Basispunkte, dann Delaunay-Triangulation, Hinzufügen von Dreiecken an der Kontur, um Diskontinuitäten zu vermeiden.
- Konvertieren Sie das triangulierte Gesicht in eine 3D-Form.
- Das triangulierte Gesicht wird zu einem tiefen 3D-Dreiecksnetzwerk.
- Nehmen Sie das triangulierte Netzwerk so ab, dass die Vorderseite des Gesichts nach vorne zeigt folgt:
Die 2D-Ausrichtung oben entspricht dem Bild (b) und die 3D-Ausrichtung entspricht (c) ~ (h).
4 Gesichtsüberprüfung (Gesichtsüberprüfung) 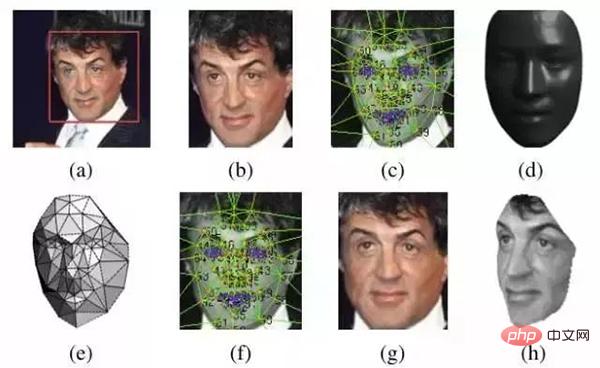
Artikel: Bayesian Face Revisited: A Joint Formulation
DeepID Series:- Fusion von sieben gemeinsamen Bayes'schen Modellen mit SVM, mit einer Genauigkeit von 99,15 %
Artikel: Deep Learning Face Representation by Joint Identification-Verification
4.2 Methode im Artikel
In dem Artikel wird ein tiefes neuronales Netzwerk (DNN) durch eine Gesichtserkennungsaufgabe mit mehreren Klassen trainiert. Die Netzwerkstruktur ist in der Abbildung oben dargestellt.
Strukturparameter: 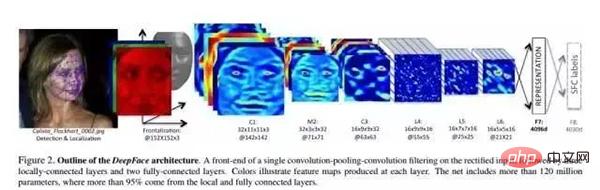
Conv: 32 11×11×3 Volumes Kernel
max-pooling: 3×3, Schritt = 2
- Conv: 16 9×9 Faltungskerne
- Local-Conv: 16 9×9 Faltungskerne, Lokal bedeutet, dass Faltungskernparameter nicht geteilt werden
- Lokal- Conv: 16 7×7-Faltungskerne, Parameter werden nicht geteilt. Level-Funktionen:
- Der Prozess ist wie folgt:
- Vorverarbeitungsstufe: 3-Kanal-Gesicht eingeben, 3D-Korrektur durchführen und dann auf 152*152 Pixel normalisieren. Größe - 152*152*3.
- Durch die Faltung Schicht C1: C1 enthält 32 11*11*3 Filter (d. h. Faltungskerne), und es werden 32 Feature-Maps erhalten – 32*142*142*3.
- Durch die Max-Polling-Schicht M2: Die Schiebefenstergröße von M2 beträgt 3*3, die Schiebeschrittgröße beträgt 2 und die drei Kanäle werden unabhängig voneinander abgefragt.
- Über eine weitere Faltungsschicht C3: C3 enthält 16 dreidimensionale Faltungskerne von 9*9*16.
Das obige dreischichtige Netzwerk dient zum Extrahieren von Merkmalen auf niedriger Ebene, z. B. einfachen Kantenmerkmalen und Texturmerkmalen. Die Max-Polling-Schicht macht das Faltungsnetzwerk robuster gegenüber lokalen Transformationen. Wenn es sich bei der Eingabe um ein korrigiertes Gesicht handelt, wird das Netzwerk robuster gegenüber kleinen Beschriftungsfehlern.
Eine solche Abfrageschicht führt jedoch dazu, dass das Netzwerk einige Informationen über die detaillierte Struktur des Gesichts und die genaue Position winziger Texturen verliert. Daher fügt das Papier die Max-Polling-Schicht erst nach der ersten Faltungsschicht hinzu. Diese vorherigen Schichten werden als adaptive Front-End-Vorverarbeitungsebenen bezeichnet. Für viele Berechnungen, in denen dies erforderlich ist, verfügen diese Schichten jedoch nur über sehr wenige Parameter. Sie erweitern einfach das Eingabebild in einen einfachen lokalen Funktionssatz.
- Nachfolgende Schichten:
- L4, L5 und L6 sind alle lokal verbundene Schichten. Genau wie die Faltungsschicht Filter verwendet, wird an jeder Position des Feature-Bildes ein anderer Satz von Filtern trainiert und gelernt. Da verschiedene Regionen nach der Korrektur unterschiedliche statistische Eigenschaften aufweisen, kann die Annahme einer räumlichen Stabilität des Faltungsnetzwerks nicht begründet werden.
- Im Vergleich zum Bereich zwischen Nase und Mund weist der Bereich zwischen Augen und Augenbrauen beispielsweise ein ganz anderes Erscheinungsbild auf und ist stark differenziert. Mit anderen Worten: Durch die Verwendung des entzerrten Eingabebilds wird die Struktur des DNN angepasst.
-
Die Verwendung lokaler Verbindungsschichten hat keinen Einfluss auf den Rechenaufwand bei der Merkmalsextraktion, wirkt sich jedoch auf die Anzahl der Trainingsparameter aus. Allein weil es eine so große Bibliothek beschrifteter Gesichter gibt, können wir uns drei große lokal verbundene Schichten leisten. Die Ausgabeeinheit der lokalen Verbindungsschicht ist von einem großen Eingabepatch betroffen, und die Verwendung (Parameter) der lokalen Verbindungsschicht kann entsprechend angepasst werden (es werden keine Gewichte geteilt)
Zum Beispiel ist die Ausgabe der L6-Schicht betroffen durch einen 74*74*3-Effekt des Eingabe-Patches. In der korrigierten Fläche ist es schwierig, statistische Parameter gemeinsam zwischen so großen Patches zu haben.
Oberste Schicht:
Schließlich sind die beiden obersten Schichten des Netzwerks (F7, F8) vollständig verbunden: Jede Ausgabeeinheit ist mit allen Eingängen verbunden. Diese beiden Ebenen können die Korrelation zwischen Merkmalen in entfernten Regionen im Gesichtsbild erfassen. Aus diesen beiden Schichten kann beispielsweise die Korrelation zwischen der Position und Form der Augen und der Position und Form des Mundes (dieser Teil enthält auch Informationen) ermittelt werden. Die Ausgabe der ersten vollständig verbundenen Schicht F7 ist unser ursprünglicher Gesichtsausdrucksvektor.
In Bezug auf den Merkmalsausdruck unterscheidet sich dieser Merkmalsvektor stark von der herkömmlichen LBP-basierten Merkmalsbeschreibung. Herkömmliche Methoden verwenden normalerweise lokale Merkmalsbeschreibungen (Berechnungshistogramme) und dienen als Eingabe für den Klassifikator.
Die Ausgabe der letzten vollständig verbundenen Schicht F8 wird in einen K-Weg-Softmax eingegeben (K ist die Anzahl der Kategorien), der eine Wahrscheinlichkeitsverteilung der Kategoriebezeichnungen generiert. Lassen Sie Ok die k-te Ausgabe eines Eingabebildes nach dem Durchlaufen des Netzwerks darstellen, dh die Wahrscheinlichkeit der Ausgabeklassenbezeichnung k kann durch die folgende Formel ausgedrückt werden:

Das Ziel des Trainings besteht darin, das zu maximieren Wahrscheinlichkeit der richtigen Ausgabekategorie (die ID des Gesichts). Dies wird erreicht, indem der Kreuzentropieverlust für jede Trainingsprobe minimiert wird. Lassen Sie k die Bezeichnung der richtigen Kategorie der gegebenen Eingabe darstellen, dann ist der Kreuzentropieverlust:
Der Kreuzentropieverlust wird minimiert, indem der Gradient des Kreuzentropieverlusts L für die Parameter berechnet und verwendet wird die Methode der stochastischen Gradientenabnahme.
Der Gradient wird durch standardmäßige Fehlerausbreitung berechnet. Interessanterweise sind die von diesem Netzwerk bereitgestellten Funktionen sehr spärlich. Mehr als 75 % der Feature-Elemente der obersten Ebene sind 0. Dies ist hauptsächlich auf die Verwendung der ReLU-Aktivierungsfunktion zurückzuführen. Diese nichtlineare Soft-Threshold-Funktion wird in allen Faltungsschichten, lokal verbundenen Schichten und vollständig verbundenen Schichten (mit Ausnahme der letzten Schicht F8) verwendet, was nach der gesamten Kaskade zu stark nichtlinearen und spärlichen Merkmalen führt.
Sparsity hängt auch mit der Verwendung der Dropout-Regularisierung zusammen, die während des Trainings zufällige Feature-Elemente auf 0 setzt. Wir haben Dropout nur in der vollständig verbundenen F7-Schicht verwendet. Aufgrund des großen Trainingssatzes konnten wir während des Trainingsprozesses keine signifikante Überanpassung feststellen.
Angesichts des Bildes I wird sein Merkmalsausdruck G(I) über das Feedforward-Netzwerk jeder L-Schicht berechnet und kann als eine Reihe von Funktionen betrachtet werden:
Normalisierung:
Auf der letzten Ebene , normalisieren wir die Elemente der Funktion auf 0 bis 1, um die Empfindlichkeit der Funktion gegenüber Beleuchtungsänderungen zu verringern. Jedes Element im Merkmalsvektor wird durch den entsprechenden Maximalwert im Trainingssatz dividiert. Führen Sie dann die L2-Normalisierung durch. Da wir die ReLU-Aktivierungsfunktion verwenden, ist unser System weniger invariant gegenüber dem Maßstab des Bildes.
Für den Ausgabevektor 4096-d:
- Normalisieren Sie zunächst jede Dimension, dh jede Dimension im Ergebnisvektor muss durch den Maximalwert der Dimension im gesamten Trainingssatz geteilt werden.
- Jeder Vektor ist L2-normalisiert. 2. Verifizierung negativ
Die Berechnungsformel für den Chi-Quadrat-Abstand lautet wie folgt:
- 2.2 Siamesisches Netzwerk
- Die In dem Artikel wurde auch die End-to-End-Metrik-Lernmethode erwähnt. Sobald das Lernen (Training) abgeschlossen ist, wird das Gesichtserkennungsnetzwerk (bis zu F7) für die beiden Eingabebilder wiederverwendet und die beiden erhaltenen Merkmalsvektoren werden direkt verwendet, um vorherzusagen, ob Die beiden Eingabebilder gehören zu derselben Person. Dies ist in die folgenden Schritte unterteilt:
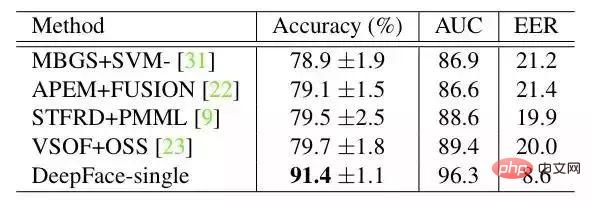
3. Experimentelle Auswertung3.1 Datensatz
- Social Face Classification Dataset (SFC): 4,4 Millionen Gesichter/4030 Personen
- LFW: 13323 Gesichter/5749 Personen
- eingeschränkt: nur Ja/Nein-Markierungen
- uneingeschränkt: andere Trainingspaare können ebenfalls absolviert werden
- unbeaufsichtigt: Kein Training auf LFW
- Youtube Face (YTF): 3425 Videos/1595 Personen
Ergebnis auf LFW:
Ergebnis auf YTF:
DeepFace mit den folgenden Methoden am größten. Der Unterschied besteht darin, dass DeepFace verwendet eine Ausrichtungsmethode vor dem Training des neuronalen Netzwerks. Der Artikel geht davon aus, dass der Grund, warum neuronale Netze funktionieren können, darin besteht, dass die Merkmale des Gesichtsbereichs nach der Ausrichtung auf bestimmte Pixel fixiert werden. Zu diesem Zeitpunkt kann das Faltungs-Neuronale Netz zum Erlernen der Merkmale verwendet werden.
Das Modell in diesem Artikel verwendet die neueste Gesichtserkennungsmethode basierend auf Deep Learning in der C++-Toolbox dlib. Basierend auf dem Benchmark-Level der Outdoor-Gesichtsdatentestbibliothek Labeled Faces in the Wild erreicht es eine Genauigkeit von 99,38 %.
Weitere Algorithmen
http://www.gycc.com/trends/face%20recognition/overview/
dlib: http://dlib.net/Datentestbibliothek Labeled Faces in the Wild : http://vis-www.cs.umass.edu/lfw/
Das Modell bietet ein einfaches Befehlszeilentool zur Gesichtserkennung, mit dem Benutzer Bildordner direkt für Gesichtserkennungsvorgänge über Befehle verwenden können.
Erfassen Sie Gesichtszüge in Bildern.
Erfassen Sie alle Gesichter in einem Bild.
Finden und verarbeiten Sie die Gesichtszüge in Bildern.
Finden Sie die Position und den Umriss der Augen, der Nase, des Mundes und des Kinns jeder Person.
import face_recognition
image = face_recognition.load_image_file("your_file.jpg")
face_locations = face_recognition.face_locations(image)
Das Erfassen von Gesichtszügen hat einen sehr wichtigen Zweck und kann natürlich auch für digitale Schönheit verwendet werden von Bildern Gesicht digitales Make-up (wie Meitu Xiuxiu)
digitales Make-up: https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py
Gesichter in Bildern erkennen
Identifizieren Wer erscheint auf dem Foto
Installationsschritte
Diese Methode unterstützt Python3/Python2. Wir haben es nur unter macOS und Linux getestet. Wir wissen nicht, ob es auf Windows anwendbar ist.
Installieren Sie dieses Modul mit pip3 von pypi (oder pip2 von Python 2)
Wichtiger Hinweis: Beim Kompilieren der dlib können Probleme auftreten. Sie können den Fehler beheben, indem Sie die dlib aus dem Quellcode (nicht pip) installieren, siehe Installationshandbuch dlib von der Quelle installieren
https://gist.github.com/ageitgey/629d75c1baac34dfa5ca2a1928a7aeaf
Schließen Sie die Installation ab, indem Sie dlib manuell installieren und pip3 install face_recognition ausführen.
So verwenden Sie die Befehlszeilenschnittstelle
Wenn Sie face_recognition installieren, erhalten Sie ein einfaches Befehlszeilenprogramm namens face_recognition, mit dem Sie ein Foto oder alle Gesichter in einem Fotoordner erkennen können.
Zuerst müssen Sie einen Ordner mit einem Foto bereitstellen, und Sie wissen bereits, wer die Person auf dem Foto ist, und der Dateiname muss nach dieser Person benannt sein.
Dann Sie Sie müssen einen weiteren Ordner mit den Fotos vorbereiten, die Sie erkennen möchten.
Als nächstes müssen Sie nur den Befehl „face_recognition“ ausführen, und das Programm kann die Person in den unbekannten Gesichtsfotos identifizieren
Für jedes Gesicht ist eine Ausgabezeile erforderlich. Die Daten bestehen aus dem Dateinamen und dem Namen der erkannten Person, getrennt durch Kommas.
Wenn Sie nur den Namen jeder Person auf dem Foto ohne den Dateinamen wissen möchten, können Sie Folgendes tun:
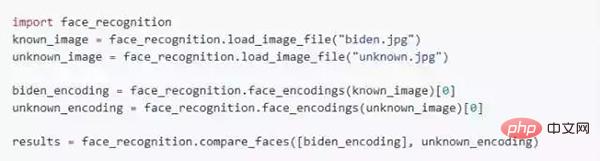
Python-Modul
Sie können den Gesichtserkennungsvorgang abschließen, indem Sie die face_recognition:
API einführen Dokumentation: https://face-recognition.readthedocs.io.
Alle Gesichter in Bildern automatisch erkennen
Bitte beachten Sie dieses Beispiel: https://github.com/ageitgey/face_recognition/blob/master/examples/ find_faces_in_picture. py
Gesichter in Bildern erkennen und Namen nennen
Bitte beziehen Sie sich auf dieses Beispiel: https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.py# 🎜🎜#
Python-Code-FallAlle Beispiele finden Sie hier.https://github.com/ageitgey/face_recognition/ tree/master/ Beispiele
·Gesichter auf einem Foto findenOkay, das war's für das heutige Teilen~https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py · 识别照片中的面部特征Identify specific facial features in a photograph https://github.com/ageitgey/face_recognition/blob/master/examples/find_facial_features_in_picture.py · 使用数字美颜Apply (horribly ugly) digital make-up https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py ·基于已知人名找到并识别出照片中的未知人脸Find and recognize unknown faces in a photograph based on photographs of known people https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.pypython人脸
Nach dem Login kopieren
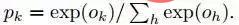
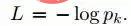

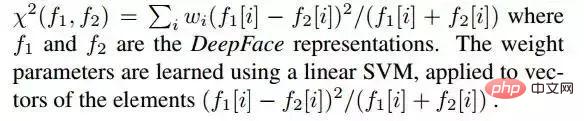 3. Experimentelle Auswertung
3. Experimentelle Auswertung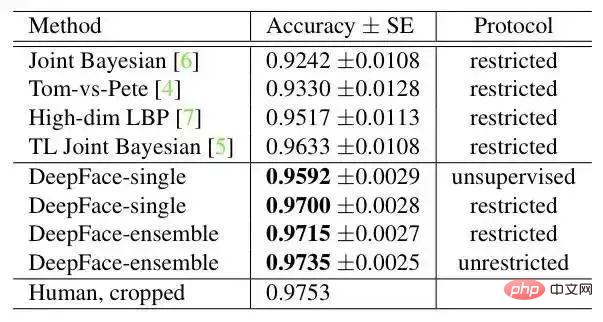


Das obige ist der detaillierte Inhalt vonPython-Gesichtserkennungssystem mit einer Offline-Erkennungsrate von bis zu 99 %, Open Source~. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1658
1658
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 Wie man Sublime Code Python ausführt
Apr 16, 2025 am 08:48 AM
Wie man Sublime Code Python ausführt
Apr 16, 2025 am 08:48 AM
Um den Python-Code im Sublime-Text auszuführen, müssen Sie zuerst das Python-Plug-In installieren, dann eine .py-Datei erstellen und den Code schreiben, und drücken Sie schließlich Strg B, um den Code auszuführen, und die Ausgabe wird in der Konsole angezeigt.
 Wo kann Code in VSCODE schreiben
Apr 15, 2025 pm 09:54 PM
Wo kann Code in VSCODE schreiben
Apr 15, 2025 pm 09:54 PM
Das Schreiben von Code in Visual Studio Code (VSCODE) ist einfach und einfach zu bedienen. Installieren Sie einfach VSCODE, erstellen Sie ein Projekt, wählen Sie eine Sprache aus, erstellen Sie eine Datei, schreiben Sie Code, speichern und führen Sie es aus. Die Vorteile von VSCODE umfassen plattformübergreifende, freie und open Source, leistungsstarke Funktionen, reichhaltige Erweiterungen sowie leichte und schnelle.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Wie man Python mit Notepad leitet
Apr 16, 2025 pm 07:33 PM
Wie man Python mit Notepad leitet
Apr 16, 2025 pm 07:33 PM
Das Ausführen von Python-Code in Notepad erfordert, dass das ausführbare Python-ausführbare Datum und das NPPEXEC-Plug-In installiert werden. Konfigurieren Sie nach dem Installieren von Python und dem Hinzufügen des Pfades den Befehl "Python" und den Parameter "{current_directory} {file_name}" im NPPExec-Plug-In, um Python-Code über den Shortcut-Taste "F6" in Notoza auszuführen.
