
 Technologie-Peripheriegeräte
KI
Maschinelles Lernen ermöglicht hochwertiges Software-Engineering
Technologie-Peripheriegeräte
KI
Maschinelles Lernen ermöglicht hochwertiges Software-Engineering
Maschinelles Lernen ermöglicht hochwertiges Software-Engineering

Übersetzer |. Zhu Xianzhong
Rezensent |. Im Laufe der Geschichte des Softwaretests werden Sie jedoch feststellen, dass viele Tests oft auf dem Niveau von Vermutungen bleiben. Mit anderen Worten: Beim Testen stellt sich der Entwickler den Betriebsprozess des Benutzers vor, schätzt die mögliche Belastung ab und analysiert die benötigte Zeit. Anschließend führt er den Test durch und vergleicht die aktuellen Ergebnisse mit der Basisantwort. Wenn wir feststellen, dass keine Regression vorliegt, gilt der aktuelle Build-Plan als korrekt. Fahren Sie dann mit den nachfolgenden Tests fort. Wenn es eine Regression gibt, geben Sie diese zurück. Meistens kennen wir die Ausgabe bereits, obwohl sie besser definiert werden muss – die Grenzen der Regression sind klar und nicht so unscharf. Tatsächlich kommen hier Systeme des maschinellen Lernens (ML) und prädiktive Analysen ins Spiel – und beenden die Mehrdeutigkeit.
Nach Abschluss des Tests prüft der Leistungsingenieur nicht nur das arithmetische Mittel und das geometrische Mittel der Ergebnisse, sondern auch die relevanten Prozentdaten. Wenn das System beispielsweise läuft, werden oft 10 % der langsamsten Anfragen durch Systemfehler verursacht – dieser Fehler führt zu einer Bedingung, die sich immer auf die Geschwindigkeit des Programms auswirkt.
Während wir die in den Daten verfügbaren Attribute manuell in Beziehung setzen können, verknüpft ML die Datenattribute möglicherweise schneller als Sie. Nachdem die Bedingungen identifiziert wurden, die 10 % der fehlerhaften Anfragen verursachen, können Leistungsingenieure Testszenarien erstellen, um das Verhalten zu reproduzieren. Das Ausführen von Tests vor und nach einem Fix kann helfen, zu bestätigen, dass der Fix korrigiert wurde.
Abbildung 1: Gesamtvertrauen in Leistungsindikatoren

Maschinelles Lernen hilft, die Softwareentwicklung zu fördern und die betreffende Entwicklungstechnologie stärker und benutzerfreundlicher zu machen verschiedene Bereiche und Branchen. Wir können kausale Muster aufdecken, indem wir Daten aus Pipelines und Umgebungen in Deep-Learning-Algorithmen einspeisen. Prädiktive Analysealgorithmen in Kombination mit Performance-Engineering-Methoden ermöglichen einen effizienteren und schnelleren Durchsatz, gewinnen Einblicke in die Art und Weise, wie Endbenutzer Software in natürlichen Szenarien verwenden, und helfen Entwicklern, die Wahrscheinlichkeit zu verringern, dass fehlerhafte Produkte in Produktionsumgebungen verwendet werden. Indem Sie Probleme und ihre Ursachen frühzeitig erkennen, können Sie sie frühzeitig im Entwicklungslebenszyklus beheben und Auswirkungen auf die Produktion verhindern. Insgesamt gibt es hier einige Möglichkeiten, wie Sie Predictive Analytics nutzen können, um die Anwendungsleistung zu verbessern.
- Ermitteln Sie die Grundursache. Sie können Techniken des maschinellen Lernens verwenden, um die Grundursache von Verfügbarkeits- oder Leistungsproblemen zu ermitteln und sich auf andere Bereiche zu konzentrieren, die Aufmerksamkeit erfordern. Prädiktive Analysen können dann verschiedene Merkmale jedes Clusters analysieren und Einblicke in die Änderungen geben, die wir vornehmen müssen, um eine optimale Leistung zu erzielen und Engpässe zu vermeiden.
- Überwachen Sie den Anwendungszustand. Der Einsatz maschineller Lerntechnologie zur Durchführung einer Anwendungsüberwachung in Echtzeit hilft Unternehmen, eine Verschlechterung der Systemleistung rechtzeitig zu erkennen und schnell zu reagieren. Die meisten Anwendungen sind auf mehrere Dienste angewiesen, um den Status der gesamten Anwendung zu ermitteln. Vorhersageanalysemodelle sind in der Lage, Daten bei normaler Ausführung der Anwendung zu korrelieren und zu analysieren, um festzustellen, ob es sich bei eingehenden Daten um Ausreißer handelt.
- Benutzerlast vorhersagen. Wir verlassen uns auf Spitzenbenutzerverkehr, um unsere Infrastruktur so zu skalieren, dass sie der Anzahl der Benutzer gerecht wird, die in Zukunft auf unsere Anwendung zugreifen. Dieser Ansatz weist Einschränkungen auf, da er Änderungen oder andere unbekannte Faktoren nicht berücksichtigt. Prädiktive Analysen helfen dabei, die Benutzerauslastung zu visualisieren und sich besser darauf vorzubereiten, und helfen Teams dabei, ihre Infrastrukturanforderungen und Kapazitätsauslastung zu planen.
- Prognostizieren Sie Ausfälle, bevor es zu spät ist. Die Vorhersage von Anwendungsausfällen oder -ausfällen, bevor sie auftreten, hilft dabei, vorbeugende Maßnahmen zu ergreifen. Predictive-Analytics-Modelle verfolgen frühere Ausfallszenarien und überwachen weiterhin ähnliche Situationen, um zukünftige Ausfälle vorherzusagen.
- Hören Sie auf, auf Schwellenwerte zu achten, und beginnen Sie mit der Datenanalyse. Die riesigen Datenmengen, die durch Observability und Monitoring entstehen, erfordern bis zu mehrere hundert Megabyte pro Woche. Auch bei modernen Analysetools muss man vorher wissen, wonach man sucht. Dies führt dazu, dass Teams nicht direkt auf die Daten schauen, sondern Schwellenwerte als Auslöser für Maßnahmen festlegen. Selbst erfahrene Teams suchen nach Ausnahmen, anstatt sich in ihre Daten zu vertiefen. Um dies zu mildern, integrieren wir das Modell mit verfügbaren Datenquellen. Das Modell filtert dann die Daten und berechnet Schwellenwerte im Zeitverlauf. Mit dieser Technik wird das Modell mit historischen Daten gefüttert und aggregiert, wodurch Schwellenwerte bereitgestellt werden, die auf der Saisonalität basieren und nicht von Menschen festgelegt werden. Das Festlegen von Schwellenwerten auf der Grundlage von Algorithmen trägt dazu bei, dass weniger Warnungen ausgelöst werden. Dies führt andererseits auch zu einer besseren Umsetzbarkeit und einem höheren Wert.
- Datensätzeübergreifend analysieren und korrelieren. Ihre Daten bestehen größtenteils aus Zeitreihen, sodass Sie leichter erkennen können, wie sich einzelne Variablen im Laufe der Zeit ändern. Viele Trends entstehen durch das Zusammenspiel mehrerer Maßnahmen. Beispielsweise verkürzen sich die Reaktionszeiten nur, wenn verschiedene Transaktionen gleichzeitig auf demselben Ziel stattfinden. Für Menschen ist dies nahezu unmöglich, aber richtig trainierte Algorithmen können dabei helfen, diese Zusammenhänge aufzudecken.
Die Bedeutung von Daten in Predictive Analytics
„Big Data“ bezieht sich normalerweise auf einen Datensatz. Ja, es handelt sich um einen großen Datensatz, die Geschwindigkeit nimmt schnell zu und der Inhalt ändert sich stark. Die Analyse solcher Daten erfordert spezielle Methoden, damit wir daraus Muster und Informationen extrahieren können. In den letzten Jahren haben Verbesserungen bei Speicher, Prozessoren, Prozessparallelität und Algorithmendesign dazu geführt, dass Systeme große Datenmengen in angemessener Zeit verarbeiten können, was eine breitere Nutzung dieser Methoden ermöglicht. Um aussagekräftige Ergebnisse zu erhalten, müssen Sie die Datenkonsistenz sicherstellen.
Zum Beispiel muss jedes Projekt das gleiche Ranking-System verwenden. Wenn also ein Projekt 1 als Schlüsselwert verwendet und ein anderes 5 – genau wie wenn Leute „DEFCON 5“ verwenden, um „DEFCON 1“ zu bedeuten, dann sind die Werte muss vor der Verarbeitung normalisiert werden. Prädiktive Algorithmen bestehen aus Algorithmen und den Daten, in die sie einspeisen, und die Softwareentwicklung generiert riesige Datenmengen, die bis vor Kurzem ungenutzt lagen und darauf warteten, gelöscht zu werden. Allerdings können Predictive-Analytics-Algorithmen diese Dateien verarbeiten, um auf der Grundlage dieser Daten Fragen zu Mustern zu stellen und zu beantworten, die wir nicht erkennen können, wie zum Beispiel:
- Verschwenden wir Zeit damit, ungenutzte Szenarien zu testen?
- Wie hängen Leistungsverbesserungen mit der Benutzerzufriedenheit zusammen?
- Wie lange dauert die Behebung eines bestimmten Defekts?
Diese Fragen und ihre Antworten dienen der prädiktiven Analyse – einem besseren Verständnis dessen, was wahrscheinlich passieren wird.
Ein weiterer wichtiger Bestandteil der Predictive Analytics ist der Algorithmus, den Sie sorgfältig auswählen oder implementieren müssen. Es ist von entscheidender Bedeutung, einfach anzufangen, da Modelle tendenziell immer komplexer werden, immer empfindlicher auf Änderungen in den Eingabedaten reagieren und möglicherweise Vorhersagen verzerren. Sie können zwei Arten von Problemen lösen: Klassifizierung und Regression (siehe Abbildung 2).Klassifizierung
- : Klassifizierung wird verwendet, um das Ergebnis einer Sammlung vorherzusagen, indem Etiketten aus den Eingabedaten abgeleitet werden (z. B „bis Beginnend mit „Down“ oder „Up“) unterteilen Sie die Sammlung in verschiedene Kategorien.
- Regression : Regression wird verwendet, um das Ergebnis einer Menge vorherzusagen, wenn die Ausgabevariable eine Menge reeller Werte ist. Es verarbeitet Eingabedaten, um Vorhersagen zu treffen – zum Beispiel die Menge des verwendeten Speichers, von Entwicklern geschriebene Codezeilen usw. Die am häufigsten verwendeten Vorhersagemodelle sind neuronale Netze, Entscheidungsbäume sowie lineare und logistische Regression.
Abbildung 2: Klassifizierung und Regression neuronaler Netze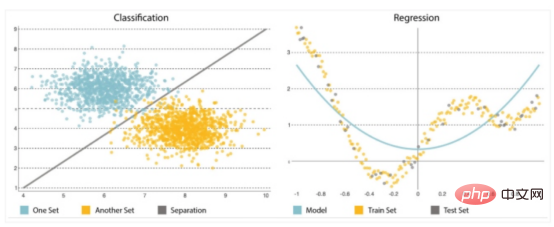
Entscheidungsbaum
Ein Entscheidungsbaum ist eine Analysemethode, die Ergebnisse in einer Reihe von „Wenn/Dann“-Optionen darstellt, um das Potenzial zu antizipieren Risiken und Vorteile bestimmter Optionen. Es kann alle Klassifizierungsprobleme lösen und komplexe Fragen beantworten.Wie in Abbildung 3 dargestellt, ähnelt ein Entscheidungsbaum einem Top-Down-Baum, der von einem Algorithmus generiert wird, der jede Komponente identifizieren kann, die die Daten in Zweige aufteilt -ähnliche Partitionen zur Veranschaulichung zukünftiger Entscheidungen und zur Identifizierung von Entscheidungspfaden.
Wenn das Laden länger als drei Sekunden dauert, handelt es sich bei einem Zweig im Baum möglicherweise um einen Benutzer, der seinen Einkaufswagen verlassen hat. Darunter kann ein weiterer Zweig anzeigen, ob es sich um eine Frau handelt. Eine „Ja“-Antwort erhöht den Einsatz, da Analysen zeigen, dass Frauen eher zu Impulskäufen neigen und diese Verzögerung zum Grübeln führen kann.
Abbildung 3: Beispiel für einen Entscheidungsbaum
Lineare und logistische Regression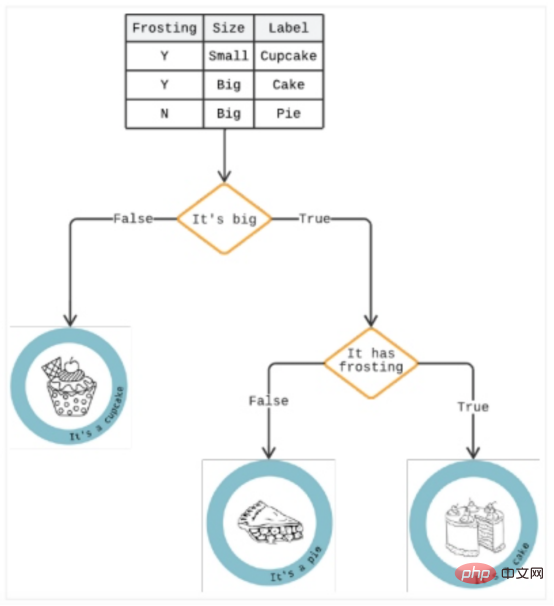
#🎜 🎜#lineare Regression | # 🎜 🎜#|
Logistische Regression | |
wird verwendet, um Werte in einem kontinuierlichen Bereich zu definieren, beispielsweise das Risiko von Benutzerverkehrsspitzen in den nächsten Monaten. |
Dies ist eine statistische Methode, bei der Parameter auf der Grundlage alter Sätze vorhergesagt werden. Es eignet sich am besten für die binäre Klassifizierung: Datensätze mit y=0 oder 1, wobei 1 die Standardklasse different darstellt. Sein Name kommt von seiner Konvertierungsfunktion ( ist eine logische Funktion ) . |
Es wird als y=a+bx dargestellt, wobei x der Eingabesatz ist, der zur Bestimmung des Ausgangs y verwendet wird. Die Koeffizienten a und b werden verwendet, um die Beziehung zwischen x und y zu quantifizieren, wobei a der Achsenabschnitt und b die Steigung der Geraden ist. |
Es wird durch die logistische Funktion dargestellt: wobei , β0 der Achsenabschnitt β ist 1 ist der Tarif . Es verwendet Trainingsdaten, um Koeffizienten zu berechnen, die den Fehler zwischen vorhergesagten und tatsächlichen Ergebnissen minimieren. |
Das Ziel besteht darin, die gerade Linie anzupassen, die den meisten Punkten am nächsten liegt, und so den Abstand oder Fehler zwischen y und der geraden Linie zu verringern. |
Es bildet eine S-förmige Kurve, bei der ein Schwellenwert angewendet wird, um die Wahrscheinlichkeiten in binäre Klassifizierungen umzuwandeln. |
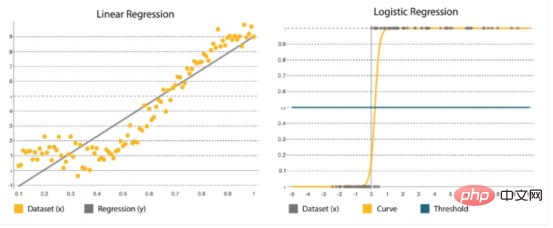
Abbildung 4: Lineare Regression vs. logistische Regression
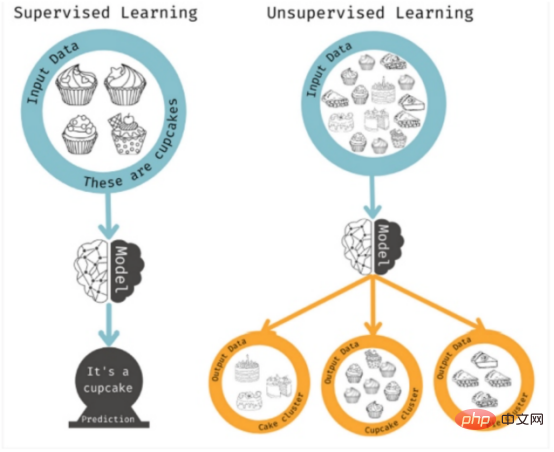
Dies sind überwachte Lernmethoden, da der Algorithmus nach bestimmten Eigenschaften sucht. Unüberwachtes Lernen kommt zum Einsatz, wenn Sie kein bestimmtes Ergebnis vor Augen haben, aber mögliche Muster oder Trends erkennen möchten. In diesem Fall analysiert das Modell so viele Merkmalskombinationen wie möglich, um Korrelationen zu finden, auf die der Mensch reagieren kann. Abbildung 5: Überwachtes vs. unüberwachtes Lernen Sobald alle Informationen gesammelt sind, müssen sie gespeichert und mithilfe geeigneter Tools und Algorithmen analysiert werden. Zu diesen Daten können Fehlerprotokolle, Testfälle, Testergebnisse, Produktionsereignisse, Anwendungsprotokolldateien, Projektdokumente, Ereignisprotokolle, Ablaufverfolgungen und mehr gehören. Wir können dies dann auf die Daten anwenden, um verschiedene Erkenntnisse zu gewinnen:
Auswirkungen auf das Kundenerlebnis bewerten
Problemmuster identifizieren
- Genauere Tests erstellen Szenarien und mehr
- Diese Technologie unterstützt einen Shift-Left-Ansatz für Qualität, der es Ihnen ermöglicht, die Zeit vorherzusagen, die für die Durchführung von Leistungstests benötigt wird, die Anzahl der Fehler, die identifiziert werden können, und die Anzahl der Fehler, die daraus resultieren können in der Produktion, wodurch eine bessere Abdeckung von Leistungstests erreicht und ein realistisches Benutzererlebnis geschaffen wird. Benutzerfreundlichkeits-, Kompatibilitäts-, Leistungs- und Sicherheitsprobleme können verhindert und behoben werden, ohne dass dies Auswirkungen auf die Benutzer hat. ...
- Defekt Ist er reproduzierbar
- Sobald Sie dies wissen, können Sie Änderungen vornehmen und Tests erstellen, um ähnliche Probleme schneller zu verhindern.
Fazit
Softwareentwickler haben seit den Anfängen der Programmierung Hunderte von Annahmen getroffen. Doch die digitalen Nutzer von heute sind sich dessen bewusster und weniger tolerant gegenüber Fehlern und Misserfolgen. Andererseits bemühen sich Unternehmen auch darum, durch maßgeschneiderte Dienste und komplexe Software, die immer schwieriger zu testen ist, ansprechendere und ausgefeiltere Benutzererlebnisse zu bieten.Heutzutage muss alles reibungslos funktionieren und alle gängigen Browser, Mobilgeräte und Apps unterstützen. Schon ein Absturz von nur wenigen Minuten kann Schäden in Höhe von mehreren Tausend oder Millionen Dollar verursachen. Um das Auftreten von Problemen zu verhindern, müssen Teams Observability-Lösungen und Benutzererfahrung während des gesamten Softwarelebenszyklus integrieren. Die Verwaltung der Qualität und Leistung komplexer Systeme erfordert mehr als nur die Ausführung von Testfällen und Lasttests. Mithilfe von Trends können Sie feststellen, ob und wie schnell eine Situation unter Kontrolle ist, sich verbessert oder verschlechtert. Die Technologie des maschinellen Lernens kann dabei helfen, Leistungsprobleme vorherzusagen, damit Teams korrigierende Anpassungen vornehmen können. Lassen Sie uns abschließend mit einem Zitat von Benjamin Franklin abschließen: „Eine Unze Prävention ist ein Pfund Heilung wert.“ Universität in Weifang und ein Veteran in der freiberuflichen Programmierbranche.
- Originaltitel:
- Performance Engineering Powered by Machine Learning
- , Autor:
Das obige ist der detaillierte Inhalt vonMaschinelles Lernen ermöglicht hochwertiges Software-Engineering. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Vier empfohlene KI-gestützte Programmiertools
Apr 22, 2024 pm 05:34 PM
Vier empfohlene KI-gestützte Programmiertools
Apr 22, 2024 pm 05:34 PM
Dieses KI-gestützte Programmiertool hat in dieser Phase der schnellen KI-Entwicklung eine große Anzahl nützlicher KI-gestützter Programmiertools zu Tage gefördert. KI-gestützte Programmiertools können die Entwicklungseffizienz verbessern, die Codequalität verbessern und Fehlerraten reduzieren. Sie sind wichtige Helfer im modernen Softwareentwicklungsprozess. Heute wird Dayao Ihnen 4 KI-gestützte Programmiertools vorstellen (und alle unterstützen die C#-Sprache). https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot ist ein KI-Codierungsassistent, der Ihnen hilft, Code schneller und mit weniger Aufwand zu schreiben, sodass Sie sich mehr auf Problemlösung und Zusammenarbeit konzentrieren können. Git
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
