

Willkommen zurück zu unserer Reihe über die Large Language Models (LLM) von OpenAI und Microsoft Sentinel. Im ersten Teil haben wir mithilfe von OpenAI und dem integrierten Azure Logic Apps-Connector von Sentinel ein grundlegendes Playbook erstellt, um die bei der Veranstaltung gefundenen MITRE ATT&CK-Taktiken zu erläutern, und einige der verschiedenen Parameter besprochen, die sich auf das OpenAI-Modell auswirken könnten, wie z. B. Temperatur und Frequenz bestrafen. Als Nächstes erweitern wir diese Funktionalität mithilfe der REST-API von Sentinel, um geplante Analyseregeln zu finden und eine Zusammenfassung der Regelerkennungslogik zurückzugeben.
Wenn Sie aufgepasst haben, ist Ihnen vielleicht aufgefallen, dass unser erstes Playbook nach MITRE ATT&CK-Taktiken aus Sentinel-Events sucht, im GPT3-Tipp jedoch keine Event-Techniken enthält. Warum nicht? Nun, starten Sie Ihren OpenAI API Playground und machen wir einen Ausflug in den Kaninchenbau (mit Entschuldigung an Lewis Carroll). ... Die folgenden MITRE ATT&CK-Taktiken und -Techniken werden erklärt: ["DefenseEvasion"], ["T1564"]"
Nun ja. ChatGPT ist wirklich „großartig“ darin, den technischen Code von MITRE ATT&CK zusammenzufassen, aber wir haben noch nicht danach gefragt. Wir haben das andere generative vorab trainierte Transformer-3.5 (GPT-3.5)-Modell „text-davinci-003“ von OpenAI im Textvervollständigungsmodus verwendet. ChatGPT verwendet das „gpt-3.5-turbo“-Modell im Chat-Abschlussmodus. Der Unterschied ist riesig. Hier ist ein Beispiel für die Antwort von ChatGPT auf dieselbe Abfrage oben:
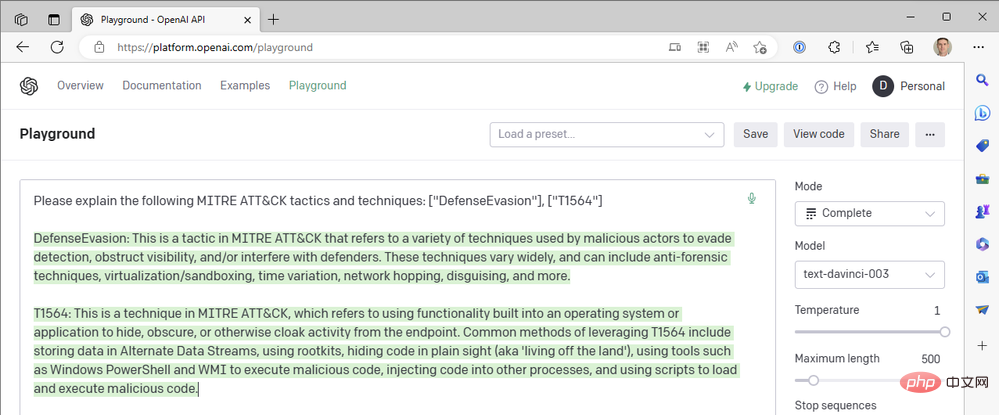
Aber der OpenAI-Connector in unserer Azure Logic App bietet uns keine chatbasierten Aktionen und wir können das Turbo-Modell nicht auswählen. Wie können wir also ChatGPT What einbinden? über unseren Sentinel-Workflow? So wie wir in Teil II den Sentinel Logic App Connector geschlossen haben, um die HTTP-Operationen der Sentinel REST API direkt aufzurufen, können wir dasselbe mit der API von OpenAI tun. Lassen Sie uns den Prozess der Erstellung eines Logic Apps-Workflows untersuchen, der ein Chat-Modell anstelle eines Textvervollständigungsmodells verwendet.
Wir verweisen auf zwei Referenzdokumente von OpenAI: Chat Creation API Reference und Chat Completion Guide. Um diesen Blog-Beitrag auf eine angemessene Länge zu beschränken, fasse ich einige der Einrichtungsaufgaben zusammen, die Sie benötigen, um unser Beispiel in Ihrer eigenen Umgebung zu replizieren: 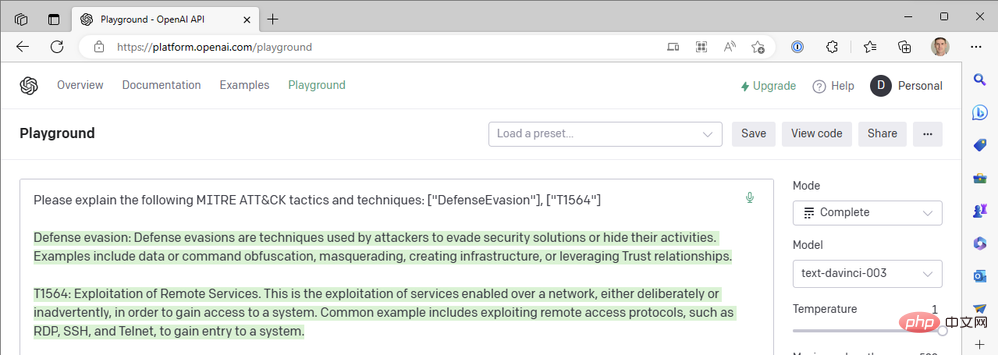
Key Vault zum Speichern Ihrer OpenAI API-Anmeldeinformationen
Eine Möglichkeit, Sie zu autorisieren Eine Möglichkeit für Ihre Logik-App, Geheimnisse aus Key Vault zu lesen (ich empfehle die Verwendung der verwalteten Identität von Azure RBAC). 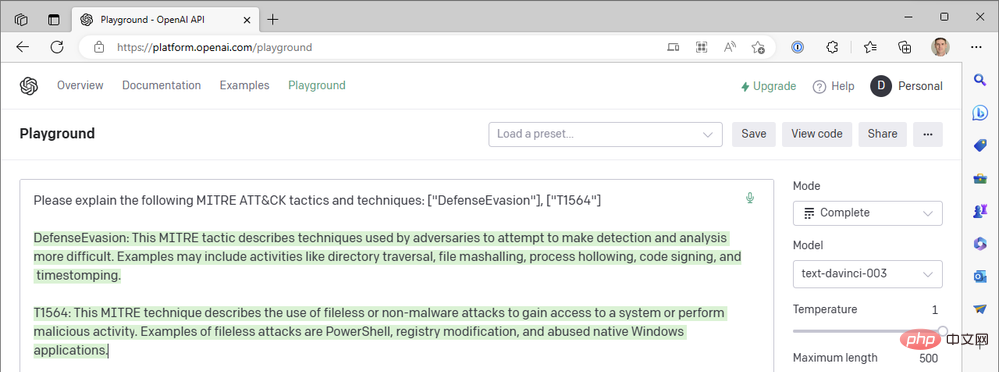
Jetzt öffnen wir unseren Logic App Designer und beginnen mit der Erstellung von Funktionen. Nach wie vor verwenden wir Microsoft Sentinel-Ereignisauslöser. Danach führen wir die Key Vault-Aktion „Get Secret“ aus, bei der wir den geheimen Namen angeben, unter dem der API-Schlüssel gespeichert wird:
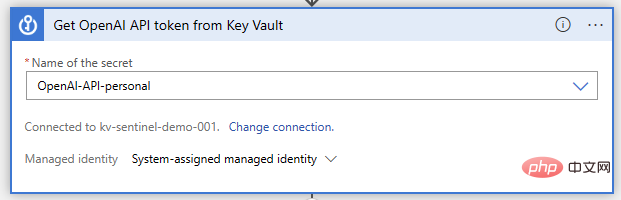 Als nächstes müssen wir einige Variablen für unsere API-Anfrage initialisieren und festlegen. Dies ist nicht unbedingt erforderlich; wir könnten die Anfrage einfach in unsere HTTP-Aktion schreiben, aber es wird es viel einfacher machen, die Eingabeaufforderung und andere Parameter später zu ändern. Die beiden erforderlichen Parameter im OpenAI-Chat-API-Aufruf sind „Modell“ und „Nachricht“. Initialisieren wir also eine Zeichenfolgenvariable zum Speichern des Modellnamens und eine Array-Variable für die Nachricht.
Als nächstes müssen wir einige Variablen für unsere API-Anfrage initialisieren und festlegen. Dies ist nicht unbedingt erforderlich; wir könnten die Anfrage einfach in unsere HTTP-Aktion schreiben, aber es wird es viel einfacher machen, die Eingabeaufforderung und andere Parameter später zu ändern. Die beiden erforderlichen Parameter im OpenAI-Chat-API-Aufruf sind „Modell“ und „Nachricht“. Initialisieren wir also eine Zeichenfolgenvariable zum Speichern des Modellnamens und eine Array-Variable für die Nachricht.
Mit dem Systemobjekt können wir den Verhaltenskontext des KI-Modells für diese Chatsitzung festlegen. Das User-Objekt ist unsere Frage und das Modell antwortet mit einem Assistant-Objekt. Bei Bedarf können wir frühere Antworten in Benutzer- und Assistentenobjekte einbinden, um dem KI-Modell einen „Gesprächsverlauf“ bereitzustellen.
Zurück in unserem Logik-App-Designer habe ich zwei Aktionen „An Array-Variable anhängen“ und eine Aktion „Variable initialisieren“ verwendet, um das Array „Nachrichten“ zu erstellen:
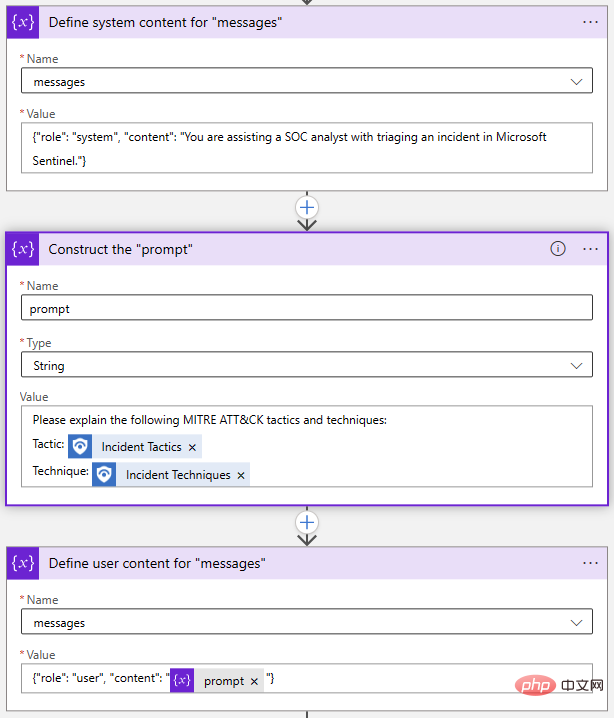
Auch dies funktioniert alles in einem Schritt erledigt, aber Ich habe mich dafür entschieden, jedes Objekt einzeln aufzulösen. Wenn ich meine Eingabeaufforderung ändern möchte, muss ich nur die Eingabeaufforderungsvariable aktualisieren.
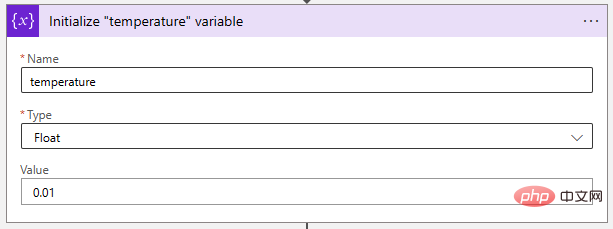
Als nächstes passen wir den Temperaturparameter auf einen sehr niedrigen Wert an, um das KI-Modell deterministischer zu machen. „Float“-Variablen eignen sich ideal zum Speichern dieses Wertes.
Zum Schluss fügen wir sie mit einer HTTP-Operation wie dieser zusammen:
{"model": @{variables('model')},"messages": @{variables('messages')},"temperature": @{variables('temperature')}}Bearer @{body('Get_OpenAI_API_token_from_Key_Vault')?['value']}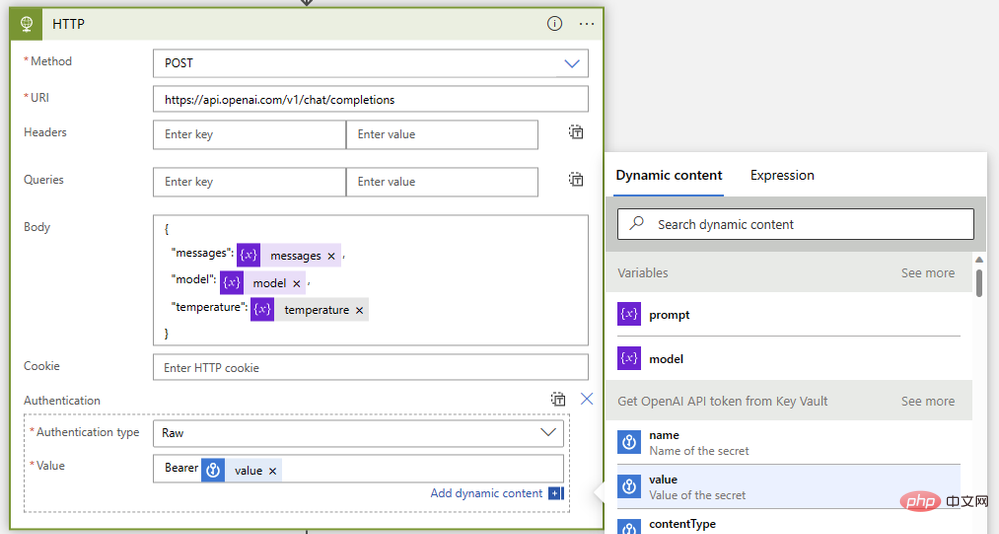
Lassen Sie uns dieses Playbook wie zuvor ohne Kommentaraktionen ausführen, um sicherzustellen, dass es fertig ist, bevor wir es wieder verbinden. Vor der Sentinel-Instanz war alles in Ordnung. Wenn alles gut geht, erhalten wir den Statuscode 200 und eine großartige Zusammenfassung der MITRE ATT&CK-Taktiken und -Techniken in der Assistentennachricht.
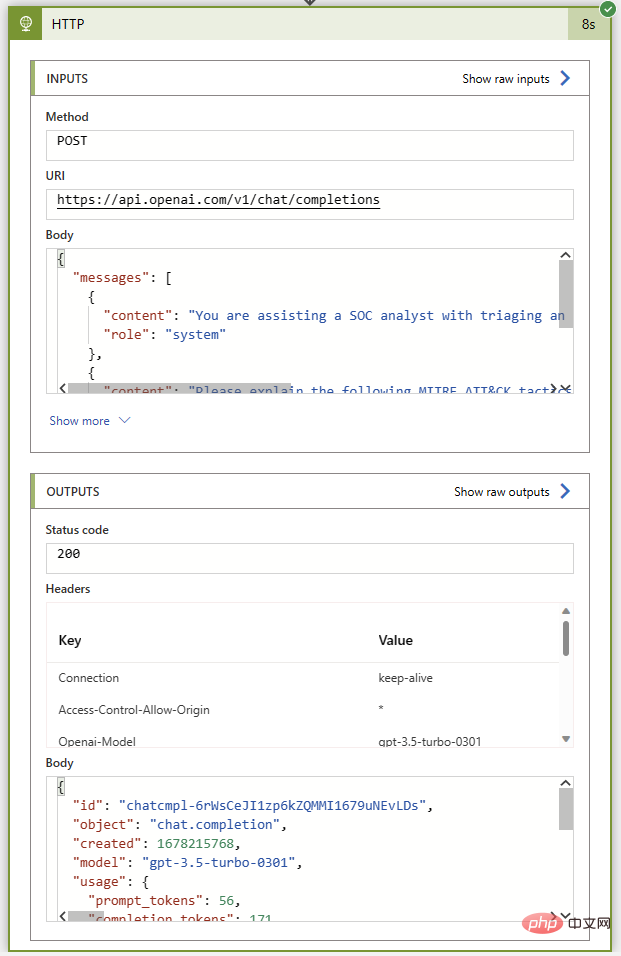
Jetzt kommt der einfache Teil: Hinzufügen von Ereigniskommentaren mithilfe des Sentinel-Connectors. Wir verwenden die Parse JSON-Operation, um den Antworttext zu analysieren und dann eine Variable mit dem Text aus der ChatGPT-Antwort zu initialisieren. Da wir das Antwortformat kennen, wissen wir, dass wir die Antwort aus dem Auswahlelement bei Index 0 mit dem folgenden Ausdruck extrahieren können:
@{body('Parse_JSON')?['choices']?[0]?['message']?['content']}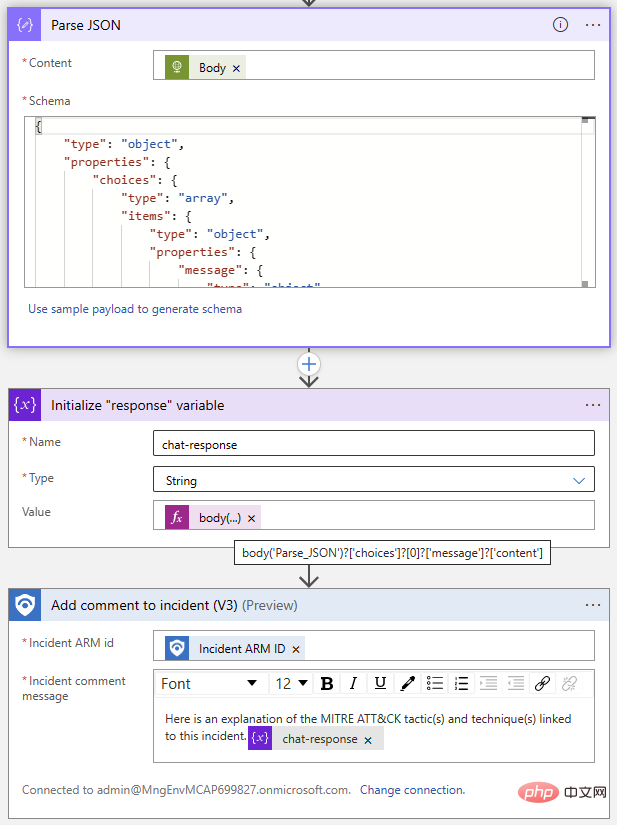
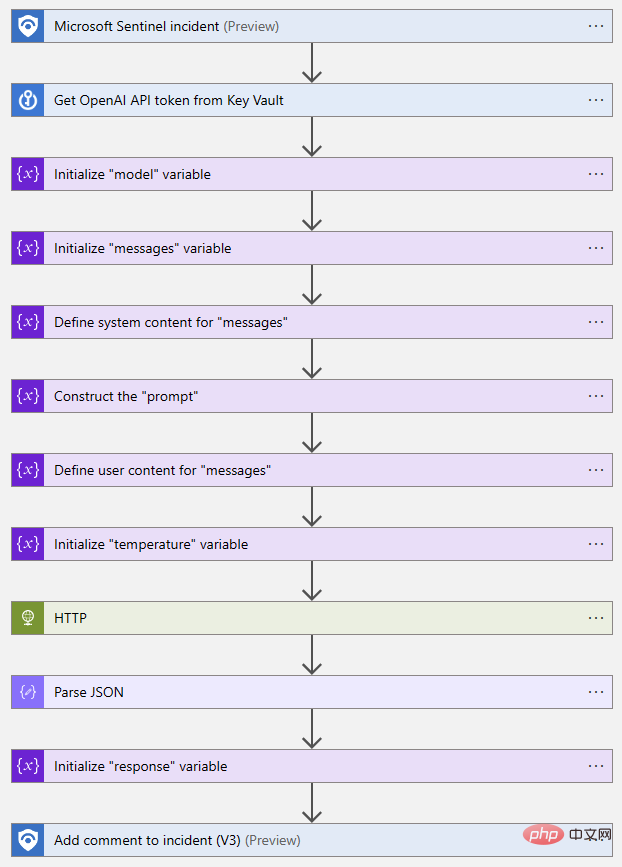
Hier ist eine Vogelperspektive des abgeschlossenen Logik-App-Ablaufs:
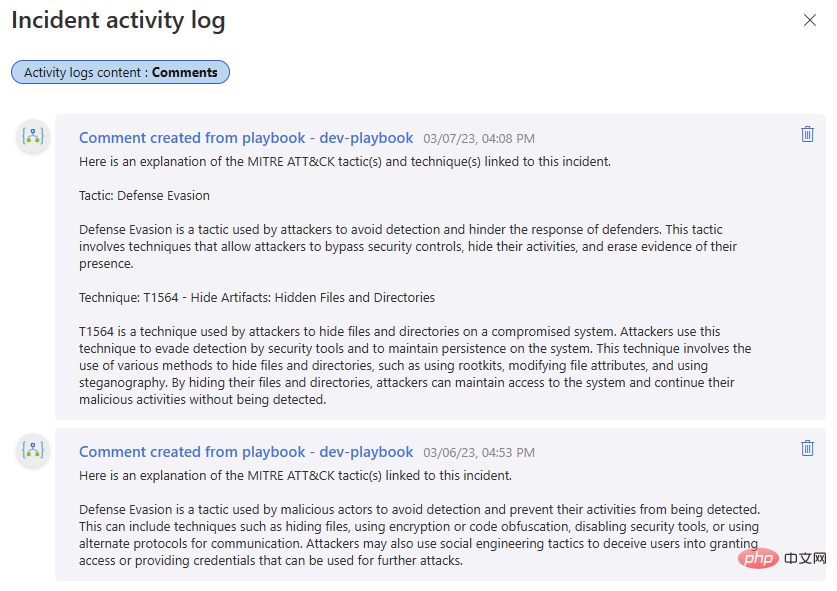
Probieren wir es aus! Ich habe Kommentare aus einer früheren Iteration dieses Playbooks in den ersten Teil dieser OpenAI- und Sentinel-Reihe eingefügt – es ist interessant, die Ausgabe der DaVinci-Textvervollständigung mit der Chat-Interaktion des Turbo-Modells zu vergleichen.
Das obige ist der detaillierte Inhalt vonOpenAI und Microsoft Sentinel Teil 3: DaVinci und Turbo. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Versionen des Linux-Systems gibt es?
Welche Versionen des Linux-Systems gibt es?
 Verwendung von #include in der C-Sprache
Verwendung von #include in der C-Sprache
 Was bedeutet Marge in CSS?
Was bedeutet Marge in CSS?
 So stellen Sie den normalen Druck wieder her, wenn der Drucker offline ist
So stellen Sie den normalen Druck wieder her, wenn der Drucker offline ist
 Was bedeutet Liquidation?
Was bedeutet Liquidation?
 Einführung in Artikel-Tag-Attribute
Einführung in Artikel-Tag-Attribute
 So starten Sie die Oracle-Datenüberwachung
So starten Sie die Oracle-Datenüberwachung
 Windows kann zum Hinzufügen eines Druckers nicht geöffnet werden
Windows kann zum Hinzufügen eines Druckers nicht geöffnet werden
 Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



