
 Technologie-Peripheriegeräte
KI
Empfohlenes Papier: Segmentierung und Klassifizierung von Brusttumoren in Ultraschallbildern basierend auf Deep Adversarial Learning
Technologie-Peripheriegeräte
KI
Empfohlenes Papier: Segmentierung und Klassifizierung von Brusttumoren in Ultraschallbildern basierend auf Deep Adversarial Learning
Empfohlenes Papier: Segmentierung und Klassifizierung von Brusttumoren in Ultraschallbildern basierend auf Deep Adversarial Learning

Bedingtes GAN (cGAN) + Atrous Convolution (AC) + Kanalaufmerksamkeit mit gewichteten Blöcken (CAW).
Dieses Papier schlägt eine Methode zur Segmentierung und Klassifizierung von Brusttumoren für Ultraschallbilder (cGAN+AC+CAW) vor, die auf Deep Adversarial Learning basiert. Obwohl das Papier bereits 2019 vorgeschlagen wurde, war die von ihm vorgeschlagene Methode zur Verwendung von GAN für die Segmentierung damals Aber Es handelt sich um eine sehr neuartige Idee, die im Grunde alle damals integrierbaren Technologien umfasste und sehr gute Ergebnisse erzielte. Darüber hinaus wurden in dem Papier auch typische Gegenmaßnahmen für SSIM-Verluste und L1-Normen vorgeschlagen Verlust als Verlustfunktion.
Verwendung von cGAN+AC+CAW für die semantische Segmentierung

Generator G
Das Generatornetzwerk besteht aus einem Encoderteil: bestehend aus sieben Faltungsschichten (En1 bis En7) und einem Decoder: sieben bestehend aus Entfaltungsschichten (Dn1 bis Dn7).
Fügen Sie einen atrous Faltungsblock zwischen En3 und En4 ein. Dilatationsverhältnisse 1, 6 und 9, Kerngröße 3×3, Schritt 2.
Es gibt auch eine Kanalaufmerksamkeitsschicht mit Kanalgewichtungsblock (CAW) zwischen En7 und Dn1.
CAW-Block ist eine Sammlung von Kanalaufmerksamkeitsmodulen (DAN) und Kanalgewichtungsblöcken (SENet), die die Darstellungsfähigkeit der Funktionen der höchsten Ebene des Generatornetzwerks erhöhen.
Diskriminator D
Es ist eine Folge von Faltungsschichten.
Die Eingabe in den Diskriminator ist die Verkettung des Bildes und einer binären Maske, die die Tumorregion markiert.
Die Ausgabe des Diskriminators ist eine 10×10-Matrix mit Werten im Bereich von 0,0 (vollständig gefälscht) bis 1,0 (echt).
Verlustfunktion
Die Verlustfunktion von Generator G besteht aus drei Begriffen: gegnerischer Verlust (binärer Kreuzentropieverlust), l1-Norm zur Erleichterung des Lernprozesses und SSIM-Verlust zur Verbesserung der Grenzform der Segmentierungsmaske:
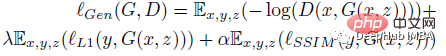
wobei z eine Zufallsvariable ist. Die Verlustfunktion des Diskriminators D lautet:
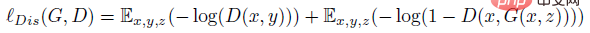
Verwendung von Random Forest für die Klassifizierungsaufgabe
Jedes Bild wird in das trainierte generative Netzwerk eingegeben, um die Tumorgrenze zu erhalten, und dann werden 13 statistische Merkmale aus dieser Grenze berechnet : fraktale Dimension, Lakunarität, konvexe Hülle, Konvexität, Zirkularität, Fläche, Umfang, Schwerpunkt, Neben- und Hauptachsenlänge, Glätte, Hu-Momente (6) und Zentralmomente (Ordnung 3 und darunter)
Unter Verwendung umfassender Merkmalsauswahl), Algorithmus um den optimalen Funktionsumfang auszuwählen. Der EFS-Algorithmus zeigt, dass fraktale Dimension, Lakunarität, konvexe Hülle und Schwerpunkt die vier optimalen Merkmale sind.
Diese ausgewählten Merkmale werden in einen Random-Forest-Klassifikator eingespeist, der dann darauf trainiert wird, zwischen gutartigen und bösartigen Tumoren zu unterscheiden.
Ergebnisvergleich
Segmentierung
Der Datensatz enthält 150 bösartige Tumoren und 100 gutartige Tumoren, die im Bild enthalten sind. Für das Training des Modells wurde der Datensatz zufällig in Trainingssatz (70 %), Validierungssatz (10 %) und Testsatz (20 %) aufgeteilt.

Dieses Modell (cGAN+AC+CAW) übertrifft andere Modelle in allen Indikatoren. Die Dice- und IoU-Werte liegen bei 93,76 % bzw. 88,82 %.
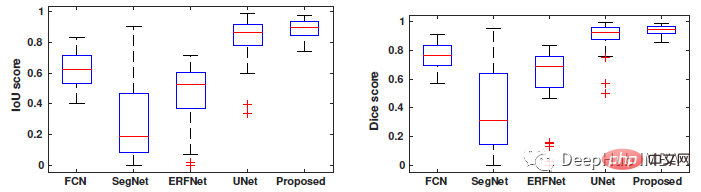
Boxplot-Vergleich von IoU und Dice des Papiermodells mit Segmentierungsköpfen wie FCN, SegNet, ERFNet und U-Net.

Der Wertebereich dieses Modells für den Dice-Koeffizienten beträgt 88 % ~ 94 %, und der Wertebereich für IoU beträgt 80 % ~ 89 %, während die Werte anderer Tiefensegmentierungsmethoden FCN, SegNet, ERFNet und U-Net sind Der Wertebereich ist breiter.
Segmentierungsergebnisse Wie in der Abbildung oben gezeigt, lieferten SegNet und ERFNet die schlechtesten Ergebnisse, mit einer großen Anzahl falsch negativer Bereiche (rot) und einigen falsch positiven Bereichen (grün).
Während U-Net, DCGAN und cGAN eine gute Segmentierung bieten, bietet das in der Arbeit vorgeschlagene Modell eine genauere Segmentierung der Brusttumorgrenzen.
Klassifizierung

Die vorgeschlagene Methode zur Klassifizierung von Brusttumoren ist besser als [9], mit einer Gesamtgenauigkeit von 85 %.
Das obige ist der detaillierte Inhalt vonEmpfohlenes Papier: Segmentierung und Klassifizierung von Brusttumoren in Ultraschallbildern basierend auf Deep Adversarial Learning. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Tipps zum dynamischen Erstellen neuer Funktionen in Golang-Funktionen
Apr 25, 2024 pm 02:39 PM
Tipps zum dynamischen Erstellen neuer Funktionen in Golang-Funktionen
Apr 25, 2024 pm 02:39 PM
Die Go-Sprache bietet zwei Technologien zur dynamischen Funktionserstellung: Schließung und Reflexion. Abschlüsse ermöglichen den Zugriff auf Variablen innerhalb des Abschlussbereichs, und durch Reflektion können mithilfe der FuncOf-Funktion neue Funktionen erstellt werden. Diese Technologien sind nützlich bei der Anpassung von HTTP-Routern, der Implementierung hochgradig anpassbarer Systeme und dem Aufbau steckbarer Komponenten.
 Überlegungen zur Parameterreihenfolge bei der Benennung von C++-Funktionen
Apr 24, 2024 pm 04:21 PM
Überlegungen zur Parameterreihenfolge bei der Benennung von C++-Funktionen
Apr 24, 2024 pm 04:21 PM
Bei der Benennung von C++-Funktionen ist es wichtig, die Reihenfolge der Parameter zu berücksichtigen, um die Lesbarkeit zu verbessern, Fehler zu reduzieren und das Refactoring zu erleichtern. Zu den gängigen Konventionen für die Parameterreihenfolge gehören: Aktion-Objekt, Objekt-Aktion, semantische Bedeutung und Einhaltung der Standardbibliothek. Die optimale Reihenfolge hängt vom Zweck der Funktion, den Parametertypen, möglichen Verwirrungen und Sprachkonventionen ab.
 AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
Herausgeber | Rettichhaut Seit der Veröffentlichung des leistungsstarken AlphaFold2 im Jahr 2021 verwenden Wissenschaftler Modelle zur Proteinstrukturvorhersage, um verschiedene Proteinstrukturen innerhalb von Zellen zu kartieren, Medikamente zu entdecken und eine „kosmische Karte“ jeder bekannten Proteininteraktion zu zeichnen. Gerade hat Google DeepMind das AlphaFold3-Modell veröffentlicht, das gemeinsame Strukturvorhersagen für Komplexe wie Proteine, Nukleinsäuren, kleine Moleküle, Ionen und modifizierte Reste durchführen kann. Die Genauigkeit von AlphaFold3 wurde im Vergleich zu vielen dedizierten Tools in der Vergangenheit (Protein-Ligand-Interaktion, Protein-Nukleinsäure-Interaktion, Antikörper-Antigen-Vorhersage) deutlich verbessert. Dies zeigt, dass dies innerhalb eines einzigen einheitlichen Deep-Learning-Frameworks möglich ist
 Wie schreibe ich effiziente und wartbare Funktionen in Java?
Apr 24, 2024 am 11:33 AM
Wie schreibe ich effiziente und wartbare Funktionen in Java?
Apr 24, 2024 am 11:33 AM
Der Schlüssel zum Schreiben effizienter und wartbarer Java-Funktionen ist: Halten Sie es einfach. Verwenden Sie eine aussagekräftige Benennung. Bewältigen Sie besondere Situationen. Nutzen Sie entsprechende Sichtbarkeit.
 Vollständige Sammlung von Excel-Funktionsformeln
May 07, 2024 pm 12:04 PM
Vollständige Sammlung von Excel-Funktionsformeln
May 07, 2024 pm 12:04 PM
1. Die SUMME-Funktion wird verwendet, um die Zahlen in einer Spalte oder einer Gruppe von Zellen zu summieren, zum Beispiel: =SUMME(A1:J10). 2. Die Funktion AVERAGE wird verwendet, um den Durchschnitt der Zahlen in einer Spalte oder einer Gruppe von Zellen zu berechnen, zum Beispiel: =AVERAGE(A1:A10). 3. COUNT-Funktion, die verwendet wird, um die Anzahl der Zahlen oder Texte in einer Spalte oder einer Gruppe von Zellen zu zählen, zum Beispiel: =COUNT(A1:A10) 4. IF-Funktion, die verwendet wird, um logische Urteile auf der Grundlage spezifizierter Bedingungen zu treffen und die zurückzugeben entsprechendes Ergebnis.
 Vergleich der Vor- und Nachteile von C++-Funktionsstandardparametern und variablen Parametern
Apr 21, 2024 am 10:21 AM
Vergleich der Vor- und Nachteile von C++-Funktionsstandardparametern und variablen Parametern
Apr 21, 2024 am 10:21 AM
Zu den Vorteilen von Standardparametern in C++-Funktionen gehören die Vereinfachung von Aufrufen, die Verbesserung der Lesbarkeit und die Vermeidung von Fehlern. Die Nachteile sind eingeschränkte Flexibilität und Namensbeschränkungen. Zu den Vorteilen variadischer Parameter gehören unbegrenzte Flexibilität und dynamische Bindung. Zu den Nachteilen gehören eine größere Komplexität, implizite Typkonvertierungen und Schwierigkeiten beim Debuggen.
 Was ist der Unterschied zwischen benutzerdefinierten PHP-Funktionen und vordefinierten Funktionen?
Apr 22, 2024 pm 02:21 PM
Was ist der Unterschied zwischen benutzerdefinierten PHP-Funktionen und vordefinierten Funktionen?
Apr 22, 2024 pm 02:21 PM
Der Unterschied zwischen benutzerdefinierten PHP-Funktionen und vordefinierten Funktionen ist: Umfang: Benutzerdefinierte Funktionen sind auf den Umfang ihrer Definition beschränkt, während auf vordefinierte Funktionen im gesamten Skript zugegriffen werden kann. So definieren Sie: Benutzerdefinierte Funktionen werden mit dem Schlüsselwort function definiert, während vordefinierte Funktionen vom PHP-Kernel definiert werden. Parameterübergabe: Benutzerdefinierte Funktionen empfangen Parameter, während vordefinierte Funktionen möglicherweise keine Parameter erfordern. Erweiterbarkeit: Benutzerdefinierte Funktionen können nach Bedarf erstellt werden, während vordefinierte Funktionen integriert sind und nicht geändert werden können.
