
 Backend-Entwicklung
Python-Tutorial
Dreißig Python-Funktionen lösen 99 % der Datenverarbeitungsaufgaben!
Backend-Entwicklung
Python-Tutorial
Dreißig Python-Funktionen lösen 99 % der Datenverarbeitungsaufgaben!
Dreißig Python-Funktionen lösen 99 % der Datenverarbeitungsaufgaben!


Wir wissen, dass Pandas die am häufigsten verwendete Datenanalyse- und Manipulationsbibliothek in Python ist. Es bietet viele Funktionen und Methoden zur schnellen Lösung von Datenverarbeitungsproblemen bei der Datenanalyse.
Um die Verwendung von Python-Funktionen besser zu beherrschen, habe ich den Kundenabwanderungsdatensatz als Beispiel genommen, um die 30 am häufigsten verwendeten Funktionen und Methoden im Datenanalyseprozess vorzustellen. Die Daten können am Ende des Artikels heruntergeladen werden .
Die Daten sehen so aus:
import numpy as np
import pandas as pd
df = pd.read_csv("Churn_Modelling.csv")
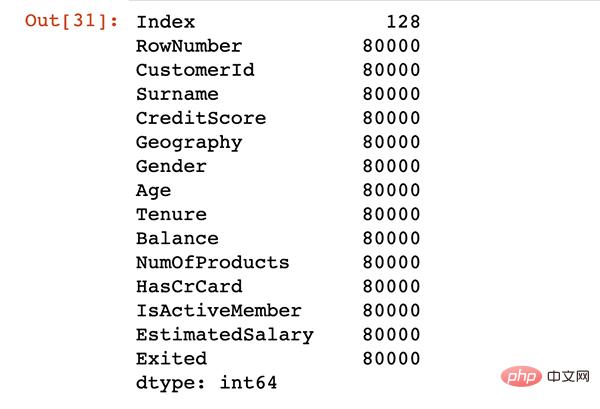
print(df.shape)
df.columns
Ergebnisausgabe
(10000, 14) Index(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography','Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard','IsActiveMember', 'EstimatedSalary', 'Exited'],dtype='object')
1. Spalten löschen
df.drop(['RowNumber', 'CustomerId', 'Surname', 'CreditScore'], axis=1, inplace=True) print(df[:2]) print(df.shape)
Ergebnisausgabe
Beschreibung: Der Parameter „Achse“ ist auf 1 gesetzt, um Spalten zu platzieren, und auf 0, um Zeilen zu platzieren. Setzen Sie den Parameter „inplace=True“ auf True, um die Änderungen zu speichern. Wir haben 4 Spalten abgezogen, sodass die Anzahl der Spalten von 14 auf 10 reduziert wurde.
GeographyGenderAgeTenureBalanceNumOfProductsHasCrCard 0FranceFemale 42 20.011 IsActiveMemberEstimatedSalaryExited 0 1101348.88 1 (10000, 10)
2.Wählen Sie bestimmte Spalten aus
Wir lesen Teilspaltendaten aus der CSV-Datei. Der Parameter usecols kann verwendet werden.
df_spec = pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_spec.head()
3.nrows
Mit dem Parameter nrows können Sie einen Datenrahmen erstellen, der die ersten 5000 Zeilen der CSV-Datei enthält. Sie können auch den Parameter „skiprows“ verwenden, um Zeilen vom Ende der Datei auszuwählen. Skiprows=5000 bedeutet, dass wir beim Lesen der CSV-Datei die ersten 5000 Zeilen überspringen.
df_partial = pd.read_csv("Churn_Modelling.csv", nrows=5000)
print(df_partial.shape)
4. Beispiel
Nachdem wir den Datenrahmen erstellt haben, benötigen wir möglicherweise ein kleines Beispiel, um die Daten zu testen. Wir können den Parameter n oder frac verwenden, um die Stichprobengröße zu bestimmen.
df= pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_sample = df.sample(n=1000)
df_sample2 = df.sample(frac=0.1)
5. Auf fehlende Werte prüfen
isna-Funktion ermittelt fehlende Werte in einem Datenrahmen. Durch die Verwendung von isna mit der Summenfunktion können wir die Anzahl der fehlenden Werte in jeder Spalte sehen.
df.isna().sum()
6. Verwenden Sie loc und iloc, um fehlende Werte hinzuzufügen.
Verwenden Sie loc und iloc, um fehlende Werte hinzuzufügen. Der Unterschied zwischen den beiden ist wie folgt:
- loc: Mit Beschriftung auswählen
- iloc: Index auswählen
Wir erstellen zunächst 20 zufällige Indexe zur Auswahl.
missing_index = np.random.randint(10000, size=20)
Wir werden loc verwenden, um einige Werte in np.nan zu ändern (fehlende Werte).
df.loc[missing_index, ['Balance','Geography']] = np.nan
20 Werte fehlen in den Spalten „Balance“ und „Geographie“. Lassen Sie uns ein weiteres Beispiel mit iloc machen.
df.iloc[missing_index, -1] = np.nan
7. Fehlende Werte auffüllen
Die Fillna-Funktion wird zum Auffüllen fehlender Werte verwendet. Es bietet viele Optionen. Wir können einen bestimmten Wert, eine Aggregatfunktion wie den Mittelwert oder den vorherigen oder nächsten Wert verwenden.
avg = df['Balance'].mean() df['Balance'].fillna(value=avg, inplace=True)
Der Methodenparameter der Funktion fillna kann verwendet werden, um fehlende Werte basierend auf dem vorherigen oder nächsten Wert in der Spalte zu füllen (z. B. method="ffill"). Dies kann für sequentielle Daten wie Zeitreihen sehr nützlich sein.
8. Fehlende Werte löschen
Eine andere Möglichkeit, mit fehlenden Werten umzugehen, besteht darin, sie zu löschen. Der folgende Code löscht Zeilen mit fehlenden Werten.
df.dropna(axis=0, how='any', inplace=True)
9. Wählen Sie Zeilen basierend auf Bedingungen aus. In einigen Fällen benötigen wir Beobachtungen (d. h. Zeilen), die bestimmte Bedingungen erfüllen.
france_churn = df[(df.Geography == 'France') & (df.Exited == 1)] france_churn.Geography.value_counts()
df2 = df.query('80000 < Balance < 100000')
df2 = df.query('80000 < Balance < 100000'
df2 = df.query('80000 < Balance < 100000')
df[df['Tenure'].isin([4,6,9,10])][:3]
12. Groupby-Funktion
Die Groupby-Funktion von Pandas ist eine vielseitige und benutzerfreundliche Funktion, die Ihnen hilft, einen Überblick über Ihre Daten zu erhalten. Es macht es einfacher, Datensätze zu untersuchen und zugrunde liegende Beziehungen zwischen Variablen aufzudecken. 
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).mean()
Nach dem Login kopieren
14. Anwenden verschiedener Aggregationsfunktionen auf verschiedene Gruppendf[['Geography','Gender','Exited']].groupby(['Geography','Gender']).mean()
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).agg(['mean','count'])
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg({'Exited':'sum', 'Balance':'mean'})
df_summary.rename(columns={'Exited':'# of churned customers', 'Balance':'Average Balance of Customers'},inplace=True)
Nach dem Login kopieren
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg({'Exited':'sum', 'Balance':'mean'})
df_summary.rename(columns={'Exited':'# of churned customers', 'Balance':'Average Balance of Customers'},inplace=True)
16. Den ursprünglichen Index zurücksetzen und löschen
import pandas as pd
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg(Number_of_churned_customers = pd.NamedAgg('Exited', 'sum'),Average_balance_of_customers = pd.NamedAgg('Balance', 'mean'))
print(df_summary)
Nach dem Login kopieren
17. Bestimmte Spalte als Index festlegen Wir können jede Spalte im Datenrahmen als Index festlegen. import pandas as pd
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg(Number_of_churned_customers = pd.NamedAgg('Exited', 'sum'),Average_balance_of_customers = pd.NamedAgg('Balance', 'mean'))
print(df_summary)
print(df_summary.reset_index())
 18. Neue Spalte einfügen
18. Neue Spalte einfügen df[['Geography','Exited','Balance']].sample(n=6).reset_index(drop=True)
19 where-Funktion
Sie wird verwendet, um den Wert in einer Zeile oder Spalte basierend auf einer Bedingung zu ersetzen. Der Standardersatzwert ist NaN, wir können aber auch einen Ersatzwert angeben.
df_new.set_index('Geography')
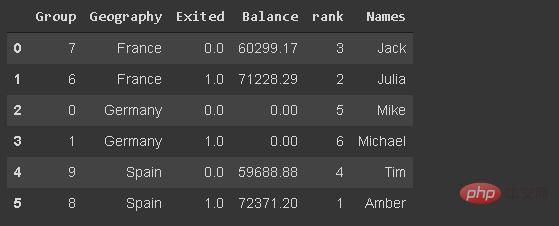
20. Rangfunktion
Die Rangfunktion weist einem Wert eine Rangfolge zu. Lassen Sie uns eine Spalte erstellen, die Kunden anhand ihres Guthabens einordnet.
group = np.random.randint(10, size=6) df_new['Group'] = group
21. Anzahl der eindeutigen Werte in einer Spalte
Das ist praktisch, wenn Sie mit kategorialen Variablen arbeiten. Möglicherweise müssen wir die Anzahl der eindeutigen Kategorien überprüfen. Wir können die Größe der von der Wertzählfunktion zurückgegebenen Sequenz überprüfen oder die Nunique-Funktion verwenden.
df_new['Balance'] = df_new['Balance'].where(df_new['Group'] >= 6, 0)
22. Speichernutzung
Mit der Funktion „memory_usage“ zeigen diese Werte den Speicher in Bytes an.
df.memory_usage()
23.数据类型转换
默认情况下,分类数据与对象数据类型一起存储。但是,它可能会导致不必要的内存使用,尤其是当分类变量具有较低的基数。
低基数意味着列与行数相比几乎没有唯一值。例如,地理列具有 3 个唯一值和 10000 行。
我们可以通过将其数据类型更改为"类别"来节省内存。
df['Geography'] = df['Geography'].astype('category')
24.替换值
替换函数可用于替换数据帧中的值。
df['Geography'].replace({0:'B1',1:'B2'})
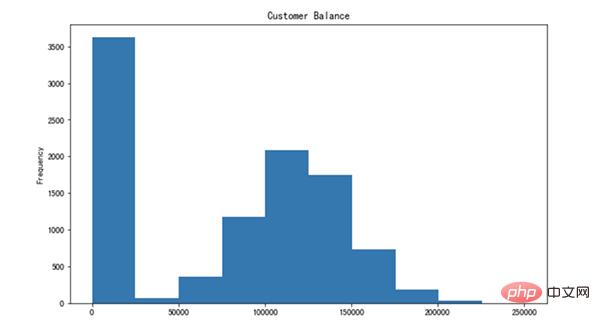
25.绘制直方图
pandas 不是一个数据可视化库,但它使得创建基本绘图变得非常简单。
我发现使用 Pandas 创建基本绘图更容易,而不是使用其他数据可视化库。
让我们创建平衡列的直方图。
26.减少浮点数小数点
pandas 可能会为浮点数显示过多的小数点。我们可以轻松地调整它。
df['Balance'].plot(kind='hist', figsize=(10,6), title='Customer Balance')
27.更改显示选项
我们可以更改各种参数的默认显示选项,而不是每次手动调整显示选项。
- get_option:返回当前选项
- set_option:更改选项 让我们将小数点的显示选项更改为 2。
pd.set_option("display.precision", 2)
可能要更改的一些其他选项包括:
- max_colwidth:列中显示的最大字符数
- max_columns:要显示的最大列数
- max_rows:要显示的最大行数
28.通过列计算百分比变化
pct_change用于计算序列中值的变化百分比。在计算时间序列或元素顺序数组中更改的百分比时,它很有用。
ser= pd.Series([2,4,5,6,72,4,6,72]) ser.pct_change()
29.基于字符串的筛选
我们可能需要根据文本数据(如客户名称)筛选观测值(行)。我已经在数据帧中添加了df_new名称。
df_new[df_new.Names.str.startswith('Mi')]
我们可能需要根据文本数据(如客户名称)筛选观测值(行)。我已经在数据帧中添加了df_new名称。

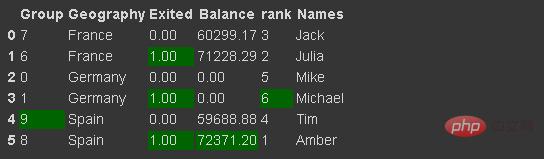
30.设置数据样式
我们可以通过使用返回 Style 对象的 Style 属性来实现此目的,它提供了许多用于格式化和显示数据框的选项。例如,我们可以突出显示最小值或最大值。
它还允许应用自定义样式函数。
df_new.style.highlight_max(axis=0, color='darkgreen')
Das obige ist der detaillierte Inhalt vonDreißig Python-Funktionen lösen 99 % der Datenverarbeitungsaufgaben!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt. Was soll ich tun? Wenn Sie MySQL herunterladen, können Sie die Korruption der Datei begegnen. Es ist heutzutage wirklich nicht einfach! In diesem Artikel wird darüber gesprochen, wie dieses Problem gelöst werden kann, damit jeder Umwege vermeiden kann. Nach dem Lesen können Sie nicht nur das beschädigte MySQL -Installationspaket reparieren, sondern auch ein tieferes Verständnis des Download- und Installationsprozesses haben, um zu vermeiden, dass Sie in Zukunft stecken bleiben. Lassen Sie uns zunächst darüber sprechen, warum das Herunterladen von Dateien beschädigt wird. Dafür gibt es viele Gründe. Netzwerkprobleme sind der Schuldige. Unterbrechung des Download -Prozesses und der Instabilität im Netzwerk kann zu einer Korruption von Dateien führen. Es gibt auch das Problem mit der Download -Quelle selbst. Die Serverdatei selbst ist gebrochen und natürlich auch unterbrochen, wenn Sie sie herunterladen. Darüber hinaus kann das übermäßige "leidenschaftliche" Scannen einer Antiviren -Software auch zu einer Beschädigung von Dateien führen. Diagnoseproblem: Stellen Sie fest, ob die Datei wirklich beschädigt ist
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
MySQL hat sich geweigert, anzufangen? Nicht in Panik, lass es uns ausprobieren! Viele Freunde stellten fest, dass der Service nach der Installation von MySQL nicht begonnen werden konnte, und sie waren so ängstlich! Mach dir keine Sorgen, dieser Artikel wird dich dazu bringen, ruhig damit umzugehen und den Mastermind dahinter herauszufinden! Nachdem Sie es gelesen haben, können Sie dieses Problem nicht nur lösen, sondern auch Ihr Verständnis von MySQL -Diensten und Ihren Ideen zur Fehlerbehebungsproblemen verbessern und zu einem leistungsstärkeren Datenbankadministrator werden! Der MySQL -Dienst startete nicht und es gibt viele Gründe, von einfachen Konfigurationsfehlern bis hin zu komplexen Systemproblemen. Beginnen wir mit den häufigsten Aspekten. Grundkenntnisse: Eine kurze Beschreibung des Service -Startup -Prozesses MySQL Service Startup. Einfach ausgedrückt, lädt das Betriebssystem MySQL-bezogene Dateien und startet dann den MySQL-Daemon. Dies beinhaltet die Konfiguration
