
 Technologie-Peripheriegeräte
KI
Von BERT bis ChatGPT, ein umfassender Überblick über neun Top-Forschungseinrichtungen, darunter die Beihang-Universität: das „Grundmodell vor der Ausbildung', das wir im Laufe der Jahre gemeinsam verfolgt haben
Technologie-Peripheriegeräte
KI
Von BERT bis ChatGPT, ein umfassender Überblick über neun Top-Forschungseinrichtungen, darunter die Beihang-Universität: das „Grundmodell vor der Ausbildung', das wir im Laufe der Jahre gemeinsam verfolgt haben
Von BERT bis ChatGPT, ein umfassender Überblick über neun Top-Forschungseinrichtungen, darunter die Beihang-Universität: das „Grundmodell vor der Ausbildung', das wir im Laufe der Jahre gemeinsam verfolgt haben

Die erstaunliche Leistung von ChatGPT in Wenig-Schuss- und Null-Schuss-Szenarien hat die Forscher zu der Überzeugung geführt, dass „Vortraining“ der richtige Weg ist.
Pretrained Foundation Models (PFM) gelten als Grundlage für verschiedene nachgelagerte Aufgaben in verschiedenen Datenmodi, d. h. basierend auf umfangreichen Daten, für BERT, GPT-3, MAE, DALLE-E und ChatGPT. usw. Das vorab trainierte Basismodell wird trainiert, um eine sinnvolle Parameterinitialisierung für nachgelagerte Anwendungen bereitzustellen.
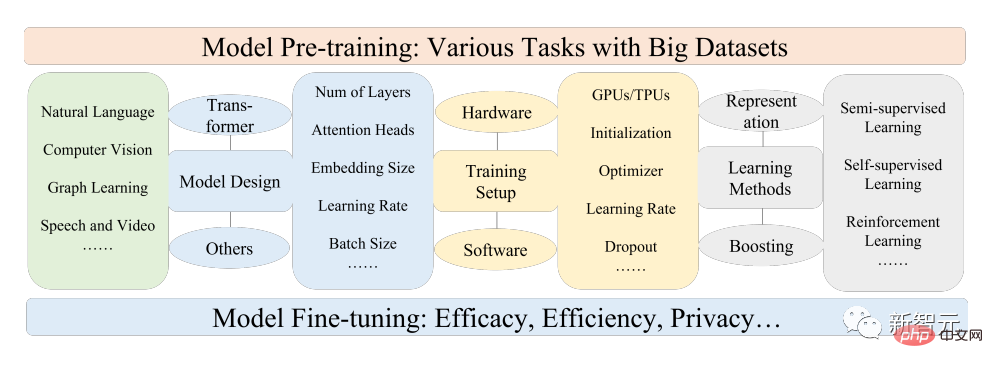
Die Pre-Training-Idee hinter PFM spielt eine wichtige Rolle bei der Anwendung großer Modelle. Anders als bei den bisherigen Methoden der Merkmalsextraktion mithilfe von Faltungs- und rekursiven Modulen spielt die generative Pre-Training-Methode (GPT) eine wichtige Rolle verwendet Transformer Als Feature-Extraktor, um autoregressives Training für große Datensätze durchzuführen.
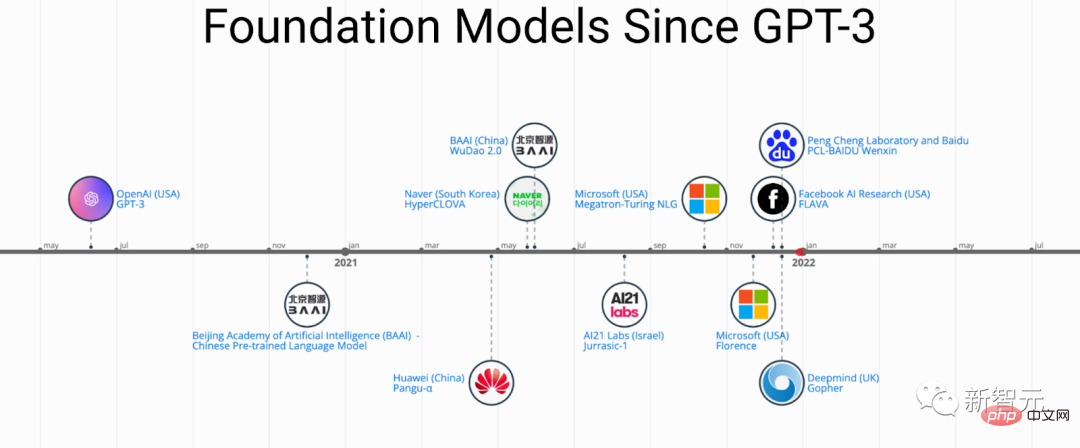
Da PFM in verschiedenen Bereichen große Erfolge erzielt hat, wurden in den letzten Jahren zahlreiche Methoden, Datensätze und Bewertungsindikatoren vorgeschlagen. Die Branche benötigt eine umfassende Überprüfung, die den Entwicklungsprozess von BERT bis ChatGPT verfolgt . .
Kürzlich haben Forscher der Beihang University, der Michigan State University, der Lehigh University, dem Nanyang Institute of Technology, Duke und anderen namhaften in- und ausländischen Universitäten und Unternehmen gemeinsam einen Bericht über Grundmodelle vor dem Training verfasst und aktuelle Forschungsfortschritte dargelegt in den Bereichen Text, Bild und Grafik sowie aktuelle und zukünftige Herausforderungen und Chancen.

Link zum Papier: https://arxiv.org/pdf/2302.09419.pdf
Die Forscher überprüften zunächst die Grundkomponenten und die bestehende Vorverarbeitung der Verarbeitung natürlicher Sprache, Computer Vision und Grafiklernen. Anschließend werden andere Datenmodi anderer fortgeschrittener PFM und vereinheitlichter PFM unter Berücksichtigung der Datenqualität und -quantität sowie der damit verbundenen Forschung zu den Grundprinzipien von PFM, einschließlich Modelleffizienz und -komprimierung, Sicherheit und Datenschutz, aufgeführt Forschungsrichtungen, Herausforderungen und offene Fragen.
Von BERT bis ChatGPT
Pre-Training-Basismodelle (PFMs) sind ein wichtiger Bestandteil beim Aufbau künstlicher Intelligenzsysteme im Zeitalter von Big Data. Sie werden häufig in der Verarbeitung natürlicher Sprache (NLP) und Computer Vision eingesetzt (CV) und Graph Learning (GL) Die drei Hauptbereiche der künstlichen Intelligenz wurden umfassend erforscht und angewendet.
PFMs sind allgemeine Modelle, die in verschiedenen Bereichen oder domänenübergreifenden Aufgaben wirksam sind und ein großes Potenzial beim Erlernen von Merkmalsdarstellungen in verschiedenen Lernaufgaben wie Textklassifizierung, Textgenerierung, Bildklassifizierung, Objekterkennung und Bildklassifizierung usw. aufweisen .
PFMs zeigen eine hervorragende Leistung beim Training mehrerer Aufgaben mit großen Korpora und bei der Feinabstimmung ähnlicher kleiner Aufgaben, wodurch eine schnelle Datenverarbeitung eingeleitet werden kann.
PFMs und Pre-Training
PFMs basieren auf Pre-Training-Technologie, die darauf abzielt, eine große Menge an Daten und Aufgaben zu nutzen, um ein allgemeines Modell zu trainieren, das in verschiedenen nachgelagerten Anwendungen leicht verfeinert werden kann.
Die Idee des Vortrainings entstand aus dem Transferlernen bei Lebenslaufaufgaben. Nachdem die Menschen die Wirksamkeit des Vortrainings im Lebenslaufbereich erkannt hatten, begannen sie, Vortrainingstechniken zu verwenden, um die Modellleistung in anderen Bereichen zu verbessern. Wenn vorab trainierte Techniken auf den NLP-Bereich angewendet werden, können gut trainierte Sprachmodelle (LMs) umfangreiches Wissen erfassen, das für nachgelagerte Aufgaben von Vorteil ist, wie z. B. langfristige Abhängigkeiten, hierarchische Beziehungen usw.
Darüber hinaus besteht der wesentliche Vorteil des Vortrainings im Bereich NLP darin, dass die Trainingsdaten aus jedem unbeschrifteten Textkorpus stammen können, d. h. es gibt eine unbegrenzte Menge an Trainingsdaten im Vortrainingsprozess.
Das frühe Vortraining war eine statische Methode wie NNLM und Word2vec, die sich nur schwer an unterschiedliche semantische Umgebungen anpassen ließ; später schlugen einige Forscher dynamische Vortrainingstechnologien wie BERT, XLNet usw. vor.

Geschichte und Entwicklung von PFMs in den Bereichen NLP, CV und GL
PFMs, die auf Pre-Training-Techniken basieren, nutzen große Korpora, um gemeinsame semantische Darstellungen zu erlernen. Mit der Einführung dieser bahnbrechenden Arbeiten haben verschiedene PFMs begonnen entstanden und wurden auf nachgelagerte Aufgaben und Anwendungen angewendet.
Ein bemerkenswerter PFM-Anwendungsfall ist das kürzlich beliebte ChatGPT.
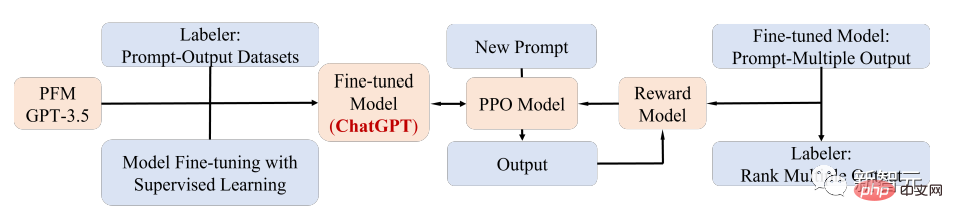
ChatGPT wird anhand des generativen Pre-Training-Transformers GPT-3.5 nach dem Training auf einem gemischten Korpus aus Text und Code verfeinert; ChatGPT nutzt Reinforcement Learning from Human Feedback (RLHF)-Technologie und ist derzeit eine der vielversprechendsten Methoden, um große LMs mit menschlichen Absichten in Einklang zu bringen.
Die überlegene Leistung von ChatGPT kann zu einem kritischen Punkt in der Transformation des Trainingsparadigmas jedes PFM-Typs führen, d. Denken) und letztendlich zur allgemeinen künstlichen Intelligenz übergehen.
In diesem Artikel untersuchen Forscher hauptsächlich PFM in Bezug auf Text, Bilder und Grafiken, bei denen es sich ebenfalls um eine relativ ausgereifte Forschungsklassifizierungsmethode handelt.
Für Texte können Sprachmodelle eine Vielzahl von Aufgaben erfüllen, indem sie das nächste Wort oder Zeichen vorhersagen. Beispielsweise können PFMs für maschinelle Übersetzung, Frage-Antwort-Systeme, Themenmodellierung, Stimmungsanalyse usw. verwendet werden .
Für Bilder werden, ähnlich wie bei PFMs im Text, große Datensätze verwendet, um ein großes Modell zu trainieren, das für mehrere CV-Aufgaben geeignet ist.
Für Diagramme werden ähnliche Ideen vor dem Training auch verwendet, um PFMs zu erhalten, die für viele nachgelagerte Aufgaben verwendet werden können.
Zusätzlich zu PFMs für bestimmte Datendomänen werden in dem Artikel auch einige andere erweiterte PFMs besprochen und erläutert, z. B. PFMs für Sprach-, Video- und domänenübergreifende Daten sowie multimodale PFMs.
Darüber hinaus zeichnet sich ein großer Fusionstrend von PFMs ab, die in der Lage sind, Multimodalität zu bewältigen, nämlich die sogenannten einheitlichen PFMs. Forscher definierten zunächst das Konzept der einheitlichen PFMs und überprüften dann den Stand der Technik. Kunst in der aktuellen Forschung Unified PFMs, einschließlich OFA, UNIFIED-IO, FLAVA, BEiT-3 usw.
Basierend auf den Merkmalen bestehender PFMs in diesen drei Bereichen kamen die Forscher zu dem Schluss, dass PFMs die folgenden zwei Hauptvorteile haben:
1 Es ist nur eine minimale Feinabstimmung erforderlich, um die Leistung des Modells bei nachgelagerten Aufgaben zu verbessern;
2. PFMs haben den Qualitätstest bestanden.
Anstatt ein Modell von Grund auf zu erstellen, um ein ähnliches Problem zu lösen, ist es eine bessere Option, PFMs auf einen aufgabenrelevanten Datensatz anzuwenden.
Die enormen Aussichten von PFMs haben viele verwandte Arbeiten inspiriert, die sich auf Themen wie Modelleffizienz, Sicherheit und Komprimierung konzentrieren.
Die Merkmale dieser Rezension sind:
- Die Forscher verfolgten die neuesten Forschungsergebnisse, gaben eine solide Zusammenfassung der Entwicklung von PFM in NLP, CV und GL, diskutierten und lieferten Informationen zu diesen drei gemeinsamen Überlegungen PFM-Design- und Pre-Training-Methoden in wichtigen Anwendungsbereichen.
- fasst die Entwicklung von PFMs in anderen Multimedia-Bereichen wie Sprache und Video zusammen und erörtert tiefergehende Themen zu PFMs, einschließlich einheitlicher PFMs, Modelleffizienz und -komprimierung sowie Sicherheit und Datenschutz.
- Anhand einer Überprüfung von PFMs für verschiedene Aufgaben in verschiedenen Modalitäten werden die wichtigsten Herausforderungen und Chancen für die zukünftige Forschung an sehr großen Modellen im Zeitalter von Big Data diskutiert, die die Entwicklung einer neuen Generation von kollaborativen Modellen leiten werden und interaktive Intelligenz basierend auf PFMs.
Referenz: https://arxiv.org/abs/2302.09419
Das obige ist der detaillierte Inhalt vonVon BERT bis ChatGPT, ein umfassender Überblick über neun Top-Forschungseinrichtungen, darunter die Beihang-Universität: das „Grundmodell vor der Ausbildung', das wir im Laufe der Jahre gemeinsam verfolgt haben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots
Oct 27, 2023 pm 06:00 PM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots
Oct 27, 2023 pm 06:00 PM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots Einführung: Im heutigen Informationszeitalter sind intelligente Kundenservicesysteme zu einem wichtigen Kommunikationsinstrument zwischen Unternehmen und Kunden geworden. Um den Kundenservice zu verbessern, greifen viele Unternehmen auf Chatbots zurück, um Aufgaben wie Kundenberatung und Beantwortung von Fragen zu erledigen. In diesem Artikel stellen wir vor, wie Sie mithilfe des leistungsstarken ChatGPT-Modells und der Python-Sprache von OpenAI einen intelligenten Kundenservice-Chatbot erstellen und verbessern können
 So installieren Sie ChatGPT auf einem Mobiltelefon
Mar 05, 2024 pm 02:31 PM
So installieren Sie ChatGPT auf einem Mobiltelefon
Mar 05, 2024 pm 02:31 PM
Installationsschritte: 1. Laden Sie die ChatGTP-Software von der offiziellen ChatGTP-Website oder dem mobilen Store herunter. 2. Wählen Sie nach dem Öffnen in der Einstellungsoberfläche die Sprache aus. 3. Wählen Sie in der Spieloberfläche das Mensch-Maschine-Spiel aus 4. Geben Sie nach dem Start Befehle in das Chatfenster ein, um mit der Software zu interagieren.
 So entwickeln Sie einen intelligenten Chatbot mit ChatGPT und Java
Oct 28, 2023 am 08:54 AM
So entwickeln Sie einen intelligenten Chatbot mit ChatGPT und Java
Oct 28, 2023 am 08:54 AM
In diesem Artikel stellen wir vor, wie man intelligente Chatbots mit ChatGPT und Java entwickelt, und stellen einige spezifische Codebeispiele bereit. ChatGPT ist die neueste Version des von OpenAI entwickelten Generative Pre-Training Transformer, einer auf neuronalen Netzwerken basierenden Technologie für künstliche Intelligenz, die natürliche Sprache verstehen und menschenähnlichen Text generieren kann. Mit ChatGPT können wir ganz einfach adaptive Chats erstellen
 Kann Chatgpt in China verwendet werden?
Mar 05, 2024 pm 03:05 PM
Kann Chatgpt in China verwendet werden?
Mar 05, 2024 pm 03:05 PM
chatgpt kann in China verwendet werden, kann jedoch nicht registriert werden. Wenn Benutzer sich registrieren möchten, können sie zur Registrierung eine ausländische Mobiltelefonnummer verwenden. Beachten Sie, dass während des Registrierungsprozesses auf die Netzwerkumgebung umgestellt werden muss eine fremde IP.
 So verwenden Sie ChatGPT und Python, um die Funktion zur Erkennung von Benutzerabsichten zu implementieren
Oct 27, 2023 am 09:04 AM
So verwenden Sie ChatGPT und Python, um die Funktion zur Erkennung von Benutzerabsichten zu implementieren
Oct 27, 2023 am 09:04 AM
So verwenden Sie ChatGPT und Python, um die Funktion zur Erkennung von Benutzerabsichten zu implementieren. Einführung: Im heutigen digitalen Zeitalter ist die Technologie der künstlichen Intelligenz in verschiedenen Bereichen nach und nach zu einem unverzichtbaren Bestandteil geworden. Unter anderem ermöglicht die Entwicklung der Technologie zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), dass Maschinen menschliche Sprache verstehen und verarbeiten können. ChatGPT (Chat-GeneratingPretrainedTransformer) ist eine Art von
 So erstellen Sie einen intelligenten Kundendienstroboter mit ChatGPT PHP
Oct 28, 2023 am 09:34 AM
So erstellen Sie einen intelligenten Kundendienstroboter mit ChatGPT PHP
Oct 28, 2023 am 09:34 AM
So bauen Sie mit ChatGPTPHP einen intelligenten Kundendienstroboter. Einführung: Mit der Entwicklung der Technologie der künstlichen Intelligenz werden Roboter zunehmend im Bereich Kundendienst eingesetzt. Der Einsatz von ChatGPTPHP zum Aufbau eines intelligenten Kundendienstroboters kann Unternehmen dabei helfen, effizientere und personalisiertere Kundendienste anzubieten. In diesem Artikel wird erläutert, wie Sie mit ChatGPTPHP einen intelligenten Kundendienstroboter erstellen, und es werden spezifische Codebeispiele bereitgestellt. 1. Installieren Sie ChatGPTPHP und nutzen Sie ChatGPTPHP, um einen intelligenten Kundendienstroboter aufzubauen.
 Die perfekte Kombination aus ChatGPT und Python: Erstellen eines Echtzeit-Chatbots
Oct 28, 2023 am 08:37 AM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines Echtzeit-Chatbots
Oct 28, 2023 am 08:37 AM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines Echtzeit-Chatbots Einführung: Mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz spielen Chatbots in verschiedenen Bereichen eine immer wichtigere Rolle. Chatbots können Benutzern helfen, sofortige und personalisierte Hilfe zu leisten und Unternehmen gleichzeitig einen effizienten Kundenservice zu bieten. In diesem Artikel wird erläutert, wie Sie mit dem ChatGPT-Modell und der Python-Sprache von OpenAI einen Echtzeit-Chat-Roboter erstellen, und es werden spezifische Codebeispiele bereitgestellt. 1. ChatGPT
