

Überblick über Ensemble-Methoden beim maschinellen Lernen

Stellen Sie sich vor, Sie kaufen online ein und finden zwei Geschäfte, die dasselbe Produkt mit derselben Bewertung verkaufen. Allerdings wurde die erste von nur einer Person bewertet und die zweite von 100 Personen. Welcher Bewertung würden Sie mehr vertrauen? Für welches Produkt werden Sie sich am Ende entscheiden? Die Antwort ist für die meisten Menschen einfach. Die Meinungen von 100 Menschen sind sicherlich vertrauenswürdiger als die Meinungen von nur einem. Dies wird als „Weisheit der Menge“ bezeichnet und ist der Grund, warum der Ensemble-Ansatz funktioniert.

Ensemble-Methoden
Normalerweise erstellen wir nur einen Lernenden (Lerner = Trainingsmodell) aus den Trainingsdaten (d. h. wir trainieren nur ein maschinelles Lernmodell auf den Trainingsdaten). Die Ensemble-Methode besteht darin, mehrere Lernende das gleiche Problem lösen zu lassen und sie dann miteinander zu kombinieren. Diese Lernenden werden Basislerner genannt und können jeden zugrunde liegenden Algorithmus haben, wie zum Beispiel neuronale Netze, Support-Vektor-Maschinen, Entscheidungsbäume usw. Wenn alle diese Basislerner aus demselben Algorithmus bestehen, werden sie als homogene Basislerner bezeichnet, während sie, wenn sie aus unterschiedlichen Algorithmen bestehen, als heterogene Basislerner bezeichnet werden. Im Vergleich zu einem einzelnen Basislerner verfügt ein Ensemble über bessere Generalisierungsfähigkeiten, was zu besseren Ergebnissen führt.
Wenn die Ensemble-Methode aus schwachen Lernenden besteht. Daher werden grundlegende Lerner manchmal als schwache Lerner bezeichnet. Während Ensemble-Modelle oder starke Lernende (die Kombinationen dieser schwachen Lernenden sind) eine geringere Voreingenommenheit/Varianz aufweisen und eine bessere Leistung erzielen. Die Fähigkeit dieses integrierten Ansatzes, schwache Lernende in starke Lernende umzuwandeln, ist populär geworden, weil schwache Lernende in der Praxis leichter verfügbar sind.
In den letzten Jahren haben integrierte Methoden kontinuierlich verschiedene Online-Wettbewerbe gewonnen. Neben Online-Wettbewerben werden Ensemble-Methoden auch in realen Anwendungen wie Computer-Vision-Technologien wie Objekterkennung, -erkennung und -verfolgung eingesetzt.
Haupttypen von Ensemble-Methoden
Wie werden schwache Lernende generiert?
Je nachdem, wie der Basislerner generiert wird, können Integrationsmethoden in zwei Hauptkategorien unterteilt werden, nämlich sequentielle Integrationsmethoden und parallele Integrationsmethoden. Wie der Name schon sagt, werden bei der Sequential-Ensemble-Methode Basislerner nacheinander generiert und dann kombiniert, um Vorhersagen zu treffen, beispielsweise Boosting-Algorithmen wie AdaBoost. Bei der Parallel-Ensemble-Methode werden die grundlegenden Lernenden parallel generiert und dann zur Vorhersage kombiniert, beispielsweise durch Bagging-Algorithmen wie Random Forest und Stacking. Die folgende Abbildung zeigt eine einfache Architektur, die parallele und sequentielle Ansätze erläutert.
Entsprechend den unterschiedlichen Generierungsmethoden grundlegender Lernender können Integrationsmethoden in zwei Hauptkategorien unterteilt werden: sequentielle Integrationsmethoden und parallele Integrationsmethoden. Wie der Name schon sagt, werden bei der sequentiellen Ensemble-Methode Basislerner der Reihe nach generiert und dann kombiniert, um Vorhersagen zu treffen, beispielsweise Boosting-Algorithmen wie AdaBoost. Bei parallelen Ensemble-Methoden werden Basislerner parallel generiert und dann zur Vorhersage kombiniert, beispielsweise Bagging-Algorithmen wie Random Forest und Stacking. Die folgende Abbildung zeigt eine einfache Architektur, die sowohl parallele als auch sequentielle Ansätze erläutert.
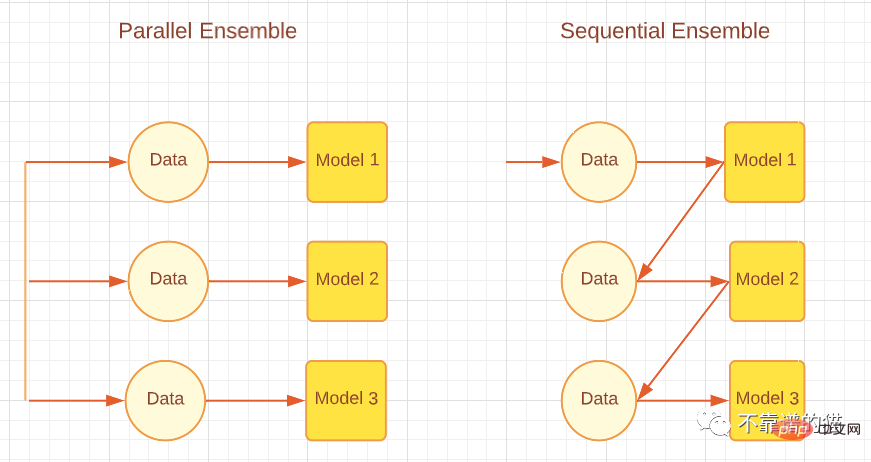
Parallele und sequentielle Integrationsmethoden
Sequentielle Lernmethoden machen sich die Abhängigkeiten zwischen schwachen Lernenden zunutze, um die Gesamtleistung in einer Weise zu verbessern, die den Restwert verringert, sodass spätere Lernende den Fehlern früherer Lernender mehr Aufmerksamkeit schenken können. Grob gesagt (bei Regressionsproblemen) wird die durch Boosting-Methoden erzielte Reduzierung des Ensemble-Modellfehlers hauptsächlich durch die Reduzierung der hohen Voreingenommenheit schwacher Lernender erreicht, obwohl manchmal eine Reduzierung der Varianz beobachtet wird. Andererseits reduziert die Parallel-Ensemble-Methode den Fehler durch die Kombination unabhängiger schwacher Lernender, d. h. sie nutzt die Unabhängigkeit zwischen schwachen Lernenden aus. Diese Fehlerreduzierung ist auf eine Verringerung der Varianz des maschinellen Lernmodells zurückzuführen. Daher können wir zusammenfassen, dass Boosting hauptsächlich Fehler reduziert, indem es die Verzerrung von Modellen für maschinelles Lernen verringert, während Bagging Fehler reduziert, indem es die Varianz von Modellen für maschinelles Lernen verringert. Dies ist wichtig, da die Wahl der Ensemble-Methode davon abhängt, ob die schwachen Lernenden eine hohe Varianz oder eine hohe Voreingenommenheit aufweisen.
Wie kann man schwache Lernende kombinieren?
Nachdem wir diese sogenannten Basislerner generiert haben, wählen wir nicht die besten dieser Lernenden aus, sondern kombinieren sie zur besseren Verallgemeinerung miteinander. Die Art und Weise, wie wir dies tun, spielt im Ensemble-Ansatz eine wichtige Rolle.
Mittelwertbildung: Wenn es sich bei der Ausgabe um eine Zahl handelt, ist die Mittelwertbildung die gebräuchlichste Methode zur Kombination von Basislernern. Der Durchschnitt kann ein einfacher Durchschnitt oder ein gewichteter Durchschnitt sein. Bei Regressionsproblemen ist der einfache Durchschnitt die Summe der Fehler aller Basismodelle geteilt durch die Gesamtzahl der Lernenden. Der gewichtete durchschnittliche kombinierte Output wird erreicht, indem jedem Basislerner unterschiedliche Gewichtungen zugewiesen werden. Bei Regressionsproblemen multiplizieren wir den Fehler jedes Basislerners mit der angegebenen Gewichtung und summieren ihn dann.
Abstimmung: Bei nominalen Ergebnissen ist die Abstimmung die häufigste Methode zur Kombination von Basislernern. Es gibt verschiedene Arten von Abstimmungen wie Mehrheitsabstimmung, Mehrheitsabstimmung, gewichtete Abstimmung und sanfte Abstimmung. Bei Klassifizierungsproblemen gibt eine Supermehrheitsabstimmung jedem Lernenden eine Stimme für eine Klassenbezeichnung. Welches Klassenlabel mehr als 50 % der Stimmen erhält, ist das vorhergesagte Ergebnis des Ensembles. Erhält jedoch kein Klassenlabel mehr als 50 % der Stimmen, besteht eine Ablehnungsmöglichkeit, was bedeutet, dass das kombinierte Ensemble keine Vorhersagen treffen kann. Bei der Abstimmung mit relativer Mehrheit ist die Klassenbezeichnung mit den meisten Stimmen das Vorhersageergebnis, und mehr als 50 % der Stimmen sind für die Klassenbezeichnung nicht erforderlich. Das heißt, wenn wir drei Ausgabebezeichnungen haben und alle drei Ergebnisse von weniger als 50 % erhalten, z. B. 40 % 30 % 30 %, dann ist das Vorhersageergebnis des Ensemblemodells das Erhalten von 40 % der Klassenbezeichnungen. . Bei der gewichteten Abstimmung werden, ebenso wie bei der gewichteten Mittelung, Klassifikatoren Gewichtungen zugewiesen, basierend auf ihrer Wichtigkeit und der Stärke eines bestimmten Lernenden. Soft Voting wird für Klassenausgaben mit Wahrscheinlichkeiten (Werten zwischen 0 und 1) anstelle von Beschriftungen (binär oder anders) verwendet. Soft Voting wird weiter unterteilt in einfaches Soft Voting (ein einfacher Durchschnitt von Wahrscheinlichkeiten) und gewichtetes Soft Voting (den Lernenden werden Gewichte zugewiesen, und die Wahrscheinlichkeiten werden mit diesen Gewichten multipliziert und addiert).
Lernen: Eine andere Möglichkeit zum Kombinieren ist das Lernen, das bei der Stacking-Ensemble-Methode zum Einsatz kommt. Bei diesem Ansatz wird ein separater Lernender, ein sogenannter Meta-Lernender, an einem neuen Datensatz trainiert, um andere Basis-/schwache Lernende zu kombinieren, die aus dem ursprünglichen Datensatz für maschinelles Lernen generiert wurden.
Bitte beachten Sie, dass alle drei Ensemble-Methoden, egal ob Boosting, Bagging oder Stacking, mit homogenen oder heterogenen schwachen Lernenden generiert werden können. Der gebräuchlichste Ansatz besteht darin, homogene schwache Lerner für Bagging und Boosting und heterogene schwache Lerner für Stacking zu verwenden. Die folgende Abbildung bietet eine gute Klassifizierung der drei wichtigsten Ensemble-Methoden.
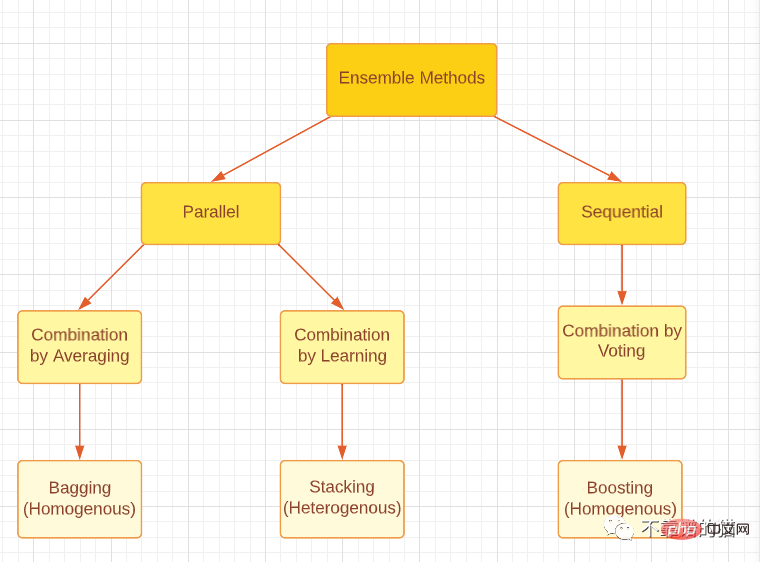
Klassifizieren Sie die wichtigsten Arten von Ensemble-Methoden.
Ensemble-Vielfalt.
Ensemble-Vielfalt bezieht sich darauf, wie unterschiedlich die Basislernenden sind, was für die Generierung guter Ensemble-Modelle von großer Bedeutung ist. Es ist theoretisch erwiesen, dass durch unterschiedliche Kombinationsmethoden völlig unabhängige (diverse) Basislerner Fehler minimieren können, während vollständig (hoch) verwandte Lernende keine Verbesserung bringen. Dies ist im wirklichen Leben ein herausforderndes Problem, da wir allen schwachen Lernenden beibringen, dasselbe Problem mithilfe desselben Datensatzes zu lösen, was zu einer hohen Korrelation führt. Darüber hinaus müssen wir sicherstellen, dass schwache Lernende keine wirklich schlechten Vorbilder sind, da dies sogar zu einer Verschlechterung der Ensembleleistung führen kann. Andererseits ist die Kombination starker und genauer Basislerner möglicherweise nicht so effektiv wie die Kombination einiger schwacher Lernender mit einigen starken Lernenden. Daher muss ein Gleichgewicht zwischen der Genauigkeit des Basislerners und den Unterschieden zwischen den Basislernern hergestellt werden.
Wie erreicht man integrierte Vielfalt?
1. Datenverarbeitung
Wir können unseren Datensatz in Teilmengen für grundlegende Lernende aufteilen. Wenn der Datensatz für maschinelles Lernen groß ist, können wir den Datensatz einfach in gleiche Teile aufteilen und diese in das Modell für maschinelles Lernen einspeisen. Wenn der Datensatz klein ist, können wir eine Zufallsstichprobe mit Ersetzung verwenden, um aus dem ursprünglichen Datensatz einen neuen Datensatz zu generieren. Die Bagging-Methode verwendet die Bootstrapping-Technik, um neue Datensätze zu generieren, bei der es sich im Grunde um eine Zufallsstichprobe mit Ersetzung handelt. Mit Bootstrapping können wir eine gewisse Zufälligkeit erzeugen, da alle generierten Datensätze unterschiedliche Werte haben müssen. Beachten Sie jedoch, dass die meisten Werte (etwa 67 % laut Theorie) immer noch wiederholt werden, sodass die Datensätze nicht vollständig unabhängig sind.
2. Eingabefunktionen
Alle Datensätze enthalten Funktionen, die Informationen über die Daten liefern. Anstatt alle Features in einem Modell zu verwenden, können wir Teilmengen von Features erstellen und verschiedene Datensätze generieren und diese in das Modell einspeisen. Diese Methode wird von der Random-Forest-Technik übernommen und ist effektiv, wenn die Daten eine große Anzahl redundanter Merkmale enthalten. Die Wirksamkeit nimmt ab, wenn der Datensatz nur wenige Features enthält.
3. Lernparameter
Diese Technik erzeugt Zufälligkeit im Basislerner, indem sie verschiedene Parametereinstellungen auf den Basislernalgorithmus anwendet, d. h. Hyperparameter-Tuning. Beispielsweise können durch Änderung der Regularisierungsterme einzelnen neuronalen Netzen unterschiedliche Anfangsgewichte zugewiesen werden.
Integration Pruning
Schließlich kann die Integration Pruning-Technologie in einigen Fällen dazu beitragen, eine bessere Integrationsleistung zu erzielen. Ensemble Pruning bedeutet, dass wir nur eine Teilmenge der Lernenden kombinieren, anstatt alle schwachen Lernenden. Darüber hinaus können kleinere Integrationen Speicher- und Rechenressourcen einsparen und so die Effizienz steigern.
Endlich
Dieser Artikel ist nur ein Überblick über die Ensemble-Methoden des maschinellen Lernens. Ich hoffe, dass jeder eine tiefergehende Recherche durchführen und, was noch wichtiger ist, in der Lage ist, die Forschung auf das wirkliche Leben anzuwenden.
Das obige ist der detaillierte Inhalt vonÜberblick über Ensemble-Methoden beim maschinellen Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 KI-Startups wechselten gemeinsam ihre Jobs zu OpenAI, und das Sicherheitsteam formierte sich neu, nachdem Ilya gegangen war!
Jun 08, 2024 pm 01:00 PM
KI-Startups wechselten gemeinsam ihre Jobs zu OpenAI, und das Sicherheitsteam formierte sich neu, nachdem Ilya gegangen war!
Jun 08, 2024 pm 01:00 PM
Letzte Woche wurde OpenAI inmitten der Welle interner Kündigungen und externer Kritik von internen und externen Problemen geplagt: - Der Verstoß gegen die Schwester der Witwe löste weltweit hitzige Diskussionen aus - Mitarbeiter, die „Overlord-Klauseln“ unterzeichneten, wurden einer nach dem anderen entlarvt – Internetnutzer listeten Ultramans „ Sieben Todsünden“ – Gerüchtebekämpfung: Laut durchgesickerten Informationen und Dokumenten, die Vox erhalten hat, war sich die leitende Führung von OpenAI, darunter Altman, dieser Eigenkapitalrückgewinnungsbestimmungen wohl bewusst und hat ihnen zugestimmt. Darüber hinaus steht OpenAI vor einem ernsten und dringenden Problem – der KI-Sicherheit. Die jüngsten Abgänge von fünf sicherheitsrelevanten Mitarbeitern, darunter zwei der prominentesten Mitarbeiter, und die Auflösung des „Super Alignment“-Teams haben die Sicherheitsprobleme von OpenAI erneut ins Rampenlicht gerückt. Das Fortune-Magazin berichtete, dass OpenA
