
 Technologie-Peripheriegeräte
KI
Die KI hat das Spielen von „Minecraft' von Grund auf gelernt, DeepMind AI hat einen Durchbruch bei der Verallgemeinerung geschafft
Technologie-Peripheriegeräte
KI
Die KI hat das Spielen von „Minecraft' von Grund auf gelernt, DeepMind AI hat einen Durchbruch bei der Verallgemeinerung geschafft
Die KI hat das Spielen von „Minecraft' von Grund auf gelernt, DeepMind AI hat einen Durchbruch bei der Verallgemeinerung geschafft

Allgemeine Intelligenz muss Aufgaben in mehreren Bereichen lösen. Man geht davon aus, dass Reinforcement-Learning-Algorithmen über dieses Potenzial verfügen, es wird jedoch durch die Ressourcen und das Wissen beeinträchtigt, die erforderlich sind, um sie an neue Aufgaben anzupassen. In einer neuen Studie von DeepMind demonstrieren Forscher DreamerV3, einen allgemeinen, skalierbaren, auf einem Weltmodell basierenden Algorithmus, der frühere Methoden in einem breiten Spektrum von Bereichen mit festen Hyperparametern übertrifft.
DreamerV3 entspricht Domänen wie kontinuierlichen und diskreten Aktionen, visuellen und niedrigdimensionalen Eingaben, 2D- und 3D-Welten, unterschiedlichen Datenmengen, Belohnungshäufigkeiten und Belohnungsniveaus. Es ist erwähnenswert, dass DreamerV3 der erste Algorithmus ist, der Diamanten in Minecraft von Grund auf ohne menschliche Daten oder aktive Ausbildung sammelt. Die Forscher sagen, dass ein solcher allgemeiner Algorithmus weitreichende Anwendungen des verstärkenden Lernens ermöglichen und möglicherweise auf schwierige Entscheidungsprobleme ausgeweitet werden könnte.
Diamanten gehören zu den beliebtesten Gegenständen im Spiel „Minecraft“. Sie gehören zu den seltensten Gegenständen im Spiel und können zur Herstellung der meisten der mächtigsten Werkzeuge, Waffen und Rüstungen im Spiel verwendet werden. Da Diamanten nur in den tiefsten Gesteinsschichten vorkommen, ist die Produktion gering.
DreamerV3 ist der erste Algorithmus zum Sammeln von Diamanten in Minecraft, ohne dass menschliche Demos oder manuelle Erstellung von Kursen erforderlich sind. Dieses Video zeigt den ersten gesammelten Diamanten, der innerhalb von 30 Millionen Umgebungsschritten / 17 Tagen Spielzeit auftrat.
Wenn Sie keine Ahnung haben, wie KI Minecraft spielt, sagt der NVIDIA-KI-Wissenschaftler Jim Fan, dass im Vergleich zu AlphaGo beim Spielen von Go die Anzahl der Minecraft-Aufgaben unbegrenzt ist, die Umgebungsänderungen unbegrenzt sind und das Wissen auch verborgene Informationen enthält.
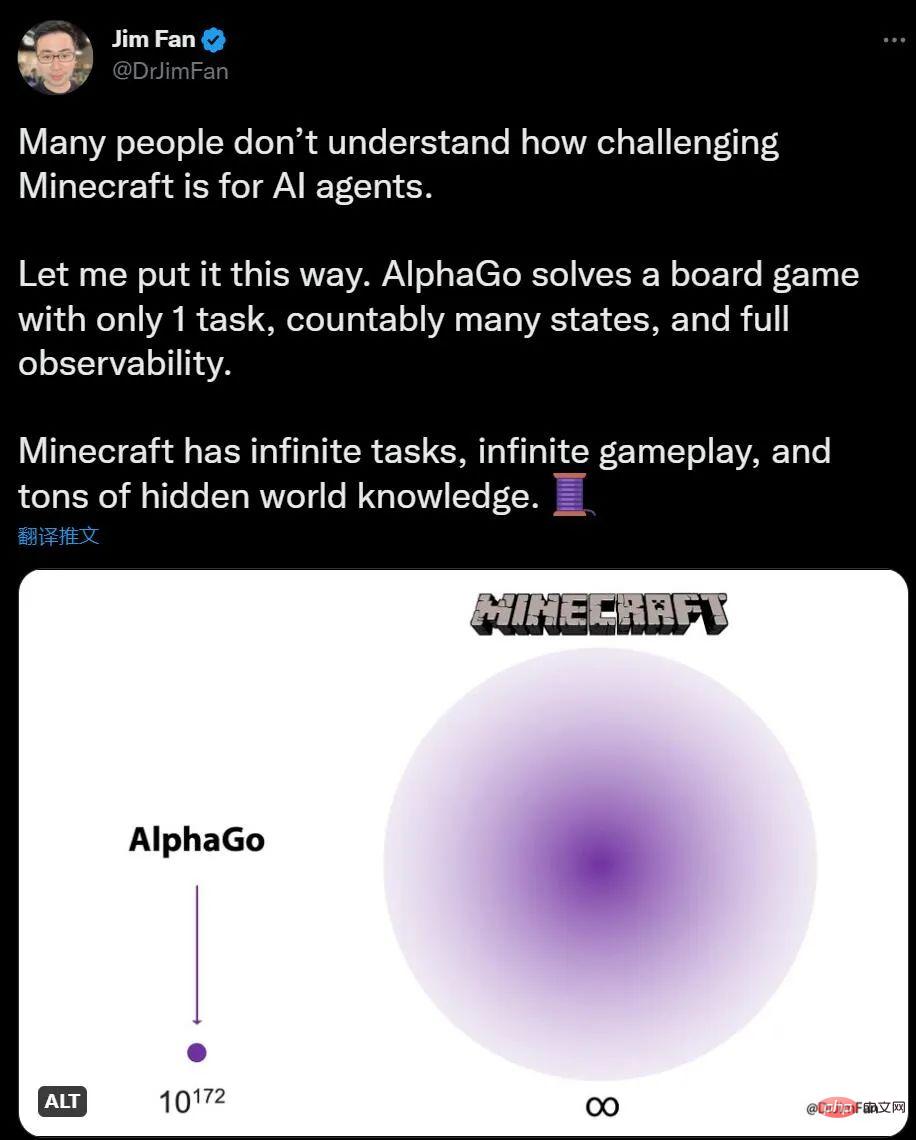
Für Menschen macht das Erkunden und Bauen in Minecraft Spaß, während Go für KI etwas kompliziert erscheint, ist die Situation genau das Gegenteil. AlphaGo hat den menschlichen Champion vor 6 Jahren besiegt, aber jetzt gibt es keinen Algorithmus, der mit den menschlichen Meistern von Minecraft mithalten kann.
Bereits im Sommer 2019 schlug die Entwicklungsfirma Minecraft die „Diamond Challenge“ vor und bot eine Belohnung für einen KI-Algorithmus an, der bis NeurIPS 2019 unter den mehr als 660 eingereichten Einsendungen Diamanten finden kann , Keine KI ist dieser Aufgabe gewachsen.
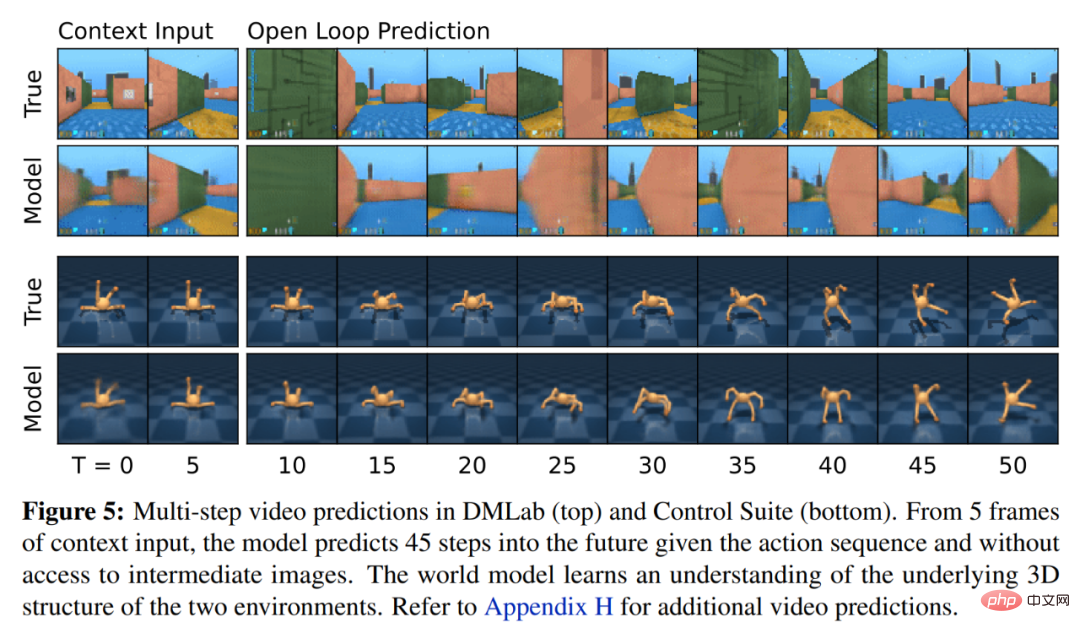
Aber das Aufkommen von DreamerV3 hat diese Situation verändert. Diamanten sind eine hochkomplexe und langfristige Aufgabe, die eine komplexe Erkundung und Planung erfordert. Der neue Algorithmus kann Diamanten ohne künstliche Datenunterstützung sammeln. Vielleicht gibt es noch viel Raum für Effizienzsteigerungen, aber die Tatsache, dass der KI-Agent nun lernen kann, Diamanten von Grund auf zu sammeln, ist ein wichtiger Meilenstein . Übersicht über die DreamerV3-Methode DreamerV3-Algorithmus ist powered by Es besteht aus drei neuronalen Netzen, nämlich Weltmodell, Kritiker und Akteur. Die drei neuronalen Netze werden gleichzeitig auf der Grundlage von Wiederholungserfahrungen ohne gemeinsame Nutzung von Gradienten trainiert. Abbildung 3(a) unten zeigt das Lernen des Weltmodells und Abbildung (b) zeigt das Lernen der Akteur-Kritiker.
Um domänenübergreifenden Erfolg zu erzielen, müssen sich diese Komponenten an unterschiedliche Signalamplituden anpassen und die Terme stabil über ihre Ziele hinweg ausbalancieren. Dies ist eine Herausforderung, da Lernen nicht nur für ähnliche Aufgaben innerhalb derselben Domäne erforderlich ist, sondern auch über verschiedene Domänen hinweg unter Verwendung fester Hyperparameter.

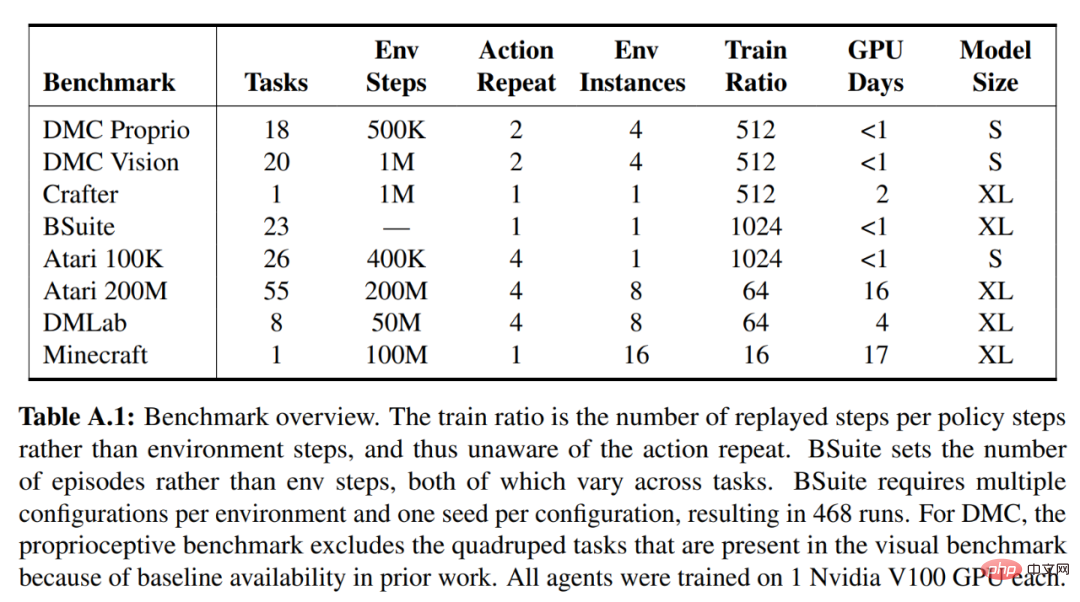
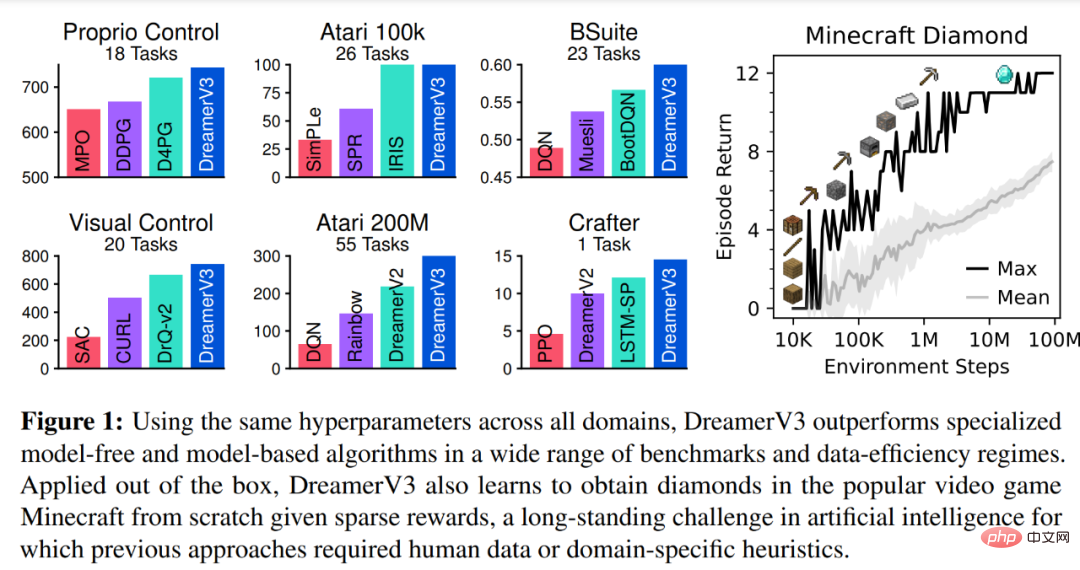
DeepMind erklärt zunächst einfache Transformationen zur Vorhersage unbekannter Größenordnungen und stellt dann Weltmodelle, Kritiker, Akteure und ihre robusten Lernziele vor. Es wurde festgestellt, dass die Kombination von KL-Gleichgewicht und freien Bits das Erlernen des Weltmodells ohne Anpassung ermöglicht und einen Entropie-Regularisierer mit fester Richtlinie erreicht, indem große Renditen verringert werden, ohne kleine Renditen zu übertreiben. Symlog-Vorhersagen Die Rekonstruktion von Eingaben und die Vorhersage von Belohnungen und Werten ist eine Herausforderung, da ihr Umfang von Domäne zu Domäne variieren kann. Die Verwendung des quadratischen Verlusts zur Vorhersage großer Ziele führt zu Divergenz, während der absolute Verlust und der Huber-Verlust das Lernen behindern. Andererseits führen Normalisierungsziele, die auf Betriebsstatistiken basieren, zu Nichtstationarität in der Optimierung. Daher schlägt DeepMind die Symlog-Vorhersage als einfache Lösung für dieses Problem vor. Dazu lernt ein neuronales Netzwerk f (x, θ) mit Eingabe x und Parameter θ, eine transformierte Version seines Ziels y vorherzusagen. Um die Vorhersage y^ des Netzwerks auszulesen, verwendet DeepMind eine inverse Transformation, wie in Gleichung (1) unten dargestellt. Wie Sie in Abbildung 4 unten sehen können, können Ziele mit negativen Werten nicht mithilfe des Logarithmus (Logarithmus) als Transformation vorhergesagt werden. Daher wählt DeepMind eine Funktion aus der Familie der bisymmetrischen Logarithmen mit dem Namen Symlog als Transformation aus und verwendet die Funktion Symexp als Umkehrfunktion. Die symlog-Funktion komprimiert die Größe großer positiver und negativer Werte. DreamerV3 verwendet die Symlog-Vorhersage im Decoder, Belohnungsprädiktor und Kritiker und verwendet auch die Symlog-Funktion, um die Eingabe des Encoders zu komprimieren. Weltmodelllernen Das Weltmodell lernt eine kompakte Darstellung sensorischer Eingaben durch automatische Kodierung und ermöglicht die Planung durch Vorhersage zukünftiger Darstellungen und Belohnungen für potenzielle Aktionen. Wie in Abbildung 3 oben dargestellt, implementiert DeepMind das Weltmodell als Recurrent State Space Model (RSSM). Zuerst ordnet ein Encoder die sensorische Eingabe x_t einer zufälligen Darstellung z_t zu, und dann sagt ein Sequenzmodell mit wiederkehrenden Zuständen h_t eine Sequenz dieser Darstellungen bei einer vergangenen Aktion a_t−1 voraus. Die Verkettung von h_t und z_t bildet den Modellzustand, aus dem die Belohnung r_t und das Episodenkontinuitätsflag c_t ∈ {0, 1} vorhergesagt werden und die Eingabe rekonstruiert wird, um die Informationsdarstellung sicherzustellen, wie in Gleichung (3) unten gezeigt. Abbildung 5 unten visualisiert die langfristige Videovorhersage der Weltwelt. Der Encoder und Decoder verwenden ein Convolutional Neural Network (CNN) für visuelle Eingaben und ein Multilayer Perceptron (MLP) für niedrigdimensionale Eingaben. Dynamische, Belohnungs- und Persistenzprädiktoren sind ebenfalls MLPs, und diese Darstellungen werden aus Vektoren von Softmax-Verteilungen abgetastet. DeepMind verwendet im Sampling-Schritt Pass-Through-Gradienten. Actor Critic Learning Actor Critic Neuronale Netzwerke lernen Verhalten vollständig aus abstrakten Sequenzen, die von einem Weltmodell vorhergesagt werden. Bei Interaktionen mit der Umgebung wählt DeepMind Aktionen durch Stichproben aus dem Akteursnetzwerk aus, ohne dass eine Vorausplanung erforderlich ist. Schauspieler und Kritiker agieren im Modellzustand Ausgehend von einer Darstellung der wiedergegebenen Eingabe erzeugen dynamische Prädiktoren und Akteure eine Folge erwarteter Modellzustände s_1:T, Aktionen a_1:T, Belohnungen r_1:T und Fortsetzungsflags c_1:T. Um Renditen für Belohnungen außerhalb des vorhergesagten Horizonts abzuschätzen, berechnet DeepMind Bootstrapped-λ-Renditen, die erwartete Renditen und Wert integrieren. DeepMind führte eine umfangreiche empirische Studie durch, um die Allgemeingültigkeit und Skalierbarkeit von DreamerV3 über verschiedene Domänen (mehr als 150 Aufgaben) unter festen Hyperparametern zu bewerten und mit vorhandenen SOTA-Methoden in der Literatur zu vergleichen. DreamerV3 wurde auch auf das anspruchsvolle Videospiel Minecraft angewendet. Für DreamerV3 vereinfacht DeepMind die Einrichtung, indem es die Leistung stochastischer Trainingsstrategien direkt meldet und separate Bewertungsläufe mit deterministischen Strategien vermeidet. Alle DreamerV3-Agenten werden auf einer Nvidia V100-GPU geschult. Tabelle 1 unten gibt einen Überblick über die Benchmarks. Um die Allgemeingültigkeit von DreamerV3 zu bewerten, führte DeepMind umfangreiche empirische Auswertungen in sieben Bereichen durch, darunter kontinuierliche und diskrete Aktionen, visuelle und niedrigdimensionale Eingaben, dichte und spärliche Belohnungen, verschiedene Belohnungsskalen, 2D- und 3D-Welt und prozedurale Generierung. Die Ergebnisse in Abbildung 1 unten zeigen, dass DreamerV3 in allen Bereichen eine starke Leistung erzielt und in vier davon alle vorherigen Algorithmen übertrifft, während in allen Benchmarks feste Hyperparameter verwendet werden. Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier. 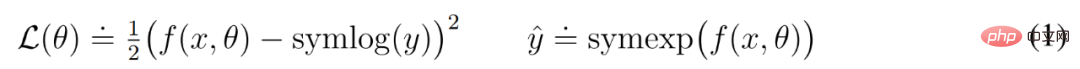

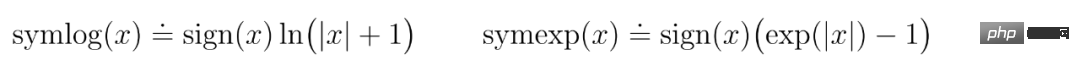
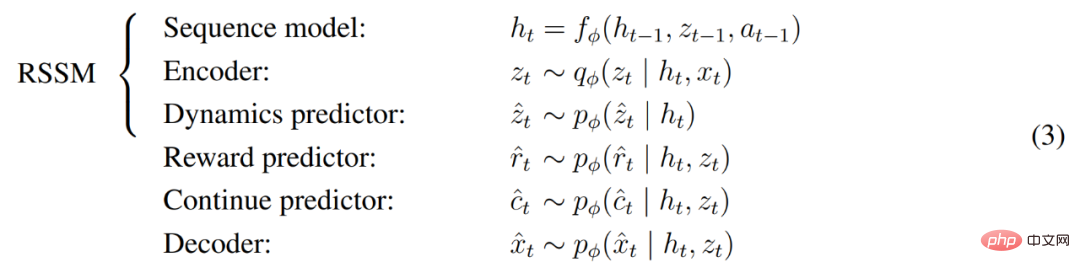
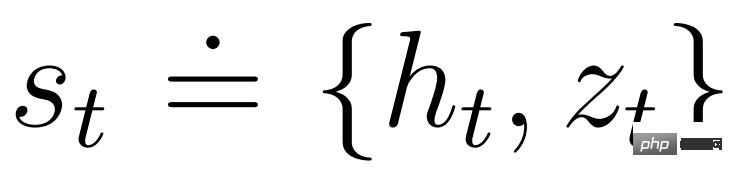 und können von der vom Weltmodell erlernten Markov-Darstellung profitieren. Das Ziel des Akteurs besteht darin, die erwartete Rendite
und können von der vom Weltmodell erlernten Markov-Darstellung profitieren. Das Ziel des Akteurs besteht darin, die erwartete Rendite 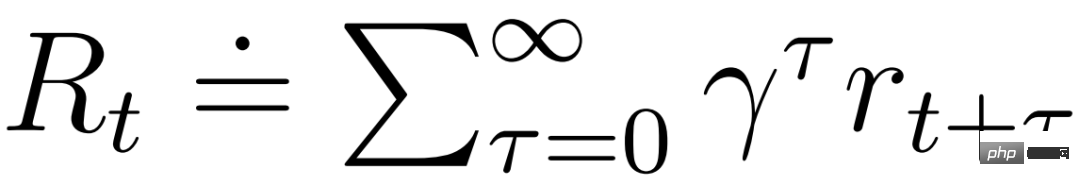 bei einem Abzinsungsfaktor γ = 0,997 für jeden Modellzustand zu maximieren. Um Belohnungen außerhalb des Vorhersagebereichs T = 16 zu berücksichtigen, lernt der Kritiker, die Belohnung für jeden Zustand anhand des aktuellen Akteurverhaltens vorherzusagen.
bei einem Abzinsungsfaktor γ = 0,997 für jeden Modellzustand zu maximieren. Um Belohnungen außerhalb des Vorhersagebereichs T = 16 zu berücksichtigen, lernt der Kritiker, die Belohnung für jeden Zustand anhand des aktuellen Akteurverhaltens vorherzusagen. 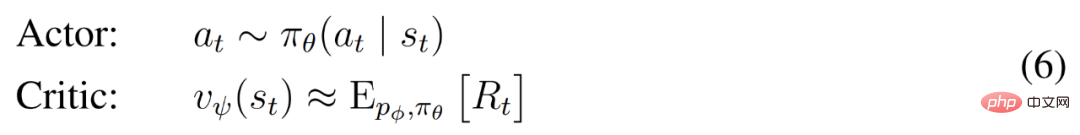
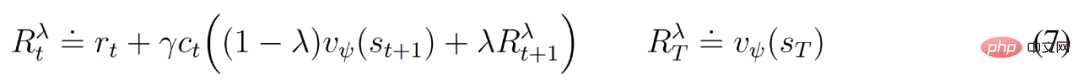
Experimentelle Ergebnisse
Das obige ist der detaillierte Inhalt vonDie KI hat das Spielen von „Minecraft' von Grund auf gelernt, DeepMind AI hat einen Durchbruch bei der Verallgemeinerung geschafft. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1206
24
52
1206
24

 Web3 Trading Platform Ranking_Web3 Globale Top Ten Summary Top Ten Summary
Apr 21, 2025 am 10:45 AM
Web3 Trading Platform Ranking_Web3 Globale Top Ten Summary Top Ten Summary
Apr 21, 2025 am 10:45 AM
Binance ist der Overlord des Global Digital Asset Trading -Ökosystems, und seine Merkmale umfassen: 1. Das durchschnittliche tägliche Handelsvolumen übersteigt 150 Milliarden US -Dollar, unterstützt 500 Handelspaare, die 98% der Mainstream -Währungen abdecken. 2. Die Innovationsmatrix deckt den Markt für Derivate, das Web3 -Layout und den Bildungssystem ab; 3. Die technischen Vorteile sind Millisekunden -Matching -Engines mit Spitzenvolumina von 1,4 Millionen Transaktionen pro Sekunde. 4. Compliance Progress hält 15 Länderlizenzen und legt konforme Einheiten in Europa und den Vereinigten Staaten ein.
 Top 10 Cryptocurrency Exchange -Plattformen Die weltweit größte Liste der digitalen Währung
Apr 21, 2025 pm 07:15 PM
Top 10 Cryptocurrency Exchange -Plattformen Die weltweit größte Liste der digitalen Währung
Apr 21, 2025 pm 07:15 PM
Börsen spielen eine wichtige Rolle auf dem heutigen Kryptowährungsmarkt. Sie sind nicht nur Plattformen, an denen Investoren handeln, sondern auch wichtige Quellen für Marktliquidität und Preisentdeckung. Der weltweit größte virtuelle Währungsbörsen gehören zu den Top Ten, und diese Börsen sind nicht nur im Handelsvolumen weit voraus, sondern haben auch ihre eigenen Vorteile in Bezug auf Benutzererfahrung, Sicherheit und innovative Dienste. Börsen, die über die Liste stehen, haben normalerweise eine große Benutzerbasis und einen umfangreichen Markteinfluss, und deren Handelsvolumen und Vermögenstypen sind häufig mit anderen Börsen schwer zu erreichen.
 Wie man Verluste nach dem ETH -Upgrade vermeidet
Apr 21, 2025 am 10:03 AM
Wie man Verluste nach dem ETH -Upgrade vermeidet
Apr 21, 2025 am 10:03 AM
Nach dem ETH -Upgrade sollten Anfänger die folgenden Strategien anwenden, um Verluste zu vermeiden: 1. Machen Sie ihre Hausaufgaben und verstehen Sie das Grundwissen und aktualisieren Sie Inhalte von ETH; 2. Kontrollpositionen, testen Sie die Gewässer in kleinen Mengen und diversifizieren Investitionen; 3. Machen Sie einen Handelsplan, klären Sie die Ziele und setzen Sie Stop -Loss -Punkte. 4. Profile rational und vermeiden emotionale Entscheidungen; 5. Wählen Sie eine formelle und zuverlässige Handelsplattform; 6. Betrachten Sie die langfristige Beteiligung, um die Auswirkungen kurzfristiger Schwankungen zu vermeiden.
 Was bedeutet Cross-Chain-Transaktion? Was sind die Cross-Chain-Transaktionen?
Apr 21, 2025 pm 11:39 PM
Was bedeutet Cross-Chain-Transaktion? Was sind die Cross-Chain-Transaktionen?
Apr 21, 2025 pm 11:39 PM
Börsen, die Cross-Chain-Transaktionen unterstützen: 1. Binance, 2. Uniswap, 3. Sushiswap, 4. Kurvenfinanzierung, 5. Thorchain, 6. 1inch Exchange, 7. DLN-Handel, diese Plattformen unterstützen Multi-Chain-Asset-Transaktionen durch verschiedene Technologien.
 Was sind die zehn besten Plattformen im Währungsaustauschkreis?
Apr 21, 2025 pm 12:21 PM
Was sind die zehn besten Plattformen im Währungsaustauschkreis?
Apr 21, 2025 pm 12:21 PM
Zu den Top -Börsen gehören: 1. Binance, das weltweit größte Handelsvolumen, unterstützt 600 Währungen und die Spot -Handhabungsgebühr beträgt 0,1%. 2. OKX, eine ausgewogene Plattform, unterstützt 708 Handelspaare, und die dauerhafte Vertragsabwicklungsgebühr beträgt 0,05%. 3. Gate.io deckt 2700 kleine Währungen ab, und die Gebühr für die Spot-Handhabung beträgt 0,1%-0,3%; 4. Coinbase, der US -Konformitäts -Benchmark, die Spot -Handhabungsgebühr beträgt 0,5%; 5. Kraken, die Top -Sicherheit und regelmäßige Reserveprüfung.
 Warum ist der Anstieg oder Abfall der virtuellen Währungspreise? Warum ist der Anstieg oder Abfall der virtuellen Währungspreise?
Apr 21, 2025 am 08:57 AM
Warum ist der Anstieg oder Abfall der virtuellen Währungspreise? Warum ist der Anstieg oder Abfall der virtuellen Währungspreise?
Apr 21, 2025 am 08:57 AM
Faktoren der steigenden Preise für virtuelle Währung sind: 1. Erhöhte Marktnachfrage, 2. Verringertes Angebot, 3.. Rückgangsfaktoren umfassen: 1. Verringerte Marktnachfrage, 2. Erhöhtes Angebot, 3. Streik der negativen Nachrichten, 4. Pessimistische Marktstimmung, 5. makroökonomisches Umfeld.
 Worldcoin (WLD) Preisprognose 2025-2031: Wird WLD bis 2031 $ erreichen?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) Preisprognose 2025-2031: Wird WLD bis 2031 $ erreichen?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) fällt auf dem Kryptowährungsmarkt mit seinen einzigartigen biometrischen Überprüfungs- und Datenschutzschutzmechanismen auf, die die Aufmerksamkeit vieler Investoren auf sich ziehen. WLD hat mit seinen innovativen Technologien, insbesondere in Kombination mit OpenAI -Technologie für künstliche Intelligenz, außerdem unter Altcoins gespielt. Aber wie werden sich die digitalen Vermögenswerte in den nächsten Jahren verhalten? Lassen Sie uns den zukünftigen Preis von WLD zusammen vorhersagen. Die Preisprognose von 2025 WLD wird voraussichtlich im Jahr 2025 ein signifikantes Wachstum in WLD erzielen. Die Marktanalyse zeigt, dass der durchschnittliche WLD -Preis 1,31 USD mit maximal 1,36 USD erreichen kann. In einem Bärenmarkt kann der Preis jedoch auf rund 0,55 US -Dollar fallen. Diese Wachstumserwartung ist hauptsächlich auf Worldcoin2 zurückzuführen.
 'Black Monday Sell' ist ein schwieriger Tag für die Kryptowährungsbranche
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' ist ein schwieriger Tag für die Kryptowährungsbranche
Apr 21, 2025 pm 02:48 PM
Der Sprung in den Kryptowährungsmarkt hat bei den Anlegern Panik verursacht, und Dogecoin (DOGE) ist zu einem der am stärksten getroffenen Bereiche geworden. Der Preis fiel stark, und die Gesamtwertsperrung der dezentralen Finanzierung (DEFI) (TVL) verzeichnete ebenfalls einen signifikanten Rückgang. Die Verkaufswelle von "Black Monday" fegte den Kryptowährungsmarkt, und Dogecoin war der erste, der getroffen wurde. Die Defitvl fiel auf 2023 und der Währungspreis fiel im vergangenen Monat um 23,78%. Die Defitvl von Dotecoin fiel auf ein Tiefpunkt von 2,72 Millionen US -Dollar, hauptsächlich aufgrund eines Rückgangs des SOSO -Wertindex um 26,37%. Andere große Defi -Plattformen wie die langweilige DAO und Thorchain, TVL, fielen ebenfalls um 24,04% bzw. 20.
