


Hallo zusammen, ich bin ein Neuling!
Bei den Daten handelt es sich um online gefundene Verkaufsdaten. Sie sehen so aus:
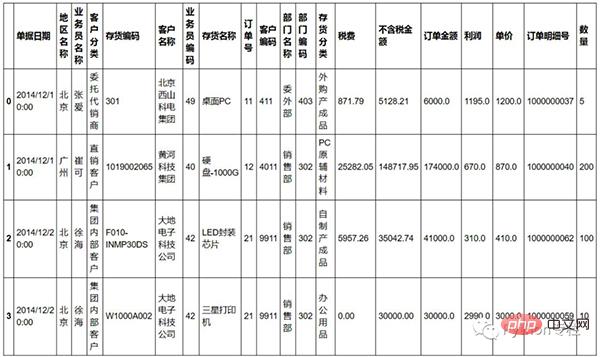
Vlookup ist fast die am häufigsten verwendete Formel in Excel und wird im Allgemeinen für verwandte Abfragen zwischen zwei verwendet Tische. Deshalb habe ich diese Tabelle zunächst in zwei Tabellen unterteilt.
df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号', '客户编码', '部门名称', '部门编码']] df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]
Nachfrage: Ich möchte den Gewinn wissen, der jeder Bestellung von df1 entspricht.
Die Gewinnspalte existiert in der Tabelle von df2, daher möchte ich den Gewinn wissen, der jeder Bestellung von df1 entspricht. Wenn Sie Excel verwenden, bestätigen Sie zunächst, dass die Bestelldetailnummer ein eindeutiger Wert ist, fügen Sie dann eine neue Spalte in df1 hinzu und schreiben Sie: =vlookup(a2,df2!a:h,6,0) und ziehen Sie sie dann nach unten sei in Ordnung. (Für die restlichen 13 werde ich kein Excel schreiben)
Wie implementiert man es mit Python?
#查看订单明细号是否重复,结果是没。 df1["订单明细号"].duplicated().value_counts() df2["订单明细号"].duplicated().value_counts() df_c=pd.merge(df1,df2,on="订单明细号",how="left")
Anforderung: Ich möchte den Gesamtgewinn und den durchschnittlichen Gewinn erfahren, den Verkäufer in jeder Region erzielen.
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])
Da die Datendimensionen jeder Spalte in dieser Tabelle unterschiedlich sind, ist ein Vergleich sinnlos, daher habe ich zuerst einen Unterschied in den Bestelldetails gemacht und dann verglichen.
Anforderung: Differenz zwischen Bestelldetailnummer und Bestelldetailnummer 2 vergleichen und anzeigen.
sale["订单明细号2"]=sale["订单明细号"] #在订单明细号2里前10个都+1. sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1 #差异输出 result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]
Anforderungen: Vom Verkäufer codierte doppelte Werte entfernen
sale.drop_duplicates("业务员编码",inplace=True)Überprüfen Sie zunächst, welche Spalten der Verkaufsdaten fehlende Werte aufweisen.
#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值 sale.info()

Anforderung: Fehlende Werte mit 0 füllen oder Zeilen mit kundencodierten fehlenden Werten löschen. Tatsächlich ist die Methode zur Verarbeitung fehlender Werte sehr kompliziert. Hier stellen wir nur einfache Verarbeitungsmethoden vor. Die am häufigsten verwendete Methode ist der Durchschnitt, der Median oder der Modus Das Gesamtstrukturmodell kann zur Vorhersage basierend auf anderen Dimensionen verwendet werden. Wenn es sich um eine kategoriale Variable handelt, ist es genauer, sie basierend auf der Geschäftslogik auszufüllen. Hier besteht die Anforderung beispielsweise darin, den fehlenden Wert des Kundennamens auszufüllen: Er kann entsprechend dem Kundennamen ausgefüllt werden, der dem Inventar mit der höchsten Häufigkeit des Vorkommens in der Inventarklassifizierung entspricht.
Hier verwenden wir eine einfache Lösung: Füllen Sie die fehlenden Werte mit 0 oder löschen Sie die vom Kunden codierten Zeilen mit fehlenden Werten.
#用0填充缺失值 sale["客户名称"]=sale["客户名称"].fillna(0) #删除有客户编码缺失值的行 sale.dropna(subset=["客户编码"])
Nachfrage: Ich möchte Informationen über den Verkäufer Zhang Ai wissen, der Waren im Raum Peking mit einem Bestellwert von mehr als 6.000 verkauft.
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]
Anforderungen: Informationen filtern, deren Inventarname „Samsung“ oder „Sony“ enthält.
sale.loc[sale["存货名称"].str.contains("三星|索尼")]Anforderungen: Der Gesamtgewinn jedes Verkäufers im Raum Peking.
sale.groupby(["地区名称","业务员名称"])["利润"].sum()
Nachfrage: Wie viele Bestellungen haben „Samsung“ im Inventarnamen und die Steuer ist höher als 1.000? Wie hoch ist die Summe und der durchschnittliche Gewinn dieser Aufträge? (Oder Minimalwert, Maximalwert, Quartil, Labeldifferenz)
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()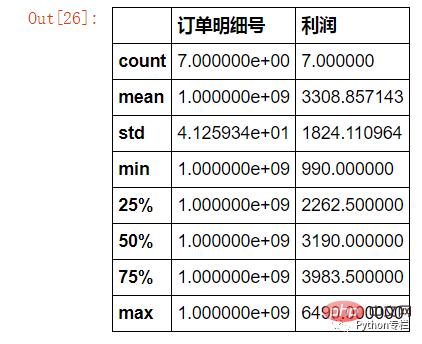
Anforderung: Löschen Sie die Leerzeichen auf beiden Seiten des Inventarnamens.
sale["Inventory Name"].map(lambda s:s.strip(""))
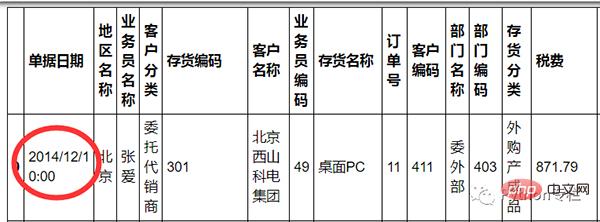
Anforderung: Datum und Uhrzeit sortieren.
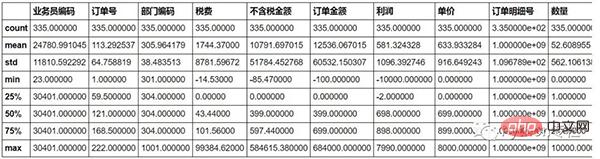
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True)Verwenden Sie zunächst die Funktion „beschreiben()“, um einfach zu überprüfen, ob es Ausreißer in den Daten gibt.
#Sie können sehen, dass die Ausgangssteuer eine negative Zahl hat. Dies ist im Allgemeinen nicht der Fall und wird als Ausreißer angesehen.
sale.describe()
Anforderung: Ausreißer durch 0 ersetzen.
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)
Anforderung: Gruppieren Sie die Regionen nach der Gewinndatenverteilung: „Schlecht“, „Mittel“, „Besser“, „Sehr gut“
Überprüfen Sie zunächst natürlich die Gewinn Datenverteilung, hier verwenden wir Quartile zur Beurteilung.
sale.groupby("地区名称")["利润"].sum().describe()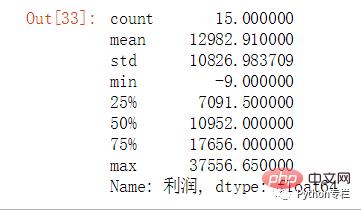
Gemäß dem Quartil wird der regionale Gesamtgewinn in den Bereich [-9,7091] als „schlecht“ und der Bereich (7091,10952) in den Bereich „mittel“ (10952,17656) eingeteilt ] Gruppierung ist besser, (17656,37556] wird als sehr gut gruppiert.
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]
#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups)Anforderungen: Produktinformationen mit einer Umsatzgewinnspanne (d. h. Gewinn/Bestellbetrag) größer als 30 % und Markieren Sie es als: Bei qualitativ hochwertigen Produkten handelt es sich um allgemeine Produkte.
sale.loc[(sale["利润"]/sale["订单金额"])>0.3,"label"]="优质商品" sale.loc[(sale["利润"]/sale["订单金额"])<0.05,"label"]="一般商品"
Tatsächlich habe ich 14 davon aufgelistet, die ich häufig verwende , Sie können sie gemeinsam kommentieren und diskutieren. Außerdem weiß ich, dass mein Schreiben in Python nicht prägnant genug ist (tatsächlich wird die Abfrage prägnanter sein, wenn Sie eine bessere Möglichkeit zum Schreiben haben). Bitte teilen Sie mir diese Vorgänge in den Kommentaren mit. Vielen Dank!
Abschließend möchte ich sagen, dass es meiner Meinung nach am besten ist, Excel und Python nicht zu vergleichen, um zu untersuchen, welches einfacher zu verwenden ist. Tatsächlich sind beide Tools das am weitesten verbreitete Datenverarbeitungstool So viele Jahre und in Bezug auf die Benutzerfreundlichkeit der Datenverarbeitung müssen einige Vorgänge in Python tatsächlich einfacher sein, aber es gibt auch viele Vorgänge in Excel, die einfacher als Python sind.
Zum Beispiel eine sehr einfache Operation: Summieren Sie jede Spalte und zeigen Sie sie in der unteren Zeile an. Excel fügt jeder Spalte einfach eine sum()-Funktion hinzu und zieht sie dann nach links, um sie zu lösen, während Python sie definieren muss eine Funktion (Da Python das Format bestimmen muss, meldet es direkt einen Fehler, wenn es sich nicht um einen numerischen Wert handelt)
.Das obige ist der detaillierte Inhalt von14 gängige Operationen in Excel mit Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Python-Entwicklungstools
Python-Entwicklungstools
 Python in ausführbare Datei gepackt
Python in ausführbare Datei gepackt
 was Python kann
was Python kann
 Vergleichen Sie die Ähnlichkeiten und Unterschiede zwischen zwei Datenspalten in Excel
Vergleichen Sie die Ähnlichkeiten und Unterschiede zwischen zwei Datenspalten in Excel
 Excel-Duplikatfilter-Farbmarkierung
Excel-Duplikatfilter-Farbmarkierung
 So verwenden Sie das Format in Python
So verwenden Sie das Format in Python
 So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
 Excel-Tabellen-Schrägstrich in zwei Teile geteilt
Excel-Tabellen-Schrägstrich in zwei Teile geteilt








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



