

Quantitativer Handel (auch automatisierter Handel genannt) ist eine Anlagemethode, die mathematische Modelle anwendet, um Anlegern dabei zu helfen, auf der Grundlage von Anweisungen, die von Computerprogrammen gesendet werden, Entscheidungen zu treffen und Transaktionen durchzuführen. Dadurch werden die Auswirkungen emotionaler Schwankungen der Anleger erheblich reduziert. Die Hauptvorteile des quantitativen Handels sind:
Der Kern des quantitativen Handels besteht darin, Strategien zu überprüfen, die auf mathematischen oder physikalischen Modellen basieren und die mathematische Sprache umwandeln Computersprache. Der Prozess des quantitativen Handels reicht von der Datenerfassung bis zur Datenanalyse und -verarbeitung.
Der erste Schritt bei der Datenanalyse besteht darin, Daten zu erhalten, also Daten zu sammeln. Es gibt viele Möglichkeiten, Daten zu erhalten. Generell werden Datenquellen hauptsächlich in zwei Kategorien unterteilt: externe Quellen (externe Einkäufe, Web-Crawling, kostenlose Open-Source-Daten usw.) und interne Quellen (eigene Unternehmensverkaufsdaten, Finanzdaten usw.). .).
Da wir keine Daten produzieren, können wir nur Daten von außen bekommen. Die Zugriffsmethode ist die Open-Source-Bibliothek tushare eines Drittanbieters.
Verwenden Sie tushare, um historische Bestandsdaten zu erhalten
tushare ist ein kostenloses Open-Source-Python-Finanzdatenschnittstellenpaket. Es implementiert hauptsächlich den Prozess der Datenerfassung, Bereinigung, Verarbeitung und Datenspeicherung von Finanzdaten wie Beständen und kann Finanzanalysten schnelle, saubere und vielfältige Daten liefern, die leicht zu analysieren sind, um so ihren Arbeitsaufwand bei der Datenerfassung zu reduzieren.
Installieren Sie die Tushare-Bibliothek, geben Sie den folgenden Befehl unter Jupter Notebook ein:
%pip install tushare
Starten Sie den Kernel neu und geben Sie dann den folgenden Befehl ein.
import tushare
print("tushare版本号{}".format(tushare.__version__))tushare版本号1.2.85
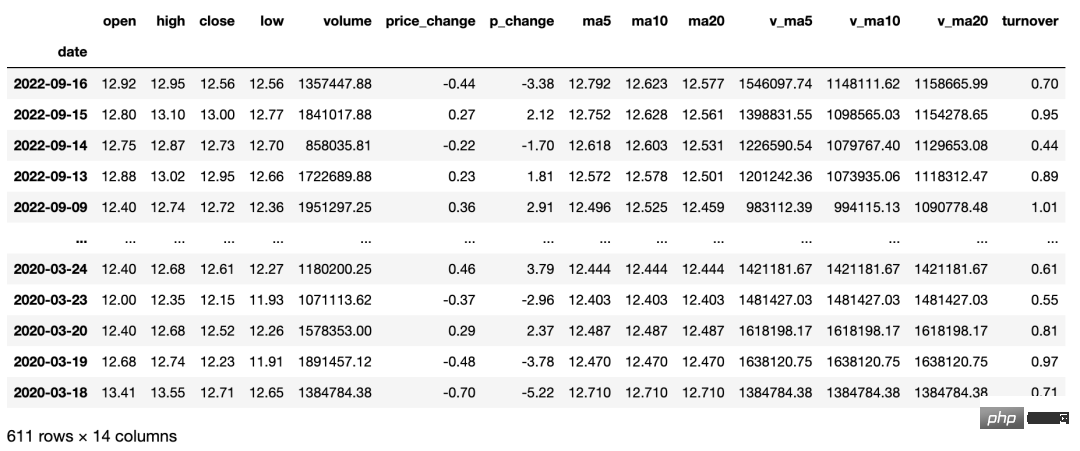
Erhalten Sie historische Transaktionsdaten einzelner Aktien (einschließlich gleitender Durchschnittsdaten). Benutzer können tägliche K-Linie, wöchentliche K-Linie, monatliche K-Linie sowie 5-Minuten-, 15-Minuten-, 30-Minuten-Daten erhalten 60-minütige K-Linien-Daten über Parametereinstellungen. Diese Schnittstelle kann nur tägliche Daten der letzten drei Jahre abrufen und eignet sich für die Aktienauswahl und -analyse in Verbindung mit gleitenden Durchschnittsdaten. Der Python-Code lautet wie folgt:
importtushareasts
ts.get_hist_data('000001') #一次性获取全部日k线数据
'''
参数说明:
code:股票代码,即6位数字代码,或者指数代码(sh=上证指数 sz=深圳成指 hs300=沪深300指数 sz50=上证50 zxb=中小板 cyb=创业板)
start:开始日期,格式YYYY-MM-DD
end:结束日期,格式YYYY-MM-DD
ktype:数据类型,D=日k线 W=周 M=月 5=5分钟 15=15分钟 30=30分钟 60=60分钟,默认为D
retry_count:当网络异常后重试次数,默认为3
pause:重试时停顿秒数,默认为0
例如:
ts.get_hist_data('000001', ktype='W') #获取周k线数据
ts.get_hist_data('000001', ktype='M') #获取月k线数据
ts.get_hist_data('000001', ktype='5') #获取5分钟k线数据
ts.get_hist_data('000001', ktype='15') #获取15分钟k线数据
ts.get_hist_data('000001', ktype='30') #获取30分钟k线数据
ts.get_hist_data('000001', ktype='60') #获取60分钟k线数据
ts.get_hist_data('sh')#获取上证指数k线数据
ts.get_hist_data('sz')#获取深圳成指k线数据
ts.get_hist_data('hs300')#获取沪深300指数k线数据
ts.get_hist_data('000001',start='2021-01-01',end='2021-03-20') #获取”000001”从2021-01-01到2021-03-20的k线数据
'''
Der Rückgabewert wird wie folgt erklärt.
importtushareasts ts.get_today_all()
Datenvorverarbeitung
Ob es sich um eine quantitative Strategie oder ein einfaches maschinelles Lernprojekt handelt, die Datenvorverarbeitung ist ein sehr wichtiger Teil. Aus der Perspektive des quantitativen Lernens umfasst die Datenvorverarbeitung hauptsächlich Datenbereinigung, Sortierung, Verarbeitung fehlender Werte oder Ausreißer, statistische Analysen, Korrelationsanalysen und Hauptkomponentenanalysen (PCA) usw. Da in den vorherigen Büchern reguläre Bestandsdaten erfasst wurden, besteht die in diesem Kapitel eingeführte Datenvorverarbeitung darin, die Bestandsdaten, die die Bedingungen nicht erfüllen, im Voraus zu eliminieren und dann die verbleibenden Bestände zu optimieren und zu überprüfen. In diesem Kapitel wird hauptsächlich die Pandas-Bibliothek verwendet, und die Leser sollten sich auf das Verständnis der Filterideen konzentrieren.Clear ST-Aktien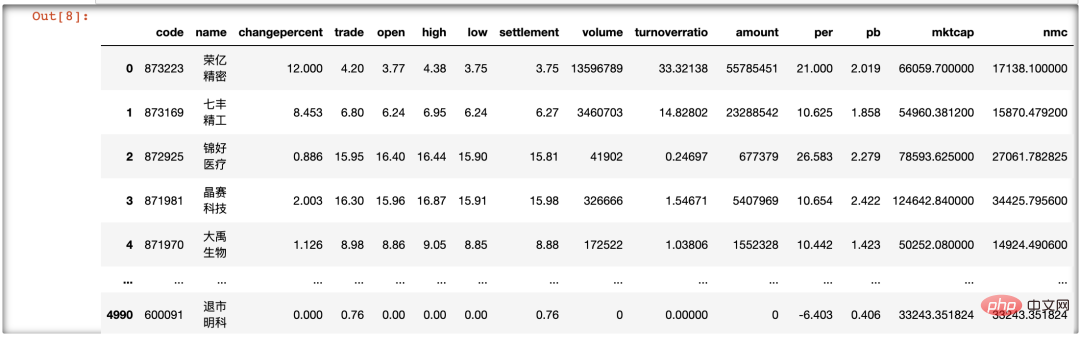
ST-Aktien weisen normalerweise darauf hin, dass Aktien börsennotierter Unternehmen mit anormalen Finanzbedingungen oder anderen Bedingungen eine Sonderbehandlung (Sonderbehandlung) für ihre Transaktionen erfordern. Aufgrund der „Sonderbehandlung“ wird der Abkürzung „ST“ vorangestellt, daher werden diese Bestände ST-Bestände genannt.
Wir möchten diese Art von „Landminenbeständen“ (ST-Beständen) vermeiden, daher können wir den folgenden Code verwenden, um ST-Bestände zu bereinigen.
import tushareasts
csv_data=ts.get_today_all()
csv_data[~csv_data.name.str.contains('ST')]我们对 csv_data 的 name 列进行操作,筛选出包含 ST 字母的行,并对整个 DataFrame 取反,进而筛选出不含 ST 股票的行。经过观察,我们发现在运行结果中没有 ST 股票,实现了数据的初步清洗。
清洗掉没成交量的股票
首先要明确定义,什么是没有成交量的股票。没有成交量不是成交量为零,而是一支股票单位时间的成交量不活跃。成交量是反映股市上人气聚散的一面镜子。人气旺盛、 买卖踊跃,成交量自然放大:相反人气低迷、买卖不活跃,成交量必定萎缩。成交量是观察庄家大户动态的有效途径。
下面开始清洗没成交量的股票,在原来的基础上增加代码如下:
import tushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data[csv_data["volume"]>15000000]#15万手在以上代码中,我们对 csv_data 的 volume 列进行操作。15 万手是过滤掉不活跃、没成交量的股票,主要以小盘股居多。
其运行结果为:

Index 出现了调行现象,即为去掉成交量小手 15 万手的股票。
清洗掉成交额过小的股票
成交额是成交价格与成交数量的乘积,它是指当天已成交股票的金额总数。成交最的至少取决于市场的投资热情。我们每天看大盘,一个重要的指标就是大 A 股成交量是否超过一万亿元,超过即为成交活跃。
筛选成交额超过 1 亿元的股票,代码如下:
import tushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data[(csv_data["amount"]>1)]筛选股票的数量没有锐减,这是因为成交额-成交价格×成交量。有些股票价格低,成交量巨大,乘积刚刚超过 1亿元;有些股票价格高,成交量相对小一些,乘积仍然超过1亿元。同成交额,2元股票相对于 20 元与 200 元股票,其成交量相差10 倍到 100 倍之多。同成交量,有些股票成交额为 100 亿元,相对于成交额仅有 1亿元的股票,也有百倍之多。
用户可以对 1亿元这个参数进行调参,不过笔者不是特别支持。因为将成交额变大即是对大盘股产生偏重,而前面成交量的筛选也己经对大盘股的成交量进行了偏重筛选,这样双重筛选下来,就会全部变成大盘股,数据偏置严重,没有合理性。预处理的思想也是先将数据进行简单的筛选。笔者认为后期的策略相对于这里的调参更为重要,策略是日后交易的核心。
清洗掉换手率低的股票
换手率=某一段时期内的成交量/流通总股数×100% 。一般情况下,大多数股票每日换手率在1%~2.5%之间(不包括初上市的股票)。70%股票的换手率基本在 3%以下,3%就成为一种分界。
当一支股票的换手率在 3%~7%之间时,该股进入相对活跃状态。当换手率在 7%~10%之间时,则为强势股的出现,股价处于高度活跃中。
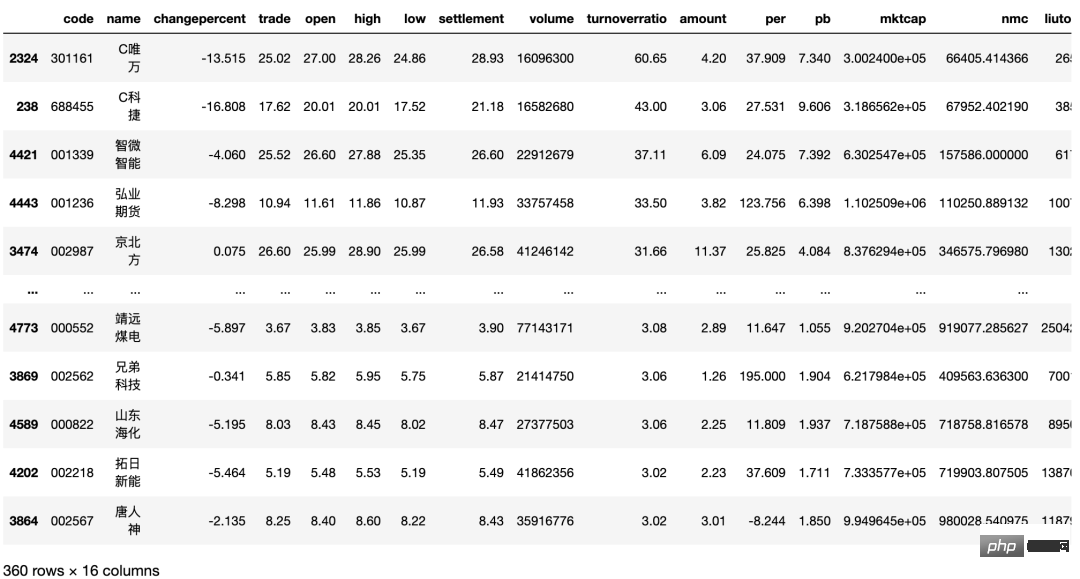
筛选换手率超过3的股票,代码如下:
importtushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data=csv_data[(csv_data["amount"]>1)]
csv_data["liutongliang"]=csv_data["nmc"]/csv_data["trade"]#增加流通盘的列
csv_data["turnoverratio"]=round(csv_data["turnoverratio"],2)#换手率保留2位
csv_data[csv_data["turnoverratio"]>3]筛选股票的数量减半。换手率低于 3%当然也有不错的股票,但是根据正态分布,我们不选取小概率事件。选择换手率较好的股票,意味着该文股票的交投越活跃,人们购买该支股票的意愿越高,该股票属于热门股。
换手率商一般意味股票流通性好,进出市场比较容易,不会出现想买买不到、想卖卖不出的现象,具有我较强的变现能力。然而值得注意的是,换手率较高的股票,往往也是短线资金追逐的对象,投机性较强,股价起伏较大,风险也相对较大。
将换手率降序排列并保存数据
换手率是最重要的一个指标,所以将筛选出来的股票换手率进行降序排列并保存,以备日后取证与研究。
将序排列用 sort_values() 两数,保存用 to_csv() 函数。这两个函数都很常用,也比较简单。代码如下:
import tushare as ts
def today_data():
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data=csv_data[(csv_data["amount"]>1)]
csv_data["liutongliang"]=csv_data["nmc"]/csv_data["trade"]#增加流通盘的列
csv_data["turnoverratio"]=round(csv_data["turnoverratio"],2)#换手率保留2位
csv_data=csv_data[csv_data["turnoverratio"]>3]
csv_data=csv_data.sort_values(by="turnoverratio", ascending=False)
return csv_data经过一系列的数据清洗与筛选,选择出符合要求的股票数据并保存到 Jupter Notebook 中。我们将上述代码进行函数化处理,并命名为 get_data.py。
以后,只要运行如下代码,就会将得到的 csv_data 显示出来:
import get_data get_data.today_data()
模块化后,将去掉大量重复代码,重加专注一个功能,也会增强代码的可读性。
本文摘编自《Python量化交易实战》,经出版方授权发布。(ISBN:9787522602820)
Das obige ist der detaillierte Inhalt vonQuantitative Handelspraxis mit Python: Bestandsdaten abrufen und analysieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



