
 Technologie-Peripheriegeräte
KI
Eine GPU führt das ChatGPT-Volumenmodell aus, und ControlNet ist ein weiteres Artefakt für das KI-Zeichnen.
Technologie-Peripheriegeräte
KI
Eine GPU führt das ChatGPT-Volumenmodell aus, und ControlNet ist ein weiteres Artefakt für das KI-Zeichnen.
Eine GPU führt das ChatGPT-Volumenmodell aus, und ControlNet ist ein weiteres Artefakt für das KI-Zeichnen.

Ein Katalog echte Protonenaustauschmembran-Brennstoffzelle mit Deep Learning
Eine umfassende Umfrage zu vortrainierten Foundation-Modellen: Eine Geschichte von BERT bis ChatGPT
- Hinzufügen bedingter Kontrolle zu Text-zu-Bild-Diffusionsmodellen
- EVA3D: Compositional 3D Menschliche Generation aus 2D-Bildsammlungen
- ArXiv Weekly Radiostation: NLP, CV, ML Weitere ausgewählte Artikel (mit Audio)
- Artikel 1: Transformer-Modelle: eine Einführung und ein Katalog
- Autor: hat gezeigt beispiellose Stärke in anderen Bereichen wie der Verarbeitung natürlicher Sprache und Computer Vision und hat technologische Durchbrüche wie ChatGPT ausgelöst. Menschen haben auch verschiedene Varianten vorgeschlagen, die auf dem ursprünglichen Modell basieren.
- Da Wissenschaft und Industrie weiterhin neue Modelle vorschlagen, die auf dem Aufmerksamkeitsmechanismus von Transformer basieren, fällt es uns manchmal schwer, diese Richtung zusammenzufassen. Kürzlich könnte uns ein ausführlicher Artikel von Xavier Amatriain, Leiter der KI-Produktstrategie bei LinkedIn, bei der Lösung dieses Problems helfen.
Empfehlung: Ziel dieses Artikels ist es, einen relativ umfassenden, aber einfachen Katalog und eine Klassifizierung der beliebtesten Transformer-Modelle bereitzustellen. Außerdem werden die wichtigsten Aspekte und Neuerungen des Transformer-Modells vorgestellt. ?? / FMInference/FlexGen/blob/main/docs/paper.pdf
- Zusammenfassung: Traditionell erforderten die hohen Rechen- und Speicheranforderungen der Large Language Model (LLM)-Inferenz den Einsatz mehrerer High-End-KI Beschleuniger für die Ausbildung. In dieser Studie wird untersucht, wie die Anforderungen der LLM-Inferenz auf eine GPU der Verbraucherklasse reduziert und eine praktische Leistung erzielt werden können. ,
- Kürzlich haben neue Forschungsergebnisse der Stanford University, der UC Berkeley, der ETH Zürich, Yandex, der Moscow State Higher School of Economics, Meta, der Carnegie Mellon University und anderen Institutionen FlexGen vorgeschlagen, eine Methode zum Betrieb einer begrenzten Hochdurchsatzgeneration Engine für LLM im GPU-Speicher. Die folgende Abbildung zeigt die Entwurfsidee von FlexGen, die Blockplanung verwendet, um Gewichte wiederzuverwenden und E/A mit Berechnungen zu überlappen, wie in Abbildung (b) unten dargestellt, während andere Basissysteme eine ineffiziente zeilenweise Planung verwenden, wie z siehe Abbildung (a) unten.
Empfehlung: Führen Sie das ChatGPT-Volumenmodell aus und benötigen Sie von nun an nur noch eine GPU: Hier kommt die Methode zur Beschleunigung um das Hundertfache.
Papier 3: Temporal Domain Generalization with Drift-Aware Dynamic Neural Networks
Papieradresse: https://arxiv.org/pdf/ 2205.106 64 .pdf
Zusammenfassung:
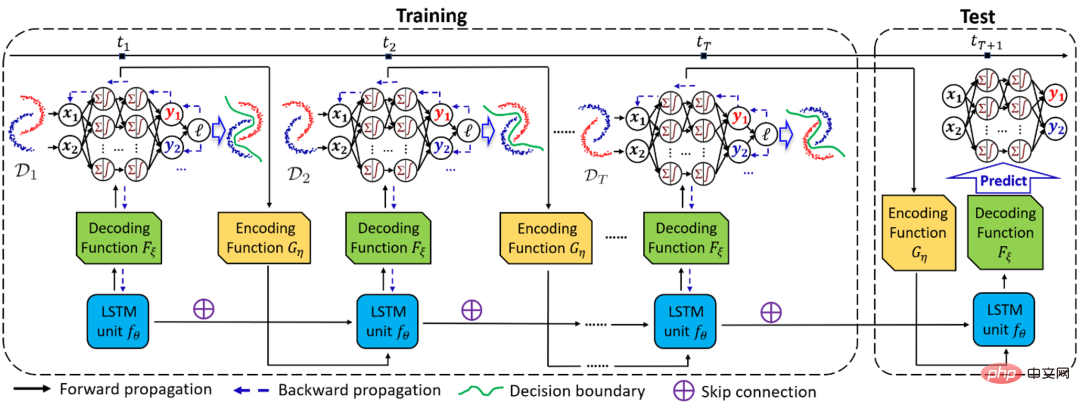
- Wenn sich bei der Domänengeneralisierungsaufgabe (DG) die Verteilung der Domäne kontinuierlich mit der Umgebung ändert, ist es sehr wichtig, die Änderung und ihre Auswirkungen auf das Modell genau zu erfassen . Aber es ist auch ein sehr herausforderndes Problem.
Zu diesem Zweck schlug das Team von Professor Zhao Liang von der Emory University ein Zeitdomänen-Generalisierungsframework DRAIN vor, das auf der Bayes'schen Theorie basiert und rekursive Netzwerke verwendet, um die Drift der Zeitdimensionsdomänenverteilung zu lernen Zeitdynamisch Die Kombination aus neuronalem Netzwerk und Graphgenerierungstechnologie maximiert die Ausdrucksfähigkeit des Modells und erreicht in der Zukunft eine Modellverallgemeinerung und -vorhersage in unbekannten Bereichen.
Diese Arbeit wurde für ICLR 2023 Oral ausgewählt (Top 5 % der akzeptierten Arbeiten). Das Folgende ist ein schematisches Diagramm des Gesamtrahmens von DRAIN. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#empfohlen:#Dynamic Dynamic neuronal Mit Netzwerkunterstützung geht das neue Framework für die Zeitdomänen-Generalisierung weit über Methoden der Domänen-Generalisierung und -Anpassung hinaus.
Aufsatz 4: Physikalisch genaue Modellierung einer echten Protonenaustauschmembran-Brennstoffzelle im großen Maßstab mit Deep Learning
#🎜🎜 #Autor: Ying Da Wang et al : https://www.nature.com/articles/s41467-023-35973-8
Abstract: # 🎜🎜#Um die Energieversorgung sicherzustellen und den Klimawandel zu bekämpfen, hat sich der Fokus der Menschen von fossilen Brennstoffen auf saubere und erneuerbare Energien verlagert, die aufgrund ihrer hohen Energiedichte und sauberen und kohlenstoffarmen Energieeigenschaften eine wichtige Rolle spielen können die Energiewende. Wasserstoffbrennstoffzellen, insbesondere Protonenaustauschmembran-Brennstoffzellen (PEMFC), sind aufgrund ihrer hohen Energieumwandlungseffizienz und ihres emissionsfreien Betriebs von entscheidender Bedeutung für diese grüne Revolution.
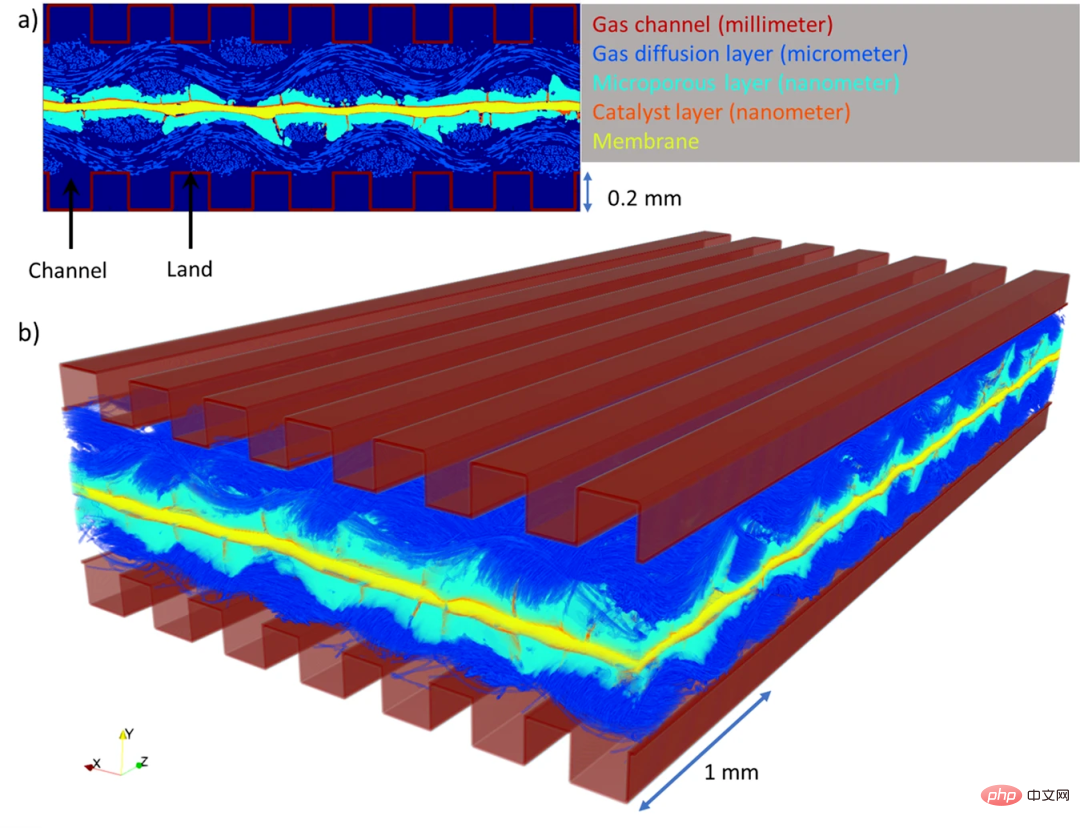
- PEMFC wandelt Wasserstoff durch einen elektrochemischen Prozess in Elektrizität um, wobei das einzige Nebenprodukt der Reaktion reines Wasser ist. Allerdings können PEMFCs ineffizient werden, wenn Wasser nicht richtig aus der Zelle fließen kann und das System anschließend „überflutet“. Bisher war es für Ingenieure schwierig, die genaue Art und Weise zu verstehen, wie Wasser in Brennstoffzellen abfließt oder sich dort ansammelt, da diese so klein und komplex sind.
- Kürzlich hat ein Forschungsteam der University of New South Wales in Sydney einen Deep-Learning-Algorithmus (DualEDSR) entwickelt, um das Verständnis der internen Bedingungen von PEMFC zu verbessern In der Röntgen-Mikrocomputertomographie können aus niedrigeren Auflösungen hochauflösende Modellbilder erzeugt werden. Der Prozess wurde an einer einzelnen Wasserstoff-Brennstoffzelle getestet, wodurch deren Innenraum genau modelliert werden konnte und möglicherweise die Effizienz verbessert wurde. Die folgende Abbildung zeigt die in dieser Studie generierten PEMFC-Domänen.
Empfohlen: Deep Learning vs. Kraftstoff Innerhalb der Batterie wird eine groß angelegte physikalische und genaue Modellierung durchgeführt, um die Batterieleistung zu verbessern.
Papier 5: Eine umfassende Umfrage zu vortrainierten Foundation-Modellen: Eine Geschichte von BERT bis ChatGPT
# 🎜🎜#
Autor: Ce Zhou et al
Papieradresse: https: / /arxiv.org/pdf/2302.09419.pdf
Zusammenfassung: Dieser Artikel ist fast ein Hundert Seiten lang Diese Rezension durchkämmt die Entwicklungsgeschichte des vorab trainierten Basismodells und ermöglicht es uns, zu sehen, wie ChatGPT Schritt für Schritt zum Erfolg kam.
- Empfohlen: Von BERT bis ChatGPT: Ein hundertseitiger Rückblick durchkämmt die Entwicklungsgeschichte vorab trainierter großer Modelle.
- Papier 6: Hinzufügen bedingter Kontrolle zu Text-zu-Bild-Diffusionsmodellen
Autor: Lvmin Zhang et al
Papieradresse: https://arxiv .org/pdf/2302.05543.pdf
Zusammenfassung: Dieses Papier schlägt eine End-to- end neuronal Die Netzwerkarchitektur ControlNet kann das Diffusionsmodell (z. B. Stable Diffusion) durch Hinzufügen zusätzlicher Bedingungen steuern, wodurch der Effekt des Zeichnens und Generierens von Bildern verbessert wird, und kann aus Strichzeichnungen Vollfarbbilder generieren und Bilder mit derselben Tiefenstruktur erzeugen , und die Verwendung von Handtasten für Punkte kann auch die Handgenerierung optimieren und vieles mehr.
-
Empfehlung: KI reduziert die Dimensionalität, um menschliche Maler zu besiegen, führt ControlNet in vinzentinische Diagramme ein und verwendet Tiefen- und Kanteninformationen vollständig wieder.
Aufsatz 7: EVA3D: Compositional 3D Human Generation from 2D image Collections
- Autor: Fangzhou Hong et al
- Aufsatzadresse: https://arxiv.org/abs/ 2210,0 4888
Zusammenfassung: Auf der ICLR 2023 schlug das S-Lab-Team des Nanyang Technological University-SenseTime Joint Research Center die erste Methode EVA3D vor, um die hochauflösende dreidimensionale Erzeugung menschlicher Körper aus einer Sammlung von zwei zu erlernen -dimensionale Bilder. Dank der differenzierbaren Darstellung durch NeRF haben neuere generative 3D-Modelle beeindruckende Ergebnisse auf stationären Objekten erzielt. Allerdings stellt die 3D-Generierung in einer komplexeren und verformbareren Kategorie wie dem menschlichen Körper immer noch große Herausforderungen dar.
Dieses Papier schlägt eine effiziente kombinierte NeRF-Darstellung des menschlichen Körpers vor, die eine hochauflösende (512x256) 3D-Generierung des menschlichen Körpers ohne Verwendung eines hochauflösenden Modells ermöglicht. EVA3D hat bestehende Lösungen bei vier umfangreichen Datensätzen zum menschlichen Körper deutlich übertroffen, und der Code ist Open Source.
Empfohlen: ICLR 2023 Spotlight | 2D-Bild-Brainstorming 3D-menschlicher Körper, Sie können die Kleidung lässig anziehen und auch die Bewegungen ändern.
ArXiv Weekly Radiostation
Heart of Machine kooperiert mit der von Chu Hang, Luo Ruotian und Mei Hongyuan initiierten ArXiv Weekly Radiostation und wählt diese Woche weitere wichtige Papiere auf der Grundlage von 7 Papieren aus, darunter NLP, CV, ML 10 ausgewählte Papiere In jedem Bereich werden abstrakte Einführungen zu den Papieren in Audioform bereitgestellt. Die Details lauten wie folgt:
7 NLP-Papiere
Die 10 ausgewählten NLP-Papiere dieser Woche sind:
1. Aktives Prompting mit Chain-of-Thought für große Sprachmodelle
2 . Erkundung sozialer Medien zur Früherkennung von Depressionen bei COVID-19-Patienten. 5. Federated Nearest Neighbor Machine Translation Begriffe mit Graph Attention. (von Michael Moortgat) 10 ausgewählte CV-Artikel sind:
1. Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes (von Richard Szeliski, Andreas Geiger)
2 Text-zu-Bild-Modelle. (von Daniel Cohen-Or) Simulation von Gesichtsporen. (von Weisi Lin) Leichte Bildverbesserung. (von Chen Change Loy)
7. Regionsbezogene Verbreitung für textgesteuerte Bildbearbeitung ohne Aufnahme. (von Changsheng Xu)
8. Side-Adapter-Netzwerk für die semantische Segmentierung mit offenem Vokabular. (von Xiang Bai)
9. VoxFormer: Sparse Voxel Transformer für die kamerabasierte semantische 3D-Szenenvervollständigung. (von Sanja Fidler)
10. Objektzentrierte Videovorhersage durch Entkopplung von Objektdynamik und Interaktionen. (Von Sven Behnke) normflows: Ein PyTorch-Paket zur Normalisierung von Flüssen. (von Bernhard Schölkopf)
2. Konzeptlernen für interpretierbares Multi-Agent-Reinforcement-Lernen. (von Katia Sycara)3. Zufällige Lehrer sind gute Lehrer. (von Thomas Hofmann)
4. Ausrichten von Text-zu-Bild-Modellen mithilfe von menschlichem Feedback. (von Craig Boutilier, Pieter Abbeel)5. Veränderung ist schwer: Ein genauerer Blick auf die Subpopulationsverschiebung. (von Dina Katabi)
6. AlpaServe: Statistisches Multiplexing mit Modellparallelität für Deep Learning Serving. (von Zhifeng Chen)
7. Vielfältige Richtlinienoptimierung für strukturierten Handlungsraum. (von Hongyuan Zha)
8. Die Geometrie der Mischbarkeit. (von Robert C. Williamson)
9. Lernt Deep Learning zu abstrahieren? Ein systematisches Untersuchungsrahmenwerk. (von Nanning Zheng)
10. Sequentielle kontrafaktische Risikominimierung. (von Julien Mairal)

Das obige ist der detaillierte Inhalt vonEine GPU führt das ChatGPT-Volumenmodell aus, und ControlNet ist ein weiteres Artefakt für das KI-Zeichnen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
