
 Technologie-Peripheriegeräte
KI
Erklären Sie in einfachen Worten das Funktionsprinzip von ChatGPT
Technologie-Peripheriegeräte
KI
Erklären Sie in einfachen Worten das Funktionsprinzip von ChatGPT
Erklären Sie in einfachen Worten das Funktionsprinzip von ChatGPT

ChatGPT ist das neueste von OpenAI veröffentlichte Sprachmodell, das gegenüber seinem Vorgänger GPT-3 deutlich verbessert wurde. Ähnlich wie viele große Sprachmodelle kann ChatGPT Text in unterschiedlichen Stilen und für unterschiedliche Zwecke generieren, mit besserer Leistung in Bezug auf Genauigkeit, narrative Details und kontextbezogene Kohärenz. Es stellt die neueste Generation großer Sprachmodelle von OpenAI dar und wurde mit einem starken Fokus auf Interaktivität entwickelt.
OpenAI verwendet eine Kombination aus überwachtem Lernen und verstärkendem Lernen, um ChatGPT zu optimieren, wobei die Komponente des verstärkenden Lernens ChatGPT einzigartig macht. OpenAI verwendet die Trainingsmethode „Reinforcement Learning with Human Feedback“ (RLHF), die beim Training menschliches Feedback nutzt, um nicht hilfreiche, verzerrte oder voreingenommene Ergebnisse zu minimieren.
In diesem Artikel werden die Einschränkungen von GPT-3 und die Gründe, warum sie sich aus dem Trainingsprozess ergeben, analysiert. Außerdem wird das Prinzip von RLHF erläutert und erläutert, wie ChatGPT RLHF verwendet, um die Probleme von GPT-3 zu überwinden. Es werden die Einschränkungen dieser Methode untersucht.
Fähigkeit vs. Konsistenz in großen Sprachmodellen
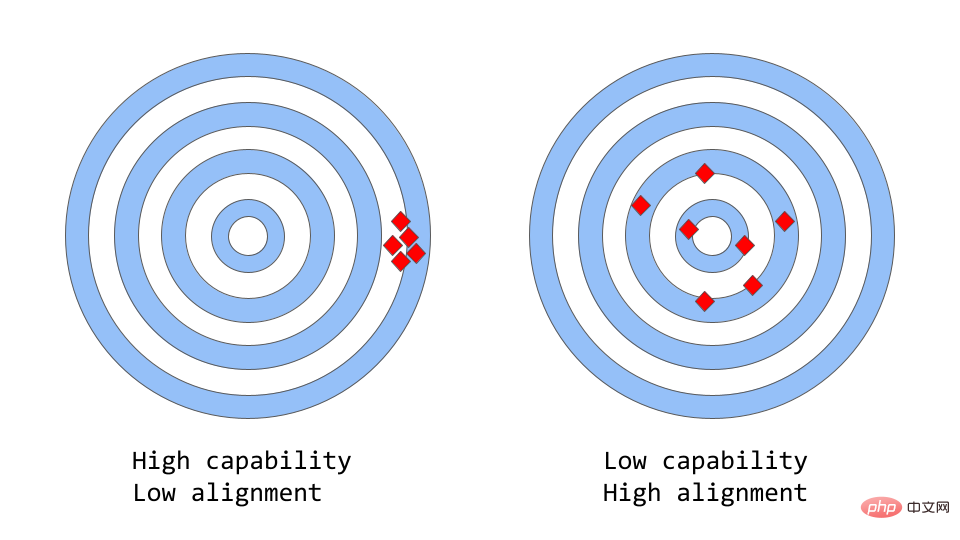
„Konsistenz vs. Fähigkeit“ kann als eine abstraktere Analogie von „Genauigkeit vs. Präzision“ betrachtet werden.
Beim maschinellen Lernen bezieht sich die Fähigkeit eines Modells auf die Fähigkeit des Modells, eine bestimmte Aufgabe oder einen Satz von Aufgaben auszuführen. Die Leistungsfähigkeit eines Modells wird üblicherweise danach beurteilt, inwieweit es in der Lage ist, seine Zielfunktion zu optimieren. Beispielsweise könnte ein Modell zur Vorhersage von Marktpreisen eine objektive Funktion haben, die die Genauigkeit der Vorhersagen des Modells misst. Einem Modell wird dann eine hohe Leistungsfähigkeit zugeschrieben, wenn es Änderungen der Tarife im Laufe der Zeit genau vorhersagen kann.
Konsistenz konzentriert sich darauf, was das Modell tatsächlich tun soll, und nicht darauf, wofür es trainiert wurde. Die Frage, die es aufwirft, lautet: „Ob die Zielfunktion den Erwartungen entspricht“, basierend auf dem Ausmaß, in dem die Ziele und Verhaltensweisen des Modells den menschlichen Erwartungen entsprechen. Angenommen, Sie möchten einen Vogelklassifizierer trainieren, um Vögel als „Spatzen“ oder „Rotkehlchen“ zu klassifizieren, und dabei den logarithmischen Verlust als Trainingsziel verwenden. Das ultimative Ziel ist eine sehr hohe Klassifizierungsgenauigkeit. Das Modell weist möglicherweise einen geringen Protokollverlust auf, d. h. das Modell ist leistungsfähiger, aber weniger genau im Testsatz. Dies ist ein Beispiel für Inkonsistenz, bei der das Modell das Trainingsziel optimieren kann, aber nicht mit dem Endziel übereinstimmt.
Der ursprüngliche GPT-3 ist ein uneinheitliches Modell. Große Sprachmodelle wie GPT-3 werden auf großen Mengen an Textdaten aus dem Internet trainiert und sind in der Lage, menschenähnlichen Text zu generieren, aber sie erzeugen möglicherweise nicht immer eine Ausgabe, die den menschlichen Erwartungen entspricht. Tatsächlich ist ihre Zielfunktion eine Wahrscheinlichkeitsverteilung über eine Folge von Wörtern, die dazu dient, vorherzusagen, wie das nächste Wort in der Folge aussehen wird.
Aber in realen Anwendungen besteht der Zweck dieser Modelle darin, irgendeine Form wertvoller kognitiver Arbeit zu leisten, und es gibt einen klaren Unterschied zwischen der Art und Weise, wie diese Modelle trainiert werden, und der erwarteten Verwendung. Obwohl Maschinen, die statistische Verteilungen von Wortsequenzen berechnen, mathematisch gesehen eine effiziente Wahl für die Modellierung von Sprache sein können, erzeugen Menschen Sprache, indem sie die Textsequenzen auswählen, die am besten zu einer bestimmten Situation passen, und dabei auf bekanntes Hintergrundwissen und gesunden Menschenverstand zurückgreifen. Dies kann ein Problem sein, wenn Sprachmodelle in Anwendungen verwendet werden, die ein hohes Maß an Vertrauen oder Zuverlässigkeit erfordern, wie etwa Konversationssysteme oder intelligente persönliche Assistenten.
Während diese großen Modelle, die auf riesigen Datenmengen trainiert wurden, in den letzten Jahren extrem leistungsfähig geworden sind, bleiben sie in der Praxis oft hinter ihrem Potenzial zurück, um das Leben der Menschen zu erleichtern. Konsistenzprobleme in großen Sprachmodellen äußern sich oft wie folgt:
- Ineffektive Hilfestellung: Nichtbeachtung expliziter Anweisungen des Benutzers.
- Der Inhalt ist erfunden: ein Modell, das nicht existierende oder falsche Tatsachen erfindet.
- Mangelnde Erklärbarkeit: Für Menschen ist es schwierig zu verstehen, wie das Modell zu einer bestimmten Entscheidung oder Vorhersage gelangt ist.
- Content Bias schädlich: Ein Sprachmodell, das auf voreingenommenen, schädlichen Daten trainiert wurde, kann dieses Verhalten in seiner Ausgabe aufweisen, auch wenn es nicht ausdrücklich dazu angewiesen wird.
Aber wo genau kommt das Konsistenzproblem her? Ist die Art und Weise, wie das Sprachmodell selbst trainiert wird, anfällig für Inkonsistenzen?
Wie führen Sprachmodell-Trainingsstrategien zu Inkonsistenzen?
Next-Token-Prediction und Masked-Language-Modeling sind die Kerntechnologien zum Trainieren von Sprachmodellen. Beim ersten Ansatz erhält das Modell eine Folge von Wörtern als Eingabe und wird gebeten, das nächste Wort in der Folge vorherzusagen. Wenn Sie dem Modell den Eingabesatz
„Die Katze saß auf dem“
bereitstellen, kann es das nächste Wort als „Matte“, „Stuhl“ oder „Boden“ vorhersagen, da diese Wörter im vorherigen Kontext „The“ sind Die Wahrscheinlichkeit des Auftretens ist hoch; das Sprachmodell ist tatsächlich in der Lage, die Wahrscheinlichkeit jedes möglichen Wortes angesichts der vorherigen Sequenz zu bewerten. Die
maskierte Sprachmodellierungsmethode ist eine Variante der Next-Token-Vorhersage, bei der einige Wörter im Eingabesatz durch spezielle Token ersetzt werden, wie z. B. [MASK]. Das Modell wird dann gebeten, das richtige Wort vorherzusagen, das an der Maskenposition eingefügt werden sollte. Wenn Sie dem Modell einen Satz geben:
„Die [MASKE] saß auf dem „
“, kann es vorhersagen, dass die Wörter, die in der MASKENposition ausgefüllt werden sollten, „Katze“ und „Hund“ sind.
Einer der Vorteile dieser objektiven Funktionen besteht darin, dass sie es dem Modell ermöglichen, die statistische Struktur der Sprache zu lernen, wie beispielsweise häufige Wortfolgen und Wortverwendungsmuster. Dies trägt häufig dazu bei, dass das Modell natürlicheren und flüssigeren Text generiert, und ist ein wichtiger Schritt in der Vortrainingsphase jedes Sprachmodells.
Allerdings können diese Zielfunktionen auch Probleme verursachen, vor allem weil das Modell nicht zwischen wichtigen Fehlern und unwichtigen Fehlern unterscheiden kann. Ein sehr einfaches Beispiel ist, wenn Sie den Satz in das Modell eingeben:
„Das Römische Reich [MASK] mit der Herrschaft des Augustus.“
Es kann vorhergesagt werden, dass die MASKE-Position mit „begann“ oder „besetzt werden sollte“ beendet“, da die Wahrscheinlichkeit des Auftretens dieser beiden Wörter sehr hoch ist.
Im Allgemeinen können diese Trainingsstrategien dazu führen, dass Sprachmodelle bei einigen komplexeren Aufgaben inkonsistent sind, da ein Modell, das nur darauf trainiert wird, das nächste Wort in einer Textsequenz vorherzusagen, möglicherweise nicht unbedingt seine Bedeutung erlernt . Daher lässt sich das Modell nur schwer auf Aufgaben übertragen, die ein tieferes Verständnis der Sprache erfordern.
Forscher untersuchen verschiedene Methoden, um das Konsistenzproblem in großen Sprachmodellen zu lösen. ChatGPT basiert auf dem ursprünglichen GPT-3-Modell, wurde jedoch mithilfe von menschlichem Feedback weiter trainiert, um den Lernprozess zu steuern und Inkonsistenzen im Modell zu beheben. Die verwendete spezifische Technologie ist die oben genannte RLHF. ChatGPT ist das erste Modell, das diese Technologie in realen Szenarien nutzt.
Wie nutzt ChatGPT menschliches Feedback, um das Konsistenzproblem zu lösen?
Verstärkendes Lernen aus menschlichem Feedback
Der Ansatz besteht im Allgemeinen aus drei verschiedenen Schritten:
- Überwachte Abstimmung: Ein vorab trainiertes Sprachmodell wird auf eine kleine Menge gekennzeichneter Daten abgestimmt, um eine überwachte Richtlinie zu lernen (d. h. SFT-Modell), das eine Ausgabe aus einer bestimmten Liste von Eingabeaufforderungen generiert;
- Simuliert menschliche Vorlieben: Annotatoren stimmen über eine relativ große Anzahl von SFT-Modellausgaben ab, wodurch ein neuer Datensatz mit Vergleichsdaten erstellt wird. Trainieren Sie ein neues Modell mit dem Namen Trainingsbelohnungsmodell (RM);
- Proximale Richtlinienoptimierung (PPO): Das RM-Modell wird verwendet, um das SFT-Modell weiter abzustimmen und zu verbessern, und das PPO-Ausgabeergebnis ist die Strategie Modell.
Schritt 1 wird nur einmal ausgeführt, während die Schritte 2 und 3 fortlaufend wiederholt werden können: Sammeln Sie weitere Vergleichsdaten zum aktuell besten Richtlinienmodell zum Trainieren eines neuen RM-Modells und trainieren Sie dann eine neue Richtlinie. Als nächstes werden die Details jedes Schritts detailliert beschrieben.
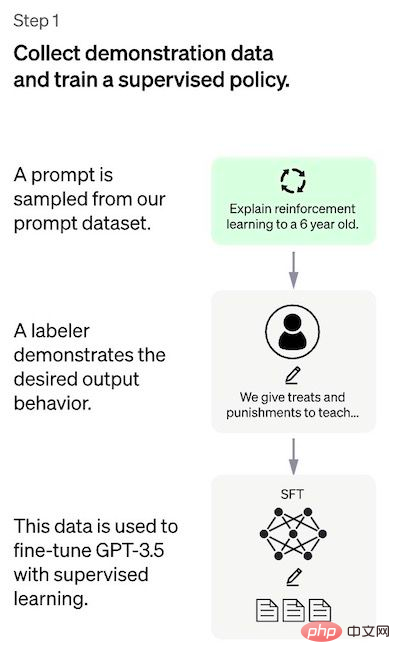
Schritt 1: Überwachtes Abstimmungsmodell
Der erste Schritt besteht darin, Daten zu sammeln, um ein überwachtes Richtlinienmodell zu trainieren.
- Datenerfassung: Wählen Sie eine Eingabeaufforderungsliste aus, und der Annotator notiert die erwartete Ausgabe nach Bedarf. Für ChatGPT werden zwei verschiedene Quellen für Eingabeaufforderungen verwendet: Einige werden direkt von Annotatoren oder Forschern vorbereitet, andere werden aus den API-Anfragen von OpenAI (d. h. von GPT-3-Benutzern) erhalten. Obwohl der gesamte Prozess langsam und teuer ist, ist das Endergebnis ein relativ kleiner, qualitativ hochwertiger Datensatz (wahrscheinlich 12–15.000 Datenpunkte), der zur Optimierung eines vorab trainierten Sprachmodells verwendet werden kann.
- Modellauswahl: Die Entwickler von ChatGPT wählten vorab trainierte Modelle aus der GPT-3.5-Serie, anstatt das ursprüngliche GPT-3-Modell zu optimieren. Das verwendete Basismodell ist die neueste Version von text-davinci-003 (ein GPT-3-Modell, das durch Optimierung des Programmcodes optimiert wurde).
Um einen universellen Chatbot wie ChatGPT zu erstellen, greifen Entwickler auf ein „Codemodell“ statt auf ein Nur-Text-Modell zurück.
Aufgrund der begrenzten Datenmenge in diesem Schritt kann das durch diesen Prozess erhaltene SFT-Modell diese Ausgabe ausgeben ist für den Benutzer immer noch kein Problem und es kommt häufig zu Inkonsistenzen. Das Problem hierbei ist, dass der Schritt des überwachten Lernens hohe Skalierbarkeitskosten mit sich bringt.
Um dieses Problem zu lösen, besteht die verwendete Strategie darin, den menschlichen Annotator anstelle des menschlichen Annotators die verschiedenen Ausgaben des SFT-Modells sortieren zu lassen, um das RM-Modell zu erstellen Erstellen Sie einen größeren kuratierten Datensatz.
Schritt 2: Training des Return-Modells
Dieser Schritt Ziel ist es, die Zielfunktion direkt aus den Daten zu lernen. Der Zweck dieser Funktion besteht darin, die Ausgaben des SFT-Modells zu bewerten, um darzustellen, wie wünschenswert diese Ausgaben für den Menschen sind. Dies spiegelt stark die spezifischen Vorlieben der ausgewählten menschlichen Kommentatoren und die gemeinsamen Richtlinien wider, denen sie folgen wollen. Letztendlich wird dieser Prozess zu einem System führen, das menschliche Präferenzen anhand der Daten nachahmt.
So funktioniert es:
- Eingabeaufforderungsliste und SFT-Modell für jedes A auswählen prompt generiert mehrere Ausgaben (jeder Wert zwischen 4 und 9);
- Der Annotator sortiert die Ausgaben vom besten zum schlechtesten. Das Ergebnis ist ein neuer beschrifteter Datensatz, der ungefähr zehnmal so groß ist wie der genaue Datensatz, der für das SFT-Modell verwendet wird. Diese neuen Daten werden zum Training des RM-Modells verwendet. Das Modell nimmt als Eingabe die Ausgaben des SFT-Modells und sortiert sie nach Priorität.
Für den Annotator ist es einfacher, die Ausgabe zu sortieren, als mehr von vorne zu beginnen Der Prozess kann effizienter skaliert werden. In der Praxis beträgt die Anzahl der ausgewählten Eingabeaufforderungen etwa 30–40.000 und umfasst verschiedene Kombinationen sortierter Ausgaben. 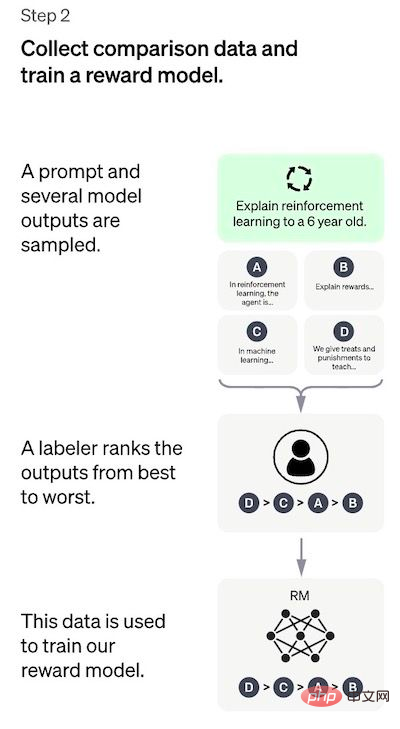
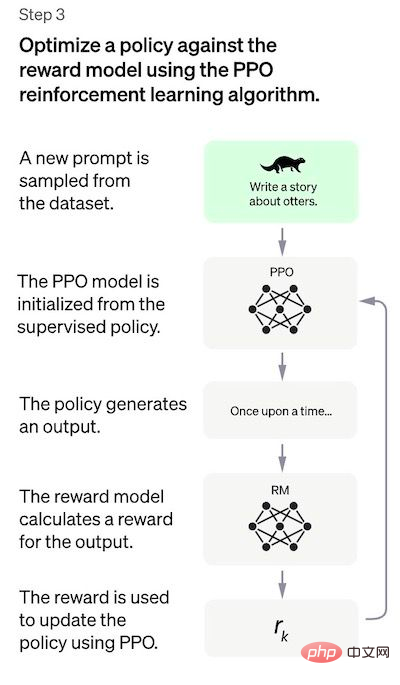
Schritt 3: Feinabstimmung des SFT-Modells mithilfe des PPO-Modells
# 🎜🎜#In einem Schritt wird Verstärkungslernen angewendet, um das SFT-Modell durch Optimierung des RM-Modells abzustimmen. Der verwendete spezifische Algorithmus wird als proximale Richtlinienoptimierung (PPO) bezeichnet, und das Optimierungsmodell wird als proximales Richtlinienoptimierungsmodell bezeichnet.
Was ist ein PPO? Die Hauptmerkmale dieses Algorithmus sind wie folgt:
- PPO ist ein Algorithmus zum Trainieren von Agenten im Reinforcement Learning. Er wird als „On-Policy“-Algorithmus bezeichnet, weil er die aktuelle Richtlinie direkt lernt und aktualisiert, anstatt aus früheren Erfahrungen zu lernen, wie der „Off-Policy“-Algorithmus von DQN. PPO passt die Strategie kontinuierlich basierend auf den vom Agenten ergriffenen Maßnahmen und den erhaltenen Belohnungen an.
- PPO verwendet die Methode der „Vertrauenszonenoptimierung“, um die Strategie zu trainieren, wodurch der Änderungsbereich der Strategie bis zu einem gewissen Grad begrenzt wird Bisherige Strategie zur Gewährleistung der Stabilität des Geschlechts. Dies steht in scharfem Gegensatz zu anderen Strategien, die Gradientenmethoden verwenden, die manchmal umfangreiche Aktualisierungen der Richtlinie vornehmen und dadurch die Richtlinie destabilisieren.
- PPO verwendet eine Wertfunktion, um die erwartete Rendite eines bestimmten Zustands oder einer bestimmten Aktion abzuschätzen. Mithilfe der Wertfunktion wird die Vorteilsfunktion berechnet, die die Differenz zwischen erwarteten Renditen und aktuellen Renditen darstellt. Die Advantage-Funktion wird dann verwendet, um die Richtlinie zu aktualisieren, indem die von der aktuellen Richtlinie ergriffenen Aktionen mit den Aktionen verglichen werden, die von der vorherigen Richtlinie ausgeführt worden wären. Dies ermöglicht es dem PPO, basierend auf dem geschätzten Wert der ergriffenen Maßnahmen fundiertere Aktualisierungen der Strategie vorzunehmen.
In diesem Schritt wird das PPO-Modell durch das SFT-Modell und die Wertfunktion durch das RM-Modell initialisiert. Bei dieser Umgebung handelt es sich um eine „Banditenumgebung“, die zufällige Eingabeaufforderungen generiert und Antworten auf die Eingabeaufforderungen erwartet. Für eine bestimmte Aufforderung und Antwort wird eine entsprechende Belohnung generiert (bestimmt durch das RM-Modell). Das SFT-Modell fügt jedem Token einen KL-Straffaktor hinzu, um eine Überoptimierung des RM-Modells zu vermeiden.
Leistungsbewertung
Da das Modell auf von Menschen kommentierten Eingaben trainiert wird, basiert der Kernteil der Bewertung auch auf menschlichen Eingaben, d. h. indem Annotatoren die Qualität der Modellausgabe bewerten. Um eine Überanpassung der Urteile der an der Trainingsphase beteiligten Annotatoren zu vermeiden, verwendete der Testsatz Eingabeaufforderungen von anderen OpenAI-Clients, die nicht in den Trainingsdaten auftauchten.
Das Modell wird anhand von drei Kriterien bewertet:
- Hilfsbereitschaft: Beurteilen Sie die Fähigkeit des Modells, Benutzeranweisungen zu befolgen und Anweisungen zu extrapolieren.
- Wahrhaftigkeit: Beurteilungsmodelle neigen dazu, in geschlossenen Aufgabenbereichen fiktive Fakten zu produzieren.
- Harmlosigkeit: Der Annotator bewertet, ob die Ausgabe des Modells angemessen ist und diskriminierende Inhalte enthält.
Das Modell wurde auch hinsichtlich der Leistung des Zero-Shot-Lernens bei traditionellen NLP-Aufgaben wie Beantwortung von Fragen, Leseverständnis und Zusammenfassung bewertet. Die Entwickler stellten fest, dass das Modell bei einigen dieser Aufgaben schlechter abschnitt als GPT-3 . Dies ist ein Beispiel für eine „Ausrichtungssteuer“, bei der Ausrichtungsverfahren, die auf dem Lernen zur Verstärkung menschlichen Feedbacks basieren, zu Lasten der Leistung bei bestimmten Aufgaben gehen.
Leistungsregression bei diesen Datensätzen kann durch einen Trick namens Pre-Training-Mixing stark reduziert werden: Während des Trainings des PPO-Modells über den Gradientenabstieg werden Gradientenaktualisierungen durch Mischen der Gradienten des SFT-Modells und des PPO-Modells berechnet.
Nachteile der Methode
Eine sehr offensichtliche Einschränkung dieser Methode besteht darin, dass die für das Feinabstimmungsmodell verwendeten Daten einer Vielzahl komplexer und subjektiver Faktoren im Prozess der Ausrichtung des Sprachmodells auf die menschliche Absicht unterliegen. Zu den Einflüssen gehören hauptsächlich:
- Die Vorlieben menschlicher Annotatoren, die Demodaten generieren;
- Forscher, die Studien entwerfen und Etikettenbeschreibungen schreiben;
- Ausgewählte Eingabeaufforderungen, die von Entwicklern erstellt oder von OpenAI-Kunden bereitgestellt werden;
- Annotator Bias ist sowohl im RM-Modelltraining als auch in der Modellbewertung enthalten.
Die Autoren von ChatGPT erkennen auch die offensichtliche Tatsache an, dass die am Trainingsprozess beteiligten Annotatoren und Forscher möglicherweise nicht alle potenziellen Endbenutzer von Sprachmodellen vollständig repräsentieren.
Zusätzlich zu dieser offensichtlichen „endogenen“ Einschränkung weist diese Methode noch einige andere Mängel und Probleme auf, die gelöst werden müssen:
- Mangel an kontrollierten Studien: Die gemeldeten Ergebnisse vergleichen die Leistung des endgültigen PPO-Modells mit dem SFT-Modell. Das kann irreführend sein: Woher wissen Sie, dass diese Verbesserungen auf RLHF zurückzuführen sind? Daher sind kontrollierte Studien erforderlich, einschließlich der Investition genau der gleichen Anzahl an Annotations-Arbeitsstunden, die für das Training des RM-Modells aufgewendet wurden, um einen größeren kuratierten, überwachten und abgestimmten Datensatz mit qualitativ hochwertigen Daten zu erstellen. Dies ermöglicht eine objektive Messung der Leistungsverbesserungen von RLHF-Methoden im Vergleich zu überwachten Methoden. Einfach ausgedrückt lässt das Fehlen solcher kontrollierten Studien eine grundlegende Frage völlig unbeantwortet: Leistet RLHF wirklich gute Arbeit bei der konsistenten Sprachmodellierung?
- Vergleichsdaten mangelt es an fundierter Wahrheit: Annotatoren sind sich häufig nicht einig über die Rangfolge der Modellergebnisse. Technisch gesehen besteht das Risiko, dass den Vergleichsdaten eine große Varianz hinzugefügt wird, ohne dass eine zugrunde liegende Wahrheit vorliegt.
- Menschliche Vorlieben sind nicht homogen: Der RLHF-Ansatz behandelt menschliche Vorlieben als homogen und statisch. Es ist offensichtlich falsch anzunehmen, dass alle Menschen die gleichen Werte haben. Obwohl es eine große Anzahl öffentlicher Werte gibt, haben die Menschen in vielen Angelegenheiten immer noch unterschiedliche Wahrnehmungen.
- Stabilitätstest des RM-Modells für Eingabeaufforderungen: Es gibt keine Experimente, die die Empfindlichkeit des RM-Modells gegenüber Änderungen der Eingabeaufforderung belegen. Wenn zwei Eingabeaufforderungen syntaktisch unterschiedlich, aber semantisch äquivalent sind, kann das RM-Modell dann einen signifikanten Unterschied in der Rangfolge der Modellausgabe aufweisen? Das heißt, wie wichtig ist die Qualität der Eingabeaufforderung für RM?
- Andere Probleme: Bei RL-Methoden können Modelle manchmal lernen, ihre eigenen RM-Modelle zu steuern, um gewünschte Ergebnisse zu erzielen, was zu „überoptimierten Strategien“ führt. Dies kann dazu führen, dass das Modell einige Muster neu erstellt, die dem RM-Modell aus unbekannten Gründen eine höhere Punktzahl verliehen haben. ChatGPT behebt dies, indem es die KL-Strafe in der RM-Funktion verwendet.
Verwandte Lektüre:
- Verwandte Artikel zur RLHF-Methode für ChatGPT: Sprachmodelle trainieren, um Anweisungen mit menschlichem Feedback zu befolgen (https://arxiv.org/pdf/2203.02155.pdf), Es enthält tatsächlich Einzelheiten ein Modell namens InstructionGPT, das OpenAI das „Geschwistermodell“ von ChatGPT nennt.
- Lernen, aus menschlichem Feedback zusammenzufassen (https://arxiv.org/pdf/2009.01325.pdf) beschreibt RLHF im Kontext der Textzusammenfassung.
- PPO (https://arxiv.org/pdf/1707.06347.pdf): PPO-Algorithmuspapier.
- Deep Reinforcement Learning aus menschlichen Vorlieben (https://arxiv.org/abs/1706.03741)
- DeepMind schlug eine Alternative zu OpenAI RLHF in Sparrow vor (https://arxiv.org/pdf/2209.14375 .pdf). ) und GopherCite (https://arxiv.org/abs/2203.11147) Dateien.
Das obige ist der detaillierte Inhalt vonErklären Sie in einfachen Worten das Funktionsprinzip von ChatGPT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots
Oct 27, 2023 pm 06:00 PM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots
Oct 27, 2023 pm 06:00 PM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots Einführung: Im heutigen Informationszeitalter sind intelligente Kundenservicesysteme zu einem wichtigen Kommunikationsinstrument zwischen Unternehmen und Kunden geworden. Um den Kundenservice zu verbessern, greifen viele Unternehmen auf Chatbots zurück, um Aufgaben wie Kundenberatung und Beantwortung von Fragen zu erledigen. In diesem Artikel stellen wir vor, wie Sie mithilfe des leistungsstarken ChatGPT-Modells und der Python-Sprache von OpenAI einen intelligenten Kundenservice-Chatbot erstellen und verbessern können
 So installieren Sie ChatGPT auf einem Mobiltelefon
Mar 05, 2024 pm 02:31 PM
So installieren Sie ChatGPT auf einem Mobiltelefon
Mar 05, 2024 pm 02:31 PM
Installationsschritte: 1. Laden Sie die ChatGTP-Software von der offiziellen ChatGTP-Website oder dem mobilen Store herunter. 2. Wählen Sie nach dem Öffnen in der Einstellungsoberfläche die Sprache aus. 3. Wählen Sie in der Spieloberfläche das Mensch-Maschine-Spiel aus 4. Geben Sie nach dem Start Befehle in das Chatfenster ein, um mit der Software zu interagieren.
 So entwickeln Sie einen intelligenten Chatbot mit ChatGPT und Java
Oct 28, 2023 am 08:54 AM
So entwickeln Sie einen intelligenten Chatbot mit ChatGPT und Java
Oct 28, 2023 am 08:54 AM
In diesem Artikel stellen wir vor, wie man intelligente Chatbots mit ChatGPT und Java entwickelt, und stellen einige spezifische Codebeispiele bereit. ChatGPT ist die neueste Version des von OpenAI entwickelten Generative Pre-Training Transformer, einer auf neuronalen Netzwerken basierenden Technologie für künstliche Intelligenz, die natürliche Sprache verstehen und menschenähnlichen Text generieren kann. Mit ChatGPT können wir ganz einfach adaptive Chats erstellen
 Kann Chatgpt in China verwendet werden?
Mar 05, 2024 pm 03:05 PM
Kann Chatgpt in China verwendet werden?
Mar 05, 2024 pm 03:05 PM
chatgpt kann in China verwendet werden, kann jedoch nicht registriert werden. Wenn Benutzer sich registrieren möchten, können sie zur Registrierung eine ausländische Mobiltelefonnummer verwenden. Beachten Sie, dass während des Registrierungsprozesses auf die Netzwerkumgebung umgestellt werden muss eine fremde IP.
 So verwenden Sie ChatGPT und Python, um die Funktion zur Erkennung von Benutzerabsichten zu implementieren
Oct 27, 2023 am 09:04 AM
So verwenden Sie ChatGPT und Python, um die Funktion zur Erkennung von Benutzerabsichten zu implementieren
Oct 27, 2023 am 09:04 AM
So verwenden Sie ChatGPT und Python, um die Funktion zur Erkennung von Benutzerabsichten zu implementieren. Einführung: Im heutigen digitalen Zeitalter ist die Technologie der künstlichen Intelligenz in verschiedenen Bereichen nach und nach zu einem unverzichtbaren Bestandteil geworden. Unter anderem ermöglicht die Entwicklung der Technologie zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), dass Maschinen menschliche Sprache verstehen und verarbeiten können. ChatGPT (Chat-GeneratingPretrainedTransformer) ist eine Art von
 So erstellen Sie einen intelligenten Kundendienstroboter mit ChatGPT PHP
Oct 28, 2023 am 09:34 AM
So erstellen Sie einen intelligenten Kundendienstroboter mit ChatGPT PHP
Oct 28, 2023 am 09:34 AM
So bauen Sie mit ChatGPTPHP einen intelligenten Kundendienstroboter. Einführung: Mit der Entwicklung der Technologie der künstlichen Intelligenz werden Roboter zunehmend im Bereich Kundendienst eingesetzt. Der Einsatz von ChatGPTPHP zum Aufbau eines intelligenten Kundendienstroboters kann Unternehmen dabei helfen, effizientere und personalisiertere Kundendienste anzubieten. In diesem Artikel wird erläutert, wie Sie mit ChatGPTPHP einen intelligenten Kundendienstroboter erstellen, und es werden spezifische Codebeispiele bereitgestellt. 1. Installieren Sie ChatGPTPHP und nutzen Sie ChatGPTPHP, um einen intelligenten Kundendienstroboter aufzubauen.
 So entwickeln Sie einen KI-basierten Sprachassistenten mit ChatGPT und Java
Oct 27, 2023 pm 06:09 PM
So entwickeln Sie einen KI-basierten Sprachassistenten mit ChatGPT und Java
Oct 27, 2023 pm 06:09 PM
So verwenden Sie ChatGPT und Java zur Entwicklung eines auf künstlicher Intelligenz basierenden Sprachassistenten. Die rasante Entwicklung der künstlichen Intelligenz (kurz: Künstliche Intelligenz) hat in verschiedene Bereiche Einzug gehalten, unter denen Sprachassistenten eine der beliebtesten Anwendungen sind. In diesem Artikel stellen wir vor, wie man mit ChatGPT und Java einen auf künstlicher Intelligenz basierenden Sprachassistenten entwickelt. ChatGPT ist ein Open-Source-Projekt für Interaktion durch natürliche Sprache, entwickelt von OpenAI, einer KI-Forschungseinrichtung.
