

Der HCC-Hochleistungs-Computing-Cluster der neuen Generation nutzt die neueste Generation selbst entwickelter Xinghai-Server und ist mit der NVIDIA H800 Tensor Core GPU ausgestattet.
Tencent-Beamte sagten, dass der Cluster auf einer selbst entwickelten Netzwerk- und Speicherarchitektur basiert und eine ultrahohe Verbindungsbandbreite von 3,2 T, eine Durchsatzkapazität auf TB-Ebene und mehrere zehn Millionen IOPS bietet. Tatsächliche Messergebnisse zeigen, dass die Rechenleistung des Clusters der neuen Generation im Vergleich zur vorherigen Generation um das Dreifache verbessert wurde.
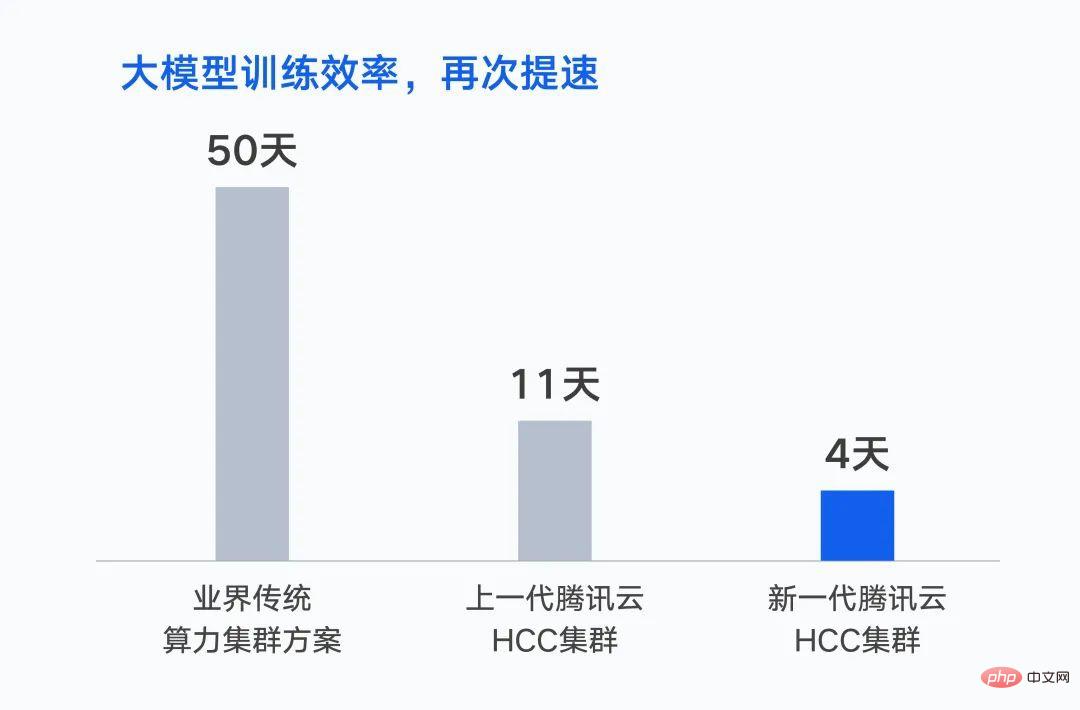
Im Oktober letzten Jahres schloss Tencent das Training des ersten groß angelegten KI-Modells mit einer Billion Parametern ab – dem Hunyuan NLP-Großmodell. Bei gleichem Datensatz verkürzt sich die Trainingszeit von 50 Tagen auf 11 Tage. Wenn es auf einem Cluster der neuen Generation basiert, wird die Schulungszeit weiter auf 4 Tage verkürzt.
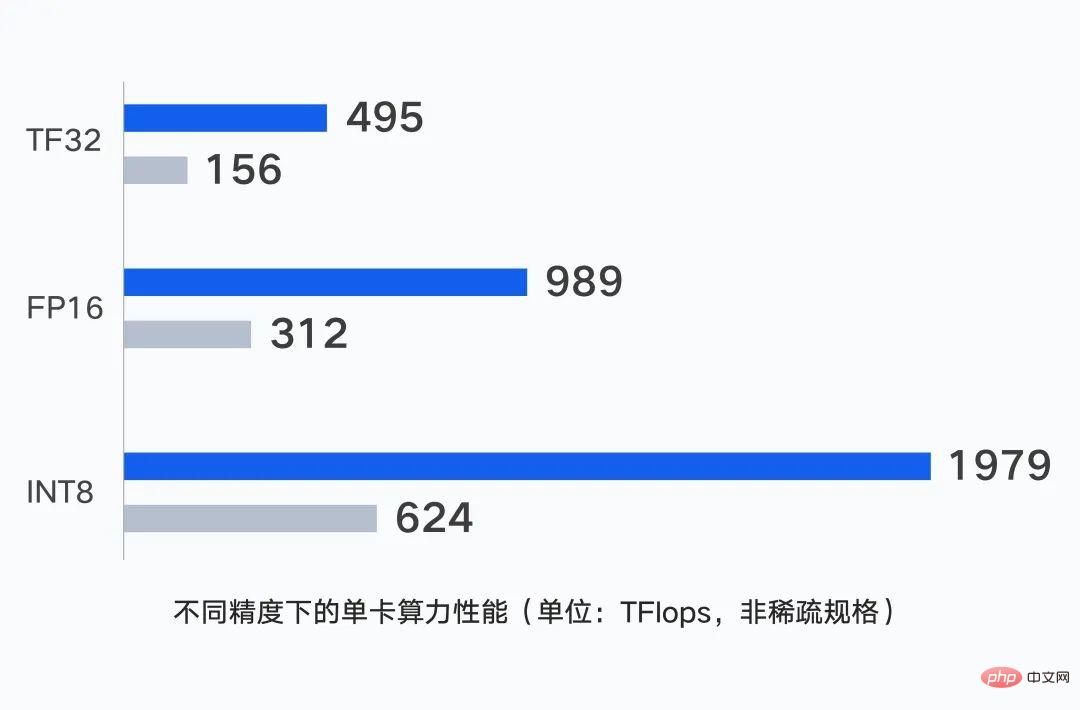
Auf der Rechenebene ist die Server-Standalone-Leistung die Grundlage der Cluster-Rechenleistung. Die einzelne GPU-Karte des Tencent Cloud-Clusters der neuen Generation unterstützt die Ausgabe von bis zu 1979 TFlops Rechenleistung bei unterschiedlichen Genauigkeiten.
Für große Modellszenarien verwendet der selbst entwickelte Server von Durch Einzelpunktberechnungen kann die Kraftleistung auf ein höheres Niveau verbessert werden.
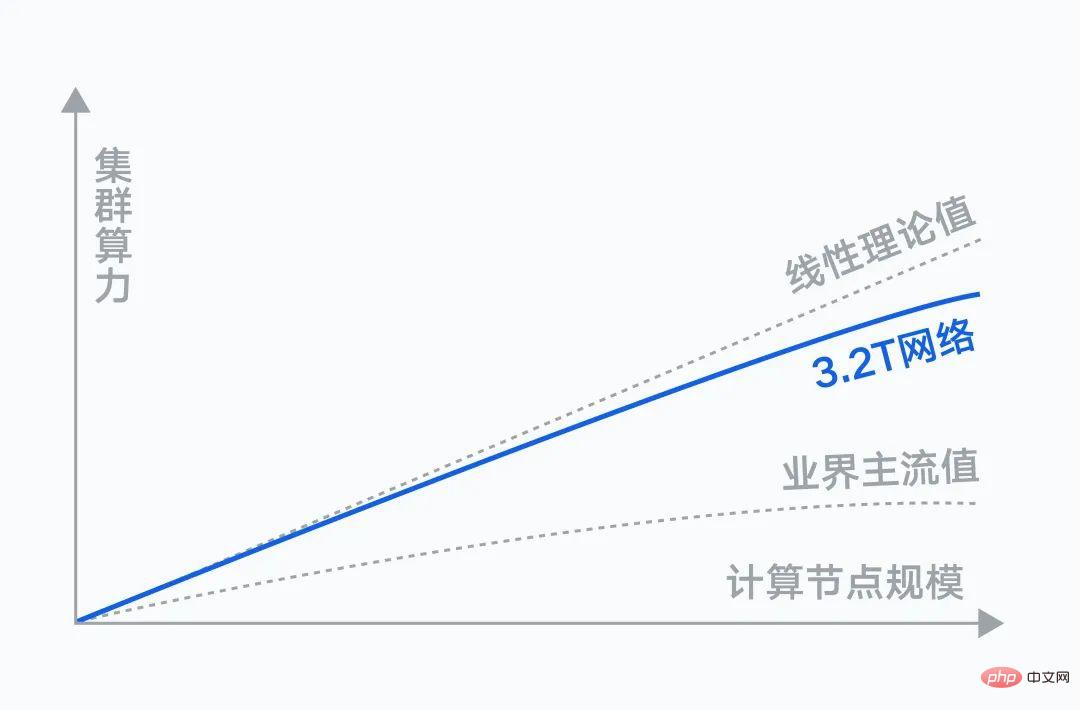
Auf Netzwerkebene bestehen enorme Anforderungen an die Dateninteraktion zwischen Rechenknoten. Mit zunehmender Clustergröße wirkt sich die Kommunikationsleistung direkt auf die Trainingseffizienz aus und erfordert eine maximale Zusammenarbeit zwischen dem Netzwerk und den Rechenknoten.
Tencents selbst entwickeltes Xingmai-Hochleistungscomputernetzwerk behauptet, über die branchenweit höchste 3,2T-RDMA-Kommunikationsbandbreite zu verfügen. Tatsächliche Messergebnisse zeigen, dass das 3,2T-Xingmai-Netzwerk bei gleicher Anzahl an GPUs eine Steigerung der Gesamtrechenleistung des Clusters um 20 % im Vergleich zum 1,6T-Netzwerk aufweist.
Gleichzeitig wird Tencents selbst entwickelte leistungsstarke kollektive Kommunikationsbibliothek TCCL in maßgeschneiderte Lösungen integriert. Im Vergleich zur branchenweiten Open-Source-Bibliothek für kollektive Kommunikation optimiert es die Lastleistung für das Training großer Modelle um 40 % und beseitigt Probleme mit Trainingsunterbrechungen, die durch mehrere Netzwerkgründe verursacht werden.
Auf der Speicherebene liest eine große Anzahl von Rechenknoten während des Trainings großer Modelle gleichzeitig einen Stapel von Datensätzen. Es ist notwendig, die Datenladezeit so weit wie möglich zu verkürzen, um Wartezeiten zu vermeiden Rechenknoten.
Die selbst entwickelte Speicherarchitektur von Tencent Cloud verfügt über Durchsatzkapazitäten auf Terabyte-Ebene und mehrere zehn Millionen IOPS und unterstützt so den Speicherbedarf in verschiedenen Szenarien. Die Objektspeicherlösung COS+GooseFS und die leistungsstarke Dateispeicherlösung CFS Turbo erfüllen die hohe Leistung, den großen Durchsatz und die massiven Speicheranforderungen in großen Modellszenarien vollständig.

Darüber hinaus integriert der Cluster der neuen Generation die von Tencent Cloud selbst entwickelte TACO-Trainingsbeschleunigungs-Engine, die eine große Anzahl von Optimierungen auf Systemebene für Netzwerkprotokolle, Kommunikationsstrategien, KI-Frameworks und Modellkompilierung durchführt und so erheblich Schulungseinsparungen ermöglicht Tuning- und Rechenleistungskosten.
AngelPTM, das Schulungsframework hinter dem Hunyuan-Großmodell von Tencent, hat über Tencent Cloud TACO auch Dienste bereitgestellt, um Unternehmen dabei zu helfen, die Implementierung großer Modelle zu beschleunigen.
Durch die umfangreichen Modellfunktionen und die Toolbox der Tencent Cloud TI-Plattform können Unternehmen fein abgestimmte Schulungen auf der Grundlage industrieller Szenariodaten durchführen, die Produktionseffizienz verbessern und schnell KI-Anwendungen erstellen und bereitstellen.
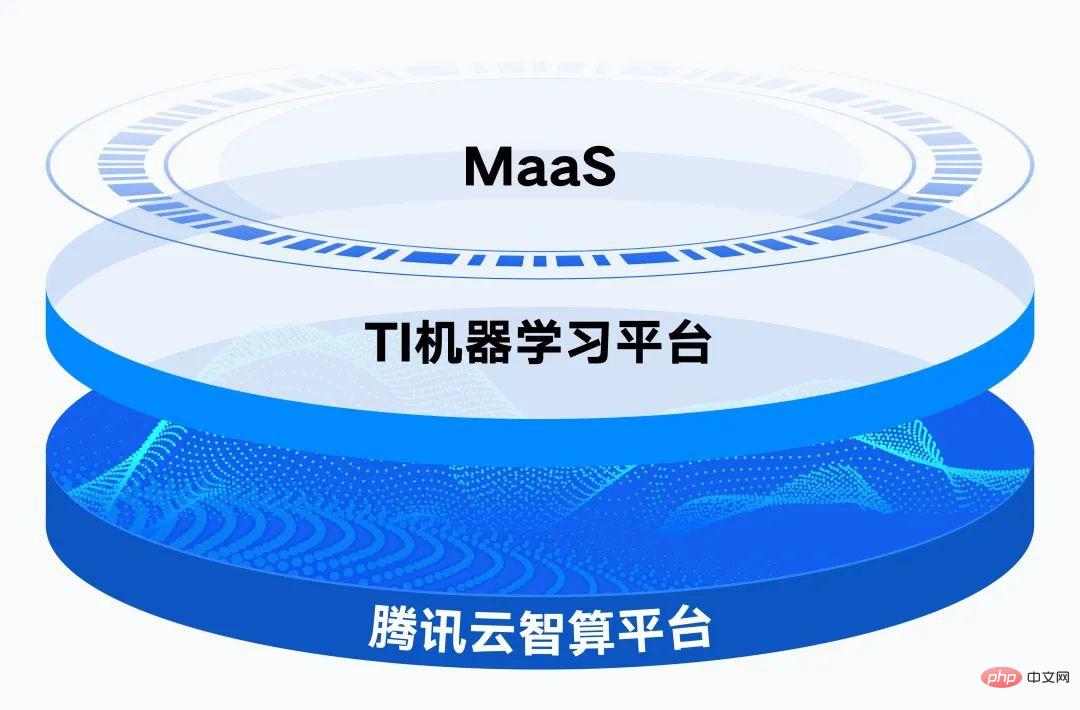
Auf der Grundlage der verteilten Cloud-nativen Governance-Funktionen bietet die Tencent Cloud Intelligent Computing Platform 16 EFLOPS Gleitkomma-Rechenleistung.
Das obige ist der detaillierte Inhalt vonTencent bringt eine neue Generation von Super-Computing-Clustern auf den Markt: Für das Training großer Modelle wurde die Leistung um das Dreifache gesteigert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Verwendung der URL-Code-Funktion
Verwendung der URL-Code-Funktion
 Was ist Hadoop?
Was ist Hadoop?
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 Ist es umso besser, je höher die CPU-Frequenz des Computers ist?
Ist es umso besser, je höher die CPU-Frequenz des Computers ist?
 So erstellen Sie einen Index in Word
So erstellen Sie einen Index in Word
 APP-Ranking der virtuellen Devisenhandelsplattform
APP-Ranking der virtuellen Devisenhandelsplattform
 Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



