

Die Optimierung des neuronalen Netzwerks während des Trainings besteht darin, zunächst den Fehler des aktuellen Zustands des Modells abzuschätzen. Um dann den Fehler der nächsten Bewertung zu reduzieren, müssen die Gewichte mithilfe einer Funktion aktualisiert werden, die dargestellt werden kann Der Fehler wird als Verlustfunktion bezeichnet. Die Wahl der Verlustfunktion hängt mit dem spezifischen Problem der Vorhersagemodellierung (z. B. Klassifizierung oder Regression) zusammen, für das das neuronale Netzwerkmodell anhand von Beispielen lernt. In diesem Artikel stellen wir einige häufig verwendete Verlustfunktionen vor, darunter:
 Mittlerer quadratischer Fehlerverlust des Regressionsmodells
Mittlerer quadratischer Fehlerverlust des Regressionsmodells
Kreuzentropie und Scharnier des binären Klassifizierungsmodells Verlust
Die Skalierung reeller Eingabe- und Ausgabevariablen auf einen angemessenen Bereich kann oft die Leistung neuronaler Netze verbessern. Wir müssen also die Daten standardisieren.
StandardScaler ist auch in der scikit-learn-Bibliothek zu finden. Um das Problem zu vereinfachen, skalieren wir alle Daten, bevor wir sie in Trainings- und Testsätze aufteilen. 
Teilen Sie dann die Trainings- und Validierungssätze gleichmäßig auf.

In der Reihenfolge Um die Unterschiede mit der Verlustfunktion einzuführen, werden wir ein kleines mehrschichtiges Perzeptronmodell (MLP) entwickeln.
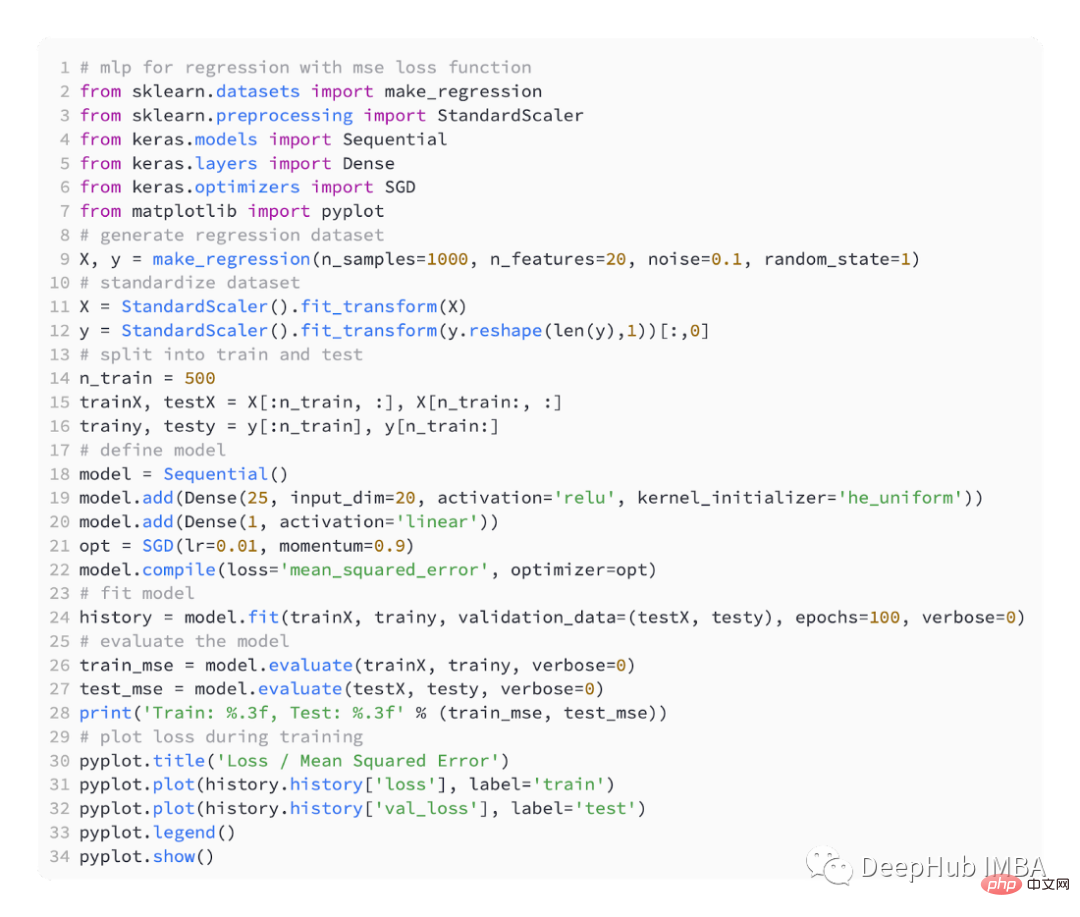
Laut Problemdefinition gibt es 20 Features als Input, die unser Modell durchlaufen. Zur Vorhersage ist ein realer Wert erforderlich, daher verfügt die Ausgabeschicht über einen Knoten. 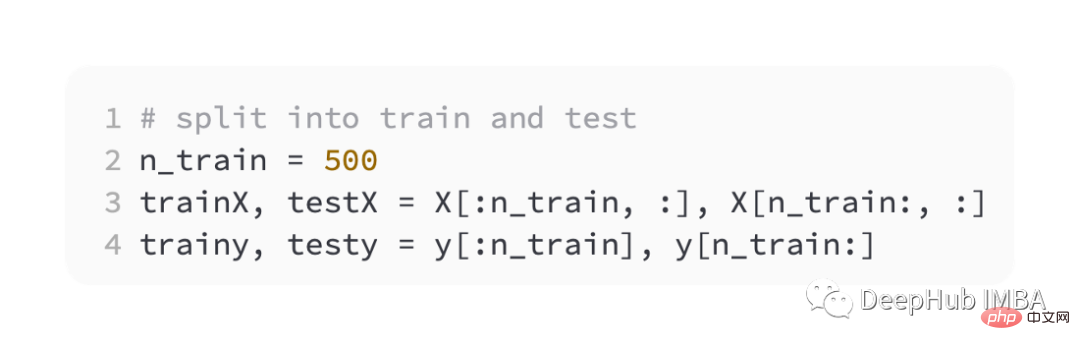
Wir verwenden SGD zur Optimierung und haben eine Lernrate von 0,01 und einen Impuls von 0,9, was beides vernünftige Standardwerte sind. Das Training wird über 100 Epochen durchgeführt, der Testsatz wird am Ende jeder Phase ausgewertet und die Lernkurve wird aufgezeichnet.

Nachdem das Modell fertiggestellt ist, kann die Verlustfunktion eingeführt werden:
MSE
Der folgende Code ist ein vollständiges Beispiel für das obige Regressionsproblem.

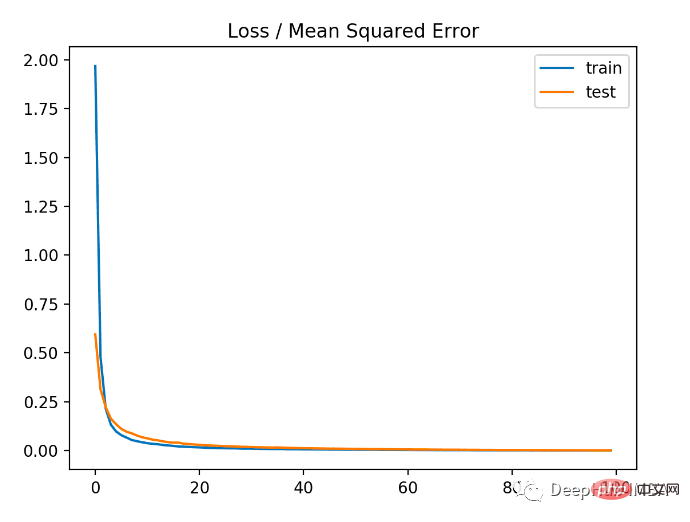
Im ersten Schritt der Ausführung des Beispiels wird der mittlere quadratische Fehler der Trainings- und Testdatensätze des Modells gedruckt, da 3 Dezimalstellen bleiben erhalten, daher wird es als 0,000 angezeigt unverändert. Abhängig von den Leistungs- und Konvergenzeigenschaften des Modells ist der mittlere quadratische Fehler eine gute Wahl für Regressionsprobleme.
MSLE
Bei Regressionsproblemen mit einem breiten Wertebereich ist es möglicherweise nicht wünschenswert, große Werte vorherzusagen wie der mittlere quadratische Fehler, der das Modell bestraft. Der mittlere quadratische Fehler kann also berechnet werden, indem zunächst der natürliche Logarithmus jedes vorhergesagten Werts berechnet wird. Dieser Verlust wird MSLE oder mittlerer quadratischer logarithmischer Fehler genannt. 
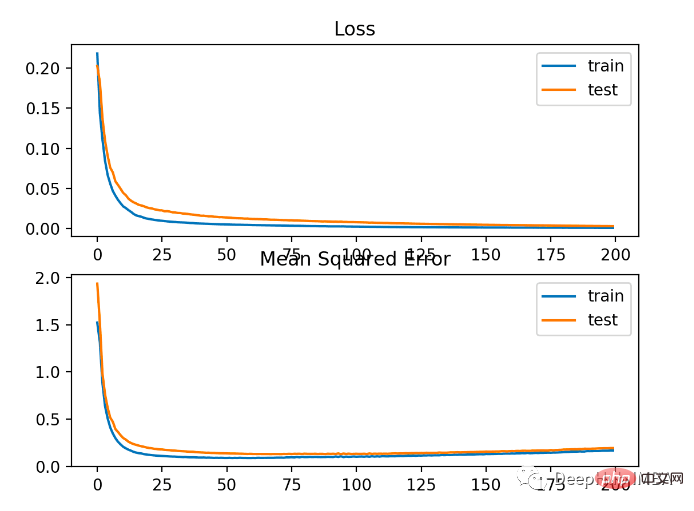
Das Modell weist sowohl bei Trainings- als auch bei Testdatensätzen einen etwas schlechteren MSE auf. Dies liegt daran, dass die Verteilung der Zielvariablen eine Standard-Gaußsche Verteilung ist, was bedeutet, dass unsere Verlustfunktion für dieses Problem möglicherweise nicht sehr geeignet ist.

Die folgende Abbildung zeigt den Vergleich der einzelnen Trainingsepochen. Der MSE konvergiert gut, aber der MSE passt möglicherweise zu stark an, da er von Epoche 20 bis zur Änderung abnimmt und zu steigen beginnt.
Je nach Regressionsproblem kann die Verteilung der Zielvariablen hauptsächlich eine Gaußsche Verteilung sein, aber auch Ausreißer enthalten, z. B. große oder kleine Werte, die weit vom Mittelwert entfernt sind.
In diesem Fall ist der mittlere absolute Fehler oder MAE-Verlust eine geeignete Verlustfunktion, da er robuster gegenüber Ausreißern ist. Berechnet als Durchschnitt unter Berücksichtigung der absoluten Differenz zwischen den tatsächlichen und den vorhergesagten Werten.
Verwendung der Verlustfunktion „mean_absolute_error“

Dies ist der vollständige Code, der MAE verwendet

Die Ergebnisse sind wie folgt

Wie Sie in der Abbildung unten sehen können, konvergiert MAE zwar, aber es hat einen holprigen Prozess. Auch MAE ist in diesem Fall wenig geeignet, da die Zielvariable eine Gauß-Funktion ohne große Ausreißer ist.
Ein binäres Klassifizierungsproblem ist eine von zwei Bezeichnungen in einem prädiktiven Modellierungsproblem. Dieses Problem wird als Vorhersage des Werts der ersten oder zweiten Klasse als 0 oder 1 definiert und im Allgemeinen als Vorhersage der Wahrscheinlichkeit der Zugehörigkeit zum Klassenwert 1 implementiert.
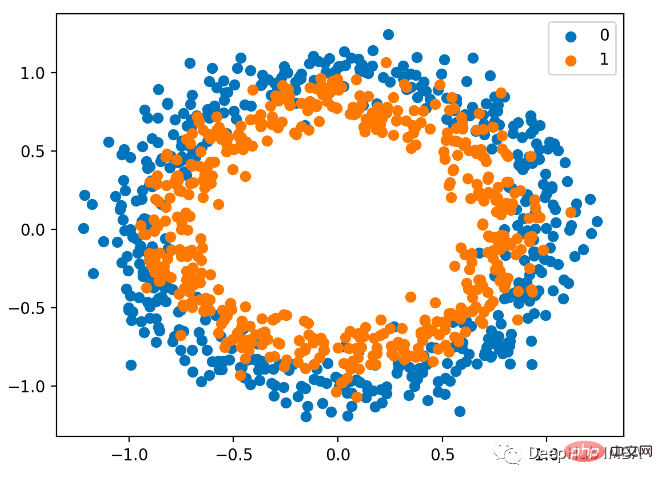
Wir verwenden auch sklearn, um Daten zu generieren. Es hat eine zweidimensionale Ebene und zwei konzentrische Kreise gehören zur Klasse 0 und die Punkte auf dem inneren Kreis gehören zur Klasse 1 . Um das Lernen anspruchsvoller zu machen, fügen wir den Stichproben auch statistisches Rauschen hinzu. Die Stichprobengröße beträgt 1000 und es werden 10 % statistisches Rauschen hinzugefügt.

Ein Streudiagramm eines Datensatzes kann uns helfen, das Problem zu verstehen, das wir modellieren. Nachfolgend finden Sie ein vollständiges Beispiel.

Das Streudiagramm sieht wie folgt aus, wobei die Eingabevariablen die Position der Punkte bestimmen und die Farben Klassenwerte sind. 0 ist blau und 1 ist orange.
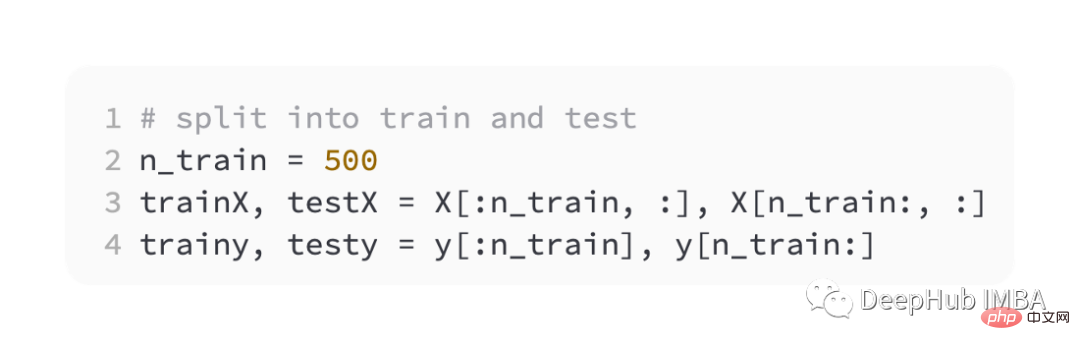
Hier ist noch die Hälfte für das Training und die andere Hälfte zum Testen,
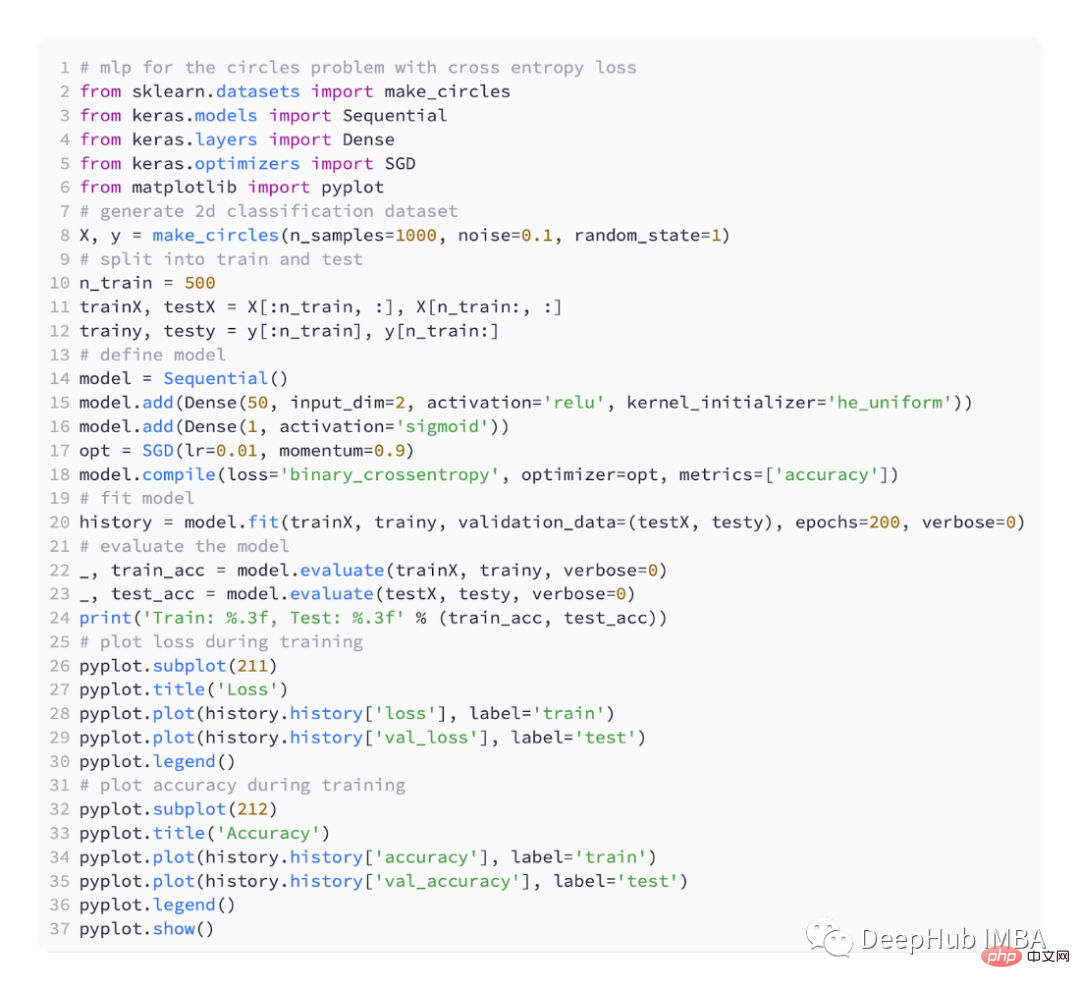
Wir definieren immer noch ein einfaches MLP-Modell,

mit SGD-Optimierung, die Lernrate beträgt 0,01 und der Impuls beträgt 0,99.

Das Modell wird 200 Runden lang zur Anpassung trainiert und die Leistung des Modells wird anhand von Verlust und Genauigkeit bewertet.

BCE ist die Standardverlustfunktion, die zur Lösung binärer Klassifizierungsprobleme verwendet wird. Im Maximum-Likelihood-Inferenzrahmen ist es die Verlustfunktion der Wahl. Für Vorhersagen vom Typ 1 berechnet die Kreuzentropie einen Score, der die durchschnittliche Differenz zwischen der tatsächlichen und der vorhergesagten Wahrscheinlichkeitsverteilung zusammenfasst.
Beim Kompilieren des Keras-Modells kann binäre_Kreuzentropie als Verlustfunktion angegeben werden.

Um die Wahrscheinlichkeit der Klasse 1 vorherzusagen, muss die Ausgabeschicht einen Knoten und eine „Sigmoid“-Aktivierung enthalten.

Hier ist der vollständige Code:
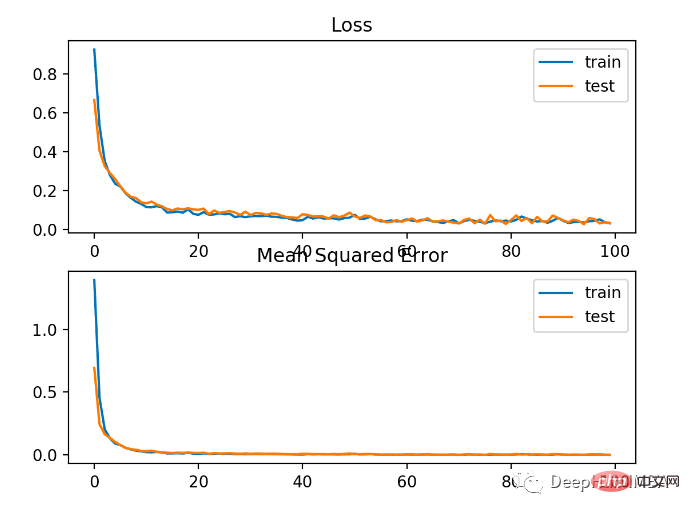
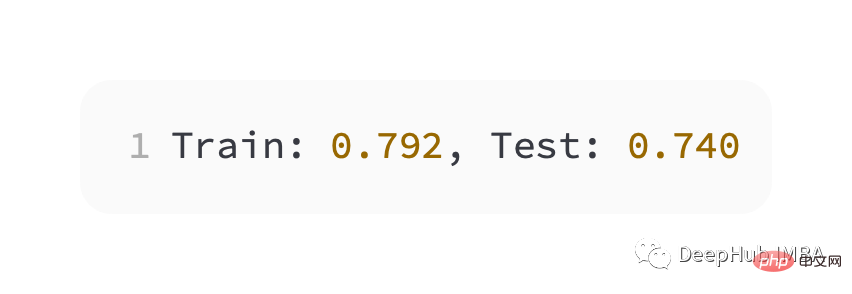
Das Modell hat das Problem relativ gut gelernt, mit einer Genauigkeit von 83 % und einer Genauigkeit von 85 % im Testdatensatz. Es gibt eine gewisse Überschneidung zwischen den Bewertungen, was darauf hindeutet, dass das Modell weder über- noch unterangepasst ist.
Wie im Bild unten zu sehen ist, ist der Trainingseffekt sehr gut. Da der Fehler zwischen Wahrscheinlichkeitsverteilungen kontinuierlich ist, ist das Verlustdiagramm glatt, während das Genauigkeitsliniendiagramm Unebenheiten aufweist, da Beispiele in den Trainings- und Testsätzen nur als richtig oder falsch vorhergesagt werden können und weniger detaillierte Informationen liefern.
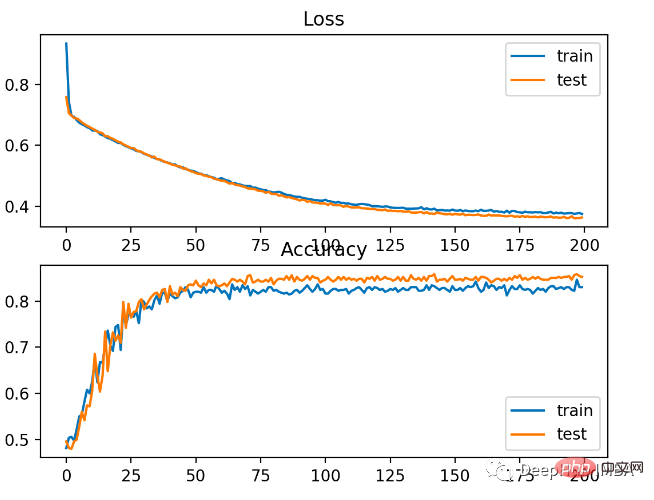
Das Support Vector Machine (SVM)-Modell verwendet die Hinge-Verlustfunktion als Alternative zur Kreuzentropie, um binäre Klassifizierungsprobleme zu lösen.
Der Zielwert liegt im Satz [-1, 1] und ist für die Verwendung mit der binären Klassifizierung vorgesehen. Scharniere erhalten größere Fehler, wenn die tatsächlichen und vorhergesagten Klassenwerte unterschiedliche Vorzeichen haben. Bei binären Klassifizierungsproblemen ist sie manchmal besser als die Kreuzentropie.
Als ersten Schritt müssen wir den Wert der Zielvariablen auf die Menge {-1, 1} ändern.

In Keras heißt es „Scharnier“.

In der Ausgabeschicht des Netzwerks muss ein einzelner Knoten der Tanh-Aktivierungsfunktion verwendet werden, um einen einzelnen Wert zwischen -1 und 1 auszugeben.

Hier ist der vollständige Code:

Etwas schlechtere Leistung als Kreuzentropie, weniger als 80 % Genauigkeit bei Trainings- und Testsätzen.
Wie Sie der folgenden Abbildung entnehmen können, ist das Modell konvergiert, und das Klassifizierungsgenauigkeitsdiagramm zeigt, dass es ebenfalls konvergiert hat.
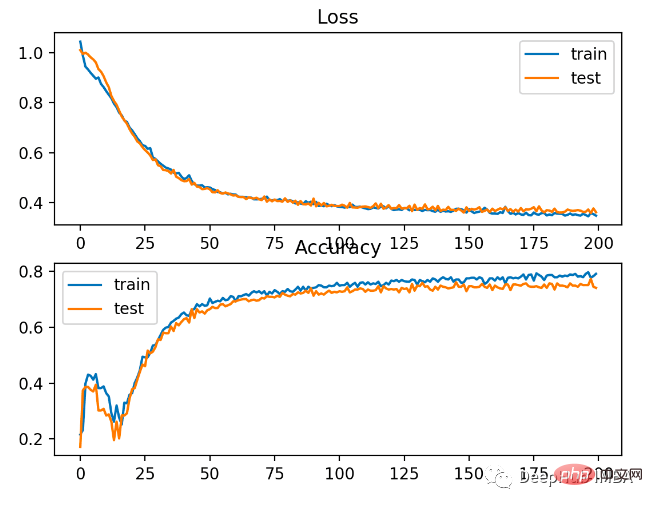
Sie können sehen, dass BCE für dieses Problem besser geeignet ist. Der mögliche Grund dafür ist, dass wir einige Lärmpunkte haben
Das obige ist der detaillierte Inhalt vonFünf häufig verwendete Verlustfunktionen zum Trainieren neuronaler Deep-Learning-Netzwerke. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Die acht am häufigsten verwendeten Funktionen in Excel
Die acht am häufigsten verwendeten Funktionen in Excel
 So beheben Sie den Fehlercode 8024401C
So beheben Sie den Fehlercode 8024401C
 Offizielle Binance-Website
Offizielle Binance-Website
 So erstellen Sie eine Datenbank in MySQL
So erstellen Sie eine Datenbank in MySQL
 Was sind die internationalen Postfächer?
Was sind die internationalen Postfächer?
 Häufig verwendete Codes in der HTML-Sprache
Häufig verwendete Codes in der HTML-Sprache
 So löschen Sie eine Datei unter Linux
So löschen Sie eine Datei unter Linux
 Verwendung der Memset-Funktion
Verwendung der Memset-Funktion








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



