
 Technologie-Peripheriegeräte
KI
Zehn häufig verwendete Entfernungsmessmethoden beim maschinellen Lernen
Technologie-Peripheriegeräte
KI
Zehn häufig verwendete Entfernungsmessmethoden beim maschinellen Lernen
Zehn häufig verwendete Entfernungsmessmethoden beim maschinellen Lernen

Die Distanzmetrik ist die Grundlage für überwachte und unbeaufsichtigte Lernalgorithmen, einschließlich k-Nearest Neighbor, Support Vector Machine und K-Means-Clustering usw.
Die Wahl der Distanzmetrik beeinflusst unsere Ergebnisse des maschinellen Lernens, daher ist es wichtig zu überlegen, welche Metrik für das Problem am besten geeignet ist. Daher sollten wir bei der Entscheidung, welche Messmethode wir verwenden, vorsichtig sein. Doch bevor wir eine Entscheidung treffen, müssen wir verstehen, wie die Entfernungsmessung funktioniert und aus welchen Messungen wir wählen können.
In diesem Artikel werden häufig verwendete Methoden zur Entfernungsmessung kurz vorgestellt, wie sie funktionieren, wie sie in Python berechnet werden und wann sie verwendet werden. Dies führt zu tieferem Wissen und Verständnis sowie zu verbesserten Algorithmen und Ergebnissen für maschinelles Lernen.
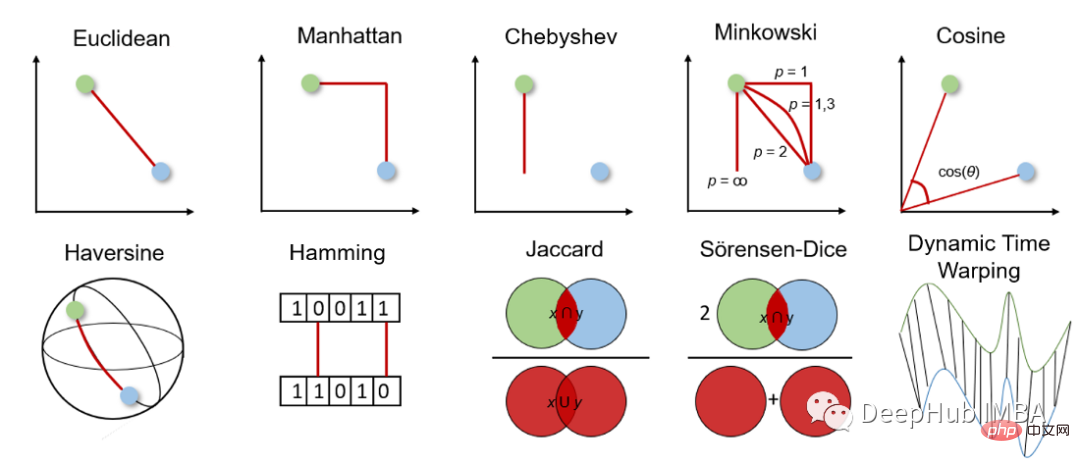
Bevor wir tiefer auf die verschiedenen Distanzmessungen eingehen, wollen wir uns zunächst einen allgemeinen Überblick über ihre Funktionsweise verschaffen und wie man die passende Messung auswählt.
Die Distanzmetrik wird verwendet, um die Differenz zwischen zwei Objekten in einem bestimmten Problemraum, d. h. Features im Datensatz, zu berechnen. Dieser Abstand kann dann verwendet werden, um die Ähnlichkeit zwischen Merkmalen zu bestimmen. Je kleiner der Abstand, desto ähnlicher sind die Merkmale.
Bei der Distanzmessung können wir zwischen geometrischer Distanzmessung und statistischer Distanzmessung wählen. Welche Distanzmessung gewählt werden soll, hängt von der Art der Daten ab. Features können von unterschiedlichen Datentypen sein (z. B. reale Werte, boolesche Werte, kategoriale Werte) und die Daten können mehrdimensional sein oder aus Geodaten bestehen.
Geometrische Distanzmessung
1. Euklidische Distanz Die euklidische Distanz misst die kürzeste Distanz zwischen zwei reellwertigen Vektoren. Aufgrund seiner Intuitivität, Benutzerfreundlichkeit und guten Ergebnisse für viele Anwendungsfälle ist es die am häufigsten verwendete Distanzmetrik und die Standard-Distanzmetrik für viele Anwendungen.
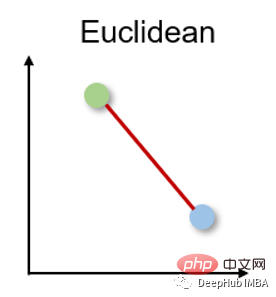 Der euklidische Abstand kann auch als l2-Norm bezeichnet werden. Die Berechnungsmethode lautet:
Der euklidische Abstand kann auch als l2-Norm bezeichnet werden. Die Berechnungsmethode lautet:
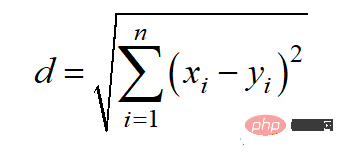 Der Python-Code lautet wie folgt:
Der Python-Code lautet wie folgt:
from scipy.spatial import distance distance.euclidean(vector_1, vector_2)
Der euklidische Abstand hat zwei Hauptnachteile. Erstens funktionieren Entfernungsmessungen nicht mit Daten größerer Dimensionen als dem 2D- oder 3D-Raum. Zweitens können Abstände um Einheiten verzerrt sein, wenn wir die Merkmale nicht normalisieren und/oder normalisieren.
2. Manhattan-Entfernung
Manhattan-Entfernung wird auch Taxi- oder Stadtblockentfernung genannt, da die Entfernung zwischen zwei reellen Vektoren auf der Grundlage der Tatsache berechnet wird, dass sich eine Person nur im rechten Winkel bewegen kann. Diese Distanzmetrik wird häufig für diskrete und binäre Attribute verwendet, damit echte Pfade ermittelt werden können.
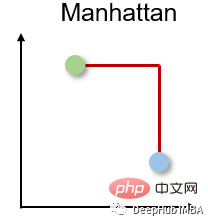 Der Manhattan-Abstand basiert auf der l1-Norm und die Berechnungsformel lautet:
Der Manhattan-Abstand basiert auf der l1-Norm und die Berechnungsformel lautet:
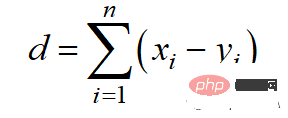 Der Python-Code lautet wie folgt:
Der Python-Code lautet wie folgt:
from scipy.spatial import distance distance.cityblock(vector_1, vector_2)
Der Manhattan-Abstand hat zwei Hauptnachteile. Sie ist nicht so intuitiv wie die euklidische Distanz im hochdimensionalen Raum und zeigt auch nicht den kürzestmöglichen Weg. Obwohl dies möglicherweise kein Problem darstellt, sollten wir uns darüber im Klaren sein, dass dies nicht die kürzeste Entfernung ist.
3. Tschebyscheff-Distanz Tschebyscheff-Distanz
Die Tschebyscheff-Distanz wird auch Schachbrettdistanz genannt, da es sich um den maximalen Abstand in jeder Dimension zwischen zwei reellwertigen Vektoren handelt. Es wird häufig in der Lagerlogistik eingesetzt, wo der längste Weg die Zeit bestimmt, die benötigt wird, um von einem Punkt zum anderen zu gelangen.
 Die Chebyshev-Distanz wird nach der L-Unendlichkeitsnorm berechnet:
Die Chebyshev-Distanz wird nach der L-Unendlichkeitsnorm berechnet:
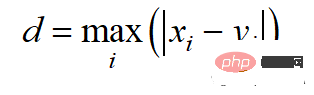 Der Python-Code lautet wie folgt:
Der Python-Code lautet wie folgt:
from scipy.spatial import distance distance.chebyshev(vector_1, vector_2)
Die Chebyshev-Distanz hat nur sehr spezifische Anwendungsfälle und wird daher selten verwendet.
4. Minkowski-Distanz Minkowski-Distanz
Minkowski-Distanz ist die verallgemeinerte Form des oben genannten Distanzmaßes. Es kann für die gleichen Anwendungsfälle eingesetzt werden und bietet gleichzeitig eine hohe Flexibilität. Wir können den p-Wert wählen, um das am besten geeignete Distanzmaß zu finden.
 Die Berechnungsmethode für den Minkowski-Abstand lautet:
Die Berechnungsmethode für den Minkowski-Abstand lautet:
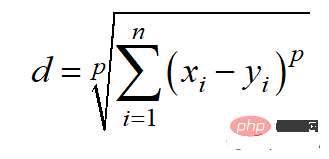 Der Python-Code lautet wie folgt:
Der Python-Code lautet wie folgt:
from scipy.spatial import distance distance.minkowski(vector_1, vector_2, p)
Da der Minkowski-Abstand unterschiedliche Abstandsmaße darstellt, weist er die gleichen Hauptnachteile auf wie diese, z. B. Probleme mit großen Dimensionen mit Raum und Abhängigkeit von charakteristischen Einheiten. Darüber hinaus kann die Flexibilität von p-Werten auch ein Nachteil sein, da sie die Recheneffizienz verringern kann, da mehrere Berechnungen erforderlich sind, um den richtigen p-Wert zu ermitteln.
5. Kosinusähnlichkeit und Abstand Kosinusähnlichkeit
Kosinusähnlichkeit ist ein Maß für die Richtung. Ihre Größe wird durch den Kosinus zwischen zwei Vektoren bestimmt und ignoriert die Größe des Vektors. Kosinusähnlichkeit wird häufig in hohen Dimensionen verwendet, bei denen die Größe der Daten keine Rolle spielt, beispielsweise bei Empfehlungssystemen oder Textanalysen.
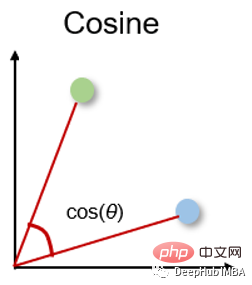
余弦相似度可以介于-1(相反方向)和1(相同方向)之间,计算方法为:
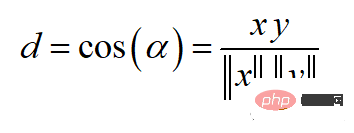
余弦相似度常用于范围在0到1之间的正空间中。余弦距离就是用1减去余弦相似度,位于0(相似值)和1(不同值)之间。
Python代码如下
from scipy.spatial import distance distance.cosine(vector_1, vector_2)
余弦距离的主要缺点是它不考虑大小而只考虑向量的方向。因此,没有充分考虑到值的差异。
6、半正矢距离 Haversine distance
半正矢距离测量的是球面上两点之间的最短距离。因此常用于导航,其中经度和纬度和曲率对计算都有影响。
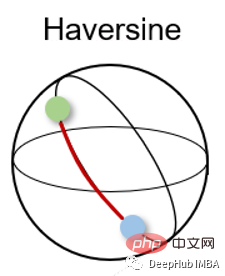
半正矢距离的公式如下:
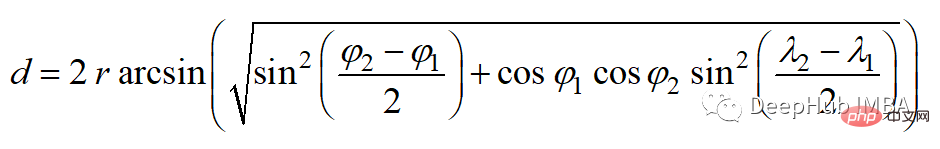
其中r为球面半径,φ和λ为经度和纬度。
Python代码如下
from sklearn.metrics.pairwise import haversine_distances haversine_distances([vector_1, vector_2])
半正矢距离的主要缺点是假设是一个球体,而这种情况很少出现。
7、汉明距离
汉明距离衡量两个二进制向量或字符串之间的差异。
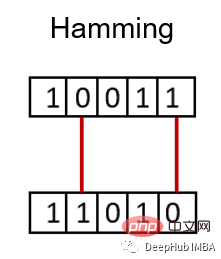
对向量按元素进行比较,并对差异的数量进行平均。如果两个向量相同,得到的距离是0之间,如果两个向量完全不同,得到的距离是1。
Python代码如下
from scipy.spatial import distance distance.hamming(vector_1, vector_2)
汉明距离有两个主要缺点。距离测量只能比较相同长度的向量,它不能给出差异的大小。所以当差异的大小很重要时,不建议使用汉明距离。
统计距离测量
统计距离测量可用于假设检验、拟合优度检验、分类任务或异常值检测。
8、杰卡德指数和距离 Jaccard Index
Jaccard指数用于确定两个样本集之间的相似性。它反映了与整个数据集相比存在多少一对一匹配。Jaccard指数通常用于二进制数据比如图像识别的深度学习模型的预测与标记数据进行比较,或者根据单词的重叠来比较文档中的文本模式。
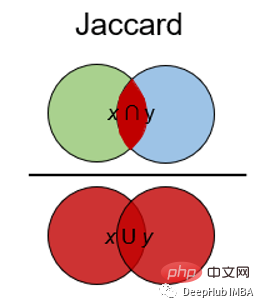
Jaccard距离的计算方法为:

Python代码如下
from scipy.spatial import distance distance.jaccard(vector_1, vector_2)
Jaccard指数和距离的主要缺点是,它受到数据规模的强烈影响,即每个项目的权重与数据集的规模成反比。
9、Sorensen-Dice指数
Sörensen-Dice指数类似于Jaccard指数,它可以衡量的是样本集的相似性和多样性。该指数更直观,因为它计算重叠的百分比。Sörensen-Dice索引常用于图像分割和文本相似度分析。
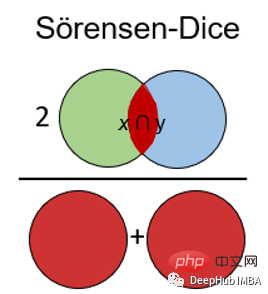
计算公式如下:
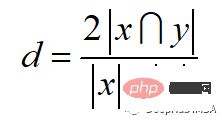
Python代码如下
from scipy.spatial import distance distance.dice(vector_1, vector_2)
它的主要缺点也是受数据集大小的影响很大。
10、动态时间规整 Dynamic Time Warping
动态时间规整是测量两个不同长度时间序列之间距离的一种重要方法。可以用于所有时间序列数据的用例,如语音识别或异常检测。
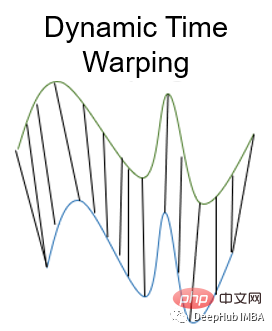
为什么我们需要一个为时间序列进行距离测量的度量呢?如果时间序列长度不同或失真,则上述面说到的其他距离测量无法确定良好的相似性。比如欧几里得距离计算每个时间步长的两个时间序列之间的距离。但是如果两个时间序列的形状相同但在时间上发生了偏移,那么尽管时间序列非常相似,但欧几里得距离会表现出很大的差异。
动态时间规整通过使用多对一或一对多映射来最小化两个时间序列之间的总距离来避免这个问题。当搜索最佳对齐时,这会产生更直观的相似性度量。通过动态规划找到一条弯曲的路径最小化距离,该路径必须满足以下条件:
- 边界条件:弯曲路径在两个时间序列的起始点和结束点开始和结束
- 单调性条件:保持点的时间顺序,避免时间倒流
- 连续条件:路径转换限制在相邻的时间点上,避免时间跳跃
- 整经窗口条件(可选):允许的点落入给定宽度的整经窗口
- 坡度条件(可选):限制弯曲路径坡度,避免极端运动
我们可以使用 Python 中的 fastdtw 包:
from scipy.spatial.distance import euclidean from fastdtw import fastdtw distance, path = fastdtw(timeseries_1, timeseries_2, dist=euclidean)
动态时间规整的一个主要缺点是与其他距离测量方法相比,它的计算工作量相对较高。
总结
在这篇文章中,简要介绍了十种常用的距离测量方法。本文中已经展示了它们是如何工作的,如何在Python中实现它们,以及经常使用它们解决什么问题。如果你认为我错过了一个重要的距离测量,请留言告诉我。
Das obige ist der detaillierte Inhalt vonZehn häufig verwendete Entfernungsmessmethoden beim maschinellen Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
